

역 사고: MetaMath의 새로운 수학적 추론 언어 모델은 대형 모델을 훈련시킵니다.

복잡한 수학적 추론은 대규모 언어 모델의 추론 능력을 평가하는 중요한 지표입니다. 현재 일반적으로 사용되는 수학적 추론 데이터 세트는 표본 크기가 제한되어 있고 문제 다양성이 부족하여 대규모로 "저주 반전" 현상이 나타나고 있습니다. 언어 모델, 즉 "A"에 대해 훈련받은 사람 "is B"라는 언어 모델은 "B is A"로 일반화될 수 없습니다[1]. 수학적 추론 작업에서 이러한 현상의 구체적인 형태는 다음과 같습니다. 수학적 문제가 주어지면 언어 모델은 문제를 해결하기 위해 순방향 추론을 사용하는 데 능숙하지만 역추론으로 문제를 해결하는 능력이 부족합니다. 역추론은 다음 2가지 예에서 볼 수 있듯이 수학 문제에서 매우 일반적입니다.
1. 같은 우리에 닭과 토끼
- 추론: 우리 안에는 닭 23마리와 토끼 12마리가 있습니다.
- 역추론: 같은 우리에 여러 마리의 닭과 토끼가 있습니다. 위에서부터 세어 보면 머리가 35개이고, 아래에서 세어 보면 다리가 94개입니다. 우리 안에 닭과 토끼가 몇 마리 있나요?
2. GSM8K 문제
- 정확한 추론: James는 각각 4파운드인 쇠고기 5팩을 구입했습니다. 쇠고기 가격은 파운드당 $5.50입니다.
- 역추론. : James는 각각 4파운드인 쇠고기 x팩을 구입했습니다. 쇠고기 가격은 파운드당 $5.50입니다. 위 질문에 대한 답이 110이라는 것을 안다면, 알 수 없는 변수 x의 값은 얼마입니까?
모델의 순방향 및 역방향 추론 기능을 향상시키기 위해 Cambridge, Hong Kong University of Science and Technology 및 Huawei의 연구원은 일반적으로 사용되는 두 가지 수학적 데이터 세트(GSM8K 및 MATH)를 기반으로 MetaMathQA 데이터 세트를 제안했습니다. : 넓은 적용 범위와 고품질의 수학적 추론 데이터 세트를 갖춘 것. MetaMathQA는 대규모 언어 모델에 의해 생성된 395K개의 정역수 수학 질문-답변 쌍으로 구성됩니다. 그들은 MetaMathQA 데이터 세트에서 LLaMA-2를 미세 조정하여 수학적 추론(정방향 및 역방향)에 초점을 맞춘 대규모 언어 모델인 MetaMath를 얻었으며 이는 수학적 추론 데이터 세트에서 SOTA에 도달했습니다. 다양한 규모의 MetaMathQA 데이터 세트와 MetaMath 모델은 연구자들이 사용할 수 있도록 오픈 소스로 제공되었습니다.

