

누락된 데이터가 모델 정확도에 미치는 영향


누락된 데이터가 모델 정확도에 미치는 영향에는 특정 코드 예제가 필요합니다.
기계 학습 및 데이터 분석 분야에서 데이터는 귀중한 리소스입니다. 그러나 실제 상황에서는 데이터 세트에 데이터가 누락되는 문제가 자주 발생합니다. 누락된 데이터는 데이터 세트에 특정 속성이나 관찰이 없음을 의미합니다. 누락된 데이터는 편향이나 부정확한 예측을 초래할 수 있으므로 모델 정확도에 부정적인 영향을 미칠 수 있습니다. 이 기사에서는 누락된 데이터가 모델 정확도에 미치는 영향을 논의하고 몇 가지 구체적인 코드 예제를 제공합니다.
우선 데이터가 누락되면 모델 학습이 부정확해질 수 있습니다. 예를 들어 분류 문제에서 일부 관찰의 범주 레이블이 누락된 경우 모델은 모델을 훈련할 때 이러한 샘플의 기능과 범주 정보를 올바르게 학습할 수 없습니다. 이는 모델의 정확도에 부정적인 영향을 미쳐 모델의 예측이 다른 기존 범주에 더 편향되게 만듭니다. 이 문제를 해결하기 위한 일반적인 접근 방식은 누락된 데이터를 처리하고 합리적인 전략을 사용하여 누락된 값을 채우는 것입니다. 다음은 구체적인 코드 예입니다.
import pandas as pd
from sklearn.preprocessing import Imputer
# 读取数据
data = pd.read_csv("data.csv")
# 创建Imputer对象
imputer = Imputer(missing_values='NaN', strategy='mean', axis=0)
# 填充缺失值
data_filled = imputer.fit_transform(data)
# 训练模型
# ...위 코드에서는 sklearn.preprocessing 모듈의 Imputer 클래스를 사용하여 누락된 값을 처리합니다. Imputer 클래스는 평균, 중앙값 또는 가장 빈번한 값을 사용하여 누락된 값을 채우는 등 누락된 값을 채우기 위한 다양한 전략을 제공합니다. 위의 예에서는 평균을 사용하여 누락된 값을 채웠습니다. sklearn.preprocessing模块中的Imputer类来处理缺失值。Imputer类提供了多种填充缺失值的策略,例如使用均值、中位数或者出现频率最高的值来填充缺失值。在上面的例子中,我们使用了均值来填充缺失值。
其次,数据缺失还可能会对模型的评估和验证产生不利的影响。在许多模型评估和验证的指标中,对缺失数据的处理是十分关键的。如果不正确处理缺失数据,那么评估指标可能会产生偏差,并无法准确反映模型在真实场景中的性能。以下是一个使用交叉验证评估模型的示例代码:
import pandas as pd
from sklearn.model_selection import cross_val_score
from sklearn.linear_model import LogisticRegression
# 读取数据
data = pd.read_csv("data.csv")
# 创建模型
model = LogisticRegression()
# 填充缺失值
imputer = Imputer(missing_values='NaN', strategy='mean', axis=0)
data_filled = imputer.fit_transform(data)
# 交叉验证评估模型
scores = cross_val_score(model, data_filled, target, cv=10)
avg_score = scores.mean()在上面的代码中,我们使用了sklearn.model_selection模块中的cross_val_score函数来进行交叉验证评估。在使用交叉验证之前,我们先使用Imputer
rrreee
위 코드에서는sklearn.model_selection 모듈의 cross_val_score 함수를 사용하여 교차 검증을 수행했습니다. 검증 평가합니다. 교차 검증을 사용하기 전에 먼저 Imputer 클래스를 사용하여 누락된 값을 채웁니다. 이를 통해 평가 지표가 실제 시나리오의 모델 성능을 정확하게 반영할 수 있습니다. 🎜🎜요약하자면, 누락된 데이터가 모델 정확도에 미치는 영향은 진지하게 받아들여야 하는 중요한 문제입니다. 누락된 데이터를 처리할 때 적절한 방법을 사용하여 누락된 값을 채울 수 있으며 모델 평가 및 검증 중에 누락된 데이터를 올바르게 처리해야 합니다. 이를 통해 모델이 실제 응용 분야에서 높은 정확도와 일반화 능력을 갖도록 보장할 수 있습니다. 위 내용은 누락된 데이터가 모델 정확도에 미치는 영향에 대한 소개이며, 몇 가지 구체적인 코드 예제가 제공됩니다. 독자들이 이 책에서 영감을 얻고 도움을 받을 수 있기를 바랍니다. 🎜위 내용은 누락된 데이터가 모델 정확도에 미치는 영향의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7473
7473
 15
1377
52
77
11
48
19
19
30
15
1377
52
77
11
48
19
19
30

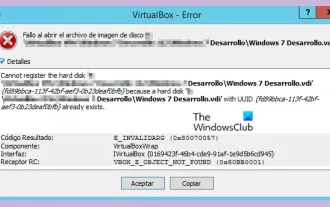 VBOX_E_OBJECT_NOT_FOUND(0x80bb0001)VirtualBox 오류
Mar 24, 2024 am 09:51 AM
VBOX_E_OBJECT_NOT_FOUND(0x80bb0001)VirtualBox 오류
Mar 24, 2024 am 09:51 AM
VirtualBox에서 디스크 이미지를 열려고 하면 하드 드라이브를 등록할 수 없다는 오류가 발생할 수 있습니다. 이는 일반적으로 열려고 하는 VM 디스크 이미지 파일이 다른 가상 디스크 이미지 파일과 동일한 UUID를 가질 때 발생합니다. 이 경우 VirtualBox는 오류 코드 VBOX_E_OBJECT_NOT_FOUND(0x80bb0001)를 표시합니다. 이 오류가 발생하더라도 걱정하지 마세요. 시도해 볼 수 있는 몇 가지 해결 방법이 있습니다. 먼저 VirtualBox의 명령줄 도구를 사용하여 디스크 이미지 파일의 UUID를 변경하면 충돌을 피할 수 있습니다. 'VBoxManageinternal' 명령을 실행할 수 있습니다.
