

Zhiyuan은 3억 개의 의미 벡터 모델 학습 데이터를 공개했으며 BGE 모델은 계속해서 반복적으로 업데이트됩니다.

대형 모델의 급속한 발전과 적용으로 인해 대형 모델의 핵심 기본 구성 요소인 Embedding의 중요성이 더욱 부각되고 있습니다. 한 달 전 Zhiyuan Company가 출시한 오픈 소스 상용 중국어 및 영어 의미 벡터 모델 BGE(BAAI General Embedding)는 커뮤니티에서 광범위한 관심을 끌었으며 Hugging Face 플랫폼에서 수십만 번 다운로드되었습니다. 현재 BGE는 버전 1.5를 빠르게 반복적으로 출시하고 여러 업데이트를 발표했습니다. 그 중 BGE는 처음으로 3억 개의 대규모 훈련 데이터를 오픈 소스화하여 커뮤니티에 유사한 모델을 훈련하고 이 분야의 기술 개발을 촉진하는 데 도움을 제공했습니다
- MTP 데이터 세트 링크: https://data.baai.ac.cn/details/BAAI-MTP
- BGE 모델 링크: https://huggingface.co/BAAI
- BGE 코드 저장소: https : //www.php .cn/link/8944871F1C9865A77A3D9C92CADF124D 3 억 3 천만 중국어 및 영어 벡터 모델 교육 데이터 오픈 최초의 오픈 소스 산업 시맨틱 벡터 모델 교육 데이터는 3 천만 건 중국에 도달했습니다. 그리고 영어 데이터
BGE의 우수성 그 역량은 주로 대규모의 다양한 학습 데이터에서 비롯됩니다. 이전에는 업계 동료들이 유사한 데이터 세트를 거의 공개하지 않았습니다. 이번 업데이트에서 Zhiyuan은 처음으로 BGE 교육 데이터를 커뮤니티에 공개하여 이러한 유형의 기술 개발을 위한 기반을 마련했습니다.
이번에 공개된 MTP 데이터 세트는 총 3억 개의 중국어 및 영어 관련 텍스트 쌍으로 구성되어 있습니다. 그 중 중국어로 된 레코드가 1억 개, 영어로 된 레코드가 2억 개입니다. 데이터 소스에는 Wudao Corpora, Pile, DuReader, Sentence Transformer 및 기타 말뭉치가 포함됩니다. 필요한 샘플링, 추출 및 청소 후 획득
자세한 내용은 데이터 허브를 참조하세요: https://data.baai.ac.cn
MTP는 최대 오픈 소스 중국어-영어 관련 텍스트 쌍 데이터 세트입니다. 현재까지 중국어와 영어 의미론적 벡터 모델을 훈련하는 데 중요한 기반을 제공하고 있습니다.
개발자 커뮤니티의 반응에 따라 BGE 기능 업그레이드
커뮤니티 피드백을 바탕으로 BGE는 1.0 버전을 기반으로 더욱 최적화되어 성능을 더욱 안정적이고 탁월하게 만들었습니다. 구체적인 업그레이드 내용은 다음과 같습니다.
모델 업데이트. BGE-*-zh-v1.5는 훈련 데이터를 필터링하고, 품질이 낮은 데이터를 삭제하고, 훈련 중 온도 계수를 0.02로 높여 유사성 값을 보다 안정적으로 만들어 유사성 분포 문제를 완화합니다.
새 모델이 추가되었습니다. 오픈 소스 BGE-reranker 크로스 인코더 모델은 관련 텍스트를 보다 정확하게 찾을 수 있으며 중국어 및 영어 이중 언어를 지원합니다. 벡터를 출력해야 하는 벡터 모델과 달리 BGE-reranker는 텍스트 쌍 간의 유사성을 직접 출력하며 순위 정확도가 더 높으며 벡터 리콜 결과를 재정렬하고 최종 결과의 관련성을 높이는 데 사용할 수 있습니다.
- 새로운 기능. BGE1.1에는 음수가 어려운 샘플 마이닝 스크립트가 추가되어 미세 조정 중 지침을 추가하는 기능이 미세 조정 모델에 추가되어 검색 효과가 효과적으로 향상됩니다. 저장은 자동으로 문장 변환기 형식으로 변환되므로 모델을 더 쉽게 로드할 수 있습니다.
