
자동 요약 기술은 주석이 달린 데이터세트에 대한 감독 미세 조정에서 GPT-4와 같은 제로 샷 힌트를 위한 LLM(대형 언어 모델) 사용에 이르기까지 패러다임 전환으로 인해 최근 몇 년간 큰 발전을 이루었습니다. 신중하게 디자인된 프롬프트를 사용하면 추가 교육 없이도 요약 길이, 주제, 스타일 및 기타 기능을 세밀하게 제어할 수 있습니다.
그러나 종종 간과되는 한 가지 측면, 즉 요약의 정보 밀도입니다. 이론적으로 다른 텍스트를 압축한 요약은 소스 파일보다 더 밀도가 높아야 합니다. 즉, 더 많은 정보를 포함해야 합니다. LLM 디코딩의 높은 대기 시간을 고려할 때 특히 실시간 애플리케이션의 경우 더 적은 단어로 더 많은 정보를 처리하는 것이 중요합니다.
그러나 정보 밀도는 공개된 질문입니다. 초록에 세부 사항이 충분하지 않으면 정보가 없는 것과 같습니다. 전체 길이를 늘리지 않고 너무 많은 정보를 포함하면 이해하기 어려워집니다. 고정된 어휘 예산 내에서 더 많은 정보를 전달하려면 추상화, 압축 및 융합을 결합해야 합니다
최근 연구에서 Salesforce, MIT 및 기타 기관의 연구원들은 다음을 시도했습니다. 이 한계는 점점 더 많은 세트에 대한 선호도에 따라 결정됩니다. GPT-4에서 생성된 더 조밀한 요약. 이 방법은 GPT-4와 같은 대규모 언어 모델의 "표현 능력"을 향상시키는 데 많은 영감을 제공합니다.

문서 링크: https://arxiv.org/pdf/2309.04269.pdf
데이터 세트 주소: https://huggingface.co/datasets/griffin/chain_of_density
구체적인 내용 말하기 , 그들의 접근 방식은 태그당 평균 엔터티 수를 밀도의 프록시로 사용하여 초기 엔터티 희소 요약을 생성합니다. 그런 다음 전체 길이를 늘리지 않고(총 길이는 원래 요약의 5배) 이전 요약에서 누락된 1~3개의 엔터티를 반복적으로 식별하고 융합하여 각 요약의 엔터티 대 태그 비율이 이전 요약보다 높아지도록 합니다. 인간 선호도 데이터 분석을 통해 저자는 마침내 인간이 작성한 요약만큼 조밀하고 일반 GPT-4 프롬프트에서 생성된 요약보다 밀도가 높은 요약 형식을 식별했습니다.