- 프로젝트 주소: https://meta-math.github.io/
- 논문 주소: https://arxiv.org/abs/2309.12284
- 데이터 주소: https: //huggingface.co/datasets/meta-math/MetaMathQA
- 모델 주소: https://huggingface.co/meta-math
- 코드 주소: https://github.com/meta-math/ MetaMath
GSM8K-Backward 데이터 세트에서 역추론 실험을 구성했습니다. 실험 결과에 따르면 SFT, RFT 및 WizardMath와 같은 방법과 비교하여 현재 방법은 역추론 문제에서 성능이 좋지 않은 것으로 나타났습니다. 대조적으로 MetaMath 모델은 순방향 추론과 역방향 추론 모두에서 탁월한 성능을 달성합니다. 1. 답변 확대:
질문이 주어지면 올바른 결과를 얻을 수 있는 사고 체인이 데이터 증강으로 대규모 언어 모델을 통해 생성됩니다. 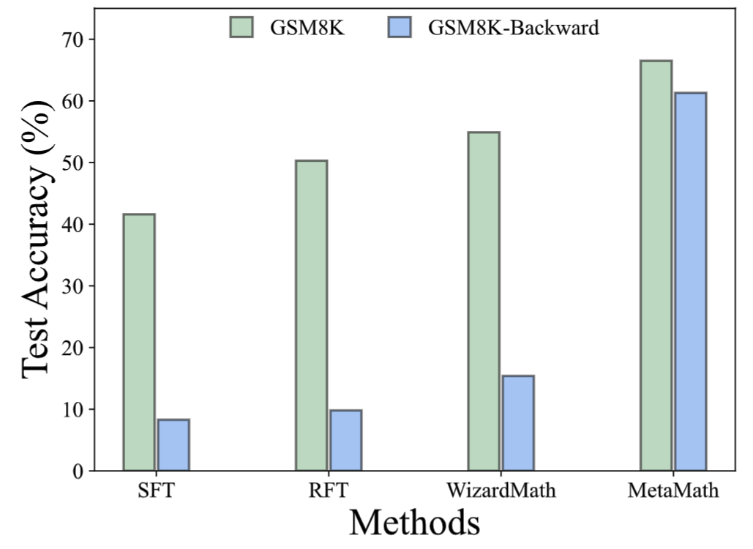
질문: 제임스는 4파운드짜리 쇠고기 5팩을 삽니다. 쇠고기 가격은 파운드당 $5.50입니다.
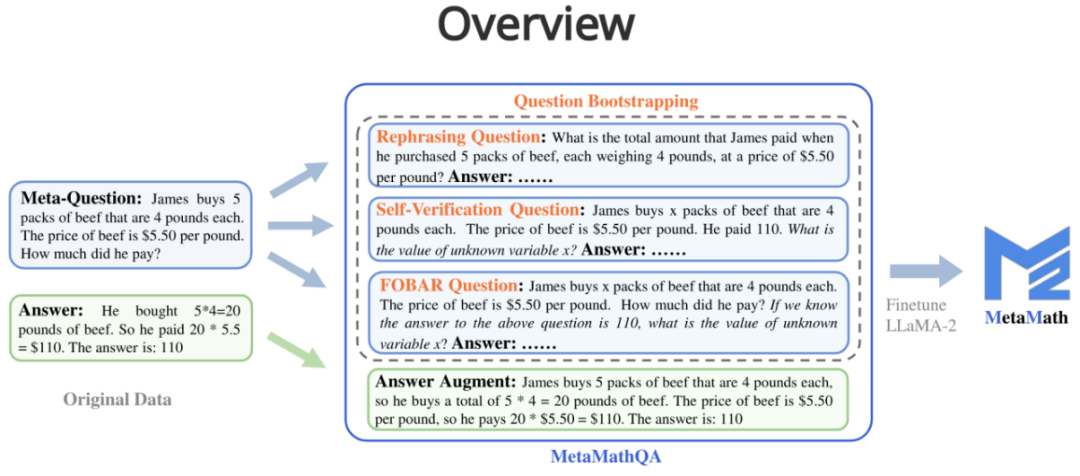 답변: 제임스는 4파운드짜리 쇠고기 5팩을 삽니다. 그래서 그는 총 5 * 4 = 20파운드의 쇠고기를 구매합니다. 쇠고기 가격은 파운드당 $5.50이므로 그는 20 * $5.50 = $110를 지불합니다.
답변: 제임스는 4파운드짜리 쇠고기 5팩을 삽니다. 그래서 그는 총 5 * 4 = 20파운드의 쇠고기를 구매합니다. 쇠고기 가격은 파운드당 $5.50이므로 그는 20 * $5.50 = $110를 지불합니다.
2. 질문(질문 재작성 강화):
메타 질문이 주어지면 대규모 언어 모델을 통해 질문을 재작성하고 데이터 증강으로 올바른 결과를 얻는 사고 체인을 생성합니다.
- 질문: 제임스가 각각 무게가 4파운드인 쇠고기 5팩을 파운드당 $5.50에 구매할 때 지불한 총 금액은 얼마입니까?
- 답변: 쇠고기 한 팩의 무게는 4파운드이므로 5팩입니다. 팩의 무게는 총 4 * 5 = 20파운드입니다. 쇠고기 1파운드당 가격은 $5.50이므로 20파운드의 총 비용은 20 * $5.50 = $110입니다. 따라서 James가 지불한 금액은 $110입니다.
