

揭开正则表达式语法的神秘面纱_PHP

正则表达式
正则表达式(REs)通常被错误地认为是只有少数人理解的一种神秘语言。在表面上它们确实看起来杂乱无章,如果你不知道它的语法,那么它的代码在你眼里只是一堆文字垃圾而已。实际上,正则表达式是非常简单并且可以被理解。读完这篇文章后,你将会通晓正则表达式的通用语法。支持多种平台
正则表达式最早是由数学家Stephen Kleene于1956年提出,他是在对自然语言的递增研究成果的基础上提出来的。具有完整语法的正则表达式使用在字符的格式匹配方面上,后来被应用到熔融信息技术领域。自从那时起,正则表达式经过几个时期的发展,现在的标准已经被ISO(国际标准组织)批准和被Open Group组织认定。
正则表达式并非一门专用语言,但它可用于在一个文件或字符里查找和替代文本的一种标准。它具有两种标准:基本的正则表达式(BRE),扩展的正则表达式(ERE)。ERE包括BRE功能和另外其它的概念。
许多程序中都使用了正则表达式,包括xsh,egrep,sed,vi以及在UNIX平台下的程序。它们可以被很多语言采纳,如HTML 和XML,这些采纳通常只是整个标准的一个子集。
比你想象的还要普通
随着正则表达式移植到交叉平台的程序语言的发展,这的功能也日益完整,使用也逐渐广泛。网络上的搜索引擎使用它,e-mail程序也使用它,即使你不是一个UNIX程序员,你也可以使用规则语言来简化你的程序而缩短你的开发时间。
正则表达式101
很多正则表达式的语法看起来很相似,这是因为你以前你没有研究过它们。通配符是RE的一个结构类型,即重复操作。让我们先看一看ERE标准的最通用的基本语法类型。为了能够提供具有特定用途的范例,我将使用几个不同的程序。
字符匹配
正则表达式的关键之处在于确定你要搜索匹配的东西,如果没有这一概念,Res将毫无用处。
每一个表达式都包含需要查找的指令,如表A所示。
|
Table A: Character-matching regular expressions |
|||
|
操作 |
解释 |
例子 |
结果 |
|
. |
Match any one character |
grep .ord sample.txt |
Will match “ford”, “lord”, “2ord”, etc. in the file sample.txt. |
|
[ ] |
Match any one character listed between the brackets |
grep [cng]ord sample.txt |
Will match only “cord”, “nord”, and “gord” |
|
[^ ] |
Match any one character not listed between the brackets |
grep [^cn]ord sample.txt |
Will match “lord”, “2ord”, etc. but not “cord” or “nord” |
|
|
|
grep [a-zA-Z]ord sample.txt |
Will match “aord”, “bord”, “Aord”, “Bord”, etc. |
|
|
|
grep [^0-9]ord sample.txt |
Will match “Aord”, “aord”, etc. but not “2ord”, etc. |
重复操作符
重复操作符,或数量词,都描述了查找一个特定字符的次数。它们常被用于字符匹配语法以查找多行的字符,可参见表B。
|
Table B: Regular expression repetition operators |
|||
|
操作 |
解释 |
例子 |
结果 |
|
? |
Match any character one time, if it exists |
egrep “?erd” sample.txt |
Will match “berd”, “herd”, etc. and “erd” |
|
* |
Match declared element multiple times, if it exists |
egrep “n.*rd” sample.txt |
Will match “nerd”, “nrd”, “neard”, etc. |
|
+ |
Match declared element one or more times |
egrep “[n]+erd” sample.txt |
Will match “nerd”, “nnerd”, etc., but not “erd” |
|
{n} |
Match declared element exactly n times |
egrep “[a-z]{2}erd” sample.txt |
Will match “cherd”, “blerd”, etc. but not “nerd”, “erd”, “buzzerd”, etc. |
|
{n,} |
Match declared element at least n times |
egrep “.{2,}erd” sample.txt |
Will match “cherd” and “buzzerd”, but not “nerd” |
|
{n,N} |
Match declared element at least n times, but not more than N times |
egrep “n[e]{1,2}rd” sample.txt |
