

대화 시스템의 컨텍스트 생성 문제


대화 시스템의 컨텍스트 생성 문제에는 특정 코드 예제가 필요합니다.
소개:
대화 시스템은 인간과 기계 간의 자연스럽고 원활한 대화 교환을 목표로 하는 인공 지능 분야의 중요한 연구 방향입니다. 좋은 대화 시스템은 사용자의 의도를 이해할 수 있을 뿐만 아니라 상황에 따라 일관된 반응을 생성할 수 있어야 합니다. 대화 시스템에서 컨텍스트 생성 문제는 핵심 과제입니다. 이 기사에서는 이 문제를 살펴보고 구체적인 코드 예제를 제공합니다.
1. 대화 시스템의 컨텍스트 생성 문제
대화 시스템에서 컨텍스트 생성은 여러 라운드의 대화 중에 역사적 대화 내용을 기반으로 현재 답변을 생성할 때 직면하는 문제를 의미합니다. 구체적으로, 맥락 속의 대화 내용을 바탕으로 관련 정보를 찾고 적절한 답변을 생성하는 방법입니다.
컨텍스트 생성 문제는 대화 시스템의 정확성과 유창성에 중요한 영향을 미칩니다. 대화 시스템이 맥락을 정확하게 이해하지 못하고 그에 상응하는 응답을 생성하지 못한다면 대화에서 모호함과 불일치가 쉽게 발생할 수 있습니다. 따라서 맥락 생성 문제를 해결하는 것이 핵심 연구 방향이다.
2. 딥러닝 기반 컨텍스트 생성 방법
딥러닝 기술은 컨텍스트 생성 문제를 해결하는 데 널리 사용됩니다. 다음은 딥러닝 기반 대화 시스템 컨텍스트 생성을 위한 구체적인 예제 코드입니다.
import tensorflow as tf
# 定义对话系统模型
class DialogModel(tf.keras.Model):
def __init__(self, vocab_size, embedding_dim, hidden_dim):
super(DialogModel, self).__init__()
self.embedding = tf.keras.layers.Embedding(vocab_size, embedding_dim)
self.gru = tf.keras.layers.GRU(hidden_dim, return_sequences=True, return_state=True)
self.dense = tf.keras.layers.Dense(vocab_size)
def call(self, inputs, hidden):
embedded = self.embedding(inputs)
output, state = self.gru(embedded, initial_state=hidden)
logits = self.dense(output)
return logits, state
# 定义损失函数
def loss_function(real, pred):
loss_object = tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True, reduction='none')
loss_ = loss_object(real, pred)
mask = tf.math.logical_not(tf.math.equal(real, 0))
mask = tf.cast(mask, dtype=loss_.dtype)
loss_ *= mask
return tf.reduce_mean(loss_)
# 定义训练过程
@tf.function
def train_step(inputs, targets, model, optimizer, hidden):
with tf.GradientTape() as tape:
predictions, hidden = model(inputs, hidden)
loss = loss_function(targets, predictions)
gradients = tape.gradient(loss, model.trainable_variables)
optimizer.apply_gradients(zip(gradients, model.trainable_variables))
return loss, hidden
# 初始化模型和优化器
vocab_size = 10000
embedding_dim = 256
hidden_dim = 512
model = DialogModel(vocab_size, embedding_dim, hidden_dim)
optimizer = tf.keras.optimizers.Adam()
# 进行训练
EPOCHS = 10
for epoch in range(EPOCHS):
hidden = model.reset_states()
for inputs, targets in dataset:
loss, hidden = train_step(inputs, targets, model, optimizer, hidden)
print('Epoch {} Loss {:.4f}'.format(epoch + 1, loss.numpy()))위 코드는 컨텍스트 학습 및 생성을 위해 GRU 네트워크를 사용하는 대화 시스템 모델의 단순화된 버전입니다. 학습 과정에서 모델의 매개변수는 손실 함수를 계산하여 최적화됩니다. 실제 적용에서 이 기본 모델은 대화 시스템의 성능을 향상시키기 위해 더욱 개선되고 확장될 수 있습니다.
3. 요약
대화 시스템의 맥락 생성 문제는 역사적 대화 내용을 기반으로 적절한 답변을 생성하는 능력이 필요한 핵심 과제입니다. 이 기사에서는 모델 훈련 및 최적화를 위해 GRU 네트워크 구조를 사용하여 딥 러닝을 기반으로 하는 대화 시스템 컨텍스트 생성을 위한 샘플 코드를 제공합니다. 본 샘플 코드는 단순화된 버전일 뿐이며, 실제 애플리케이션에서는 더욱 복잡한 모델 설계 및 알고리즘 개선이 가능합니다. 지속적인 연구와 최적화를 통해 대화 시스템의 정확성과 유창성을 향상시켜 인간 대화의 특성과 요구에 더욱 부합하도록 만들 수 있습니다.
위 내용은 대화 시스템의 컨텍스트 생성 문제의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

