

Python에서 학생 잔차를 계산하는 방법은 무엇입니까?

학생 잔차는 회귀 분석에서 데이터의 잠재적 이상값을 식별하는 데 자주 사용됩니다. 이상값은 데이터의 전체 추세와 크게 다르며 적합 모델에 상당한 영향을 미칠 수 있는 점입니다. 이상값을 식별하고 분석하면 데이터의 기본 패턴을 더 잘 이해하고 모델의 정확도를 높일 수 있습니다. 이번 글에서는 스튜던트화 잔차(Studentized Residual)와 이를 파이썬으로 구현하는 방법에 대해 자세히 살펴보겠습니다.
학생잔차란 무엇인가요?
"학생화 잔차"라는 용어는 표준 편차를 추정치로 나눈 특정 잔차 클래스를 의미합니다. 회귀 분석 잔차는 반응 변수의 관측값과 모델에서 생성된 기대값 간의 차이를 설명합니다. 적합 모델에 큰 영향을 미칠 수 있는 데이터의 이상값을 찾기 위해 스튜던트화 잔차가 사용되었습니다.
다음 공식은 일반적으로 스튜던트화 잔차를 계산하는 데 사용됩니다. -
으아악"잔차"는 관찰된 반응 값과 예상 반응 값의 차이를 나타내고, "잔차 표준 편차"는 잔차 표준 편차의 추정치를 나타내며, "hii"는 각 데이터 포인트에 대한 레버리지 계수를 나타냅니다.
Python을 사용하여 학생화 잔차 계산
statsmodels 패키지는 Python에서 스튜던트화 잔차를 계산하는 데 사용할 수 있습니다. 예를 들어 다음을 고려하십시오 -
문법
으아악OLSResults는 statsmodels의 ols() 메서드를 사용하여 피팅된 선형 모델을 나타냅니다.
으아악여기서 "등급"과 "점수"는 단순 선형 회귀를 나타냅니다.
알고리즘
numpy, pandas, Statsmodel API를 가져옵니다.
데이터세트를 만듭니다.
데이터세트에서 간단한 선형 회귀 모델을 수행합니다.
학생화 잔차를 계산하세요.
학생 잔차를 인쇄하세요.
예
다음은 scikit-posthocs 라이브러리를 사용하여 Dunn의 테스트를 실행하는 데모입니다. -
으아악다음으로 statsmodels OLS 클래스를 사용하여 선형 회귀 모델을 만듭니다. -
으아악이상치 테스트() 방법을 사용하여 데이터세트의 각 관측값에 대한 스튜던트화 잔차를 DataFrame에서 생성할 수 있습니다. -
으아악출력
으아악학생화 잔차에 대한 예측 변수 값을 빠르게 플롯할 수도 있습니다. -
문법
으아악여기에서는 matpotlib 라이브러리를 사용하여 색상 = '검은색' 및 라이프스타일 = '--'으로 차트를 그립니다.
알고리즘
matplotlib의 pyplot 라이브러리 가져오기
예측 변수 값 정의
학생 잔차 정의
예측 변수와 스튜던트화 잔차의 산점도 만들기
예
으아악출력
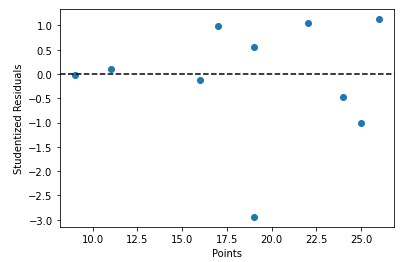
결론
가능한 데이터 이상값을 식별하고 평가합니다. 스튜던트화 잔차를 조사하면 데이터의 전체 추세에서 크게 벗어나는 점을 찾고 해당 점이 적합 모델에 영향을 미치는 이유를 탐색할 수 있습니다. 중요한 관측값 식별 스튜던트화 잔차를 사용하여 적합 모델에 큰 영향을 미치는 영향력 있는 데이터를 발견하고 평가할 수 있습니다. 레버리지가 높은 지점을 찾으세요. 스튜던트화 잔차를 사용하여 높은 레버리지 지점을 식별할 수 있습니다. 레버리지는 적합 모델에 대한 특정 지점의 영향을 측정한 것입니다. 전반적으로 스튜던트화 잔차를 사용하면 회귀 모델의 성능을 분석하고 개선하는 데 도움이 됩니다.
