

일반적으로 사용되는 9가지 Python 기능 중요도 분석 방법

특성 중요도 분석은 예측 시 각 특성(변수 또는 입력)의 유용성이나 가치를 이해하는 데 사용됩니다. 모델 출력에 가장 큰 영향을 미치는 가장 중요한 특징을 식별하는 것이 목표이며, 머신러닝에서 자주 사용되는 방법입니다.
특성 중요도 분석이 중요한 이유는 무엇인가요?
수십 또는 수백 개의 특성이 포함된 데이터 세트가 있는 경우 각 특성은 기계 학습 모델의 성능에 기여할 수 있습니다. 그러나 모든 기능이 동일하게 생성되는 것은 아닙니다. 일부는 중복되거나 관련성이 없을 수 있으며, 이로 인해 모델링 복잡성이 증가하고 과적합이 발생할 수 있습니다.
기능 중요도 분석은 가장 유용한 기능을 식별하고 이에 집중할 수 있으므로 다음과 같은 이점이 있습니다. 1. 통찰력 제공: 특징의 중요성을 분석함으로써 데이터의 어떤 특징이 결과에 가장 큰 영향을 미치는지에 대한 통찰력을 얻을 수 있으므로 데이터의 성격을 더 잘 이해하는 데 도움이 됩니다. 2. 모델 최적화: 주요 기능을 식별함으로써 모델 성능을 최적화하고 불필요한 컴퓨팅 및 스토리지 오버헤드를 줄이며 모델의 훈련 및 예측 효율성을 향상시킬 수 있습니다. 3. 특징 선택: 특징 중요도 분석은 예측력이 가장 높은 특징을 선택하는 데 도움이 되므로 모델의 정확도와 일반화 능력이 향상됩니다. 4. 모델 설명: 특성 중요도 분석은 모델의 예측 결과를 설명하고, 모델 이면의 패턴과 인과 관계를 밝히고, 모델의 해석성을 향상시키는 데도 도움이 됩니다. 함께
- 더 빠른 학습 및 추론
- 향상된 해석 가능성
- Python에서 기능 중요도 분석의 몇 가지 방법을 자세히 살펴보겠습니다.
- Feature 중요도 분석 방법
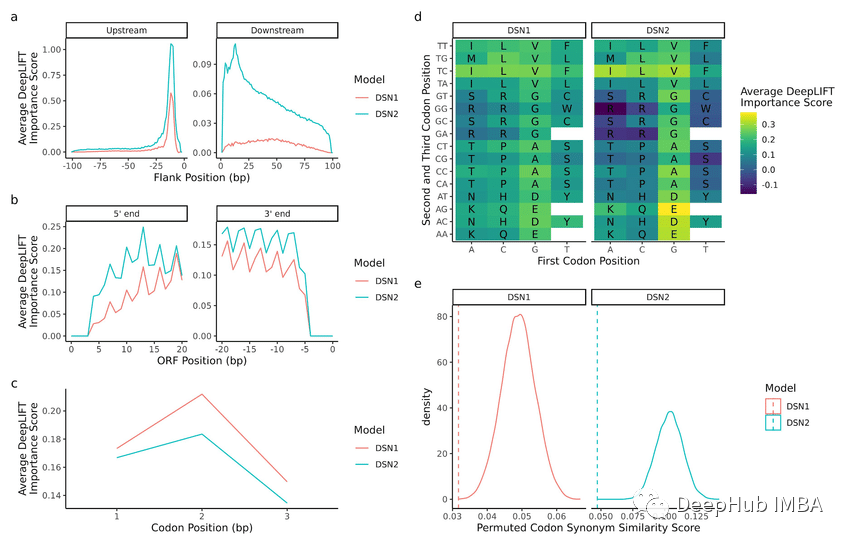
1. Permutation Importance PermutationImportance
이 방법은 각 특성의 값을 무작위로 배열한 후 모델 성능 저하 정도를 모니터링합니다. 감소량이 클수록 특성이 더 중요하다는 의미입니다from sklearn.datasets import load_breast_cancer from sklearn.ensemble import RandomForestClassifier from sklearn.inspection import permutation_importance from sklearn.model_selection import train_test_split import matplotlib.pyplot as plt cancer = load_breast_cancer() X_train, X_test, y_train, y_test = train_test_split(cancer.data, cancer.target, random_state=1) rf = RandomForestClassifier(n_estimators=100, random_state=1) rf.fit(X_train, y_train) baseline = rf.score(X_test, y_test) result = permutation_importance(rf, X_test, y_test, n_repeats=10, random_state=1, scoring='accuracy') importances = result.importances_mean # Visualize permutation importances plt.bar(range(len(importances)), importances) plt.xlabel('Feature Index') plt.ylabel('Permutation Importance') plt.show()로그인 후 복사