 비행기 모드를 사용하여 전화를 받는 것이 얼마나 효과적인가요?
Feb 20, 2024 am 10:07 AM
비행기 모드를 사용하여 전화를 받는 것이 얼마나 효과적인가요?
Feb 20, 2024 am 10:07 AM
비행기 모드로 전화를 걸면 어떻게 될까요? 휴대폰은 사람들의 삶에 없어서는 안될 도구 중 하나가 되었습니다. 휴대폰은 의사소통 도구일 뿐만 아니라 오락, 학습, 업무 및 기타 기능의 집합체이기도 합니다. 휴대폰 기능의 지속적인 업그레이드와 개선으로 인해 사람들은 휴대폰에 대한 의존도가 점점 더 높아지고 있습니다. 비행기 모드의 등장으로 사람들은 비행 중에 휴대폰을 더욱 편리하게 사용할 수 있게 되었습니다. 하지만 비행기 모드에서 다른 사람의 통화가 휴대폰이나 사용자에게 어떤 영향을 미칠지 걱정하시는 분들도 계시죠? 이 글에서는 여러 측면에서 분석하고 논의할 것이다. 첫 번째
 Java의 파일 포함 취약점과 그 영향
Aug 08, 2023 am 10:30 AM
Java의 파일 포함 취약점과 그 영향
Aug 08, 2023 am 10:30 AM
Java는 다양한 애플리케이션을 개발하는 데 일반적으로 사용되는 프로그래밍 언어입니다. 그러나 다른 프로그래밍 언어와 마찬가지로 Java에도 보안 취약점과 위험이 있습니다. 일반적인 취약점 중 하나는 파일 포함 취약점(FileInclusionVulnerability)입니다. 이 문서에서는 이 취약점의 원리, 영향 및 방지 방법을 살펴봅니다. 파일 인클루젼 취약점은 프로그램 내에서 다른 파일을 동적으로 도입하거나 포함시키지만, 도입된 파일이 완전히 검증 및 보호되지 않는 취약점을 말합니다.
 TikTok에서 댓글 기능을 끄는 방법은 무엇입니까? TikTok에서 댓글 기능을 끄면 어떻게 되나요?
Mar 23, 2024 pm 06:20 PM
TikTok에서 댓글 기능을 끄는 방법은 무엇입니까? TikTok에서 댓글 기능을 끄면 어떻게 되나요?
Mar 23, 2024 pm 06:20 PM
Douyin 플랫폼에서 사용자는 인생의 순간을 공유할 수 있을 뿐만 아니라 다른 사용자와 상호 작용할 수도 있습니다. 때로는 댓글 기능이 온라인 폭력, 악성 댓글 등 불쾌한 경험을 유발할 수 있습니다. 그렇다면 TikTok의 댓글 기능을 끄는 방법은 무엇입니까? 1. Douyin의 댓글 기능을 끄는 방법은 무엇입니까? 1. Douyin APP에 로그인하고 개인 홈페이지에 들어가세요. 2. 오른쪽 하단의 "I"를 클릭하여 설정 메뉴로 들어갑니다. 3. 설정 메뉴에서 "개인정보 설정"을 찾으세요. 4. "개인정보 설정"을 클릭하여 개인정보 설정 인터페이스로 들어갑니다. 5. 개인정보 설정 인터페이스에서 "댓글 설정"을 찾으세요. 6. "댓글 설정"을 클릭하여 댓글 설정 인터페이스로 들어갑니다. 7. 댓글 설정 인터페이스에서 '댓글 닫기' 옵션을 찾으세요. 8. "댓글 닫기" 옵션을 클릭하여 댓글 닫기를 확인하세요.