3. FOBAR 질문(FOBAR 역질문 강화): 메타 질문이 있는 경우 마스크 조건의 숫자는 x이며, 원래 답변이 주어지고 x를 반전하여 역질문을 생성합니다. 이 역 문제는 데이터 증대를 수행하기 위한 올바른 사고 체인을 생성합니다(역전의 예: "위 질문에 대한 답이 110이라는 것을 알고 있다면 알 수 없는 변수 x의 값은 무엇입니까?").
- 질문: James는 각각 4파운드인 쇠고기 x팩을 구입했습니다. 쇠고기 가격은 파운드당 $5.50입니다. 위 질문에 대한 답이 110이라는 것을 안다면 그 가치는 얼마입니까? 의 알 수 없는 변수 x?
- 답변: James는 각각 4파운드인 쇠고기 x팩을 구입하므로 총 4x파운드의 쇠고기를 구입합니다. 쇠고기 가격은 파운드당 $5.50이므로 쇠고기의 총 비용은 다음과 같습니다. 는 5.50 * 4x = 22x입니다. 총 비용은 $110이므로 다음과 같이 쓸 수 있습니다. 22x = 110. 양변을 22로 나누면 x = 5가 됩니다. x의 값은 5입니다.
4. 자가 검증 질문(자가 검증 역질문 강화): FOBAR를 기반으로 역질문 부분을 대규모 언어 모델을 통해 문장으로 재작성하여 데이터 증대를 수행합니다. 그는 지불합니까?”(답은 110)는 “그는 110을 지불했습니다”로 다시 작성되었습니다.
- 질문: James는 각각 4파운드인 쇠고기 x팩을 구입합니다. 쇠고기 가격은 파운드당 $5.50입니다. 그는 110을 지불했습니다. 알 수 없는 변수 x의 값은 무엇입니까?
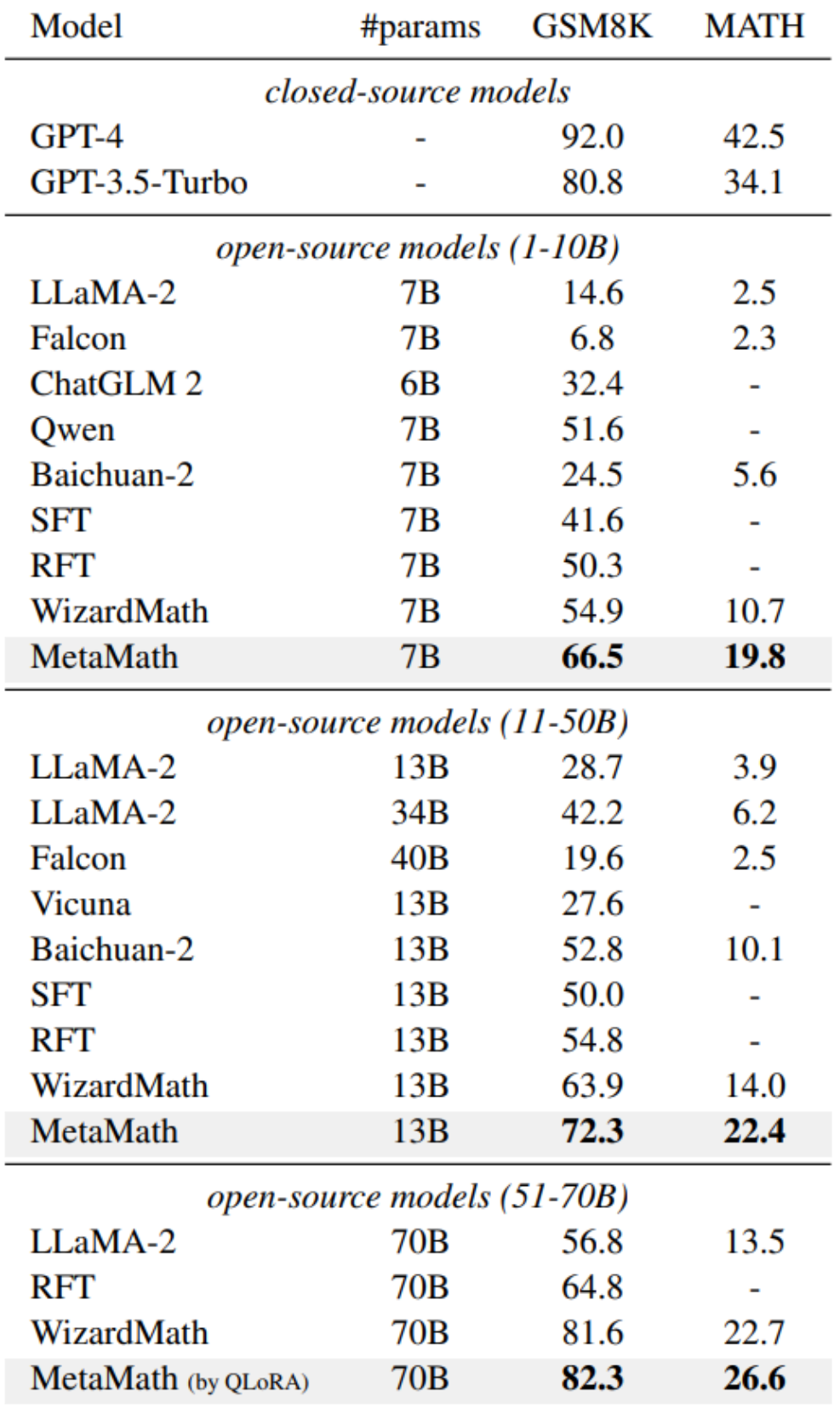