- 최근 Zhiyuan과 Hugging Face가 C-Pack을 사용하여 중국 보편적 의미 벡터 모델을 향상시킬 것을 제안하는 기술 보고서를 발표했다는 점은 언급할 가치가 있습니다.
- "C-Pack: 일반 중국어 임베딩을 발전시키기 위한 패키지 리소스"
링크: https://arxiv.org/pdf/2309.07597.pdf
개발자 커뮤니티에서 높은 인기 얻기
BGE는 출시 이후 대규모 모델 개발자 커뮤니티의 주목을 받았습니다. 현재 Hugging Face는 수십만 번 다운로드되었으며 LangChain, LangChain-Chachat, llama_index 등
Langchain 관계자, LangChain 공동 창립자 겸 CEO Harrison Chase, Deep Trading 창립자 Yam Peleg 및 기타 커뮤니티 영향력자들은 BGE에 대한 우려를 표명했습니다.
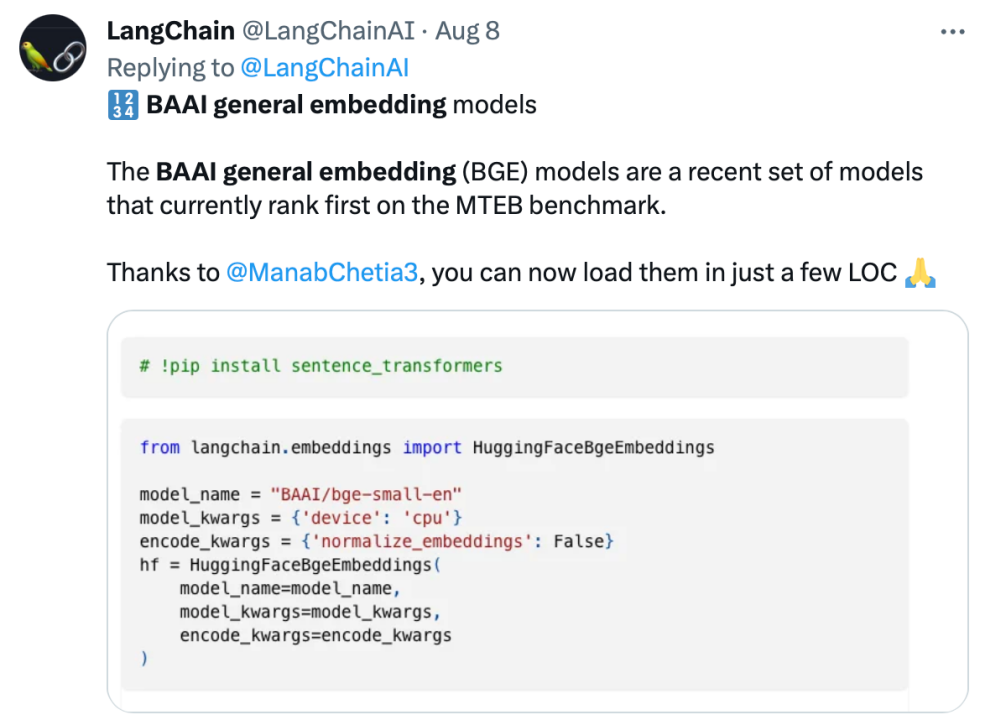
오픈 소스와 개방성을 고수하고 협력적 혁신을 촉진하는 Zhiyuan 대형 모델 기술 개발 시스템 FlagOpen BGE는 Embedding 기술과 모델에 초점을 맞춘 새로운 FlagEmbedding 섹션을 추가했습니다. BGE는 주목받는 오픈 소스 프로젝트 중 하나입니다. FlagOpen은 대형 모델 시대의 인공지능 기술 인프라 구축에 최선을 다하고 있으며, 앞으로도 더욱 완성도 높은 대형 모델 풀스택 기술을 학계와 산업계에 지속적으로 공개해 나갈 예정입니다
위 내용은 Zhiyuan은 3억 개의 의미 벡터 모델 학습 데이터를 공개했으며 BGE 모델은 계속해서 반복적으로 업데이트됩니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

Video Face Swap
완전히 무료인 AI 얼굴 교환 도구를 사용하여 모든 비디오의 얼굴을 쉽게 바꾸세요!

