

Java 데이터베이스 검색 최적화 전략 및 기법 분석


Java 데이터베이스 검색 최적화 전략 및 기법에 대한 실제 분석
요약: 애플리케이션 요구 사항이 계속 증가함에 따라 데이터베이스 검색 성능이 중요한 문제가 되었습니다. 이 기사에서는 몇 가지 Java 데이터베이스 검색 최적화 전략 및 기술을 소개하고 개발자가 데이터베이스 검색 성능 문제를 해결하는 데 도움이 되는 해당 코드 예제를 제공합니다.
- 색인 최적화
데이터베이스의 색인은 검색 성능을 향상시키는 열쇠입니다. 적절하게 생성된 인덱스는 검색 속도를 크게 높일 수 있습니다. 데이터베이스 테이블에서 적절한 컬럼을 인덱스 컬럼으로 선택하고 해당 컬럼에 인덱스를 생성하면 검색 성능을 효과적으로 향상시킬 수 있습니다. 다음은 MySQL 데이터베이스에 대한 인덱스 최적화의 예입니다.
// 创建索引 CREATE INDEX idx_user_id ON user(id); // 使用索引查询 SELECT * FROM user WHERE id = 1;
쿼리 최적화
데이터베이스 쿼리 문을 작성할 때 쿼리 성능을 최적화하려면 다음 사항에 주의해야 합니다.- 적절한 쿼리 문을 선택하세요. 보다 정확한 쿼리 조건은 쓸모 없는 데이터 반환을 줄이고 쿼리 성능을 향상시킬 수 있습니다. 예를 들어
LIKE대신=를 사용하고 연속OR쿼리 대신IN을 사용하는 등의 작업을 수행합니다.=代替LIKE、使用IN代替连续的OR查询等。 - 避免查询所有列:只查询需要的列可以减少网络传输的数据量,提高查询性能。
- 避免使用
SELECT *:明确指定需要的列,而不是使用通配符*。 - 合理使用分页:对于大数据量的查询结果,使用有效的分页方式可以减少查询的处理时间。可以使用
LIMIT모든 열 쿼리 방지: 필요한 열만 쿼리하면 네트워크를 통해 전송되는 데이터의 양을 줄이고 쿼리 성능을 향상시킬 수 있습니다.
- 적절한 쿼리 문을 선택하세요. 보다 정확한 쿼리 조건은 쓸모 없는 데이터 반환을 줄이고 쿼리 성능을 향상시킬 수 있습니다. 예를 들어
SELECT * 사용을 피하세요. 와일드카드 *를 사용하는 대신 필수 열을 명시적으로 지정하세요. 페이징의 합리적인 사용: 대용량 데이터가 포함된 쿼리 결과의 경우 효과적인 페이징 방법을 사용하면 쿼리 처리 시간을 줄일 수 있습니다. LIMIT 키워드를 사용하여 지정된 양의 데이터를 반환할 수 있습니다.
CriteriaBuilder cb = session.getCriteriaBuilder();
CriteriaQuery<User> query = cb.createQuery(User.class);
Root<User> root = query.from(User.class);
query.select(root).where(cb.equal(root.get("id"), 1));
Query<User> q = session.createQuery(query);
List<User> users = q.getResultList();- 데이터 캐싱
읽기 작업이 빈번한 데이터베이스의 경우 캐시를 사용하면 검색 성능을 크게 향상시킬 수 있습니다. 검색 결과를 메모리에 캐시하면 데이터베이스에 대한 액세스 횟수를 줄여 응답 시간을 단축할 수 있습니다. 일반적으로 사용되는 캐싱 기술에는 Redis, Memcached 등이 포함됩니다. 다음은 단순히 캐싱을 위해 Redis를 사용하는 예입니다.
// 查询时先检查缓存中是否存在
String key = "user:" + id;
String userStr = cache.get(key);
if (userStr == null) {
// 从数据库中查询
User user = userDao.findById(id);
if (user != null) {
// 将查询结果缓存到Redis中
cache.set(key, user.toString());
}
} else {
// 取出缓存数据
User user = new User(userStr);
// ...