- 답변: 이 문제를 해결하려면 문제를 해결하려면 James가 구입한 쇠고기 팩 수를 나타내는 x 값을 결정해야 합니다. 쇠고기 한 팩의 무게는 파운드당 5.50달러입니다. 우리는 James가 지불한 총 금액이 $110임을 알 수 있습니다. 다음과 같습니다: 쇠고기 팩 수 * 팩당 무게 * 파운드당 가격 = 지불된 총 금액 x * 4 * $5.50 = $110 x를 단순화하여 계산해 보겠습니다. 4x * $5.50 = $110; 방정식의 양쪽을 22로 나눕니다: 22x / 22 = $110 / 22; x = $5; 수학적 추론 데이터 세트(GSM8K 및 MATH)에 대한 실험 결과는 MetaMath가 기존 개방형보다 훨씬 우수하다는 것을 보여줍니다. LLM 모델의 성능을 향상시키며 외부 도구(예: 코드 해석기)를 사용할 필요가 없습니다. 그 중 MetaMath-7B 모델은 GSM8K에서 66.5%, MATH에서 19.8%의 정확도에 도달했는데, 이는 동일한 규모의 최신 모델보다 각각 11.6%, 9.1% 더 높습니다. 특히 MetaMath-70B가 GSM8K에서 GPT-3.5-Turbo
를 초과하는 82.3%의 정확도를 달성했다는 점은 언급할 가치가 있습니다. "표면 정렬 가설"[2]에 따르면 대규모 언어 모델의 능력은 사전에 다운스트림 작업의 데이터는 사전 훈련 중에 학습된 언어 모델의 고유 기능을 활성화합니다. 따라서 이는 두 가지 중요한 질문을 제기합니다. (i) 어떤 유형의 데이터가 잠재 지식을 가장 효과적으로 활성화하는지, 그리고 (ii) 한 데이터 세트가 다른 데이터 세트보다 그러한 활성화에 더 나은 이유는 무엇입니까?