Video Face Swap
완전히 무료인 AI 얼굴 교환 도구를 사용하여 모든 비디오의 얼굴을 쉽게 바꾸세요!

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)



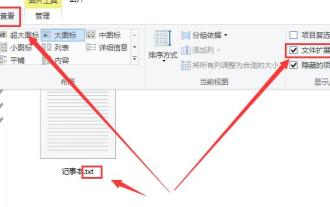 Win10 메모장의 파일 확장자를 변경하는 방법
Jan 04, 2024 pm 12:49 PM
Win10 메모장의 파일 확장자를 변경하는 방법
Jan 04, 2024 pm 12:49 PM
메모장을 사용할 때 처리해야 할 사항이 다르기 때문에 메모장의 확장자를 변경해야 하는데, 확장자를 어떻게 변경해야 할까요? 실제로 확장자를 수정하려면 이름 바꾸기 기능만 사용하면 됩니다. Win10 메모장 확장자를 변경하는 방법: 1. 폴더에서 먼저 상단을 클릭하여 확인합니다. 2. 이렇게 하면 파일 확장자가 표시되며, 메모장을 마우스 오른쪽 버튼으로 클릭하고 3. 다음을 변경합니다. 4. .jpeg 형식으로 변경한 경우. 그러면 안내창이 뜨는데 클릭해주세요. 5. 변경이 완료되었습니다.
 HTML을 MP4 형식으로 변환하는 방법
Feb 19, 2024 pm 02:48 PM
HTML을 MP4 형식으로 변환하는 방법
Feb 19, 2024 pm 02:48 PM
제목: HTML을 MP4 형식으로 변환하는 방법: 자세한 코드 예 일상적인 웹 페이지 제작 과정에서 HTML 페이지나 특정 HTML 요소를 MP4 비디오로 변환해야 하는 경우가 종종 있습니다. 예를 들어 애니메이션 효과, 슬라이드쇼 또는 기타 동적 요소를 비디오 파일로 저장합니다. 이 기사에서는 HTML5와 JavaScript를 사용하여 HTML을 MP4 형식으로 변환하는 방법을 소개하고 구체적인 코드 예제를 제공합니다. HTML5 비디오 태그 및 CanvasAPI HTML5 소개
 SQL 트리거를 호출하여 외부 프로그램 실행
Feb 18, 2024 am 10:25 AM
SQL 트리거를 호출하여 외부 프로그램 실행
Feb 18, 2024 am 10:25 AM
제목: 외부 프로그램을 호출하기 위한 SQL 트리거의 특정 코드 예제 텍스트: SQL 트리거를 사용할 때 일부 특정 작업을 처리하기 위해 외부 프로그램을 호출해야 하는 경우가 있습니다. 이 문서에서는 SQL 트리거에서 외부 프로그램을 호출하는 방법을 소개하고 특정 코드 예제를 제공합니다. 1. 트리거 생성 먼저 데이터베이스에서 이벤트를 수신하는 트리거를 생성해야 합니다. 여기서는 "주문 테이블(order_table)"을 예로 들어보겠습니다. 새 주문이 삽입되면 트리거가 활성화되고 외부 프로그램이 호출되어 작업을 수행합니다.
 덤프 파일을 추출하는 방법
Feb 19, 2024 pm 12:15 PM
덤프 파일을 추출하는 방법
Feb 19, 2024 pm 12:15 PM
덤프 파일을 가져오는 방법 컴퓨터 시스템에서 덤프 파일은 시스템의 작동 상태와 데이터를 기록하는 파일입니다. 소프트웨어 개발 및 시스템 문제 해결에서 덤프 파일을 가져오면 프로그램 개발자와 시스템 관리자가 프로그램 충돌, 메모리 누수 및 시스템 이상과 같은 다양한 문제를 분석하고 진단하는 데 도움이 될 수 있습니다. 이 문서에서는 덤프 파일을 가져오는 몇 가지 일반적인 방법과 도구를 소개합니다. 1. 작업 관리자를 사용하여 Windows 시스템에서 덤프 파일을 가져오는 방법: Windows 운영 체제에서는
 윈도우 12 출시일
Jan 05, 2024 pm 05:24 PM
윈도우 12 출시일
Jan 05, 2024 pm 05:24 PM
