

NLP용 Python을 사용하여 PDF 파일에서 핵심 문장을 추출하는 방법은 무엇입니까?


NLP용 Python을 사용하여 PDF 파일에서 핵심 문장을 추출하는 방법은 무엇입니까?
소개:
정보 기술의 급속한 발전과 함께 자연어 처리(NLP)는 텍스트 분석, 정보 추출 및 기계 번역과 같은 분야에서 중요한 역할을 합니다. 실제 응용에서는 PDF 파일에서 핵심 문장을 추출하는 등 대량의 텍스트 데이터에서 핵심 정보를 추출해야 하는 경우가 많습니다. 이 기사에서는 Python의 NLP 패키지를 사용하여 PDF 파일에서 핵심 문장을 추출하는 방법을 소개하고 자세한 코드 예제를 제공합니다.
1단계: 필수 Python 라이브러리 설치
시작하기 전에 후속 텍스트 처리 및 PDF 파일 구문 분석을 용이하게 하기 위해 여러 Python 라이브러리를 설치해야 합니다.
1. nltk 라이브러리 설치:
nltk 라이브러리를 설치하려면 명령줄에 다음 명령을 입력하세요.
pip install nltk
2 pdfminer 라이브러리를 설치하세요.
pdfminer 라이브러리를 설치하려면 명령줄에 다음 명령을 입력하세요.
pip install pdfminer.six
먼저 PDF 파일을 일반 텍스트 형식으로 변환해야 합니다. pdfminer 라이브러리는 PDF 파일을 구문 분석하는 기능을 제공합니다.
from pdfminer.converter import TextConverter
from pdfminer.layout import LAParams
from pdfminer.pdfinterp import PDFResourceManager, PDFPageInterpreter
from pdfminer.pdfpage import PDFPage
from io import StringIO
def convert_pdf_to_text(file_path):
resource_manager = PDFResourceManager()
string_io = StringIO()
laparams = LAParams()
device = TextConverter(resource_manager, string_io, laparams=laparams)
interpreter = PDFPageInterpreter(resource_manager, device)
with open(file_path, 'rb') as file:
for page in PDFPage.get_pages(file):
interpreter.process_page(page)
text = string_io.getvalue()
device.close()
string_io.close()
return text다음으로 nltk 라이브러리를 사용하여 핵심 문장을 추출해야 합니다. nltk는 텍스트 토큰화, 단어 분할 및 문장 분할을 위한 풍부한 기능을 제공합니다.
import nltk
def extract_key_sentences(text, num_sentences):
sentences = nltk.sent_tokenize(text)
word_frequencies = {}
for sentence in sentences:
words = nltk.word_tokenize(sentence)
for word in words:
if word not in word_frequencies:
word_frequencies[word] = 1
else:
word_frequencies[word] += 1
sorted_word_frequencies = sorted(word_frequencies.items(), key=lambda x: x[1], reverse=True)
top_sentences = [sentence for (sentence, _) in sorted_word_frequencies[:num_sentences]]
return top_sentences다음은 PDF 파일에서 핵심 문장을 추출하는 방법을 보여주는 전체 샘플 코드입니다.
from pdfminer.converter import TextConverter
from pdfminer.layout import LAParams
from pdfminer.pdfinterp import PDFResourceManager, PDFPageInterpreter
from pdfminer.pdfpage import PDFPage
from io import StringIO
import nltk
def convert_pdf_to_text(file_path):
resource_manager = PDFResourceManager()
string_io = StringIO()
laparams = LAParams()
device = TextConverter(resource_manager, string_io, laparams=laparams)
interpreter = PDFPageInterpreter(resource_manager, device)
with open(file_path, 'rb') as file:
for page in PDFPage.get_pages(file):
interpreter.process_page(page)
text = string_io.getvalue()
device.close()
string_io.close()
return text
def extract_key_sentences(text, num_sentences):
sentences = nltk.sent_tokenize(text)
word_frequencies = {}
for sentence in sentences:
words = nltk.word_tokenize(sentence)
for word in words:
if word not in word_frequencies:
word_frequencies[word] = 1
else:
word_frequencies[word] += 1
sorted_word_frequencies = sorted(word_frequencies.items(), key=lambda x: x[1], reverse=True)
top_sentences = [sentence for (sentence, _) in sorted_word_frequencies[:num_sentences]]
return top_sentences
# 示例使用
pdf_file = 'example.pdf'
text = convert_pdf_to_text(pdf_file)
key_sentences = extract_key_sentences(text, 5)
for sentence in key_sentences:
print(sentence)이 글에서는 Python의 NLP 패키지를 사용하여 PDF 파일에서 핵심 문장을 추출하는 방법을 소개합니다. pdfminer 라이브러리를 통해 PDF 파일을 일반 텍스트로 변환하고, nltk 라이브러리의 토큰화 및 문장 분할 기능을 사용하면 핵심 문장을 쉽게 추출할 수 있습니다. 이 방법은 정보 추출, 텍스트 요약, 지식 그래프 구축 등의 분야에서 널리 사용됩니다. 이 글의 내용이 여러분에게 도움이 되기를 바라며, 실제 적용에 활용되길 바랍니다.
위 내용은 NLP용 Python을 사용하여 PDF 파일에서 핵심 문장을 추출하는 방법은 무엇입니까?의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

Video Face Swap
완전히 무료인 AI 얼굴 교환 도구를 사용하여 모든 비디오의 얼굴을 쉽게 바꾸세요!