 MetaMathQA가 왜 유용한가요? 사고체인 데이터의 품질(Perplexity) 향상
MetaMathQA가 왜 유용한가요? 사고체인 데이터의 품질(Perplexity) 향상
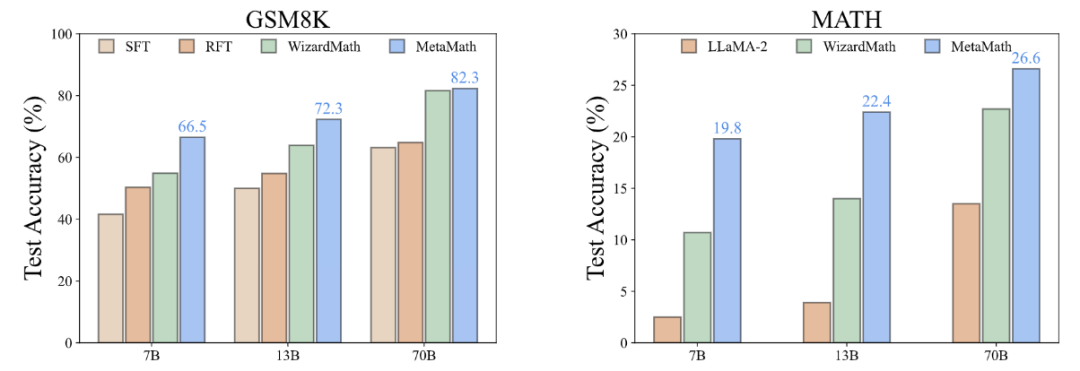
위 그림과 같이 연구진은 답변 전용 데이터인 GSM8K CoT의 각 부분에서 LLaMA-2-7B 모델을 계산했습니다. MetaMathQA 데이터는 혼란 수준을 설정합니다. MetaMathQA 데이터 세트의 복잡성은 다른 두 데이터 세트보다 현저히 낮습니다. 이는 학습 가능성이 더 높고 모델의 잠재 지식을 드러내는 데 더 도움이 될 수 있음을 나타냅니다
MetaMathQA가 유용한 이유는 무엇인가요? 사고체인 데이터의 다양성 증가 데이터의 다양성 이득과 모델의 정확도 이득을 비교한 결과, 연구원들은 재구성, FOBAR 및 SV를 통해 동일한 양의 증강 데이터를 도입하면 모두 명백한 다양성 이득을 가져오고 모델이 크게 향상된다는 것을 발견했습니다. 정확성. 대조적으로, 답변 확대만을 사용하면 정확도가 상당히 포화되었습니다. 정확도가 포화 상태에 도달한 후 AnsAug 데이터를 추가해도 성능 향상은 제한적입니다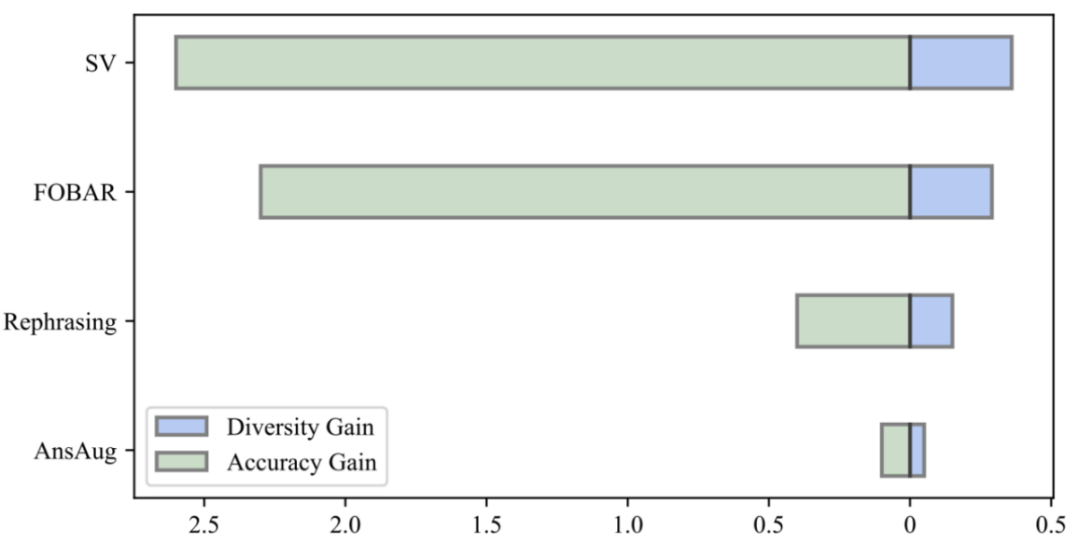
위 내용은 역 사고: MetaMath의 새로운 수학적 추론 언어 모델은 대형 모델을 훈련시킵니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

Video Face Swap
완전히 무료인 AI 얼굴 교환 도구를 사용하여 모든 비디오의 얼굴을 쉽게 바꾸세요!

