
Text-to-Image 분야는 지난 몇 년 동안, 특히 AIGC(인공 지능 생성 콘텐츠) 시대에 엄청난 발전을 이루었습니다. DALL-E 모델이 등장하면서 Imagen, Stable Diffusion, ControlNet 및 기타 모델과 같은 점점 더 많은 Text-to-Image 모델이 학계에 등장했습니다. 그러나 Text-to-Image 분야의 급속한 발전에도 불구하고 기존 모델은 여전히 텍스트가 포함된 이미지를 안정적으로 생성하는 데 몇 가지 어려움에 직면해 있습니다
기존 sota text-to-image 모델을 사용해 본 결과 텍스트 부분이 모델에 의해 생성된 문자는 기본적으로 읽을 수 없으며 왜곡된 문자와 유사하여 이미지의 전반적인 미학에 큰 영향을 미칩니다.

기존 sota 텍스트 생성 모델에서 생성된 텍스트 정보는 가독성이 좋지 않습니다.
조사 결과 학계에서 이 분야에 대한 연구가 적습니다. 실제로 텍스트가 포함된 이미지는 포스터, 책 표지, 거리 표지판 등 일상생활에서 매우 흔하게 접할 수 있습니다. AI가 이러한 이미지를 효과적으로 생성할 수 있다면 디자이너의 작업을 지원하고 디자인 영감을 불러일으키며 디자인 부담을 줄이는 데 도움이 될 것입니다. 또한 사용자는 Vincent 다이어그램 모델 결과의 텍스트 부분만 수정하고 텍스트가 아닌 다른 영역에는 결과를 유지하기를 원할 수도 있습니다.
원래 의미가 변하지 않도록 내용을 중국어로 다시 작성해야 합니다. 원문이 나올 필요는 없습니다

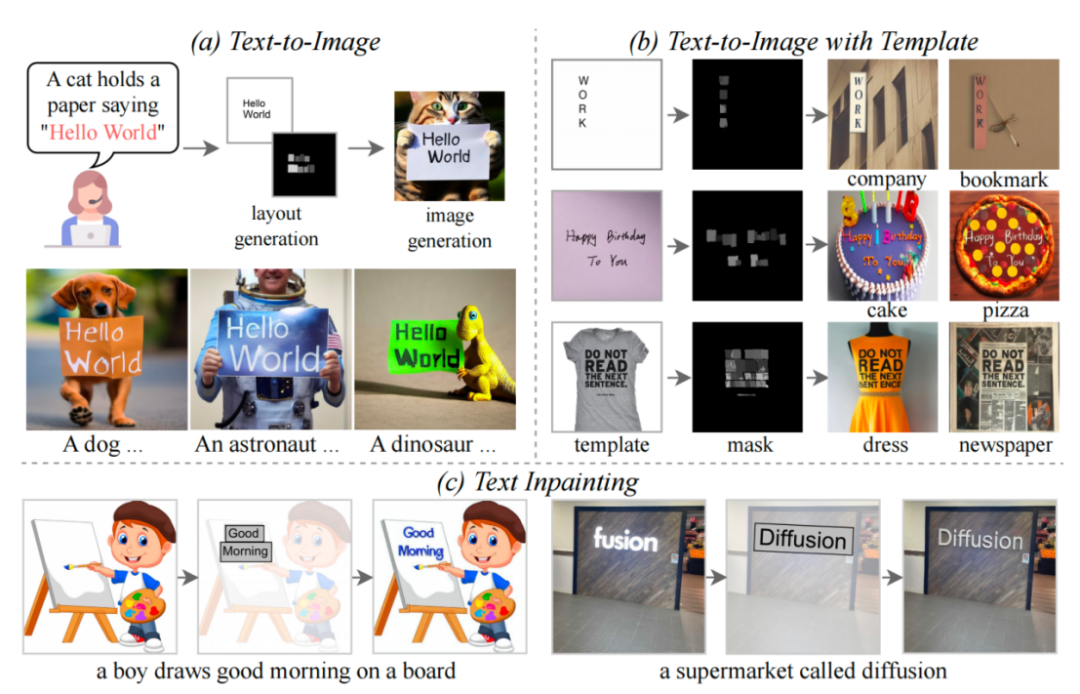
TextDiffuser의 세 가지 기능
이 기사에서는 두 단계로 구성된 TextDiffuser 모델을 제안합니다. 첫 번째 단계는 레이아웃을 생성하고 두 번째 단계는 이미지를 생성합니다.