from sklearn.datasets import load_breast_cancer from sklearn.ensemble import RandomForestClassifier from sklearn.inspection import permutation_importance from sklearn.model_selection import train_test_split import matplotlib.pyplot as plt cancer = load_breast_cancer() X_train, X_test, y_train, y_test = train_test_split(cancer.data, cancer.target, random_state=1) rf = RandomForestClassifier(n_estimators=100, random_state=1) rf.fit(X_train, y_train) baseline = rf.score(X_test, y_test) result = permutation_importance(rf, X_test, y_test, n_repeats=10, random_state=1, scoring='accuracy') importances = result.importances_mean # Visualize permutation importances plt.bar(range(len(importances)), importances) plt.xlabel('Feature Index') plt.ylabel('Permutation Importance') plt.show()2. 내장된 특성 중요도(coef_ 또는 feature_importances_)
선형 회귀 및 랜덤 포레스트와 같은 일부 모델은 다음을 수행할 수 있습니다. 특성 중요도 점수를 직접 출력합니다. 이는 최종 예측에 대한 각 기능의 기여도를 보여줍니다.
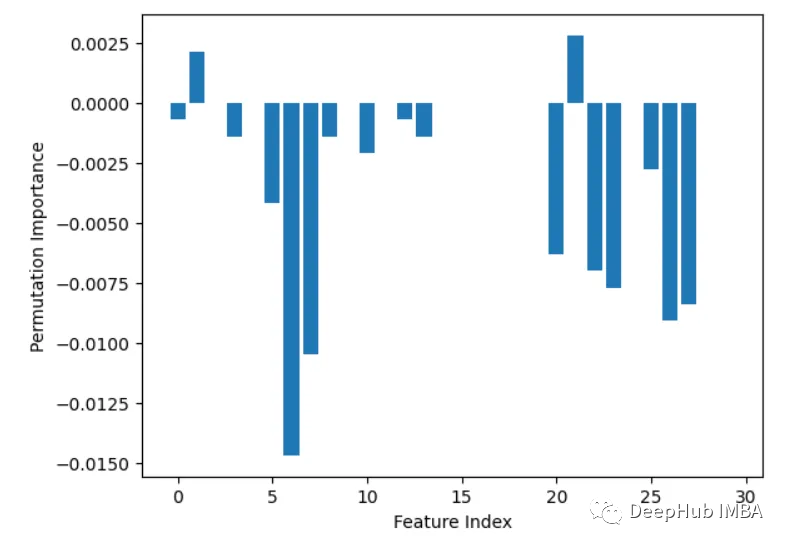
from sklearn.datasets import load_breast_cancer from sklearn.ensemble import RandomForestClassifier X, y = load_breast_cancer(return_X_y=True) rf = RandomForestClassifier(n_estimators=100, random_state=1) rf.fit(X, y) importances = rf.feature_importances_ # Plot importances plt.bar(range(X.shape[1]), importances) plt.xlabel('Feature Index') plt.ylabel('Feature Importance') plt.show()3, Leave-one-out
한 번에 하나의 특징을 반복적으로 제거하고 정확성을 평가합니다.