Will match “nerd” and “neerd” |
锚是指它所要匹配的格式,如图C所示。使用它能方便你查找通用字符的合并。例如,我用vi行编辑器命令:s来代表substitute,这一命令的基本语法是:
s/pattern_to_match/pattern_to_substitute/
|
Table C: Regular expression anchors |
|||
|
操作 |
解释 |
例子 |
结果 |
|
^ |
Match at the beginning of a line |
s/^/blah / |
Inserts “blah “ at the beginning of the line |
|
$ |
Match at the end of a line |
s/$/ blah/ |
Inserts “ blah” at the end of the line |
|
\ |
Match at the beginning of a word |
s/\/ |
Inserts “blah” at the beginning of the word |
|
|
|
egrep “\ |
Matches “blahfield”, etc. |
|
\> |
Match at the end of a word |
s/\>/blah/ |
Inserts “blah” at the end of the word |
|
|
|
egrep “\>blah” sample.txt |
Matches “soupblah”, etc. |
|
\b |
Match at the beginning or end of a word |
egrep “\bblah” sample.txt |
Matches “blahcake” and “countblah” |
|
\B |
Match in the middle of a word |
egrep “\Bblah” sample.txt |
Matches “sublahper”, etc. |
间隔
Res中的另一可便之处是间隔(或插入)符号。实际上,这一符号相当于一个OR语句并代表|符号。下面的语句返回文件sample.txt中的“nerd” 和 “merd”的句柄:
egrep “(n|m)erd” sample.txt
间隔功能非常强大,特别是当你寻找文件不同拼写的时候,但你可以在下面的例子得到相同的结果:
egrep “[nm]erd” sample.txt
当你使用间隔功能与Res的高级特性连接在一起时,它的真正用处更能体现出来。
一些保留字符
Res的最后一个最重要特性是保留字符(也称特定字符)。例如,如果你想要查找“ne*rd”和“ni*rd”的字符,格式匹配语句“n[ei]*rd”与“neeeeerd” 和 “nieieierd”相符合,但并不是你要查找的字符。因为‘*’(星号)是个保留字符,你必须用一个反斜线符号来替代它,即:“n[ei]\*rd”。其它的保留字符包括:
- ^ (carat)
- . (period)
- [ (left bracket}
- $ (dollar sign)
- ( (left parenthesis)
- ) (right parenthesis)
- | (pipe)
- * (asterisk)
- + (plus symbol)
- ? (question mark)
- { (left curly bracket, or left brace)
- \ backslash
一旦你把以上这些字符包括在你的字符搜索中,毫无疑问Res变得非常的难读。比如说以下的PHP中的eregi搜索引擎代码就很难读了。
eregi("^[_a-z0-9-]+(\.[_a-z0-9-]+)*@[a-z0-9-]+(\.[a-z0-9-]+)*$",$sendto)
你可以看到,程序的意图很难把握。但如果你抛开保留字符,你常常会错误地理解代码的意思。
总结
在本文中,我们揭开了正则表达式的神秘面纱,并列出了ERE标准的通用语法。如果你想阅览Open Group组织的规则的完整描述,你可以参见:Regular Expressions,欢迎你在其中的讨论区发表你的问题或观点。

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7338
7338
 9
1627
14
1352
46
1265
25
1210
29
9
1627
14
1352
46
1265
25
1210
29

 Python 코드를 API로 빠르게 전환하는 방법
Apr 14, 2023 pm 06:28 PM
Python 코드를 API로 빠르게 전환하는 방법
Apr 14, 2023 pm 06:28 PM
API 개발이라고 하면 DjangoRESTFramework, Flask, FastAPI를 떠올릴 수 있습니다. 예, API를 작성하는 데 사용할 수 있습니다. 하지만 오늘 공유되는 프레임워크를 사용하면 기존 기능을 더 빠르게 API로 변환할 수 있습니다. Sanic 소개 Sanic[1]은 성능 향상을 위해 설계된 Python3.7+ 웹 서버 및 웹 프레임워크입니다. Python 3.5에 추가된 async/await 구문을 사용할 수 있으므로 효과적으로 차단을 방지하고 응답 속도를 향상시킬 수 있습니다. Sanic은 간단하고 빠른 생성 및 출시 방법을 제공하기 위해 최선을 다하고 있습니다.
