
다음과 같은 날카로운 의견을 들어보셨을 것입니다.
1. NVIDIA의 기술 경로를 따른다면 결코 NVIDIA를 따라잡지 못할 수도 있습니다.
2. DSA가 엔비디아를 따라잡을 기회가 있을지도 모르지만, 현재 상황은 DSA가 멸종 위기에 처해 있고 희망이 보이지 않습니다
반면, 이제 대형 모델이 대세라는 것은 우리 모두가 알고 있는 사실입니다. 최전선에서 업계의 많은 사람들이 대형 모델 칩을 만들고 싶어하는 동시에 대형 모델 칩에 투자하려는 사람들도 많습니다.
대형 모델 칩 설계의 핵심은 무엇일까요? 넓은 대역폭과 대용량 메모리의 중요성은 다들 아시는 것 같은데, 칩이 NVIDIA와 어떻게 다른가요?
질문이 있는 이 기사는 여러분에게 영감을 주기 위해 노력합니다.
순전히 의견을 바탕으로 한 기사는 형식적인 것처럼 보일 때가 많습니다. 우리는 이를 아키텍처 사례를 통해 설명할 수 있습니다.
SambaNova Systems는 미국 10대 유니콘 기업 중 하나로 알려져 있습니다. 2021년 4월에는 소프트뱅크가 주도하는 시리즈 D 투자에서 6억 7,800만 달러를 유치했으며, 가치 평가액은 50억 달러에 달해 슈퍼 유니콘 기업으로 거듭났습니다. 이전에 SambaNova의 투자자에는 Google Ventures, Intel Capital, SK, Samsung Catalytic Fund 등 세계 최고의 벤처 캐피탈 펀드가 포함되었습니다. 그렇다면 세계 최고의 투자기관들의 사랑을 받고 있는 슈퍼 유니콘 기업은 과연 어떤 파괴적인 일을 하고 있을까? 초기 홍보 자료를 보면 SambaNova가 AI 거대 NVIDIA
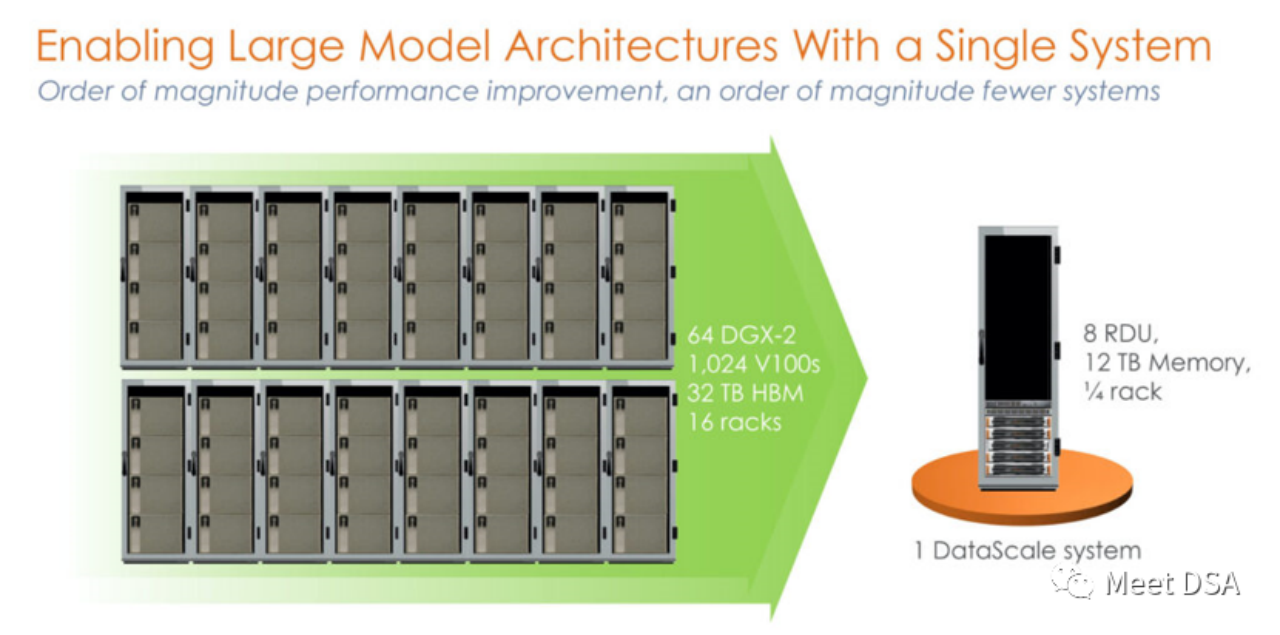
와는 다른 개발 경로를 선택했음을 알 수 있습니다. 조금 충격적이지 않나요? NVIDIA 플랫폼에서 전례 없는 성능으로 구축된 1024 V100 클러스터는 실제로 SambaNova의 단일 시스템과 동일합니까? ! 이 제품은 SN10 RDU를 기반으로 한 독립형 8카드 머신인 1세대 제품입니다.