연구의 전반적인 기여는 다음과 같습니다.
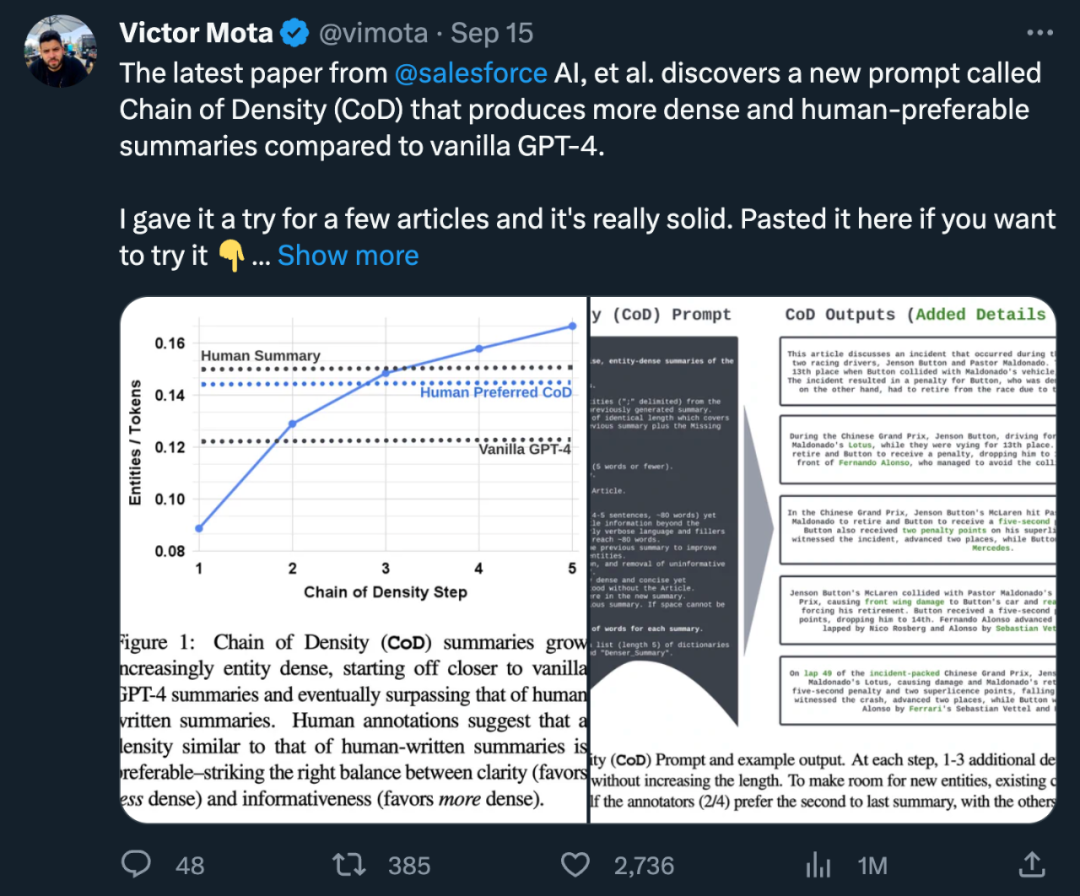
저자는 초기 요약을 생성하고 점차적으로 개체 밀도를 높이기 위해 "CoD"(밀도 체인)라는 프롬프트를 설정합니다. 구체적으로, 고정된 수의 상호 작용 내에서 소스 텍스트의 고유하고 두드러진 엔터티 집합이 식별되어 길이를 늘리지 않고 이전 요약에 병합됩니다
그림 2에 프롬프트가 표시되고 예제가 출력됩니다. 저자는 항목 유형을 지정하지 않지만 누락된 항목을 다음과 같이 정의합니다.
 저자는 CNN/DailyMail 요약 테스트 세트에서 무작위로 100개의 기사를 선택하여 CoD 요약을 생성했습니다. 쉽게 참조할 수 있도록 CoD 요약 통계를 "기사에 대한 매우 짧은 요약을 작성하세요.
저자는 CNN/DailyMail 요약 테스트 세트에서 무작위로 100개의 기사를 선택하여 CoD 요약을 생성했습니다. 쉽게 참조할 수 있도록 CoD 요약 통계를 "기사에 대한 매우 짧은 요약을 작성하세요.
Statistics
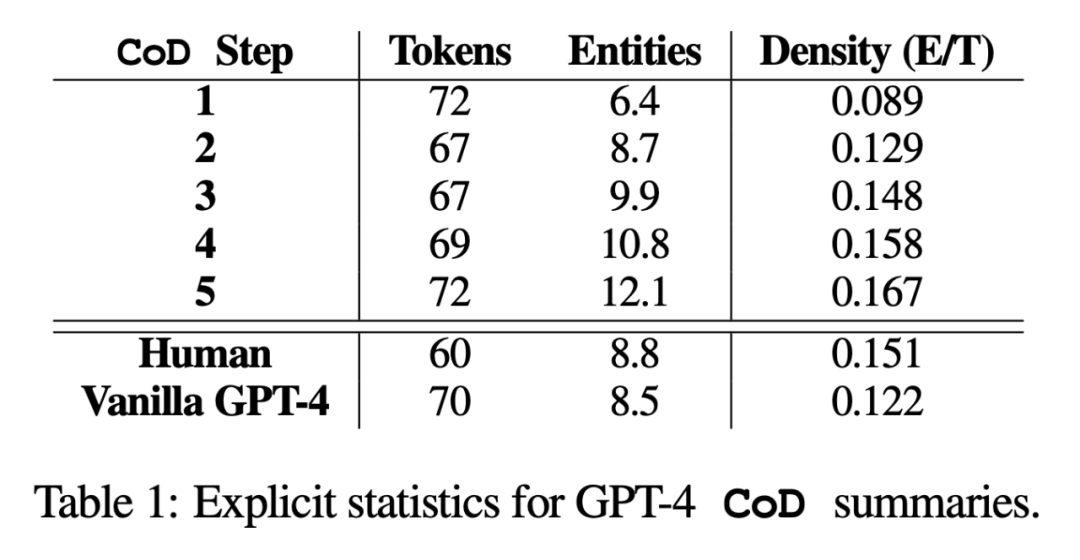
다시 작성한 내용은 다음과 같습니다. 통계에 따르면 긴 초록에서 불필요한 단어를 제거하여 두 번째 단계의 평균 길이가 5토큰(72에서 67로) 줄었습니다. 초기 엔터티 밀도는 0.089로 인간 및 바닐라 GPT-4(0.151 및 0.122)보다 낮으며, 5단계의 치밀화 단계를 거쳐 최종적으로 0.167
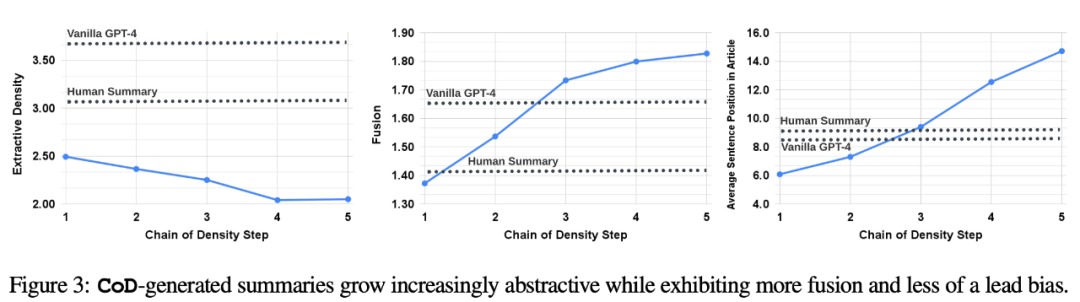
간접 통계로 상승합니다. 각 추가 엔터티에 대한 공간을 확보하기 위해 추상이 반복적으로 다시 작성되므로 CoD의 각 단계마다 추상화 수준이 높아져야 합니다. 저자는 추출 밀도(추출된 조각의 평균 제곱 길이)를 사용하여 추상화를 측정합니다(Grusky et al., 2018). 마찬가지로 고정 길이 요약에 엔터티가 추가됨에 따라 개념 융합이 단조롭게 증가해야 합니다. 