 데이터 부족이 모델 학습에 미치는 영향
Oct 08, 2023 pm 06:17 PM
데이터 부족이 모델 학습에 미치는 영향
Oct 08, 2023 pm 06:17 PM
데이터 부족이 모델 학습에 미치는 영향에는 특정 코드 예제가 필요합니다. 기계 학습 및 인공 지능 분야에서 데이터는 모델 학습의 핵심 요소 중 하나입니다. 그러나 현실에서 우리가 자주 직면하는 문제는 데이터의 부족입니다. 데이터 희소성은 훈련 데이터의 양이 부족하거나 주석이 달린 데이터가 부족한 것을 의미합니다. 이 경우 모델 훈련에 일정한 영향을 미칩니다. 데이터 부족 문제는 주로 다음과 같은 측면에서 나타납니다. 과적합(Overfitting): 훈련 데이터의 양이 부족하면 모델이 과적합되기 쉽습니다. 과적합은 모델이 훈련 데이터에 과도하게 적응하는 것을 말합니다.
 하드 드라이브의 불량 섹터로 인해 어떤 문제가 발생합니까?
Feb 18, 2024 am 10:07 AM
하드 드라이브의 불량 섹터로 인해 어떤 문제가 발생합니까?
Feb 18, 2024 am 10:07 AM
하드디스크의 배드섹터(Bad Sector)란 하드디스크의 물리적인 고장, 즉 하드디스크의 저장장치가 정상적으로 데이터를 읽거나 쓸 수 없는 상태를 의미합니다. 불량 섹터가 하드 드라이브에 미치는 영향은 매우 크며 데이터 손실, 시스템 충돌 및 하드 드라이브 성능 저하로 이어질 수 있습니다. 이 기사에서는 하드 드라이브 불량 섹터의 영향과 관련 솔루션을 자세히 소개합니다. 첫째, 하드 드라이브의 불량 섹터로 인해 데이터가 손실될 수 있습니다. 하드 디스크의 섹터에 불량 섹터가 있으면 해당 섹터의 데이터를 읽을 수 없어 파일이 손상되거나 액세스할 수 없게 됩니다. 불량 섹터가 위치한 섹터에 중요한 파일이 저장되어 있는 경우 이러한 상황은 특히 심각합니다.
 광산 카드가 게임에 구체적으로 어떤 영향을 미치나요?
Jan 03, 2024 am 09:05 AM
광산 카드가 게임에 구체적으로 어떤 영향을 미치나요?
Jan 03, 2024 am 09:05 AM
일부 사용자는 저렴함을 위해 마이닝 카드 구매를 고려할 수도 있습니다. 그러나 일부 게이머는 마이닝 카드가 게임 플레이에 미치는 영향을 걱정합니다. . 마이닝 카드를 사용하여 게임을 할 때의 효과는 무엇입니까? 1. 마이닝 카드의 수명이 매우 짧고 그냥 플레이한 후에는 쓸모가 없게 될 가능성이 높기 때문에 마이닝 카드를 사용한 게임 플레이의 안정성은 보장할 수 없습니다. 2. 마이닝 카드는 기본적으로 원본 버전의 거세 버전이므로 장기간 마모로 인해 모든 측면에서 성능이 약할 수 있습니다. 3. 이와 같은 방법으로 이용자는 게임 플레이 시 게임의 효과를 모두 표현하지 못할 수도 있습니다. 4. 게다가 그래픽 카드의 전자 부품은 미리 노후화되며, 게임을 하는 것도 그래픽 카드를 소모하기 때문에 소모되는 정도가 크기 때문에 게임에 미치는 영향이 큽니다. 5. 일반적으로 게임을 할 때는 마이닝 카드를 사용합니다.
 낮은 그래픽 카드 구성은 어떤 영향을 미치나요?
Feb 15, 2024 pm 03:27 PM
낮은 그래픽 카드 구성은 어떤 영향을 미치나요?
Feb 15, 2024 pm 03:27 PM
컴퓨터의 실행 품질은 기본적으로 그래픽 카드에 큰 영향을 미칩니다. 일부 사용자는 그래픽 카드에 대해 잘 모르고 그래픽 카드가 컴퓨터의 어떤 측면에 영향을 미치는지 정확히 알지 못합니다. 낮은 그래픽 카드 구성에 따른 몇 가지 효과를 소개하겠습니다. 낮은 그래픽 카드 구성의 영향은 무엇입니까? 답변: 1. 일부 대규모 3D 게임은 실행할 수 없습니다. 2. 일부 고화질 비디오를 재생할 때 컴퓨터는 큰 압박을 받게 됩니다. 3. 좀 더 전문적인 소프트웨어의 경우 도면 및 3D 모델 렌더링이 필요할 때 제대로 실행할 방법이 없습니다. 4. 그래픽 카드 구성이 낮으면 게임을 열 수 없거나 자주 충돌하고 정지되며 컴퓨터 화면도 흐려지거나 블루 스크린이 나타납니다. 5. 게임에서 가장 중요한 것은 그래픽 카드입니다. 많은 사진이 필요하기 때문입니다.