}데이터베이스 연결은 제한된 리소스이며 연결을 만들고 해제하는 데 비용이 많이 드는 작업입니다. 커넥션 풀을 이용하면 미리 커넥션 배치를 생성해 이러한 커넥션을 효과적으로 재사용할 수 있어 커넥션 생성 및 해제 횟수를 줄이고 데이터베이스 검색 성능을 향상시킬 수 있다. 일반적으로 사용되는 연결 풀에는 HikariCP, Druid 등이 있습니다.
HikariConfig config = new HikariConfig();
config.setJdbcUrl("jdbc:mysql://localhost:3306/test");
config.setUsername("root");
config.setPassword("password");
HikariDataSource dataSource = new HikariDataSource(config);
Connection connection = dataSource.getConnection();
// 使用连接进行数据库操作
connection.close(); // 释放连接위 내용은 Java 데이터베이스 검색 최적화 전략 및 기법 분석의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7530
7530
 15
1378
52
82
11
54
19
21
76
15
1378
52
82
11
54
19
21
76

 Java Spring 인터뷰 질문
Aug 30, 2024 pm 04:29 PM
Java Spring 인터뷰 질문
Aug 30, 2024 pm 04:29 PM
이 기사에서는 가장 많이 묻는 Java Spring 면접 질문과 자세한 답변을 보관했습니다. 그래야 면접에 합격할 수 있습니다.
 Java 8 Stream foreach에서 나누거나 돌아 오시겠습니까?
Feb 07, 2025 pm 12:09 PM
Java 8 Stream foreach에서 나누거나 돌아 오시겠습니까?
Feb 07, 2025 pm 12:09 PM
Java 8은 스트림 API를 소개하여 데이터 컬렉션을 처리하는 강력하고 표현적인 방법을 제공합니다. 그러나 스트림을 사용할 때 일반적인 질문은 다음과 같은 것입니다. 기존 루프는 조기 중단 또는 반환을 허용하지만 스트림의 Foreach 메소드는이 방법을 직접 지원하지 않습니다. 이 기사는 이유를 설명하고 스트림 처리 시스템에서 조기 종료를 구현하기위한 대체 방법을 탐색합니다. 추가 읽기 : Java Stream API 개선 스트림 foreach를 이해하십시오 Foreach 메소드는 스트림의 각 요소에서 하나의 작업을 수행하는 터미널 작동입니다. 디자인 의도입니다
 캡슐의 양을 찾기위한 Java 프로그램
Feb 07, 2025 am 11:37 AM
캡슐의 양을 찾기위한 Java 프로그램
Feb 07, 2025 am 11:37 AM
캡슐은 3 차원 기하학적 그림이며, 양쪽 끝에 실린더와 반구로 구성됩니다. 캡슐의 부피는 실린더의 부피와 양쪽 끝에 반구의 부피를 첨가하여 계산할 수 있습니다. 이 튜토리얼은 다른 방법을 사용하여 Java에서 주어진 캡슐의 부피를 계산하는 방법에 대해 논의합니다. 캡슐 볼륨 공식 캡슐 볼륨에 대한 공식은 다음과 같습니다. 캡슐 부피 = 원통형 볼륨 2 반구 볼륨 안에, R : 반구의 반경. H : 실린더의 높이 (반구 제외). 예 1 입력하다 반경 = 5 단위 높이 = 10 단위 산출 볼륨 = 1570.8 입방 단위 설명하다 공식을 사용하여 볼륨 계산 : 부피 = π × r2 × h (4
 Spring Tool Suite에서 첫 번째 Spring Boot 응용 프로그램을 실행하는 방법은 무엇입니까?
Feb 07, 2025 pm 12:11 PM
Spring Tool Suite에서 첫 번째 Spring Boot 응용 프로그램을 실행하는 방법은 무엇입니까?