위 내용은 Python에서 학생 잔차를 계산하는 방법은 무엇입니까?의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7319
7319
 9
1625
14
1349
46
1261
25
1209
29
9
1625
14
1349
46
1261
25
1209
29

 Python의 잔차 분석 기술
Jun 10, 2023 am 08:52 AM
Python의 잔차 분석 기술
Jun 10, 2023 am 08:52 AM
Python은 널리 사용되는 프로그래밍 언어이며 강력한 데이터 분석 및 시각화 기능으로 인해 데이터 과학자와 기계 학습 엔지니어가 선호하는 도구 중 하나입니다. 이러한 응용 프로그램에서 잔차 분석은 모델 정확도를 평가하고 모델 편향을 식별하는 데 사용되는 일반적인 기술입니다. 이 기사에서는 Python에서 잔차 분석 기술을 사용하는 몇 가지 방법을 소개합니다. 잔차 이해 Python의 잔차 분석 기술을 소개하기 전에 먼저 잔차가 무엇인지 이해하겠습니다. 통계에서 잔차는 실제 관찰된 값과 실제 관찰된 값의 차이입니다.
 AssertionError: Python 어설션 오류를 해결하는 방법은 무엇입니까?
Jun 25, 2023 pm 11:07 PM
AssertionError: Python 어설션 오류를 해결하는 방법은 무엇입니까?
Jun 25, 2023 pm 11:07 PM
Python의 어설션은 프로그래머가 코드를 디버그하는 데 유용한 도구입니다. 프로그램의 내부 상태가 기대치를 충족하는지 확인하고 이러한 조건이 거짓인 경우 어설션 오류(AssertionError)를 발생시키는 데 사용됩니다. 개발 프로세스 중에 코드 상태가 예상 결과와 일치하는지 확인하기 위해 테스트 및 디버깅 중에 어설션이 사용됩니다. 이 문서에서는 원인, 해결 방법 및 코드에서 어설션을 올바르게 사용하는 방법에 대해 설명합니다. Assertion 오류 원인 Assertion 오류 통과
 Python에서 취약점 스캐너를 개발하는 방법
Jul 01, 2023 am 08:10 AM
Python에서 취약점 스캐너를 개발하는 방법
Jul 01, 2023 am 08:10 AM
Python을 통해 취약점 스캐너를 개발하는 방법 개요 오늘날 인터넷 보안 위협이 증가하는 환경에서 취약점 스캐너는 네트워크 보안을 보호하는 중요한 도구가 되었습니다. Python은 간결하고 읽기 쉽고 강력하며 다양한 실용적인 도구를 개발하는 데 적합한 인기 있는 프로그래밍 언어입니다. 이 기사에서는 Python을 사용하여 네트워크에 대한 실시간 보호를 제공하는 취약성 스캐너를 개발하는 방법을 소개합니다. 1단계: 스캔 대상 결정 취약점 스캐너를 개발하기 전에 스캔할 대상을 결정해야 합니다. 이는 자체 네트워크일 수도 있고 테스트 권한이 있는 모든 것일 수도 있습니다.