어떤 사람들은 이 비교가 불공평하다고 말할 수도 있습니다. NVIDIA에는 DGX A100이 있지 않습니까? 아마도 SambaNova 자체가 그것을 깨달았고 2세대 제품인 SN30은 다음과 같이 변경되었습니다.

DGX A100에는 컴퓨팅 기능이 있습니다. 5페타플롭스의 성능을 제공하는 SambaNova의 2세대 DataScale도 5페타플롭스의 컴퓨팅 성능을 제공합니다. 320GB HBM과 8TB DDR4의 메모리 비교(편집자는 기사를 잘못 썼을 수도 있다고 추측하며 3TB * 8이어야 함).
2세대 칩은 실제로 SN10 RDU의 Die-to-Die 버전입니다. SN10 RDU의 아키텍처 지표는 320TFLOPS@BF16, 320M SRAM, 1.5T DDR4입니다. 이를 기준으로 SN30 RDU는 아래 설명과 같이 두 배가 됩니다.
“이 칩에는 BF16 부동 소수점 정밀도에서 320테라플롭 이상의 컴퓨팅을 갖춘 640개의 패턴 컴퓨팅 장치가 있으며 320MB의 온칩 SRAM을 갖춘 640개의 패턴 메모리 장치도 있습니다. 그리고 150TB/초의 온칩 메모리 대역폭을 제공합니다. 각 SN10 프로세서는 1.5TB의 DDR4 보조 메모리도 처리할 수 있었습니다." "Cardinal SN30 RDU를 사용하면 RDU의 용량이 두 배로 늘어나는데, 그 이유는 다음과 같습니다. SambaNova는 처음부터 멀티다이 패키징을 사용하도록 아키텍처를 설계했으며, 이 경우 SambaNova는 두 개의 새로운 RDU를 채워서 DataScale 시스템의 용량을 두 배로 늘렸습니다. 우리가 추측하는 것은 마이크로 아키텍처가 변경된 두 개의 조정된 SN10입니다. 대규모 기반 모델을 SN30이라는 단일 컴플렉스로 더 효과적으로 지원합니다. DataScale 시스템의 각 소켓은 이제 1세대 머신보다 컴퓨팅 용량, 로컬 메모리 용량, 메모리 대역폭이 두 배입니다.”
Key 포인트 추출:대역폭과 대용량은 두 가지 옵션 중에서만 선택할 수 있습니다. NVIDIA는 대용량 HBM을 선택한 반면 SambaNova는 대용량 DDR4를 선택했습니다. 성능 결과에서는 SambaNova가 승리했습니다.
DGX H100으로 전환하면 FP8 등 저정밀 기술로 전환해도 격차가 줄어들 수 밖에 없습니다.
“그리고 DGX-H100이 DGX-A100보다 16비트 부동 소수점 계산에서 3배의 성능을 제공하더라도 SambaNova 시스템과의 격차를 좁히지는 못할 것입니다. 그러나 낮은 정밀도의 FP8 데이터에서는 Nvidia가 그럴 수도 있습니다. 성능 격차를 줄일 수 있지만, 낮은 정밀도의 데이터 및 처리로 전환하면 얼마나 많은 정밀도가 희생될지는 불분명합니다.”