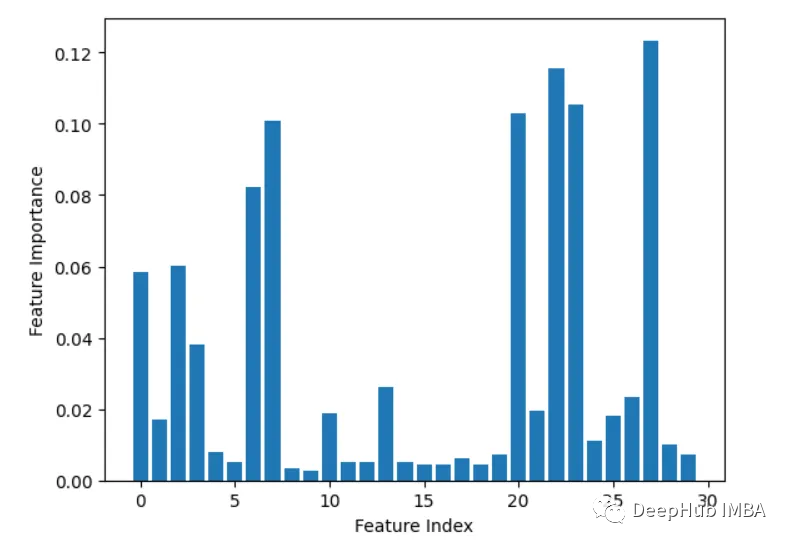
from sklearn.datasets import load_breast_cancer from sklearn.model_selection import train_test_split from sklearn.ensemble import RandomForestClassifier from sklearn.metrics import accuracy_score import matplotlib.pyplot as plt import numpy as np # Load sample data X, y = load_breast_cancer(return_X_y=True) # Split data into train and test sets X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=1) # Train a random forest model rf = RandomForestClassifier(n_estimators=100, random_state=1) rf.fit(X_train, y_train) # Get baseline accuracy on test data base_acc = accuracy_score(y_test, rf.predict(X_test)) # Initialize empty list to store importances importances = [] # Iterate over all columns and remove one at a time for i in range(X_train.shape[1]):X_temp = np.delete(X_train, i, axis=1)rf.fit(X_temp, y_train)acc = accuracy_score(y_test, rf.predict(np.delete(X_test, i, axis=1)))importances.append(base_acc - acc) # Plot importance scores plt.bar(range(len(importances)), importances) plt.show()
4. 상관 분석
다시 작성해야 할 것은: 특성과 대상 변수 간의 상관 관계를 계산하는 것입니다. 상관 관계가 높을수록 특성이 더 중요합니다
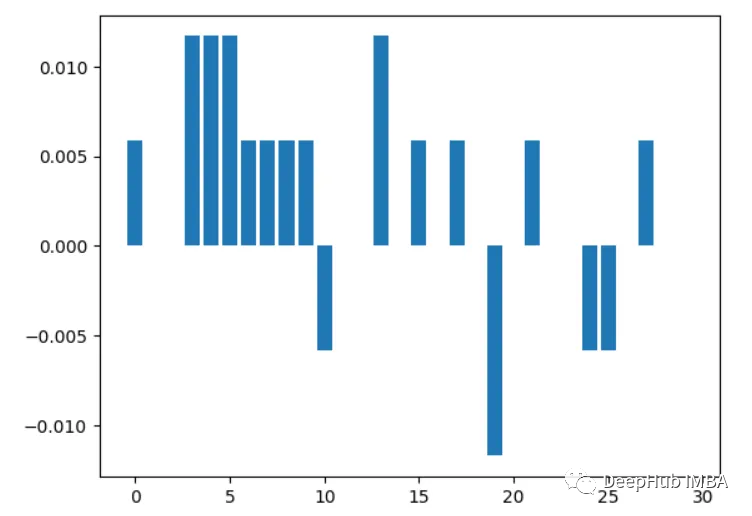
import pandas as pd from sklearn.datasets import load_breast_cancer X, y = load_breast_cancer(return_X_y=True) df = pd.DataFrame(X, columns=range(30)) df['y'] = y correlations = df.corrwith(df.y).abs() correlations.sort_values(ascending=False, inplace=True) correlations.plot.bar()
5. 재귀적 특징 제거
재귀적으로 특징을 제거하고 모델 성능에 어떤 영향을 미치는지 확인하세요. 제거 시 더 큰 방울이 발생하는 기능이 더 중요합니다.
