
본 글은 자율주행하트 공개 계정의 승인을 받아 재인쇄되었습니다.
[2D 라벨만 사용하여 다중 뷰 3D 점유 모델을 훈련하는 최초의 새로운 패러다임,RenderOcc] 저자는 다중 뷰 이미지에서 NeRF 스타일 3D 체적 표현을 추출하고 볼륨 렌더링 기술을 사용하여 2D 재구성을 구축하여 의미론적 변환을 달성합니다. 깊이 라벨이 포함된 2D Direct 3D 감독은 값비싼 3D 점유 주석에 대한 의존도를 줄여줍니다. 광범위한 실험을 통해 RenderOcc는 3D 라벨을 사용하는 완전 감독 모델과 비슷한 성능을 보여 실제 응용 프로그램에서 이 접근 방식의 중요성을 강조합니다. 이미 오픈 소스입니다.
제목: RenderOcc: Vision-Centric 3D Occupancy Prediction with 2DRendering Supervision
저자 소속: Peking University, Xiaomi Automobile, Hong Kong Chinese MMLAB
다시 작성해야 하는 콘텐츠는 다음과 같습니다. 오픈 소스 주소: GitHub - pmj110119/RenderOcc
3D 장면을 의미적으로 라벨링된 그리드 셀로 수량화하는 3D 직업 예측은 로봇 인식 및 자율 주행 분야에서 중요한 약속을 가지고 있습니다. 최근 연구에서는 주로 감독을 위해 3D 복셀 공간의 완전한 점유 라벨을 활용합니다. 그러나 비용이 많이 드는 주석 프로세스와 때로는 모호한 레이블로 인해 3D 점유 모델의 유용성과 확장성이 심각하게 제한됩니다. 이 문제를 해결하기 위해 저자는 2D 라벨만을 사용하여 3D 점유 모델을 훈련하는 새로운 패러다임인 RenderOcc를 제안합니다. 특히 다중 뷰 이미지에서 NeRF 스타일의 3D 체적 표현을 추출하고 볼륨 렌더링 기술을 사용하여 2D 재구성을 구축하여 2D 의미 및 깊이 레이블에서 직접 3D 감독을 가능하게 합니다. 또한 저자는 자율주행 장면에서 희박한 시점 문제를 해결하기 위해 순차적 프레임을 활용하여 각 대상에 대한 포괄적인 2D 렌더링을 구축하는 보조 광선 방법을 소개합니다. RenderOcc는 값비싼 3D 점유 주석에 대한 의존도를 줄여 2D 라벨만 사용하여 다중 뷰 3D 점유 모델을 훈련하려는 최초의 시도입니다. 광범위한 실험을 통해 RenderOcc는 3D 라벨을 사용하는 완전 감독 모델과 비슷한 성능을 보여 실제 응용 프로그램에서 이 접근 방식의 중요성을 강조합니다.
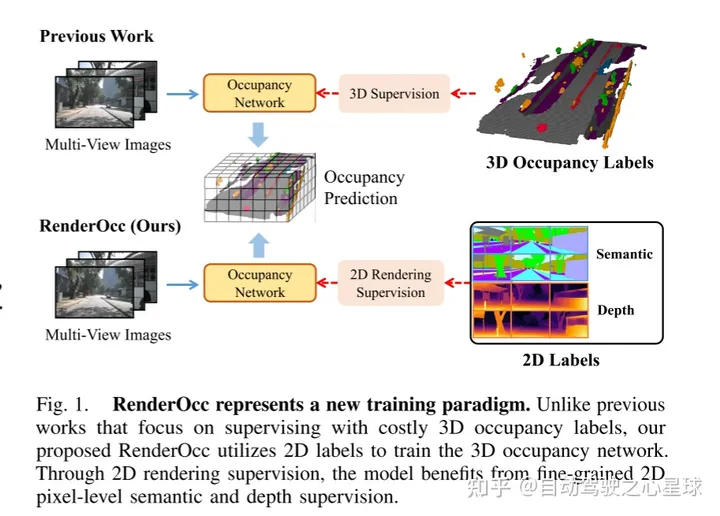
그림 1은 RenderOcc의 새로운 훈련 방법을 보여줍니다. 감독을 위해 고가의 3D 점유 라벨을 사용하는 이전 방법과 달리, 본 논문에서 제안하는 RenderOcc는 2D 라벨을 활용하여 3D 점유 네트워크를 훈련합니다. 2D 렌더링 감독을 통해 모델은 세분화된 2D 픽셀 수준 의미론 및 깊이 감독의 이점을 누릴 수 있습니다.
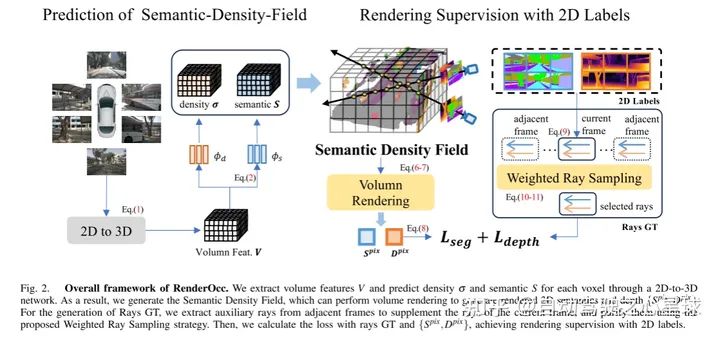
그림 2. RenderOcc의 전체 프레임워크. 본 논문에서는 2D에서 3D 네트워크를 통해 체적 특징을 추출하고 각 복셀의 밀도와 의미를 예측합니다. 따라서 본 논문에서는 볼륨 렌더링을 수행하여 렌더링된 2D 의미 및 깊이를 생성할 수 있는 Semantic Density Field를 생성합니다. Rays GT 생성을 위해 본 논문에서는 인접 프레임에서 보조 광선을 추출하여 현재 프레임의 광선을 보완하고 제안된 가중치 광선 샘플링 전략을 사용하여 이를 정화합니다. 그런 다음 이 기사에서는 라이트 GT와 {}를 사용하여 2D 라벨의 렌더링 감독을 달성하기 위한 손실을 계산합니다.
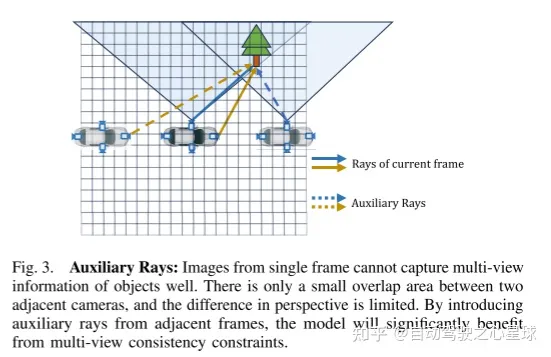
재작성된 콘텐츠: 그림 3. 보조 조명: 단일 프레임 이미지는 물체의 다중 뷰 정보를 잘 포착할 수 없습니다. 인접한 카메라 사이에는 약간의 중첩 영역만 있고 시야각의 차이도 제한됩니다. 인접한 프레임에서 보조 광선을 도입함으로써 모델은 다중 뷰 일관성 제약 조건의 이점을 크게 누릴 수 있습니다.

다시 작성해야 하는 내용은 다음과 같습니다. 원본 링크: https://mp.weixin.qq.com/s/WzI8mGoIOTOdL8irXrbSPQ
위 내용은 첫 번째 기사: 2D 라벨만 사용하여 다중 뷰 3D 점유 모델을 훈련하기 위한 새로운 패러다임의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!


















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