 Word에서 화살표를 입력하는 방법
Apr 16, 2023 pm 11:37 PM
Word에서 화살표를 입력하는 방법
Apr 16, 2023 pm 11:37 PM
자동 고침을 사용하여 Word에서 화살표를 입력하는 방법 Word에서 화살표를 입력하는 가장 빠른 방법 중 하나는 미리 정의된 자동 고침 바로 가기를 사용하는 것입니다. 특정 문자 시퀀스를 입력하면 Word에서는 자동으로 해당 문자를 화살표 기호로 변환합니다. 이 방법을 사용하면 다양한 화살표 스타일을 그릴 수 있습니다. 자동 고침을 사용하여 Word에서 화살표를 입력하려면 문서에서 화살표를 표시할 위치로 커서를 이동합니다. 다음 문자 조합 중 하나를 입력하십시오. 입력한 내용을 화살표 기호로 수정하지 않으려면 키보드의 백스페이스 키를 눌러
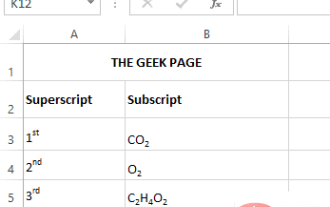 Microsoft Excel에서 위 첨자 및 아래 첨자 서식 옵션을 적용하는 방법
Apr 14, 2023 pm 12:07 PM
Microsoft Excel에서 위 첨자 및 아래 첨자 서식 옵션을 적용하는 방법
Apr 14, 2023 pm 12:07 PM
위 첨자는 일반 텍스트 줄보다 약간 위에 설정해야 하는 문자 또는 숫자입니다. 예를 들어, 1st를 써야 한다면 문자 st는 문자 1보다 약간 높아야 합니다. 마찬가지로 아래 첨자는 문자 그룹 또는 단일 문자이므로 일반 텍스트 수준보다 약간 낮게 설정해야 합니다. 예를 들어, 화학식을 작성할 때 일반 문자 줄 아래에 숫자를 배치해야 합니다. 다음 스크린샷은 위 첨자 및 아래 첨자 형식의 몇 가지 예를 보여줍니다. 어려운 작업처럼 보일 수도 있지만 텍스트에 위 첨자 및 아래 첨자 서식을 적용하는 것은 실제로 매우 간단합니다. 이 기사에서는 위 첨자 또는 아래 첨자를 사용하여 텍스트 서식을 쉽게 지정하는 방법을 몇 가지 간단한 단계로 설명합니다. 이 기사를 재미있게 읽으셨기를 바랍니다. Excel에서 위 첨자를 적용하는 방법
 iPhone 및 Mac에서 도 기호와 같은 확장 문자를 어떻게 입력합니까?
Apr 22, 2023 pm 02:01 PM
iPhone 및 Mac에서 도 기호와 같은 확장 문자를 어떻게 입력합니까?