저자들은 각 요약 문장에 정렬된 원본 문장의 평균 개수로 통합 정도를 표현했습니다. 정렬을 위해 저자는 추가 문장의 상대 ROUGE 이득이 더 이상 양수가 아닐 때까지 원본 문장을 대상 문장과 정렬하는 상대 ROUGE 이득 방법(Zhou et al., 2018)을 사용합니다. 그들은 또한 콘텐츠 배포나 요약 콘텐츠가 나오는 기사 내 위치의 변화도 예상했습니다.
특히 저자는 Call of Duty(CoD) 요약이 처음에 강한 "부트스트래핑 편향"을 보여줄 것이라고 예측합니다. 즉, 기사 시작 부분에 더 많은 엔터티가 소개될 것입니다. 그러나 기사가 전개되면서 이러한 지도 편향은 점차 약화되고 기사의 중간과 끝 부분부터 개체가 소개되기 시작합니다. 이를 측정하기 위해 융합에서 정렬 결과를 사용하고 정렬된 모든 소스 문장의 평균 문장 순위를 측정했습니다.
그림 3은 이러한 가설을 확인합니다. 다시 작성 단계가 증가할수록 추상성도 증가합니다. 추출 밀도가 증가함에 따라(낮아짐) 추출 밀도는 왼쪽), 융합 속도는 증가하고(가운데 이미지) 초록은 기사 중간과 끝 부분의 내용을 통합하기 시작합니다(오른쪽 이미지). 흥미롭게도 모든 CoD 요약은 사람이 작성한 요약 및 기본 요약에 비해 더 추상적이었습니다.
CoD 요약의 장단점을 더 잘 이해하기 위해 저자는 선호도 기반 인간 연구를 다음과 같이 수행했습니다. GPT-4
인간 선호도를 사용한 등급 기반 평가. 구체적으로, 동일한 100개의 논문(5단계 *100 = 총 500개의 초록)에 대해 저자는 "재작성된" CoD 초록과 논문을 논문의 처음 4명의 저자에게 무작위로 보여주었습니다. 각 주석자는 Stiennon et al.(2020)의 "좋은 요약" 정의를 기반으로 자신이 가장 좋아하는 요약을 제공했습니다. 표 2는 CoD 단계에서 각 주석자의 1위 투표와 각 주석자의 요약을 보고합니다. 전체적으로 1위 초록의 61%(23.0+22.5+15.5)가 ≥3의 치밀화 단계를 포함했습니다. 선호되는 CoD 단계의 중앙값은 중간(3)에 있으며 예상 단계 수는 3.06입니다.