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7894
7894
 15
1651
14
1411
52
1302
25
1248
29
15
1651
14
1411
52
1302
25
1248
29

 iPhone에서 PDF를 병합하는 방법
Feb 02, 2024 pm 04:05 PM
iPhone에서 PDF를 병합하는 방법
Feb 02, 2024 pm 04:05 PM
여러 문서 또는 동일한 문서의 여러 페이지로 작업할 때 이를 하나의 파일로 결합하여 다른 사람과 공유할 수 있습니다. 간편한 공유를 위해 Apple에서는 여러 PDF 파일을 하나의 파일로 병합하여 여러 파일을 보내지 않도록 할 수 있습니다. 이 기사에서는 iPhone에서 두 개 이상의 PDF를 하나의 PDF 파일로 병합하는 모든 방법을 알려 드리겠습니다. iPhone에서 PDF를 병합하는 방법 iOS에서는 파일 앱과 바로가기 앱을 사용하여 두 가지 방법으로 PDF 파일을 하나로 병합할 수 있습니다. 방법 1: 파일 앱 사용 두 개 이상의 PDF를 하나의 파일로 병합하는 가장 쉬운 방법은 파일 앱을 사용하는 것입니다. 아이폰에서 열기
 iPhone에서 PDF에서 텍스트를 가져오는 3가지 방법
Mar 16, 2024 pm 09:20 PM
iPhone에서 PDF에서 텍스트를 가져오는 3가지 방법
Mar 16, 2024 pm 09:20 PM
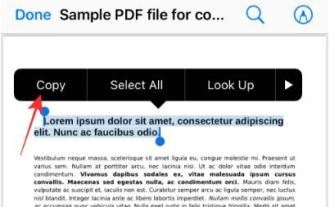
Apple의 라이브 텍스트 기능은 사진이나 카메라 앱을 통해 텍스트, 손으로 쓴 메모, 숫자를 인식하고 해당 정보를 다른 앱에 붙여넣을 수 있습니다. 하지만 PDF로 작업하면서 PDF에서 텍스트를 추출하려면 어떻게 해야 할까요? 이번 포스팅에서는 iPhone에서 PDF 파일에서 텍스트를 추출하는 모든 방법을 설명하겠습니다. iPhone에서 PDF 파일에서 텍스트를 가져오는 방법 [3가지 방법] 방법 1: PDF에서 텍스트 드래그 PDF에서 텍스트를 추출하는 가장 쉬운 방법은 텍스트가 있는 다른 앱에서와 마찬가지로 복사하는 것입니다. 1. 텍스트를 추출하려는 PDF 파일을 연 다음 PDF의 아무 곳이나 길게 누르고 복사하려는 텍스트 부분을 드래그하기 시작합니다. 2
 PDF에서 서명을 확인하는 방법
Feb 18, 2024 pm 05:33 PM
PDF에서 서명을 확인하는 방법
Feb 18, 2024 pm 05:33 PM
우리는 일반적으로 정부나 기타 기관으로부터 PDF 파일을 받으며, 일부는 디지털 서명이 포함되어 있습니다. 서명을 확인한 후 SignatureValid 메시지와 녹색 확인 표시가 표시됩니다. 서명이 확인되지 않으면 유효성을 알 수 없습니다. 서명을 확인하는 것이 중요합니다. PDF에서 이를 수행하는 방법을 살펴보겠습니다. PDF에서 서명을 확인하는 방법 PDF 형식의 서명을 확인하면 더욱 신뢰할 수 있고 문서가 승인될 가능성이 높아집니다. 다음과 같은 방법으로 PDF 문서의 서명을 확인할 수 있습니다. Adobe Reader에서 PDF를 엽니다. 서명을 마우스 오른쪽 버튼으로 클릭하고 서명 속성 표시를 선택합니다. 서명자 인증서 표시 버튼을 클릭합니다. 신뢰 탭에서 신뢰할 수 있는 인증서 목록에 서명을 추가합니다. 서명 확인을 클릭하여 확인을 완료합니다.
 Apple Notes에서 PDF를 가져오고 주석을 추가하는 방법
Oct 13, 2023 am 08:05 AM
Apple Notes에서 PDF를 가져오고 주석을 추가하는 방법
Oct 13, 2023 am 08:05 AM