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7664
7664
 15
1393
52
1205
24
91
11
73
19
15
1393
52
1205
24
91
11
73
19

 Web3 Trading Platform Ranking_Web3 글로벌 교환 상위 10 개 요약
Apr 21, 2025 am 10:45 AM
Web3 Trading Platform Ranking_Web3 글로벌 교환 상위 10 개 요약
Apr 21, 2025 am 10:45 AM
Binance는 Global Digital Asset Trading Ecosystem의 대 군주이며, 그 특성에는 다음이 포함됩니다. 1. 평균 일일 거래량은 1,500 억 달러를 초과하여 주류 통화의 98%를 차지하며 500 개의 거래 쌍을 지원합니다. 2. 혁신 매트릭스는 파생 상품 시장, Web3 레이아웃 및 교육 시스템을 포함합니다. 3. 기술적 이점은 밀리 초에 일치하는 엔진이며, 최고 처리량은 초당 140 만 건의 트랜잭션입니다. 4. 규정 준수 진행 상황은 15 개국 라이센스를 보유하고 있으며 유럽과 미국에 준수 엔티티를 설립합니다.
 ETH 업그레이드 후 손실을 피하는 방법
Apr 21, 2025 am 10:03 AM
ETH 업그레이드 후 손실을 피하는 방법
Apr 21, 2025 am 10:03 AM
ETH 업그레이드 후, 초보자는 손실을 피하기 위해 다음 전략을 채택해야합니다. 1. 숙제를하고 기본 지식과 ETH의 업그레이드 내용을 이해합니다. 2. 통제 위치, 소량으로 물을 테스트하고 투자를 다각화합니다. 3. 거래 계획을 세우고 목표를 명확하게하고 중지 손실 지점을 설정하십시오. 4. 합리적으로 프로파일 링하고 정서적 의사 결정을 피하십시오. 5. 공식적이고 안정적인 거래 플랫폼을 선택하십시오. 6. 단기 변동의 영향을 피하기 위해 장기 보유를 고려하십시오.
 Top 10 Cryptocurrency Exchange 플랫폼 세계 최대의 디지털 환전 목록
Apr 21, 2025 pm 07:15 PM
Top 10 Cryptocurrency Exchange 플랫폼 세계 최대의 디지털 환전 목록
Apr 21, 2025 pm 07:15 PM
거래소는 오늘날의 cryptocurrency 시장에서 중요한 역할을합니다. 그들은 투자자들이 거래 할 수있는 플랫폼 일뿐 만 아니라 시장 유동성 및 가격 발견의 중요한 원천이기도합니다. 세계 최대의 가상 환전 거래소는 상위 10 위이며, 이러한 거래소는 거래량이 훨씬 앞서있을뿐만 아니라 사용자 경험, 보안 및 혁신적인 서비스에서 고유 한 장점이 있습니다. 목록 위에있는 교환은 일반적으로 대규모 사용자 기반과 광범위한 시장 영향을 미치며 거래량 및 자산 유형은 종종 다른 거래소에서 도달하기가 어렵습니다.
 크로스 체인 거래는 무엇을 의미합니까? 크로스 체인 거래는 무엇입니까?
Apr 21, 2025 pm 11:39 PM
크로스 체인 거래는 무엇을 의미합니까? 크로스 체인 거래는 무엇입니까?
Apr 21, 2025 pm 11:39 PM
크로스 체인 거래를 지원하는 교환 : 1. Binance, 2. Uniswap, 3. Sushiswap, 4. Curve Finance, 5. Thorchain, 6. 1inch Exchange, 7. DLN 거래,이 플랫폼은 다양한 기술을 통해 다중 체인 자산 거래를 지원합니다.
 환전 회계의 상위 10 개 플랫폼은 무엇입니까?
Apr 21, 2025 pm 12:21 PM
환전 회계의 상위 10 개 플랫폼은 무엇입니까?