누군가 그러한 효과를 얻을 수 있다면 완벽한 대형 칩 솔루션이 아닐까요? 그리고 NVIDIA와의 경쟁에 직접 맞설 수도 있습니다!
(Grace CPU는 LPDDR에도 연결할 수 있어 용량을 늘리는 데 도움이 된다고 말할 수도 있습니다. 반면 SambaNova는 이 문제를 어떻게 봅니다. Grace는 단지 대용량 메모리 컨트롤러일 뿐이지만 512GB만 가져올 수 있습니다.
우리는 Nvidia의 "Grace" Arm CPU가 단지 Hopper GPU를 위한 과대포장된 메모리 컨트롤러일 뿐이라고 농담하곤 했으며 많은 경우 실제로는 그저 메모리 컨트롤러일 뿐이었습니다. 그리고 각 Grace-Hopper 슈퍼 칩 패키지의 Hopper GPU에는 최대 512GB의 메모리만 있습니다. 이는 SambaNova에서 제공하는 3TB의 메모리보다 훨씬 적습니다.
역사에 따르면 가장 번영하는 제국이라도 그래야 할 수 있습니다. 조심하세요. 눈에 띄지 않는 균열
Huawei의 거장인 Xia He는 최근 NVIDIA 제국의 약점이 비용 측면에서 GB당 비용에 있을 수 있다고 추측했습니다. 그는 대규모 내부 입출력을 위해 저렴한 DDR 메모리를 미친 듯이 적층할 것을 제안했습니다. NVIDIA에 혁명적인 영향을 미칠 수도 있습니다
(확장자:https://www.php.cn/link/617974172720b96de92525536de581fa)
그리고 DSA를 연구하는 또 다른 Zhihu 마스터인 Mackler는 다음과 같은 관점에서 자신의 의견을 밝혔습니다. $/GBps(데이터 이동), LLM은 메모리 용량에 대한 수요가 상대적으로 크지만 훈련에는 DRAM에서 교환해야 하는 많은 매개변수가 필요하므로 비용 효율적입니다. .
(확장자: https://www.php.cn/link/a56ee48e5c142c26cf645b2cc23d78fc)
SambaNova의 아키텍처 예시로 볼 때, 대용량 저가형 DDR은 LLM의 문제를 해결할 수 있다는 것을 확인시켜줍니다. 코어의 판단! 그러나 Mackler의 관점에 따르면 데이터 마이그레이션을 위한 막대한 대역폭 요구 사항도 문제입니다. 그러면 SambaNova는 이를 어떻게 해결합니까?
RDU 아키텍처의 특성을 더 잘 이해해야 합니다. 사실 이해하기 쉽습니다.
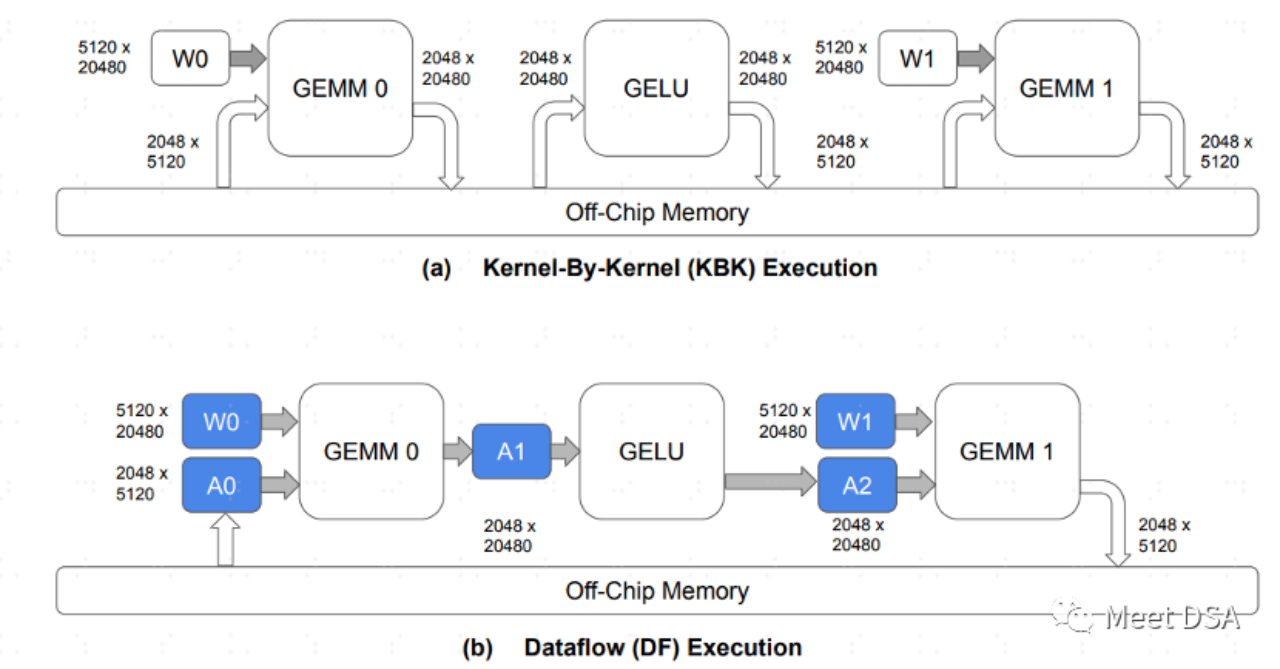
