
이 문서는 확장된 NFNet을 평가하고 대규모 문제에서 ConvNet이 ViT보다 성능이 떨어진다는 생각에 도전합니다.
딥 러닝의 초기 성공은 ConvNet(Convolutional Neural Network)의 사용에 기인할 수 있습니다. 개발하다. ConvNet은 거의 10년 동안 컴퓨터 비전 벤치마크를 지배해 왔습니다. 그러나 최근에는 점점 ViT(Vision Transformers)로 대체되고 있습니다.
많은 사람들은 ConvNet이 중소 규모 데이터 세트에서는 좋은 성능을 발휘하지만 더 큰 네트워크 규모의 데이터 세트에서는 ViT와 경쟁할 수 없다고 생각합니다.
한편, CV 커뮤니티는 특정 데이터 세트(예: ImageNet)에서 무작위로 초기화된 네트워크의 성능을 평가하는 것에서 네트워크에서 수집된 대규모 일반 데이터 세트에 대해 사전 훈련된 네트워크의 성능을 평가하는 것으로 전환했습니다. 이는 중요한 질문으로 이어집니다. Vision Transformers는 유사한 계산 예산에서 사전 훈련된 ConvNets 아키텍처보다 성능이 뛰어난가요?
이 기사에서는 Google DeepMind의 연구원들이 이 문제를 연구합니다. 다양한 규모의 JFT-4B 데이터세트에서 여러 NFNet 모델을 사전 훈련함으로써 ImageNet

문서 링크 주소: https://arxiv.org/pdf/2310.16764.pdf
The의 ViT와 유사한 성능을 달성했습니다. 이 문서의 연구에서는 TPU-v4 코어 컴퓨팅 시간 0.4,000~110,000시간 사이의 사전 교육 컴퓨팅 예산에 대해 논의하고 일련의 네트워크 교육을 위해 NFNet 모델 계열의 깊이와 폭을 늘리는 이점을 활용합니다. 연구에 따르면 보유 손실과 컴퓨팅 예산 사이에 로그-로그 스케일링 법칙이 있는 것으로 나타났습니다.
예를 들어 이 기사는 TPU-v4 코어 시간(코어 시간)이 0.4k에서 시작하는 JFT-4B를 기반으로 합니다. 110k로 확장되었으며 NFNet은 사전 훈련되었습니다. 미세 조정 후 가장 큰 모델은 ImageNet Top-1에서 90.4%의 정확도를 달성하여 동일한 계산 예산 하에서 사전 훈련된 ViT 모델과 경쟁했습니다
본 논문은 확장된 NFNet을 평가하여 다음과 같이 말할 수 있습니다. 대규모 데이터 세트에서 ConvNet이 ViT보다 성능이 떨어진다는 관점에 도전합니다. 또한 충분한 데이터와 계산이 주어지면 ConvNet은 경쟁력을 유지하며 모델 설계와 리소스는 아키텍처보다 더 중요합니다.
이 연구를 본 후 Turing Award 수상자 Yann LeCun은 다음과 같이 말했습니다. "주어진 계산량에서 ViT와 ConvNets는 계산적으로 동일합니다. 비록 ViT가 컴퓨터 비전 분야에서 인상적인 성공을 거두었지만 제 생각에는 다음과 같은 강력한 증거가 없습니다. 사전 훈련된 ViT는 사전 훈련된 ConvNet보다 공정하게 평가됩니다.” 그러나 일부 네티즌은 LeCun이 많은 경우 모달 모델에서 ViT를 사용하면 여전히 연구에 이점이 있을 수 있다고 말했습니다. Google DeepMind는 ConvNets가 결코 사라지지 않을 것이라고 말합니다
논문의 구체적인 내용을 살펴보겠습니다.
사전 훈련된 NFNet은 스케일링 법칙을 따릅니다.
아래 차트에서 다양한 에포크 예산에 걸쳐 세 가지 모델을 볼 수 있습니다. 관찰된 최고 학습률( 즉, 검증 손실을 최소화하는 것입니다). 연구원들은 더 낮은 에포크 예산의 경우 NFNet 모델 계열이 모두 약 1.6이라는 유사한 최적 학습률을 보였다는 것을 발견했습니다. 그러나 최적의 학습률은 에포크 예산이 증가함에 따라 감소하고 모델이 클수록 더 빠르게 감소합니다. 연구자들은 모델 크기와 에포크 예산이 증가함에 따라 최적의 학습률이 느리고 단조롭게 감소한다고 가정할 수 있으므로 시행 간에 학습률을 효과적으로 조정할 수 있다고 말합니다