이전에 win11이 공식적으로 출시되었고, 이미 많은 사용자들이 win12를 즐기기 시작했습니다. 그들은 실제로 규정에 따르면 2024년쯤에 win12가 출시될 것인지 알고 싶어합니다. win12는 언제 출시되나요? A: Win12는 2024년 가을쯤 출시될 것으로 예상됩니다. 1. Microsoft의 최신 속보 정보에 따르면 win12는 2024년 가을에 출시될 것으로 예상됩니다. 2. 그리고 이번에 win12에는 여러 가지 새로운 디자인 컨셉이 추가될 예정이며, 깔끔함과 시각적인 외관이 더 많이 개선될 것입니다. 3. 최근 개발자 회의에서 Microsoft 개발자들은 작업 표시줄에 떠 있는 느낌을 주기 위해 플로팅 작업 표시줄을 만들겠다고 밝혔습니다.
 NVIDIA 제어판의 역할은 무엇입니까?
Feb 19, 2024 pm 03:59 PM
NVIDIA 제어판의 역할은 무엇입니까?
Feb 19, 2024 pm 03:59 PM
NVIDIA 제어판이란 무엇입니까? 컴퓨터 기술의 급속한 발전으로 인해 그래픽 카드의 중요성이 더욱 중요해졌습니다. 세계 최고의 그래픽 카드 제조업체 중 하나인 NVIDIA의 제어판이 더욱 주목을 받고 있습니다. 그렇다면 NVIDIA 제어판은 정확히 어떤 역할을 할까요? 이 문서에서는 NVIDIA 제어판의 기능과 사용법을 자세히 소개합니다. 먼저 NVIDIA 제어판의 개념과 정의를 살펴보겠습니다. NVIDIA Control Panel은 그래픽 카드 관련 설정을 관리하고 구성하는 데 사용되는 소프트웨어입니다.
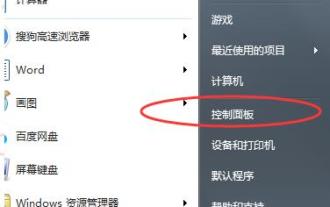 Windows 7 데스크탑 디스플레이 비율을 조정하는 방법
Dec 27, 2023 am 08:13 AM
Windows 7 데스크탑 디스플레이 비율을 조정하는 방법
Dec 27, 2023 am 08:13 AM
win7을 사용하는 친구들이 많은데, 컴퓨터로 영상이나 자료를 볼 때 비율을 조정해야 하는데 어떻게 조정해야 할까요? 자세한 설정 방법을 살펴보겠습니다. win7의 데스크탑 디스플레이 비율을 설정하는 방법: 1. 컴퓨터의 왼쪽 하단 모서리에 있는 을 클릭하여 "제어판"을 엽니다. 2. 그런 다음 제어판에서 "모양"을 찾으십시오. 3. 외형을 입력한 후 "표시"를 클릭하세요. 4. 그런 다음 원하는 디스플레이 효과에 따라 데스크탑의 크기와 디스플레이를 조정할 수 있습니다. 5. 왼쪽의 "해상도 조정"을 클릭할 수도 있습니다. 6. 화면 해상도를 변경하여 컴퓨터 바탕화면의 비율을 조정합니다.
 PyCharm Community Edition과 Professional Edition의 기능 비교
Feb 25, 2024 am 09:54 AM
PyCharm Community Edition과 Professional Edition의 기능 비교
Feb 25, 2024 am 09:54 AM
PyCharm은 JetBrains에서 개발한 Python 개발용 통합 개발 환경(IDE)으로 현재 Community Edition과 Professional Edition의 두 가지 버전이 있습니다. 많은 Python 개발자에게는 적절한 PyCharm 버전을 선택하는 것이 매우 중요합니다. 다양한 기능적 특징이 개발 효율성과 경험에 영향을 미칠 수 있기 때문입니다. 다음은 개발자가 자신에게 적합한 버전을 선택할 수 있도록 PyCharm Community Edition과 Professional Edition의 기능과 특징을 비교합니다. 우선, PyCharm Community Edition은 무료입니다.