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7762
7762
 15
1644
14
1399
52
1293
25
1234
29
15
1644
14
1399
52
1293
25
1234
29

 Worldcoin (WLD) 가격 예측 2025-2031 : WLD가 2031 년까지 4 달러에 도달 할 것인가?
Apr 21, 2025 pm 02:42 PM
Worldcoin (WLD) 가격 예측 2025-2031 : WLD가 2031 년까지 4 달러에 도달 할 것인가?
Apr 21, 2025 pm 02:42 PM
Worldcoin (WLD)은 Cryptocurrency 시장에서 고유 한 생체 인정 및 개인 정보 보호 메커니즘으로 눈에 띄고 많은 투자자의 관심을 끌고 있습니다. WLD는 혁신적인 기술, 특히 OpenAi 인공 지능 기술과 함께 Altcoins에서 뛰어난 성과를 거두었습니다. 그러나 향후 몇 년 안에 디지털 자산은 어떻게 행동 할 것인가? WLD의 미래 가격을 함께 예측합시다. 2025 WLD 가격 예측은 2025 년 WLD에서 상당한 성장을 달성 할 것으로 예상됩니다. 시장 분석에 따르면 평균 WLD 가격은 최대 $ 1.36로 $ 1.31에 도달 할 수 있습니다. 그러나 곰 시장에서 가격은 약 $ 0.55로 떨어질 수 있습니다. 이러한 성장 기대는 주로 WorldCoin2에 기인합니다.
 가상 통화 가격의 상승 또는 하락은 왜입니까? 가상 통화 가격의 상승 또는 하락은 왜입니까?
Apr 21, 2025 am 08:57 AM
가상 통화 가격의 상승 또는 하락은 왜입니까? 가상 통화 가격의 상승 또는 하락은 왜입니까?
Apr 21, 2025 am 08:57 AM
가상 통화 가격 상승의 요인은 다음과 같습니다. 1. 시장 수요 증가, 2. 공급 감소, 3. 긍정적 인 뉴스, 4. 낙관적 시장 감정, 5. 거시 경제 환경; 감소 요인에는 다음이 포함됩니다. 1. 시장 수요 감소, 2. 공급 증가, 3. 부정적인 뉴스의 파업, 4. 비관적 시장 감정, 5. 거시 경제 환경.
 크로스 체인 거래는 무엇을 의미합니까? 크로스 체인 거래는 무엇입니까?
Apr 21, 2025 pm 11:39 PM
크로스 체인 거래는 무엇을 의미합니까? 크로스 체인 거래는 무엇입니까?
Apr 21, 2025 pm 11:39 PM
크로스 체인 거래를 지원하는 교환 : 1. Binance, 2. Uniswap, 3. Sushiswap, 4. Curve Finance, 5. Thorchain, 6. 1inch Exchange, 7. DLN 거래,이 플랫폼은 다양한 기술을 통해 다중 체인 자산 거래를 지원합니다.
 통화 서클 시장의 실시간 데이터에 대한 상위 10 개 무료 플랫폼 권장 사항이 출시됩니다.
Apr 22, 2025 am 08:12 AM
통화 서클 시장의 실시간 데이터에 대한 상위 10 개 무료 플랫폼 권장 사항이 출시됩니다.
Apr 22, 2025 am 08:12 AM
초보자에게 적합한 cryptocurrency 데이터 플랫폼에는 CoinmarketCap 및 비소 트럼펫이 포함됩니다. 1. CoinmarketCap은 초보자 및 기본 분석 요구에 대한 글로벌 실시간 가격, 시장 가치 및 거래량 순위를 제공합니다. 2. 비소 인용문은 중국 사용자가 저 위험 잠재적 프로젝트를 신속하게 선별하는 데 적합한 중국 친화적 인 인터페이스를 제공합니다.