A는 기존 GPU 아키텍처의 데이터 교환 패러다임입니다. 칩 DRAM이 데이터를 주고받는다는 것은 DDR 대역폭을 많이 차지한다는 것을 이해하기 쉬울 것입니다. B는 SambaNova의 아키텍처가 달성할 수 있는 것입니다. 모델 계산 과정에서 데이터 이동의 상당 부분이 칩에 유지되므로 교환을 위해 DRAM을 오갈 필요가 없습니다.
그러므로 대역폭과 대용량 중 선택의 문제인 B와 같은 효과를 얻을 수 있다면 안심하고 대용량을 선택할 수 있습니다.
“우리가 가진 질문은 이것입니다. 기반 모델, 메모리 용량 또는 메모리 대역폭을 지원하는 하이브리드 메모리 아키텍처에서 더 중요한 것은 단일 메모리 기술을 기반으로 둘 다 가질 수는 없다는 것입니다. 어떤 아키텍처든, 빠르고 날씬하고 느리고 뚱뚱한 기억이 혼합되어 있더라도 Nvidia와 SambaNova가 선을 그리는 곳은 다릅니다.”
강력한 NVIDIA를 마주하면 우리는 희망이 없지 않습니다! 그러나 NVIDIA의 GPGPU 전략을 따르는 것이 불가능할 수도 있습니다. 대형 칩의 올바른 생각은 저렴한 DRAM을 사용하는 것 같습니다. 동일한 컴퓨팅 성능 사양으로 성능은 NVIDIA의 6배 이상에 도달할 수 있습니다!
SambaNova의 RDU/DataFlow 아키텍처는 어떻게 B의 효과를 달성합니까? 아니면 B와 유사한 효과를 얻을 수 있는 다른 방법이 있습니까? 다음번에도 공유해드리겠습니다. 관심 있는 친구들은 계속해서 저희 업데이트에 관심을 가져주세요
추가 자료:
[1]https://sambanova.ai/blog/a-new- 최첨단 -the-art-in-nlp-beyond-gpus/
[2]https://www.nextplatform.com/2022/09/17/sambanova-doubles-up-chips-to-chase -ai- Foundation-models/
[3]https://hc33.hotchips.org/assets/program/conference/day2/SambaNova%20HotChips%202021%20Aug%2023%20v1.pdf
[ 4] 《 희소성 및 데이터 흐름을 사용하여 효율적으로 대규모 언어 모델 훈련》
[5]https://www.php.cn/link/617974172720b96de92525536de581fa
다시 작성해야 하는 콘텐츠는 다음과 같습니다. [6]https ://www.php.cn/link/a56ee48e5c142c26cf645b2cc23d78fc
위 내용은 DSA는 어떻게 한 구석에서 NVIDIA GPU를 추월합니까?의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