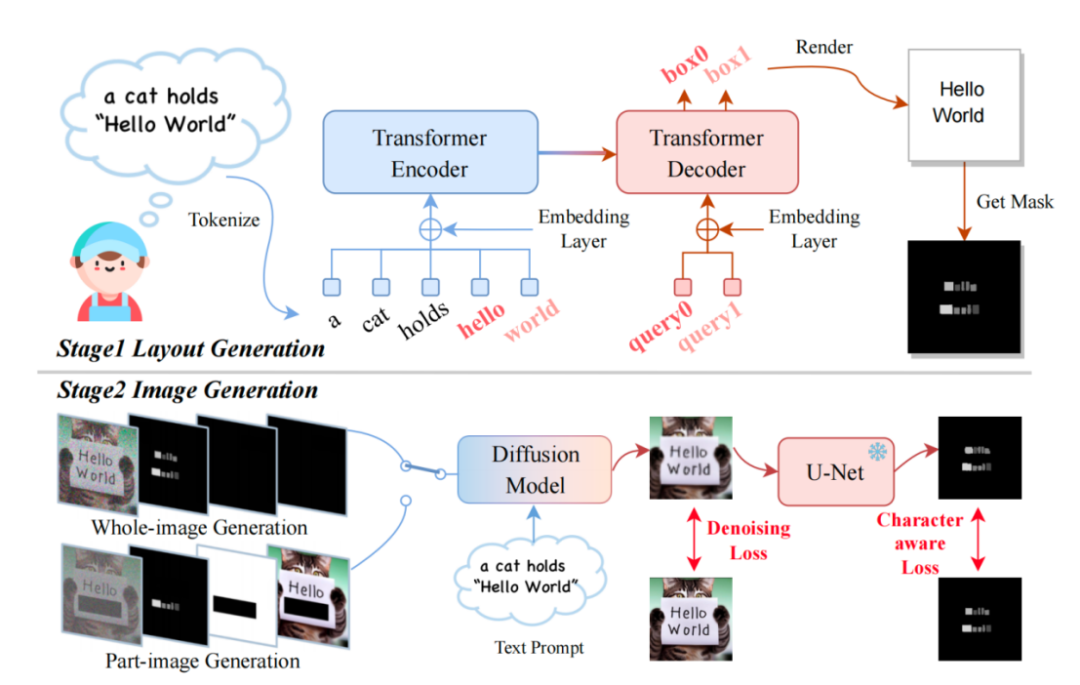
다시 작성해야 할 사항은 다음과 같습니다. TextDiffuser 프레임 다이어그램
모델은 텍스트 프롬프트를 받아들인 다음, 키워드를 기반으로 각 키워드의 레이아웃(즉, 좌표 상자)을 결정합니다. 프롬프트. 연구원들은 Layout Transformer를 사용했고, 인코더-디코더 형식을 사용하여 키워드의 좌표 상자를 자동 회귀적으로 출력했으며, Python의 PILLOW 라이브러리를 사용하여 텍스트를 렌더링했습니다. 이 과정에서 Pillow의 기성 API를 사용하여 각 문자의 좌표 상자를 얻을 수도 있으며 이는 문자 수준의 상자 수준 분할 마스크를 얻는 것과 같습니다. 연구진은 이 정보를 바탕으로 Stable Diffusion을 미세 조정하려고 했습니다.