Feb 07, 2025 pm 12:11 PM
Spring Boot는 강력하고 확장 가능하며 생산 가능한 Java 응용 프로그램의 생성을 단순화하여 Java 개발에 혁명을 일으킨다. Spring Ecosystem에 내재 된 "구성에 대한 협약"접근 방식은 수동 설정, Allo를 최소화합니다.
 미래를 창조하세요: 완전 초보자를 위한 Java 프로그래밍
Oct 13, 2024 pm 01:32 PM
미래를 창조하세요: 완전 초보자를 위한 Java 프로그래밍
Oct 13, 2024 pm 01:32 PM
Java는 초보자와 숙련된 개발자 모두가 배울 수 있는 인기 있는 프로그래밍 언어입니다. 이 튜토리얼은 기본 개념부터 시작하여 고급 주제를 통해 진행됩니다. Java Development Kit를 설치한 후 간단한 "Hello, World!" 프로그램을 작성하여 프로그래밍을 연습할 수 있습니다. 코드를 이해한 후 명령 프롬프트를 사용하여 프로그램을 컴파일하고 실행하면 "Hello, World!"가 콘솔에 출력됩니다. Java를 배우면 프로그래밍 여정이 시작되고, 숙달이 깊어짐에 따라 더 복잡한 애플리케이션을 만들 수 있습니다.
 Java Made Simple: 초보자를 위한 프로그래밍 능력 가이드
Oct 11, 2024 pm 06:30 PM
Java Made Simple: 초보자를 위한 프로그래밍 능력 가이드
Oct 11, 2024 pm 06:30 PM
간단해진 Java: 강력한 프로그래밍을 위한 초보자 가이드 소개 Java는 모바일 애플리케이션에서 엔터프라이즈 수준 시스템에 이르기까지 모든 분야에서 사용되는 강력한 프로그래밍 언어입니다. 초보자의 경우 Java의 구문은 간단하고 이해하기 쉬우므로 프로그래밍 학습에 이상적인 선택입니다. 기본 구문 Java는 클래스 기반 객체 지향 프로그래밍 패러다임을 사용합니다. 클래스는 관련 데이터와 동작을 함께 구성하는 템플릿입니다. 다음은 간단한 Java 클래스 예입니다. publicclassPerson{privateStringname;privateintage;
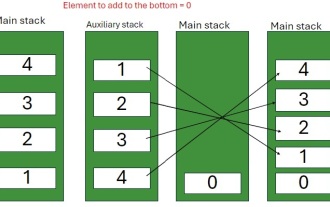 스택 하단에 요소를 삽입하는 Java 프로그램
Feb 07, 2025 am 11:59 AM
스택 하단에 요소를 삽입하는 Java 프로그램
Feb 07, 2025 am 11:59 AM
스택은 Lifo (마지막으로, 첫 번째) 원칙을 따르는 데이터 구조입니다. 다시 말해서, 우리가 스택에 추가하는 마지막 요소는 제거 된 첫 번째 요소입니다. 우리가 스택에 요소를 추가 (또는 푸시) 할 때, 그것들은 상단에 배치됩니다. 즉, 무엇보다도
 MySQL : 쉽게 학습하기위한 간단한 개념
Apr 10, 2025 am 09:29 AM
MySQL : 쉽게 학습하기위한 간단한 개념
Apr 10, 2025 am 09:29 AM
MySQL은 오픈 소스 관계형 데이터베이스 관리 시스템입니다. 1) 데이터베이스 및 테이블 작성 : CreateAbase 및 CreateTable 명령을 사용하십시오. 2) 기본 작업 : 삽입, 업데이트, 삭제 및 선택. 3) 고급 운영 : 가입, 하위 쿼리 및 거래 처리. 4) 디버깅 기술 : 확인, 데이터 유형 및 권한을 확인하십시오. 5) 최적화 제안 : 인덱스 사용, 선택을 피하고 거래를 사용하십시오.