 Python의 계층화된 샘플링 기술
Jun 10, 2023 pm 10:40 PM
Python의 계층화된 샘플링 기술
Jun 10, 2023 pm 10:40 PM
Python의 계층화 샘플링 기법 샘플링은 통계에서 일반적으로 사용되는 데이터 수집 방법으로, 데이터 세트에서 일부 샘플을 선택하여 분석하여 전체 데이터 세트의 특성을 추론할 수 있습니다. 빅데이터 시대에는 데이터의 양이 방대하고, 전체 샘플을 활용해 분석하는 것은 시간 소모적일 뿐만 아니라 경제적으로도 실용적이지 않습니다. 따라서 적절한 샘플링 방법을 선택하면 데이터 분석의 효율성을 높일 수 있습니다. 이 기사에서는 주로 Python의 계층화 샘플링 기술을 소개합니다. 계층화 샘플링이란 무엇입니까? 샘플링에서는 계층화 샘플링
 Linux에서 스크립팅 및 실행을 위해 Python을 사용하는 방법
Oct 05, 2023 am 11:45 AM
Linux에서 스크립팅 및 실행을 위해 Python을 사용하는 방법
Oct 05, 2023 am 11:45 AM
Linux에서 Python을 사용하여 스크립트를 작성하고 실행하는 방법 Linux 운영 체제에서는 Python을 사용하여 다양한 스크립트를 작성하고 실행할 수 있습니다. Python은 스크립팅을 보다 쉽고 효율적으로 만들기 위한 풍부한 라이브러리와 도구를 제공하는 간결하고 강력한 프로그래밍 언어입니다. 아래에서는 Linux에서 스크립트 작성 및 실행을 위해 Python을 사용하는 방법의 기본 단계를 소개하고, Python을 더 잘 이해하고 사용하는 데 도움이 되는 몇 가지 구체적인 코드 예제를 제공합니다. 파이썬 설치
 Python에서 sqrt() 함수 사용
Feb 21, 2024 pm 03:09 PM
Python에서 sqrt() 함수 사용
Feb 21, 2024 pm 03:09 PM
Python에서 sqrt() 함수의 사용법 및 코드 예 1. sqrt() 함수의 기능 및 소개 Python 프로그래밍에서 sqrt() 함수는 math 모듈에 있는 함수이며, 그 기능은 의 제곱근을 계산하는 것입니다. 숫자. 제곱근은 자신을 곱한 숫자가 그 숫자의 제곱과 같다는 것을 의미합니다. 즉, x*x=n이면 x는 n의 제곱근이 됩니다. sqrt() 함수는 프로그램에서 제곱근을 계산하는 데 사용할 수 있습니다. 2. Python, sq에서 sqrt() 함수를 사용하는 방법
 Python에서 지원 벡터 클러스터링 기술을 사용하는 방법은 무엇입니까?
Jun 06, 2023 am 08:00 AM
Python에서 지원 벡터 클러스터링 기술을 사용하는 방법은 무엇입니까?
Jun 06, 2023 am 08:00 AM
SVC(지원 벡터 클러스터링)는 SVM(지원 벡터 머신)을 기반으로 하는 비지도 학습 알고리즘으로, 레이블이 지정되지 않은 데이터 세트에서 클러스터링을 달성할 수 있습니다. Python은 풍부한 기계 학습 라이브러리 및 툴킷 세트를 갖춘 인기 있는 프로그래밍 언어입니다. 이 기사에서는 Python에서 지원 벡터 클러스터링 기술을 사용하는 방법을 소개합니다. 1. 서포트 벡터 클러스터링의 원리 SVC는 서포트 벡터 세트를 기반으로 합니다.
 Python 프로그래밍 실습: Baidu Map API를 사용하여 정적 지도 함수를 생성하는 방법
Jul 30, 2023 pm 09:05 PM
Python 프로그래밍 실습: Baidu Map API를 사용하여 정적 지도 함수를 생성하는 방법
Jul 30, 2023 pm 09:05 PM
Python 프로그래밍 실습: Baidu Map API를 사용하여 정적 지도 기능을 생성하는 방법 소개: 현대 사회에서 지도는 사람들의 삶에 없어서는 안 될 부분이 되었습니다. 지도 작업을 할 때 웹 페이지, 모바일 앱 또는 보고서에 표시하기 위해 특정 영역의 정적 지도를 얻어야 하는 경우가 많습니다. 이 기사에서는 Python 프로그래밍 언어와 Baidu Map API를 사용하여 정적 지도를 생성하는 방법을 소개하고 관련 코드 예제를 제공합니다. 1. 준비작업 Baidu Map API를 이용하여 정적 지도 생성 기능을 구현하기 위해,
