
AI 에이전트는 현재 핫한 분야입니다. OpenAI 응용 연구 책임자인 LilianWeng이 쓴 장문의 글[1]에서 그녀는 에이전트 = LLM + 메모리 + 계획 능력 + 도구 사용
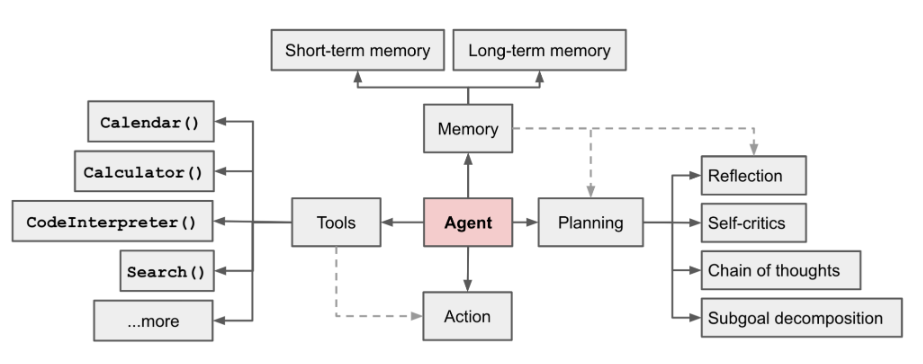
그림 1 LLM 기반 자율 에이전트 시스템 개요
에이전트의 역할은 LLM의 강력한 언어 이해 및 논리적 추론 기능을 사용하여 인간이 작업을 완료하는 데 도움이 되는 도구를 호출하는 것입니다. 그러나 이는 또한 몇 가지 과제를 안겨줍니다. 예를 들어 기본 모델의 능력이 에이전트 호출 도구의 효율성을 결정하지만 기본 모델 자체에는 대형 모델 환상과 같은 문제가 있습니다
이 기사는 "조각 입력"으로 시작됩니다. 복잡한 작업을 자동으로 분할하고 함수를 호출하는 방법'을 예로 들어 기본 Agent 프로세스를 구축하고, '기본 모델 선택', 'Prompt'을 통해 '작업 분할' 및 '함수 호출' 모듈을 성공적으로 구축하는 방법을 중점적으로 설명합니다. 디자인' 등
다시 작성된 내용은 다음과 같습니다. 주소:
https://sota.jiqizhixin.com/project/smart_agent
GitHub 저장소:
무거워야 해 작성된 내용은 다음과 같습니다: https://github.com/zzlgreat/smart_agent
"명령을 입력하여 복잡한 작업 분할 및 함수 호출을 자동으로 구현" 구현을 위해 프로젝트 구축된 에이전트 프로세스는 다음과 같습니다.
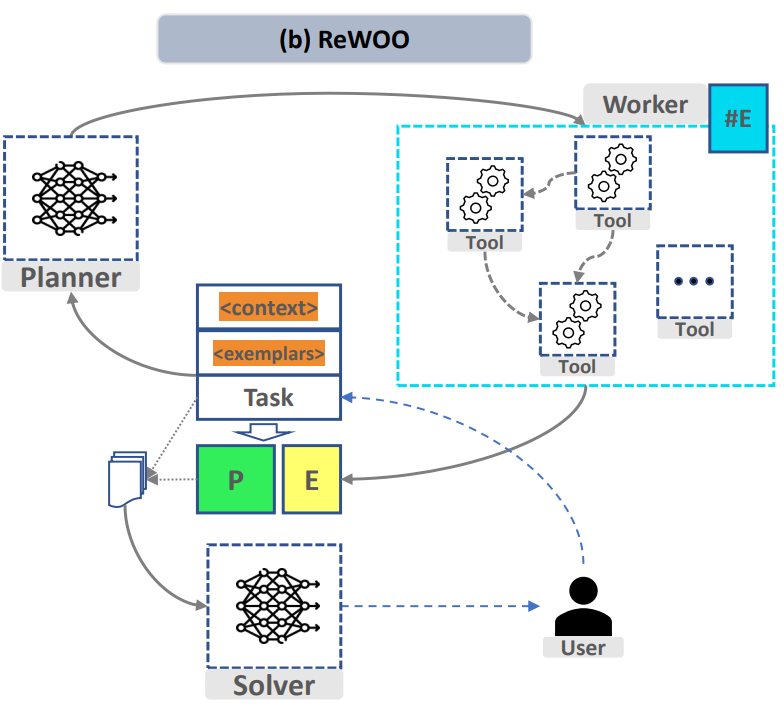
그림 1 "ReWOO: Decoupling Reasoning from Observations for Efficient Augmented Language Models"
위 프로세스를 구현하기 위해 "Task Splitting" 및 "Function Calling" 모듈에서 프로젝트 복잡한 작업을 분할하고 필요에 따라 사용자 지정 기능을 호출할 수 있는 기능을 지원하는 두 개의 미세 조정 모델이 별도로 설계되었습니다. 요약된 모델 솔버는 분할 작업 모델과 동일할 수 있습니다
"작업 분할" 모듈에서, 대형 모델 복잡한 작업을 더 간단한 작업으로 나누는 능력이 필요합니다. "작업 분할"의 성공은 주로 다음 두 가지 요소에 달려 있습니다.