 Binance 전체 프로세스 전략에 대한 커널 에어 드롭 보상을받는 방법
Apr 21, 2025 pm 01:03 PM
Binance 전체 프로세스 전략에 대한 커널 에어 드롭 보상을받는 방법
Apr 21, 2025 pm 01:03 PM
암호 화폐의 번화 한 세계에서는 새로운 기회가 항상 나타납니다. 현재 Kerneldao (Kernel) 에어 드롭 활동은 많은 관심을 끌고 많은 투자자들의 관심을 끌고 있습니다. 그렇다면이 프로젝트의 기원은 무엇입니까? BNB 보유자는 어떤 이점을 얻을 수 있습니까? 걱정하지 마십시오. 다음은 당신을 위해 하나씩 공개 할 것입니다.
 Rexas Finance (RXS)는 2025 년 Solana (Sol), Cardano (ADA), XRP 및 Dogecoin (Doge)을 능가 할 수 있습니다.
Apr 21, 2025 pm 02:30 PM
Rexas Finance (RXS)는 2025 년 Solana (Sol), Cardano (ADA), XRP 및 Dogecoin (Doge)을 능가 할 수 있습니다.
Apr 21, 2025 pm 02:30 PM
휘발성 cryptocurrency 시장에서 투자자들은 대중적인 통화를 넘어서는 대안을 찾고 있습니다. Solana (Sol), Cardano (ADA), XRP 및 Dogecoin (DOGE)과 같은 잘 알려진 암호 화폐도 시장 감정, 규제 불확실성 및 확장 성과 같은 도전에 직면 해 있습니다. 그러나 새로운 신흥 프로젝트 인 Rexasfinance (RXS)가 떠오르고 있습니다. 유명 인사 효과 나 과대 광고에 의존하지는 않지만 RWA (Ralld Assets)와 블록 체인 기술을 결합하여 투자자에게 혁신적인 투자 방법을 제공하는 데 중점을 둡니다. 이 전략은 2025 년의 가장 성공적인 프로젝트 중 하나가되기를 희망합니다. Rexasfi
 Aavenomics는 AAVE 프로토콜 토큰을 수정하고 쿼럼 수의 사람들에게 도달 한 토큰 재구매를 소개하는 권장 사항입니다.
Apr 21, 2025 pm 06:24 PM
Aavenomics는 AAVE 프로토콜 토큰을 수정하고 쿼럼 수의 사람들에게 도달 한 토큰 재구매를 소개하는 권장 사항입니다.
Apr 21, 2025 pm 06:24 PM
Aavenomics는 AAVE 프로토콜 토큰을 수정하고 Aavedao의 쿼럼을 구현 한 Token Repos를 소개하는 제안입니다. AAVE 프로젝트 체인 (ACI)의 설립자 인 Marc Zeller는 X에서 이것을 발표하여 계약의 새로운 시대를 표시한다고 지적했습니다. AAVE 체인 이니셔티브 (ACI)의 설립자 인 Marc Zeller는 AAVENOMICS 제안서에 AAVE 프로토콜 토큰 수정 및 토큰 리포지션 도입이 포함되어 있다고 X에서 AAVEDAO에 대한 쿼럼을 달성했다고 발표했습니다. Zeller에 따르면, 이것은 계약의 새로운 시대를 나타냅니다. Aavedao 회원국은 수요일에 주당 100 인 제안을지지하기 위해 압도적으로 투표했습니다.
 비트 코인 완제품 구조의 분석 차트는 무엇입니까? 그리는 방법?
Apr 21, 2025 pm 07:42 PM
비트 코인 완제품 구조의 분석 차트는 무엇입니까? 그리는 방법?
Apr 21, 2025 pm 07:42 PM
비트 코인 구조 분석 차트를 그리는 단계에는 다음이 포함됩니다. 1. 도면의 목적과 청중 결정, 2. 올바른 도구 선택, 3. 프레임 워크 설계 및 핵심 구성 요소를 채우십시오. 4. 기존 템플릿을 참조하십시오. 완전한 단계는 차트가 정확하고 이해하기 쉽도록합니다.