iOS 17 및 MacOS Sonoma에서 Apple은 Notes 앱에서 직접 PDF를 열고 주석을 달 수 있는 기능을 추가했습니다. 이 작업이 어떻게 수행되었는지 알아보려면 계속 읽어보세요. 최신 버전의 iOS 및 macOS에서 Apple은 인라인 PDF를 지원하도록 Notes 앱을 업데이트했습니다. 즉, Notes에 PDF를 삽입한 다음 문서를 읽고 주석을 달고 공동 작업을 할 수 있습니다. 이 기능은 스캔한 문서에도 작동하며 iPhone과 iPad 모두에서 사용할 수 있습니다. iPhone 및 iPad의 Notes에서 PDF에 주석 달기 iPhone을 사용하고 Notes에서 PDF에 주석을 달고 싶다면 가장 먼저 해야 할 일은 PDF 파일을 선택하는 것입니다.
 pdg 파일을 pdf로 변환하는 방법
Nov 14, 2023 am 10:41 AM
pdg 파일을 pdf로 변환하는 방법
Nov 14, 2023 am 10:41 AM
방법은 다음과 같습니다. 1. 전문적인 문서 변환 도구를 사용합니다. 2. 온라인 변환 도구를 사용합니다. 3. 가상 프린터를 사용합니다.
 xmind 파일을 pdf 파일로 내보내는 방법
Mar 20, 2024 am 10:30 AM
xmind 파일을 pdf 파일로 내보내는 방법
Mar 20, 2024 am 10:30 AM
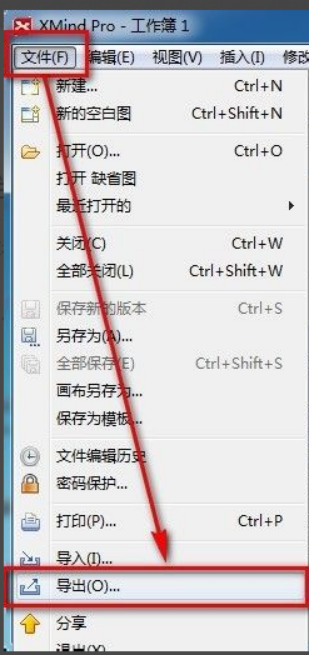
xmind는 매우 실용적인 마인드 매핑 소프트웨어입니다. 사람들의 생각과 영감을 사용하여 만든 지도 형식입니다. xmind 파일을 만든 후에는 일반적으로 모든 사람이 쉽게 배포하고 사용할 수 있도록 PDF 파일 형식으로 변환합니다. PDF 파일로? 다음은 참조할 수 있는 구체적인 단계입니다. 1. 먼저 마인드맵을 PDF 문서로 내보내는 방법을 보여드리겠습니다. [파일]-[내보내기] 기능버튼을 선택하세요. 2. 새로 나타난 인터페이스에서 [PDF 문서]를 선택하고 [다음] 버튼을 클릭하세요. 3. 내보내기 인터페이스에서 용지 크기, 방향, 해상도 및 문서 저장 위치 설정을 선택합니다. 설정을 완료한 후 [마침] 버튼을 클릭하세요. 4. [마침] 버튼을 클릭하면
 PHP7에서 PDF 파일 다운로드 문제 해결
Feb 29, 2024 am 11:12 AM
PHP7에서 PDF 파일 다운로드 문제 해결
Feb 29, 2024 am 11:12 AM
PHP7을 사용하여 PDF 파일을 다운로드할 때 발생하는 문제 해결 웹 개발에서 파일을 다운로드하기 위해 PHP를 사용해야 하는 경우가 종종 있습니다. 특히 PDF 파일을 다운로드하면 사용자가 필요한 정보나 파일을 얻는 데 도움이 될 수 있습니다. 그러나 때로는 PHP7에서 PDF 파일을 다운로드할 때 문자가 깨지거나 다운로드가 불완전해지는 등 몇 가지 문제가 발생할 수 있습니다. 이 문서에서는 PHP7에서 PDF 파일을 다운로드할 때 발생할 수 있는 문제를 해결하는 방법을 자세히 설명하고 몇 가지 구체적인 코드 예제를 제공합니다. 문제점 분석: PHP7에서는 문자 인코딩 및 H로 인해
 엣지 브라우저 단축키를 사용하여 PDF 파일을 회전하는 방법 알아보기
Jan 05, 2024 am 09:17 AM
엣지 브라우저 단축키를 사용하여 PDF 파일을 회전하는 방법 알아보기
Jan 05, 2024 am 09:17 AM
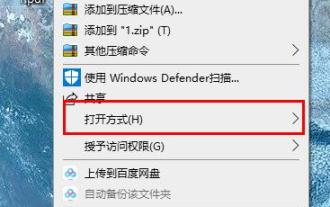
PDF 파일은 사용하기 매우 편리하지만 여전히 많은 친구들이 Word를 사용하여 편집하고 보는 것을 좋아합니다. 그렇다면 파일을 변환하는 방법은 무엇입니까? 아래에서 자세한 운용방법을 살펴보겠습니다. Edge browser pdf 회전 단축키: A: 회전 단축키는 F9입니다. 1. pdf 파일을 마우스 오른쪽 버튼으로 클릭하고 "다음으로 열기"를 선택하세요. 2. "Microsoft Edge"를 선택하여 PDF 파일을 엽니다. 3. pdf 파일을 입력하시면 아래와 같이 작업표시줄이 나타납니다. 4. 오른쪽으로 회전하려면 "+" 기호 옆에 있는 회전 버튼을 클릭하세요.