Apr 21, 2025 pm 12:21 PM
최고 거래소에는 다음이 포함됩니다. 1. 세계 최대의 거래량 인 Binance는 600 개의 통화를 지원하며 스팟 취급 수수료는 0.1%입니다. 2. 균형 잡힌 플랫폼 인 OKX는 708 개의 거래 쌍을 지원하며 영구 계약 처리 수수료는 0.05%입니다. 3. Gate.io, 2700 개의 소규모 통화를 포괄하며 스팟 취급 수수료는 0.1%-0.3%입니다. 4. Coinbase, 미국 규정 준수 벤치 마크, 스팟 취급 수수료는 0.5%입니다. 5. Kraken, 최고 보안 및 정기 예약 감사.
 통화에서 레버리지 교환 순위 순위 서클 통화 서클에서 상위 10 개의 레버리지 거래소의 최신 권장 사항
Apr 21, 2025 pm 11:24 PM
통화에서 레버리지 교환 순위 순위 서클 통화 서클에서 상위 10 개의 레버리지 거래소의 최신 권장 사항
Apr 21, 2025 pm 11:24 PM
2025 년에 레버리지 거래, 보안 및 사용자 경험에서 뛰어난 성능을 보이는 플랫폼은 다음과 같습니다. 1. OKX, 고주파 거래자에게 적합하여 최대 100 배의 레버리지를 제공합니다. 2. Binance, 전 세계의 다중 통화 거래자에게 적합하며 125 배 높은 레버리지를 제공합니다. 3. Gate.io, 전문 파생 상품 플레이어에게 적합하며 100 배의 레버리지를 제공합니다. 4. 초보자 및 소셜 트레이더에게 적합한 Bitget, 최대 100 배의 레버리지를 제공합니다. 5. 크라켄은 꾸준한 투자자에게 적합하며 5 배의 레버리지를 제공합니다. 6. Bybit, Altcoin Explorers에 적합하며 20 배의 레버리지를 제공합니다. 7. 저비용 거래자에게 적합한 Kucoin, 10 배의 레버리지를 제공합니다. 8. 비트 피 넥스, 시니어 플레이에 적합합니다
 가상 통화 가격의 상승 또는 하락은 왜입니까? 가상 통화 가격의 상승 또는 하락은 왜입니까?
Apr 21, 2025 am 08:57 AM
가상 통화 가격의 상승 또는 하락은 왜입니까? 가상 통화 가격의 상승 또는 하락은 왜입니까?
Apr 21, 2025 am 08:57 AM
가상 통화 가격 상승의 요인은 다음과 같습니다. 1. 시장 수요 증가, 2. 공급 감소, 3. 긍정적 인 뉴스, 4. 낙관적 시장 감정, 5. 거시 경제 환경; 감소 요인에는 다음이 포함됩니다. 1. 시장 수요 감소, 2. 공급 증가, 3. 부정적인 뉴스의 파업, 4. 비관적 시장 감정, 5. 거시 경제 환경.
 'Black Monday Sell'은 Cryptocurrency 업계의 힘든 날입니다.
Apr 21, 2025 pm 02:48 PM
'Black Monday Sell'은 Cryptocurrency 업계의 힘든 날입니다.
Apr 21, 2025 pm 02:48 PM
cryptocurrency 시장의 급락으로 인해 투자자들 사이에 공황이 발생했으며 Dogecoin (Doge)은 가장 어려운 지역 중 하나가되었습니다. 가격은 급격히 하락했으며 분산 금융 (DEFI) (TVL)의 총 가치 잠금 장치도 크게 감소했습니다. "Black Monday"의 판매 물결은 cryptocurrency 시장을 휩쓸었고 Dogecoin은 처음으로 타격을 받았습니다. DefitVl은 2023 년 수준으로 떨어졌고 지난 달 통화 가격은 23.78% 하락했습니다. Dogecoin의 Defitvl은 주로 SOSO 가치 지수의 26.37% 감소로 인해 272 만 달러로 떨어졌습니다. 지루한 Dao 및 Thorchain과 같은 다른 주요 Defi 플랫폼도 TVL도 각각 24.04% 및 20으로 떨어졌습니다.