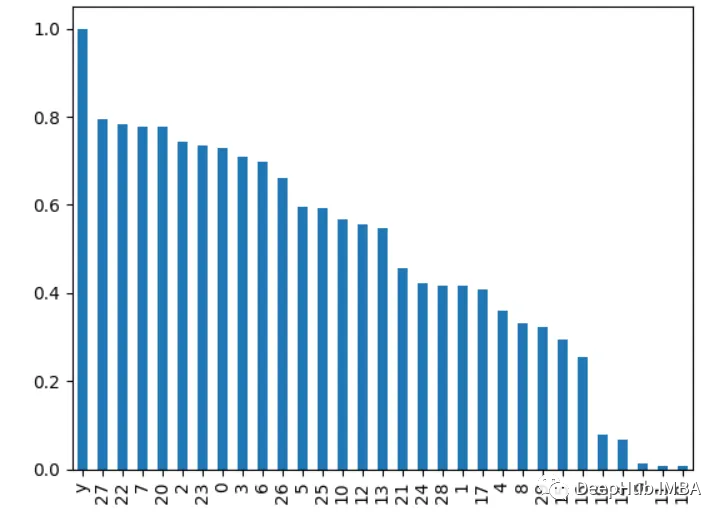
from sklearn.ensemble import RandomForestClassifier from sklearn.feature_selection import RFE import pandas as pd from sklearn.datasets import load_breast_cancer import matplotlib.pyplot as plt X, y = load_breast_cancer(return_X_y=True) df = pd.DataFrame(X, columns=range(30)) df['y'] = y rf = RandomForestClassifier() rfe = RFE(rf, n_features_to_select=10) rfe.fit(X, y) print(rfe.ranking_)
출력은 [6 4 11 12 7 11 18 21 8 16 10 3 15 14 19 17 20 13 11 11 12 9 11 5 11]
6입니다.
계산하다 one 데이터를 분할할 때 모든 트리에서 기능이 사용되는 횟수입니다. 분할이 많을수록 중요합니다import xgboost as xgb import pandas as pd from sklearn.datasets import load_breast_cancer import matplotlib.pyplot as plt X, y = load_breast_cancer(return_X_y=True) df = pd.DataFrame(X, columns=range(30)) df['y'] = y model = xgb.XGBClassifier() model.fit(X, y) importances = model.feature_importances_ importances = pd.Series(importances, index=range(X.shape[1])) importances.plot.bar()
7. 주성분 분석 PCA
특징에 대한 주성분 분석을 수행하고 각 주성분의 설명된 분산 비율을 살펴보세요. 처음 몇 개의 구성 요소에 더 높은 부하가 걸리는 특성이 더 중요합니다.