다시 작성해야 할 사항은 다음과 같습니다. 그림 2의 사전 훈련된 모델 중 일부가 예상대로 수행되지 않았다는 점에 유의해야 합니다. 연구팀은 이러한 상황이 발생하는 이유는 훈련 실행이 선점/다시 시작되는 경우 데이터 로딩 프로세스가 각 훈련 샘플이 각 에포크에서 한 번씩 샘플링될 수 있다고 보장할 수 없기 때문이라고 생각합니다. 훈련 실행이 여러 번 다시 시작되면 일부 훈련 샘플이 과소 샘플링될 수 있습니다.
NFNet 대 ViT
ImageNet의 실험에서는 미세 조정된 NFNet과 Vision Transformer가 비슷한 성능을 보이는 것으로 나타났습니다
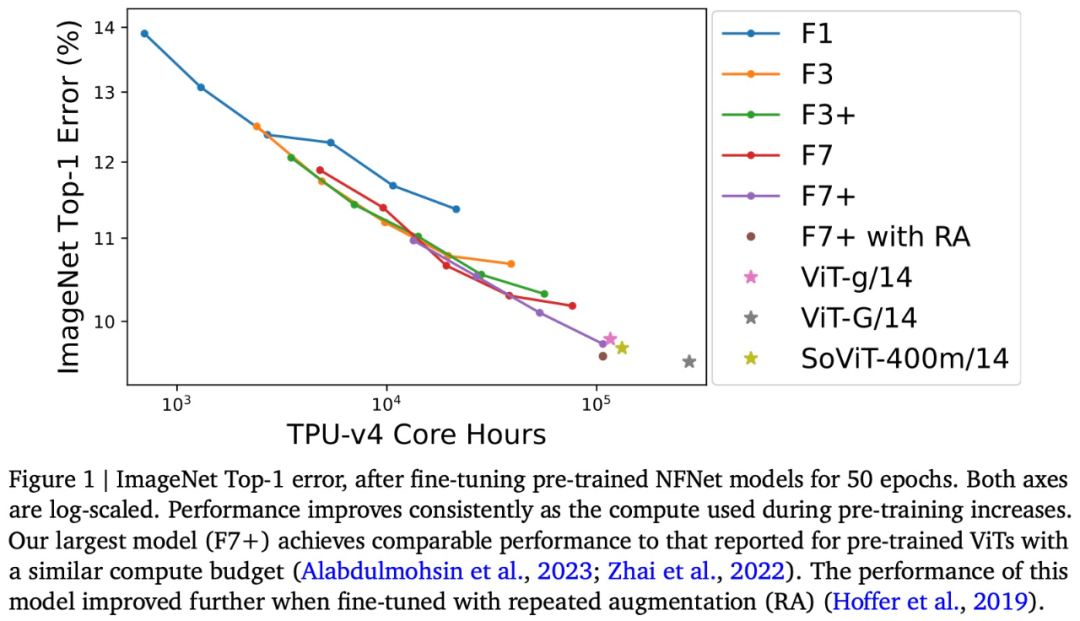
특히 이 연구는 훌륭하다고 말했습니다. 위의 그림 1과 같이 ImageNet에서 사전 훈련 NFNet을 조정하고 사전 훈련 계산과 Top-1 오류 간의 관계를 플롯했습니다.
ImageNet Top-1 정확도는 예산이 증가함에 따라 계속해서 향상됩니다. 그 중 가장 비싼 사전 훈련 모델은 NFNet-F7+로, 8 epoch 동안 사전 훈련되었으며 ImageNet Top-1에서 90.3%의 정확도를 가지고 있습니다. 사전 학습 및 미세 조정에는 약 110,000 TPU-v4 코어 시간과 1.6,000 TPU-v4 코어 시간이 필요합니다. 또한, 미세 조정 중에 추가적인 반복 향상 기법을 도입하면 90.4%의 Top-1 정확도를 달성할 수 있습니다. NFNet은 대규모 사전 훈련을 통해 큰 이점을 얻습니다.
두 모델 아키텍처인 NFNet과 ViT 간에는 분명한 차이가 있지만 사전 훈련된 NFNet과 사전 훈련된 ViT의 성능은 비슷합니다. 예를 들어 ViT-g/14는 210,000 TPU-v3 코어 시간으로 JFT-3B를 사전 훈련한 후 ImageNet에서 90.2%의 Top-1 정확도를 달성했으며 코어 시간 이후에는 JFT-3B에서 500,000 TPU-v3 이상을 수행했습니다. 사전 훈련에서 ViT-G/14는 90.45%의 Top-1 정확도를 달성했습니다.
이 기사에서는 TPU-v4에서 이러한 모델의 사전 훈련 속도를 평가하고 ViT-g/14에 120k TPU-v4 코어가 필요한 것으로 추정합니다. ViTG/14에는 280,000 TPU-v4 코어 시간이 필요하고 SoViT-400m/14에는 130,000 TPU-v4 코어 시간이 필요합니다. 이 논문에서는 이러한 추정치를 사용하여 그림 1의 ViT와 NFNet의 사전 훈련 효율성을 비교합니다. 이 연구에서는 NFNet이 TPU-v4에 최적화되어 있으며 다른 장치에서 평가할 때 성능이 좋지 않다는 점에 주목했습니다.
마지막으로 이 백서에서는 사전 훈련된 체크포인트가 JFT-4B에서 가장 낮은 검증 손실을 달성하지만 미세 조정 후 ImageNet에서 항상 가장 높은 Top-1 정확도를 달성하지는 못한다는 점을 지적합니다. 특히, 이 논문에서는 고정된 사전 훈련 계산 예산 하에서 미세 조정 메커니즘이 약간 더 큰 모델과 약간 더 작은 에포크 예산을 선택하는 경향이 있음을 발견했습니다. 직관적으로 더 큰 모델은 더 큰 용량을 가지므로 새로운 작업에 더 잘 적응할 수 있습니다. 어떤 경우에는 (사전 훈련 중) 약간 더 큰 학습률이 미세 조정 후 더 나은 성능으로 이어질 수도 있습니다
위 내용은 DeepMind: 컨벌루션 네트워크가 ViT보다 열등하다고 누가 말했습니까?의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!


















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