그들은 두 가지 상황을 고려했습니다. 하나는 사용자가 전체 이미지를 직접 생성하기를 원한다는 것입니다(전체 이미지 생성이라고 함). 또 다른 상황은 논문에서 텍스트 인페인팅(Text-inpainting)이라고도 불리는 부분 이미지 생성(Part-Image Generation)입니다. 이는 사용자가 이미지를 제공하고 이미지의 특정 텍스트 영역을 수정해야 함을 의미합니다.
위의 두 가지 목표를 달성하기 위해 연구진은 입력 기능을 다시 설계하고 원래 4차원에서 17차원으로 차원을 늘렸습니다. 여기에는 4차원 노이즈 이미지 특징, 8차원 문자 정보, 1차원 이미지 마스크 및 4차원 마스크되지 않은 이미지 특징이 포함됩니다. 연구진은 전체 이미지 생성인 경우 마스크 영역을 전체 이미지로 설정하고, 반대로 부분 이미지 생성인 경우 이미지의 일부만 마스크 처리한다. 확산 모델의 훈련 과정은 LDM과 유사합니다. 관심 있는 친구는 원본 기사의 방법 설명을 참조할 수 있습니다
추론 단계에서 TextDiffuser는 매우 유연한 사용 방법을 제공하며 이를 나눌 수 있습니다. 세 가지 유형으로:

구성된 MARIO 데이터
TextDiffuser를 훈련하기 위해 연구원들은 위 그림과 같이 MARIO-LAION, MARIO-TMDB 및 MARIO의 세 가지 하위 집합을 포함하여 천만 개의 텍스트 이미지를 수집했습니다. OpenLibrary
연구원들은 데이터를 필터링할 때 여러 측면을 고려했습니다. 예를 들어 이미지가 OCR된 후에는 텍스트 수량이 [1,8]인 이미지만 유지됩니다. 8개 이상의 텍스트가 포함된 텍스트를 필터링한 이유는 이러한 텍스트에 조밀한 텍스트가 많이 포함되어 있는 경우가 많고 신문이나 복잡한 디자인 도면과 같이 일반적으로 OCR 결과의 정확도가 떨어지기 때문입니다. 또한, 텍스트 영역을 10%보다 크게 설정했습니다. 이 규칙은 이미지에서 텍스트 영역이 너무 작아지는 것을 방지하기 위해 설정되었습니다.