Apr 22, 2023 pm 02:01 PM
실제 또는 숫자 키보드는 표면에 제한된 수의 문자 옵션을 제공합니다. 하지만 iPhone, iPad, Mac에서는 여러 가지 방법으로 악센트 부호가 있는 문자, 특수 문자 등에 접근할 수 있습니다. 표준 iOS 키보드를 사용하면 대문자와 소문자, 표준 숫자, 구두점 및 문자에 빠르게 액세스할 수 있습니다. 물론 그 외에도 많은 캐릭터들이 있습니다. 발음 구별 부호가 있는 문자부터 거꾸로 된 물음표까지 선택할 수 있습니다. 숨겨진 특별한 캐릭터를 우연히 발견했을 수도 있습니다. 그렇지 않은 경우 iPhone, iPad 및 Mac에서 액세스하는 방법은 다음과 같습니다. iPhone 및 iPad에서 확장 문자에 액세스하는 방법 iPhone 또는 iPad에서 확장 문자를 얻는 방법은 매우 간단합니다. "정보"에서는 "
 java의 Character.isDigit() 함수를 사용하여 문자가 숫자인지 확인합니다.
Jul 27, 2023 am 09:32 AM
java의 Character.isDigit() 함수를 사용하여 문자가 숫자인지 확인합니다.
Jul 27, 2023 am 09:32 AM
Java의 Character.isDigit() 함수를 사용하여 문자가 숫자인지 확인합니다. 문자는 컴퓨터 내부에서 ASCII 코드 형식으로 표시됩니다. 그 중 숫자 0~9에 해당하는 아스키코드 값은 각각 48~57이다. 문자가 숫자인지 확인하려면 Java의 Character 클래스에서 제공하는 isDigit() 메서드를 사용할 수 있습니다. isDigit() 메소드는 Character 클래스에 속합니다.
 matplotlib에서 한자를 표시하는 올바른 방법
Jan 13, 2024 am 11:03 AM
matplotlib에서 한자를 표시하는 올바른 방법
Jan 13, 2024 am 11:03 AM
matplotlib에서 한자를 올바르게 표시하는 것은 많은 중국 사용자가 자주 겪는 문제입니다. 기본적으로 matplotlib는 영어 글꼴을 사용하므로 중국어 문자를 올바르게 표시할 수 없습니다. 이 문제를 해결하려면 올바른 중국어 글꼴을 설정하고 이를 matplotlib에 적용해야 합니다. 다음은 matplotlib에서 중국어 문자를 올바르게 표시하는 데 도움이 되는 몇 가지 특정 코드 예제입니다. 먼저 필수 라이브러리를 가져와야 합니다. importmatplot
 PHP8.0의 새로운 유형 별칭 구문
May 14, 2023 pm 02:21 PM
PHP8.0의 새로운 유형 별칭 구문
May 14, 2023 pm 02:21 PM
PHP 8.0 릴리스에서는 새로운 유형 별칭 구문이 추가되어 사용자 정의 유형을 더 쉽게 사용할 수 있습니다. 이 기사에서는 이 새로운 구문과 이것이 개발자에게 미치는 영향을 자세히 살펴보겠습니다. 유형 별칭이란 무엇입니까? PHP에서 유형 별칭은 기본적으로 다른 유형의 이름을 참조하는 변수입니다. 이 변수는 다른 유형처럼 사용할 수 있으며 코드의 어느 위치에서나 선언할 수 있습니다. 이 구문의 주요 기능은 일반적으로 사용되는 유형에 대한 사용자 정의 별칭을 정의하여 코드를 더 쉽게 읽고 이해할 수 있도록 하는 것입니다.
 람다 표현식의 구문과 구조적 특징은 무엇입니까?
Apr 25, 2024 pm 01:12 PM
람다 표현식의 구문과 구조적 특징은 무엇입니까?
Apr 25, 2024 pm 01:12 PM
람다 표현식은 이름이 없는 익명 함수이며 구문은 (parameter_list)->expression입니다. 익명성, 다양성, 커링 및 폐쇄 기능이 특징입니다. 실제 응용 프로그램에서는 람다 표현식을 사용하여 합산 함수 sum_lambda=lambdax,y:x+y와 같은 함수를 간결하게 정의하고 map() 함수를 목록에 적용하여 합산 작업을 수행할 수 있습니다.