동시에 주어진 프롬프트 템플릿에서 작업 분할 모델의 출력 형식이 최대한 상대적으로 고정될 수 있기를 바랍니다. 하지만 과적합되지 않고 원래 추론 및 일반화 기능을 잃지 않을 것입니다. 모델 여기서는 lora를 사용하여 qv 레이어를 미세 조정하여 원래 모델에 가능한 한 적은 구조적 변경을 적용합니다.
"기능 호출" 모듈에서 대형 모델은 처리 작업 요구 사항에 맞게 도구를 안정적으로 호출할 수 있는 능력이 있어야 합니다.
또한 컴퓨팅 파워 사용량 측면에서 lora/qlora 미세 조정을 통해 낮은 컴퓨팅 파워 조건에서 대규모 언어 모델의 미세 조정 및 추론이 이루어지며, 정량적 배포를 채택하여 임계값을 더욱 낮춥니다. 추론을 위해.
"작업 분할" 모델을 선택하려면 모델이 강력한 일반화 기능과 특정 사고 체인 기능을 갖기를 바랍니다. 이와 관련하여 HuggingFace의 Open LLM 순위를 참조하여 모델을 선택할 수 있습니다. 테스트 MMLU 및 텍스트 모델의 다중 작업 정확도를 측정하는 종합 점수 평균
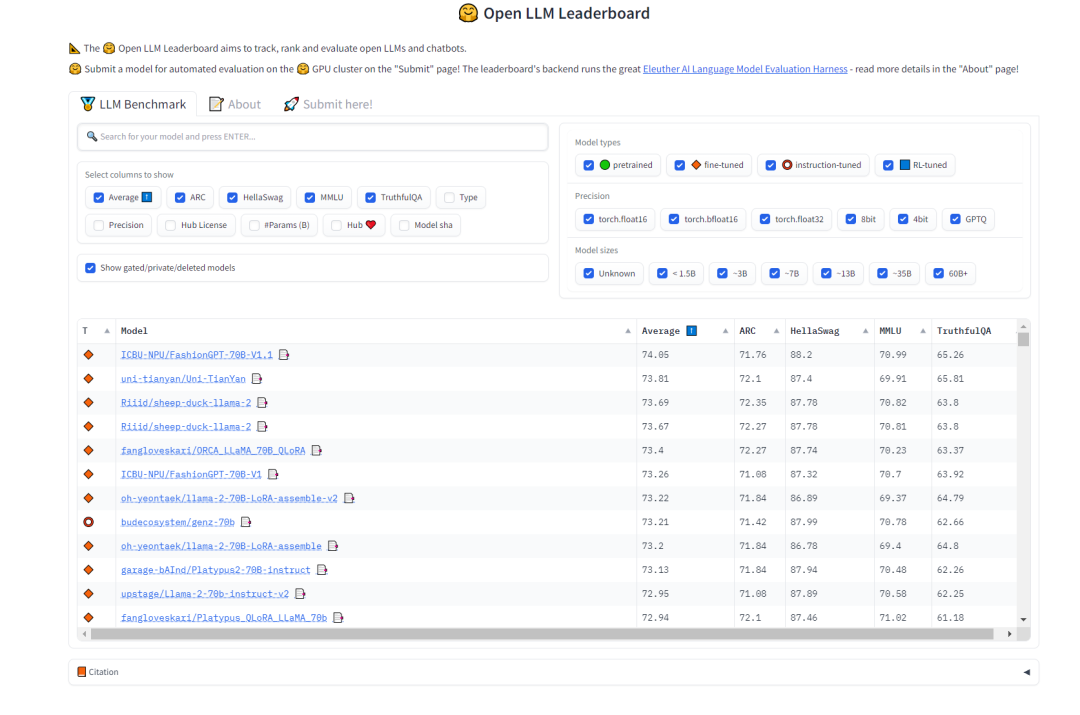
다시 작성해야 함 내용은 다음과 같습니다. 그림 2 HuggingFace 공개 LLM 순위(0921)
이 프로젝트에 선택된 작업 분할 모델 모델은 다음과 같습니다.