from sklearn.decomposition import PCA import pandas as pd from sklearn.datasets import load_breast_cancer import matplotlib.pyplot as plt X, y = load_breast_cancer(return_X_y=True) df = pd.DataFrame(X, columns=range(30)) df['y'] = y pca = PCA() pca.fit(X) plt.bar(range(pca.n_components_), pca.explained_variance_ratio_) plt.xlabel('PCA components') plt.ylabel('Explained Variance')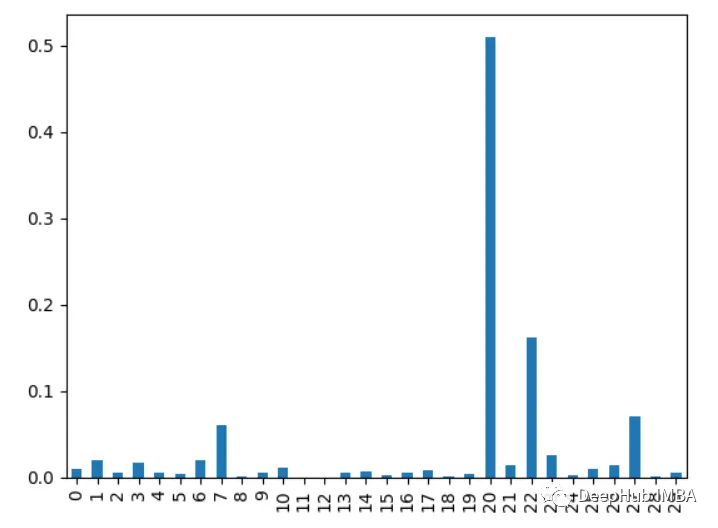
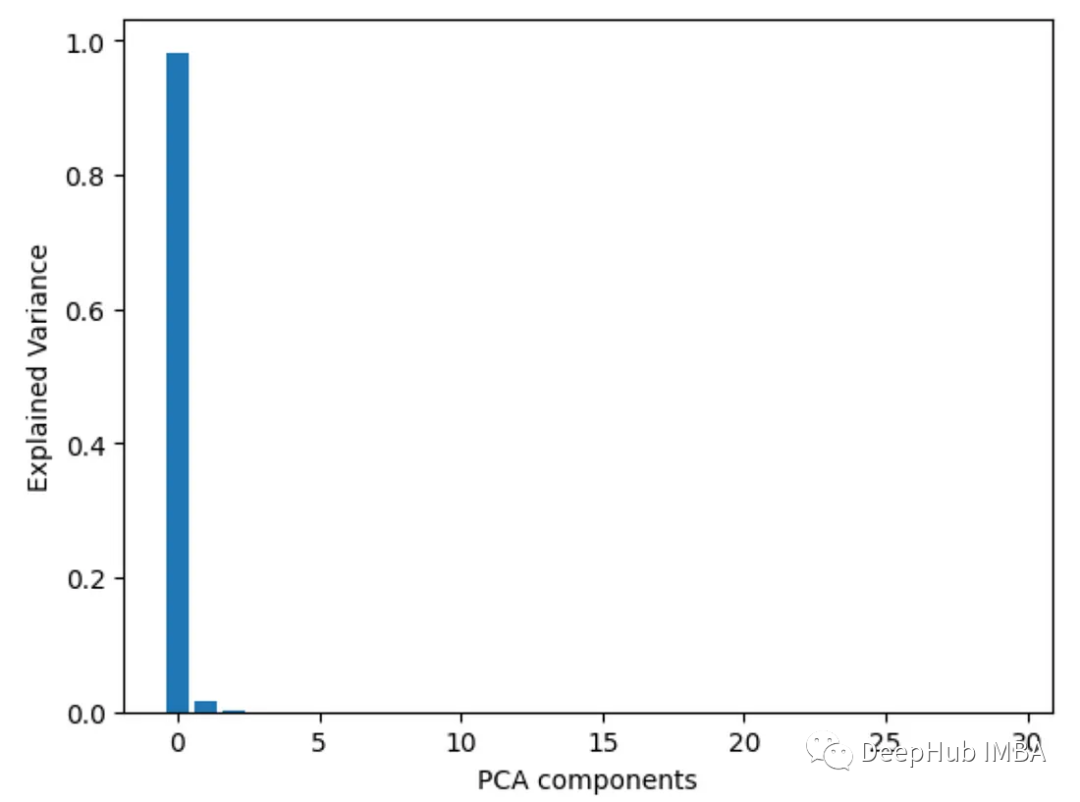
8. 분산 분산 분석
f_classif()를 사용하여 각 특성의 분산 f 값 분석을 얻습니다. f 값이 높을수록 특징과 목표 간의 상관 관계가 더 강해집니다.