MARIO-10M 데이터 세트에 대한 교육을 마친 후 연구원들은 TextDiffuser와 기존 방법의 정량적, 정성적 비교를 수행했습니다. 예를 들어, 전체 이미지 생성 작업에서 아래 그림과 같이 우리 방법으로 생성된 이미지는 더 명확하고 읽기 쉬운 텍스트를 가지며 텍스트 영역은 배경 영역과 더 잘 통합됩니다.
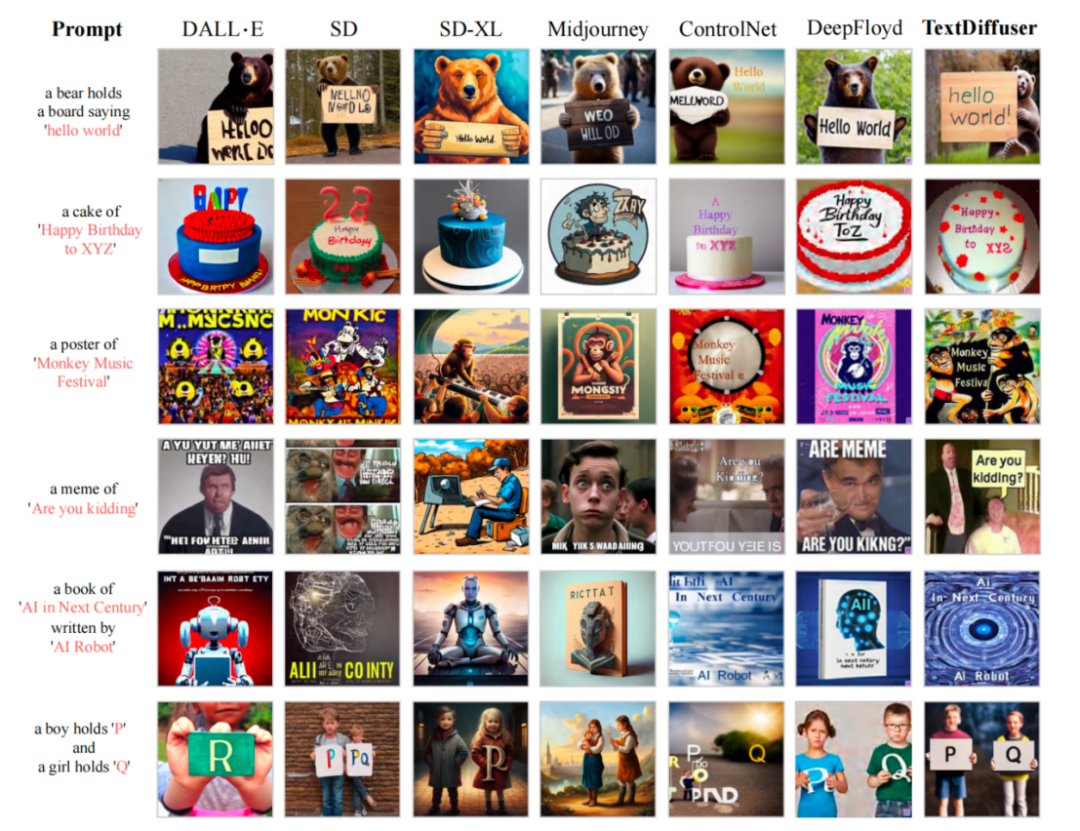
기존 작업 렌더링 성능
연구원들도 일련의 정성적 실험을 진행하였고, 그 결과는 표 1과 같습니다. 평가 지표에는 FID, CLIPScore 및 OCR이 포함됩니다. 특히 OCR 지수의 경우 이 연구 방법은 비교 방법에 비해 크게 향상되었습니다
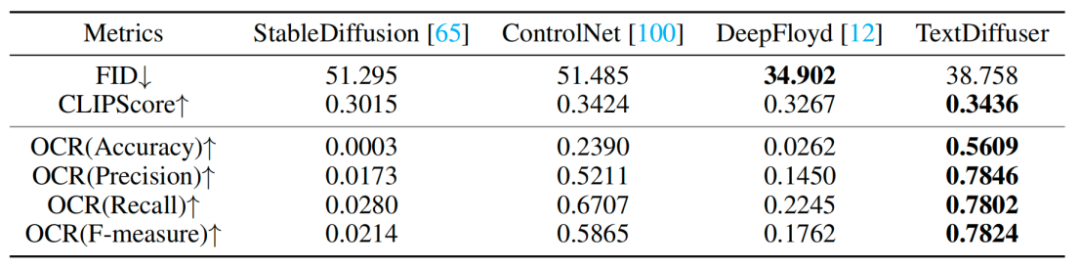
재작성된 내용: 실험 결과는 표 1에 나와 있습니다. 정성적 실험
부분 이미지 생성 작업의 경우, 연구원 주어진 이미지에 문자를 추가하거나 수정해 보면 실험 결과 TextDiffuser가 매우 자연스러운 결과를 생성하는 것으로 나타났습니다.

텍스트 복구 기능의 시각화
전반적으로 본 논문에서 제안한 TextDiffuser 모델은 텍스트 렌더링 분야에서 상당한 진전을 이루었으며 읽을 수 있는 텍스트가 포함된 고품질 이미지를 생성할 수 있습니다. 앞으로 연구자들은 TextDiffuser의 효과를 더욱 향상시킬 것입니다.
위 내용은 새 제목: TextDiffuser: 이미지 속 텍스트에 대한 두려움이 없어 더 높은 품질의 텍스트 렌더링 제공의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