"함수 호출" 모델을 선택하려면 CodeLlama 프로그래밍 모델의 메타 오픈 소스 Llama2 버전의 원본 훈련 데이터에 많은 양의 코드 데이터가 포함되어 있으므로 사용자 정의 스크립트에 qlora를 미세하게 사용할 수 있습니다- 동조. 함수 호출 모델의 경우 벤치마크로 CodeLlama 모델(34b/13b/7b 허용)을 선택합니다.
이 프로젝트에서는 함수 호출 모델 모델을 선택했습니다.
"함수 호출" 모델을 미세 조정하기 위해 이 프로젝트에서는 신속한 손실 마스크 훈련 방법을 사용하여 모델의 출력을 안정화합니다. 손실 함수를 조정하는 방법은 다음과 같습니다.
For the following tasks, make plans that can solve the problem step-by-step. For each plan, indicate which external tool together with tool input to retrieve evidence. You can store the evidence into a variable #E that can be called by later tools. (Plan, #E1, Plan, #E2, Plan, ...) Tools can be one of the following: Wikipedia[input]: Worker that search for similar page contents from Wikipedia. Useful when you need to get holistic knowledge about people, places, companies, historical events, or other subjects.The response are long and might contain some irrelevant information. Input should be a search query. LLM[input]: A pretrained LLM like yourself. Useful when you need to act with general world knowledge and common sense. Prioritize it when you are confident in solving the problem yourself. Input can be any instruction.
분해 임무 모델: Marcoroni-70B는 알파카의 프롬프트 템플릿을 사용합니다. 모델은 Llama2 70B의 지침에 따라 미세 조정됩니다. 원본 모델의 템플릿과 정렬하려면 알파카 형식의 데이터 세트가 필요합니다. 여기서는 rewoo의 플래너 데이터 세트 형식을 사용했지만 원본 데이터 세트에는 위키와 자체를 호출하는 옵션만 있으므로 이 템플릿을 적용하고 gpt4 인터페이스를 사용하여 이 스타일의 데이터 세트를 생성할 수 있습니다.
함수 호출 모델: 선택한 HuggingFace 오픈 소스 함수 호출 데이터 세트에는 적은 양의 데이터(55행)가 있지만 qlora는 매우 효과적이며 이 데이터 세트에 코드 훈련 템플릿이 함께 제공됩니다.