from sklearn.feature_selection import f_classif import pandas as pd from sklearn.datasets import load_breast_cancer import matplotlib.pyplot as plt X, y = load_breast_cancer(return_X_y=True) df = pd.DataFrame(X, columns=range(30)) df['y'] = y fval = f_classif(X, y) fval = pd.Series(fval[0], index=range(X.shape[1])) fval.plot.bar()
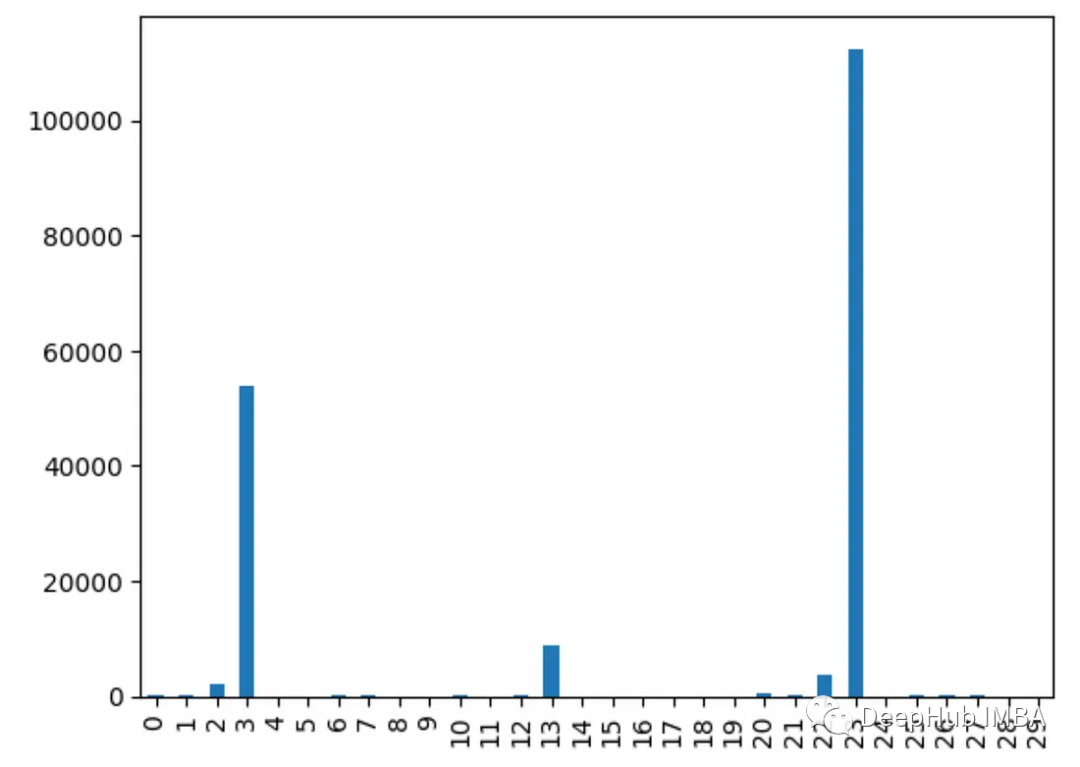
9. 카이제곱 테스트
chi2() 함수를 사용하여 각 특성의 카이제곱 통계를 구합니다. 점수가 높은 기능은 대상 변수에 독립적일 가능성이 더 높습니다
from sklearn.feature_selection import chi2 import pandas as pd from sklearn.datasets import load_breast_cancer import matplotlib.pyplot as plt X, y = load_breast_cancer(return_X_y=True) df = pd.DataFrame(X, columns=range(30)) df['y'] = y chi_scores = chi2(X, y) chi_scores = pd.Series(chi_scores[0], index=range(X.shape[1])) chi_scores.plot.bar()
为什么不同的方法会检测到不同的特征?