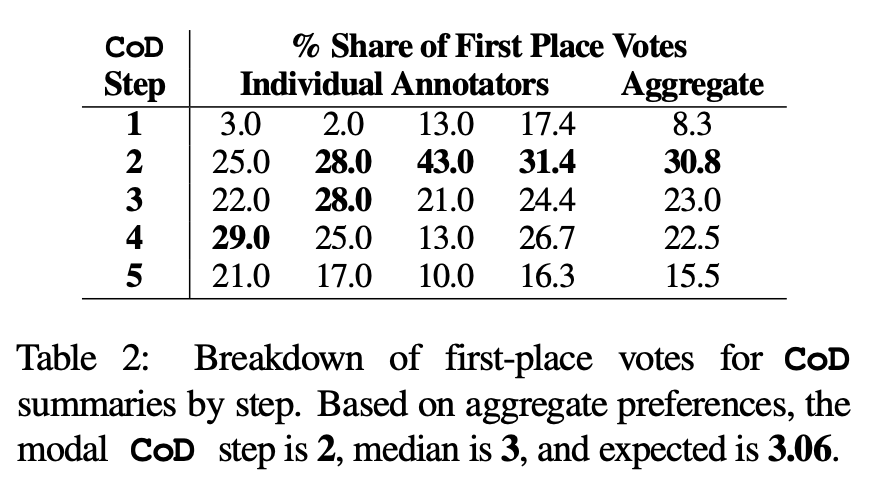
Step 3 요약의 평균 밀도를 기준으로 모든 CoD 후보의 선호 개체 밀도는 ~0.15라는 것을 대략적으로 유추할 수 있습니다. 표 1에서 볼 수 있듯이 이 밀도는 사람이 작성한 요약(0.151)과 일치하지만 일반 GPT-4 프롬프트로 작성된 요약(0.122)보다 훨씬 높습니다.
자동 측정. 인간 평가(아래)에 대한 보완으로 저자는 GPT-4를 사용하여 정보성, 품질, 일관성, 귀속성 및 전체성이라는 5가지 차원에 따라 CoD 요약(1-5점)을 평가했습니다. 표 3에서 볼 수 있듯이 밀도는 정보성과 상관 관계가 있지만 최대 한도에 이르며 점수는 4단계(4.74)에서 최고점에 이릅니다.
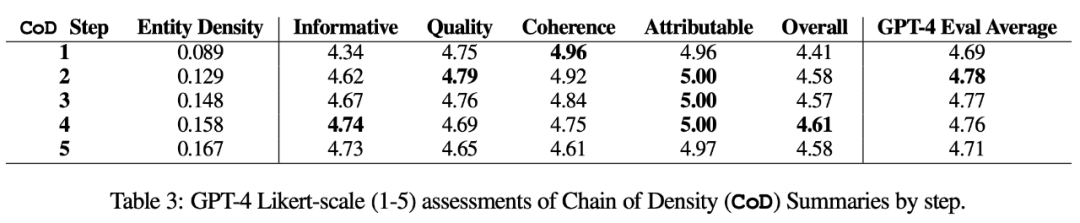
각 차원의 평균 점수 중 CoD의 첫 번째와 마지막 단계의 점수가 가장 낮은 반면, 중간 세 단계의 점수는 각각 4.78, 4.77, 4.76입니다.
정성적 분석. 초록의 일관성/가독성과 정보성 사이에는 분명한 균형이 있습니다. 그림 4는 두 가지 CoD 단계를 보여줍니다. 한 단계의 요약은 더 많은 세부 정보로 개선되고 다른 단계의 요약은 손상됩니다. 전반적으로 중간 CoD 요약은 이러한 균형을 달성할 수 있지만 이러한 균형은 향후 작업에서 여전히 정확하게 정의되고 정량화되어야 합니다

논문의 자세한 내용은 원문을 참고해주세요.
위 내용은 '적은 단어, 많은 양의 정보', Salesforce 및 MIT 연구원이 GPT-4 '개정'을 가르치고 데이터 세트가 오픈 소스임의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