### Instruction:<prompt> (without the )### Response:如:### Instruction:For the following tasks, make plans that can solve the problem step-by-step. For each plan, indicate which external tool together with tool input to retrieve evidence. You can store the evidence into a variable #E that can be called by later tools. (Plan, #E1, Plan, #E2, Plan, ...) Tools can be one of the following:get_current_time[input]: Get the current time for now. search_bing[input]: Search the web for content on Bing, and return the top 10 results. Remember, the results may not as good as Wikipedia. If you think the result will not exist in wikipedia, use it. search_wiki[input]: Search the web for content on Wikipedia, and return the top 3 results. If you think the result can exist in wikipedia, use it. search_bilibili[input]: Search for videos on Bilibili, which is a website full of ACG. It can return top 10 search results. save_file[input]: save a file in the target dir which contains the data. query_mysql[input]: Execute the sql in the local mysql database. And return the result. What movies did the director of 'Oppenheim' direct? List the top 10 best.### Response:Step 1: Identify the director of "Oppenheimer" movie.#E1 = search_wiki("Director of Oppenheimer")Step 2: Retrieve information about the director's other works.If the retrieved name exists in Wikipedia, proceed with searching their filmography using search_wiki. Otherwise, try searching through Bing or another source like IMDb.For example, if Christopher Nolan is found as the director of "Oppenheimer":#E2 = search_bing("Filmography of Christopher Nolan")Step 3: Extract the list of films directed by this person from the retrieved information.From the returned results, extract the titles of the top 10 best movies according to critics/audience ratings or personal preference.</prompt>在Ubuntu 22.04系统上,使用了CUDA 11.8和Pytorch 2.0.1,并采用了LLaMA-Efficient-Tuning框架。此外,还使用了Deepspeed 0.10.4
需要进行针对 Marcoroni-70B 的 lora 微调
全部选择完成后,新建一个训练的 bash 脚本,内容如下:
accelerate launch src/train_bash.py \--stage sft \--model_name_or_path your_model_path \--do_train \--dataset rewoo \--template alpaca \--finetuning_type lora \--lora_target q_proj,v_proj \--output_dir your_output_path \--overwrite_cache \--per_device_train_batch_size 1 \--gradient_accumulation_steps 4 \--lr_scheduler_type cosine \--logging_steps 10 \--save_steps 1000 \--learning_rate 5e-6 \--num_train_epochs 4.0 \--plot_loss \--flash_attn \--bf16
这样的设置需要的内存峰值最高可以到 240G,但还是保证了 6 卡 4090 可以进行训练。开始的时候可能会比较久,这是因为 deepspeed 需要对模型进行 init。之后训练就开始了。
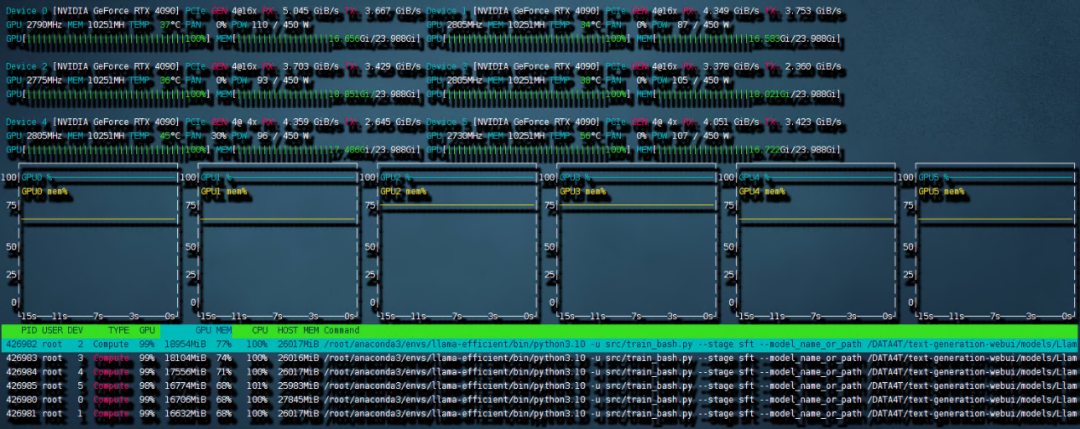
需要重新写的内容是:图4 6 卡 4090 训练带宽速度
共计用时 8:56 小时。本次训练中因为主板上的 NVME 插槽会和 OCULINK 共享一路 PCIE4.0 x16 带宽。所以 6 张中的其中两张跑在了 pcie4.0 X4 上,从上图就可以看出 RX 和 TX 都只是 PCIE4.0 X4 的带宽速度。这也成为了本次训练中最大的通讯瓶颈。如果全部的卡都跑在 pcie 4.0 x16 上,速度应该是比现在快不少的。
需要进行改写的内容是:图5展示了LLaMA-Efficient-Tuning生成的损失曲线
以上是 LLaMA-Efficient-Tuning 自动生成的 loss 曲线,可以看到 4 个 epoch 后收敛效果还是不错的。
2)针对 codellama 的 qlora 微调
根据前文所述的 prompt loss mask 方法,我们对 trainer 类进行了重构(请参考项目代码仓库中的 func_caller_train.py)。由于数据集本身较小(共55行),所以仅需两分钟即可完成4个epoch的训练,模型迅速收敛
在项目代码仓库中,提供了一个简短可用的 toolkit 示例。里面的函数包括:
现在有一个70B和一个34B的模型,在实际使用中,用6张4090同时以bf16精度运行这两个模型是不现实的。但是可以通过量化的方法压缩模型大小,同时提升模型推理速度。这里采用高性能LLM推理库exllamav2运用flash_attention特性来对模型进行量化并推理。在项目页面中作者介绍了一种独特的量化方式,本文不做赘述。按照其中的转换机制可以将70B的模型按照2.5-bit量化为22G的大小,这样一张显卡就可以轻松加载
需要重新编写的内容是:1)测试方法
훈련 세트에 없는 복잡한 작업 설명이 주어지면 훈련 세트에 포함되지 않은 기능과 해당 설명을 툴킷에 추가하세요. 기획자가 작업 분할을 완료할 수 있으면 배포자는 함수를 호출할 수 있고, 해결자는 전체 프로세스를 기반으로 결과를 요약할 수 있습니다.