由于不同的特征重要性方法,有时可以确定哪些特征是最重要的
1、他们用不同的方式衡量重要性:
有的使用不同特特征进行预测,监控精度下降
像XGBOOST或者回归模型使用内置重要性来进行特征的重要性排序
而PCA着眼于方差解释
2、不同模型有不同模型的方法:
线性模型偏向于处理线性关系,而树模型则更倾向于捕捉接近根节点的特征
3、交互作用:
有些方法可以获取特征之间的相互关系,而有些方法则不行,这会导致结果的不同
3、不稳定:
使用不同的数据子集,重要性值可能在同一方法的不同运行中有所不同,这是因为数据差异决定的
4、Hyperparameters:
通过调整超参数,例如主成分分析(PCA)组件或决策树的深度,也会对结果产生影响
所以不同的假设、偏差、数据处理和方法的可变性意味着它们并不总是在最重要的特征上保持一致。
选择特征重要性分析方法的一些最佳实践
- 尝试多种方法以获得更健壮的视图
- 聚合结果的集成方法
- 更多地关注相对顺序,而不是绝对值
- 差异并不一定意味着有问题,检查差异的原因会对数据和模型有更深入的了解
위 내용은 일반적으로 사용되는 9가지 Python 기능 중요도 분석 방법의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7569
7569
 15
1386
52
87
11
61
19
28
107
15
1386
52
87
11
61
19
28
107

 PHP 및 Python : 코드 예제 및 비교
Apr 15, 2025 am 12:07 AM
PHP 및 Python : 코드 예제 및 비교
Apr 15, 2025 am 12:07 AM
PHP와 Python은 고유 한 장점과 단점이 있으며 선택은 프로젝트 요구와 개인 선호도에 달려 있습니다. 1.PHP는 대규모 웹 애플리케이션의 빠른 개발 및 유지 보수에 적합합니다. 2. Python은 데이터 과학 및 기계 학습 분야를 지배합니다.
 Python vs. JavaScript : 커뮤니티, 라이브러리 및 리소스
Apr 15, 2025 am 12:16 AM
Python vs. JavaScript : 커뮤니티, 라이브러리 및 리소스
Apr 15, 2025 am 12:16 AM
Python과 JavaScript는 커뮤니티, 라이브러리 및 리소스 측면에서 고유 한 장점과 단점이 있습니다. 1) Python 커뮤니티는 친절하고 초보자에게 적합하지만 프론트 엔드 개발 리소스는 JavaScript만큼 풍부하지 않습니다. 2) Python은 데이터 과학 및 기계 학습 라이브러리에서 강력하며 JavaScript는 프론트 엔드 개발 라이브러리 및 프레임 워크에서 더 좋습니다. 3) 둘 다 풍부한 학습 리소스를 가지고 있지만 Python은 공식 문서로 시작하는 데 적합하지만 JavaScript는 MDNWebDocs에서 더 좋습니다. 선택은 프로젝트 요구와 개인적인 이익을 기반으로해야합니다.
 터미널 VSCODE에서 프로그램을 실행하는 방법
Apr 15, 2025 pm 06:42 PM
터미널 VSCODE에서 프로그램을 실행하는 방법
Apr 15, 2025 pm 06:42 PM
vs 코드에서는 다음 단계를 통해 터미널에서 프로그램을 실행할 수 있습니다. 코드를 준비하고 통합 터미널을 열어 코드 디렉토리가 터미널 작업 디렉토리와 일치하는지 확인하십시오. 프로그래밍 언어 (예 : Python의 Python Your_file_name.py)에 따라 실행 명령을 선택하여 성공적으로 실행되는지 여부를 확인하고 오류를 해결하십시오. 디버거를 사용하여 디버깅 효율을 향상시킵니다.
 Python에서 비주얼 스튜디오 코드를 사용할 수 있습니다
Apr 15, 2025 pm 08:18 PM
Python에서 비주얼 스튜디오 코드를 사용할 수 있습니다
Apr 15, 2025 pm 08:18 PM
VS 코드는 파이썬을 작성하는 데 사용될 수 있으며 파이썬 애플리케이션을 개발하기에 이상적인 도구가되는 많은 기능을 제공합니다. 사용자는 다음을 수행 할 수 있습니다. Python 확장 기능을 설치하여 코드 완료, 구문 강조 및 디버깅과 같은 기능을 얻습니다. 디버거를 사용하여 코드를 단계별로 추적하고 오류를 찾아 수정하십시오. 버전 제어를 위해 git을 통합합니다. 코드 서식 도구를 사용하여 코드 일관성을 유지하십시오. 라인 도구를 사용하여 잠재적 인 문제를 미리 발견하십시오.
