
Builder News 10월 12일, 최근 Zhipu AI & Tsinghua KEG는 Moda 커뮤니티에서 다중 모달 대형 모델인 CogVLM-17B를 출시하고 직접 오픈 소스화했습니다. CogVLM은 시각적 전문가 모듈을 사용하여 언어 코딩과 시각적 코딩을 심층적으로 통합하는 강력한 오픈 소스 시각적 언어 모델이며 14개의 권위 있는 크로스 모달 벤치마크에서 SOTA 성능을 달성한 것으로 보고되었습니다.
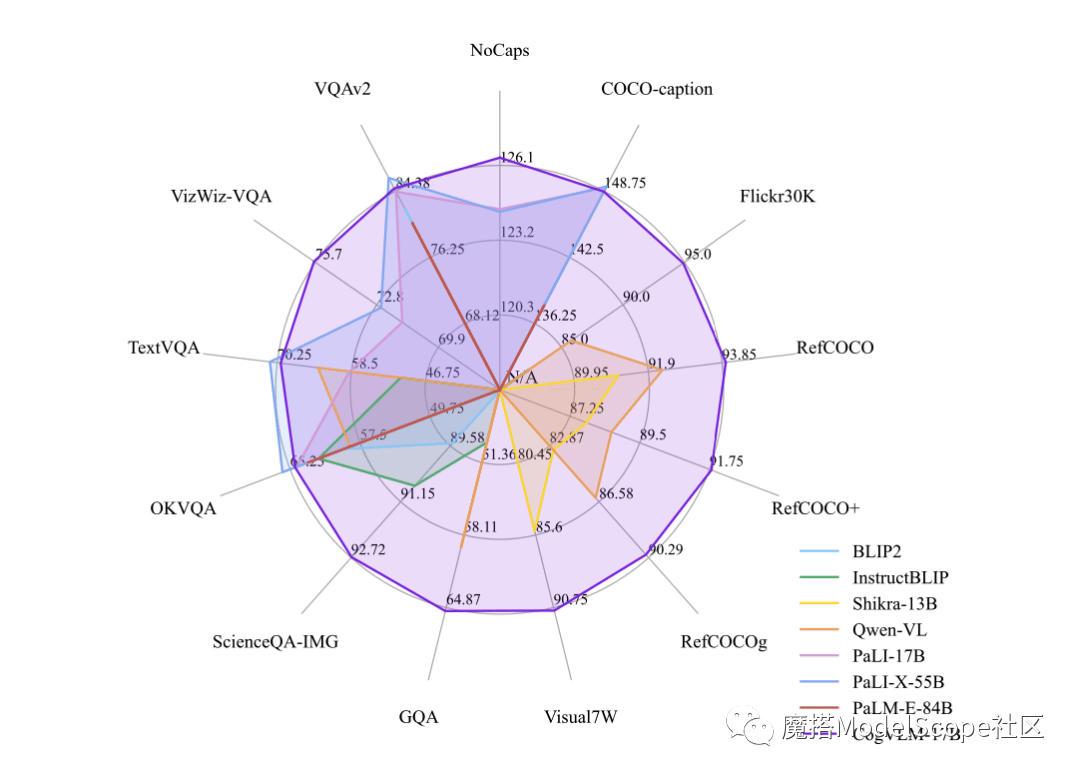
CogVLM-17B는 현재 다중 모달 권위 있는 학술 목록에서 첫 번째 종합 성능을 갖춘 모델로, 14개 데이터 세트에서 가장 진보된 결과 또는 2위를 달성했습니다. CogVLM의 효과는 "시각적 우선순위"라는 아이디어에 달려 있습니다. 즉, 다중 모드 모델에서 시각적 이해에 더 높은 우선순위를 부여하는 것입니다. 5B 매개변수 시각적 인코더와 6B 매개변수 시각적 전문가 모듈을 사용하며, 텍스트의 7B 매개변수보다 훨씬 더 많은 총 11B 매개변수를 사용하여 이미지 특징을 모델링합니다
위 내용은 Zhipu AI는 Tsinghua KEG와 협력하여 CogVLM-17B라는 오픈 소스 다중 모드 대형 모델을 출시했습니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