다시 작성해야 하는 내용은 다음과 같습니다. 2) 테스트 결과
작업 분할: 먼저 다음 그림과 같이 text- Generation-webui를 사용하여 작업 분할 모델의 효과를 빠르게 테스트합니다. :

그림 6 작업 분할 테스트 결과
여기서 에이전트 테스트 환경에서 호출을 용이하게 하기 위해 간단한 Restful_api 인터페이스를 작성할 수 있습니다(프로젝트 코드 fllama_api.py 참조).
함수 호출: 간단한 플래너-배포자-작업자-해결사 논리가 프로젝트에 작성되었습니다. 다음으로 이 작업을 테스트해 보겠습니다. 명령을 입력하세요: '꽃달의 살인자' 감독은 어떤 영화를 감독했나요? 그 중 하나를 나열하고 bilibili에서 검색하세요.
「bilibili 검색」 이 기능은 프로젝트의 함수 호출 훈련 세트에 포함되어 있지 않습니다. 동시에, 이 영화는 아직 공개되지 않은 새로운 영화이기도 합니다. 모델 자체의 훈련 데이터가 포함되어 있는지는 확실하지 않습니다. 모델이 입력 명령을 매우 잘 분할하는 것을 볼 수 있습니다.
를 검색하고 동시에 함수를 호출하면 다음과 같은 결과가 나왔습니다. 클릭한 결과는 영화 감독과 일치하는 Goodfellas입니다.
이 프로젝트는 "명령을 입력하여 복잡한 작업 분할 및 함수 호출을 자동으로 실현하는" 시나리오를 예로 들어 기본 에이전트 프로세스인 toolkit-plan-distribute-worker-solver를 설계합니다. 한 단계로 완료할 수 없는 기본적이고 복잡한 작업을 수행할 수 있는 에이전트를 구현합니다. lora의 기본 모델 선택과 미세 조정을 통해 낮은 컴퓨팅 성능 조건에서도 대형 모델의 미세 조정과 추론을 완료할 수 있습니다. 그리고 추론의 문턱을 더욱 낮추기 위해 정량적 배치 방식을 채택합니다. 마지막으로 이 파이프라인을 통해 영화감독의 다른 작품을 검색하는 예제가 구현되어 기본적이고 복잡한 작업이 완료되었습니다.
제한 사항: 이 문서에서는 검색 및 기본 작업용 툴킷을 기반으로 함수 호출 및 작업 분할만 설계합니다. 사용된 도구 세트는 매우 간단하고 디자인이 많지 않습니다. 내결함성 메커니즘에 대한 고려는 많지 않습니다. 이 프로젝트를 통해 모든 사람은 계속해서 RPA 분야의 애플리케이션을 탐색하고 에이전트 프로세스를 더욱 개선하며 더 높은 수준의 지능형 자동화를 달성하여 프로세스의 관리 효율성을 향상시킬 수 있습니다.
위 내용은 AI Agent는 어떻게 구현되나요? 4090 마법 수정 Llama2 사진 6장: 하나의 명령으로 작업 분할 및 기능 호출의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