 Docker 원리에 대한 자세한 설명
Apr 14, 2025 pm 11:57 PM
Docker 원리에 대한 자세한 설명
Apr 14, 2025 pm 11:57 PM
Docker는 Linux 커널 기능을 사용하여 효율적이고 고립 된 응용 프로그램 실행 환경을 제공합니다. 작동 원리는 다음과 같습니다. 1. 거울은 읽기 전용 템플릿으로 사용되며, 여기에는 응용 프로그램을 실행하는 데 필요한 모든 것을 포함합니다. 2. Union 파일 시스템 (Unionfs)은 여러 파일 시스템을 스택하고 차이점 만 저장하고 공간을 절약하고 속도를 높입니다. 3. 데몬은 거울과 컨테이너를 관리하고 클라이언트는 상호 작용을 위해 사용합니다. 4. 네임 스페이스 및 CGroup은 컨테이너 격리 및 자원 제한을 구현합니다. 5. 다중 네트워크 모드는 컨테이너 상호 연결을 지원합니다. 이러한 핵심 개념을 이해 함으로써만 Docker를 더 잘 활용할 수 있습니다.
 VScode 확장자가 악의적입니까?
Apr 15, 2025 pm 07:57 PM
VScode 확장자가 악의적입니까?
Apr 15, 2025 pm 07:57 PM
VS 코드 확장은 악의적 인 코드 숨기기, 취약성 악용 및 합법적 인 확장으로 자위하는 등 악성 위험을 초래합니다. 악의적 인 확장을 식별하는 방법에는 게시자 확인, 주석 읽기, 코드 확인 및주의해서 설치가 포함됩니다. 보안 조치에는 보안 인식, 좋은 습관, 정기적 인 업데이트 및 바이러스 백신 소프트웨어도 포함됩니다.
 Windows 8에서 코드를 실행할 수 있습니다
Apr 15, 2025 pm 07:24 PM
Windows 8에서 코드를 실행할 수 있습니다
Apr 15, 2025 pm 07:24 PM
VS 코드는 Windows 8에서 실행될 수 있지만 경험은 크지 않을 수 있습니다. 먼저 시스템이 최신 패치로 업데이트되었는지 확인한 다음 시스템 아키텍처와 일치하는 VS 코드 설치 패키지를 다운로드하여 프롬프트대로 설치하십시오. 설치 후 일부 확장은 Windows 8과 호환되지 않을 수 있으며 대체 확장을 찾거나 가상 시스템에서 새로운 Windows 시스템을 사용해야합니다. 필요한 연장을 설치하여 제대로 작동하는지 확인하십시오. Windows 8에서는 VS 코드가 가능하지만 더 나은 개발 경험과 보안을 위해 새로운 Windows 시스템으로 업그레이드하는 것이 좋습니다.
 파이썬 : 자동화, 스크립팅 및 작업 관리
Apr 16, 2025 am 12:14 AM
파이썬 : 자동화, 스크립팅 및 작업 관리
Apr 16, 2025 am 12:14 AM
파이썬은 자동화, 스크립팅 및 작업 관리가 탁월합니다. 1) 자동화 : 파일 백업은 OS 및 Shutil과 같은 표준 라이브러리를 통해 실현됩니다. 2) 스크립트 쓰기 : PSUTIL 라이브러리를 사용하여 시스템 리소스를 모니터링합니다. 3) 작업 관리 : 일정 라이브러리를 사용하여 작업을 예약하십시오. Python의 사용 편의성과 풍부한 라이브러리 지원으로 인해 이러한 영역에서 선호하는 도구가됩니다.
