
최근 'Taylor Swift 과시 중국어' 영상이 주요 소셜 미디어에서 빠르게 인기를 끌었고, 이후 'Guo Degang 과시 영어' 등 유사한 영상이 등장했습니다. 이러한 영상 중 다수는 "HeyGen"이라는 인공지능 애플리케이션으로 제작됩니다. 그러나 HeyGen의 현재 인기로 판단할 때 이를 사용하여 유사한 영상을 제작하는 데는 오랜 시간이 걸릴 수 있습니다. 다행히도 이것이 그것을 만드는 유일한 방법은 아닙니다. 기술을 이해하는 친구들은 음성-텍스트 모델 Whisper, 텍스트 번역 GPT, 음성 복제 + 오디오 생성 so-vits-svc, 오디오 GeneFace++dengdeng과 일치하는 입 모양 비디오 생성과 같은 다른 대안을 찾을 수도 있습니다.
다시 작성된 내용은 다음과 같습니다. 그 중 위스퍼(Whisper)는 OpenAI가 개발, 오픈소스화한 자동음성인식(ASR) 모델로 사용이 매우 간편하다. 그들은 웹에서 수집한 680,000시간의 다국어(98개 언어) 및 다중 작업 감독 데이터에 대해 Whisper를 교육했습니다. OpenAI는 이렇게 크고 다양한 데이터 세트를 사용하면 악센트, 배경 소음 및 기술 용어를 인식하는 모델의 능력을 향상시킬 수 있다고 믿습니다. 음성 인식 외에도 Whisper는 여러 언어를 전사하고 해당 언어를 영어로 번역할 수도 있습니다. 현재 Whisper에는 많은 변형이 있으며 많은 AI 애플리케이션을 구축할 때 필수 구성 요소가 되었습니다
최근 HuggingFace 팀은 새로운 변형인 Distil-Whisper를 제안했습니다. 이 변형은 작은 크기, 빠른 속도 및 매우 높은 정확도가 특징인 Whisper 모델의 증류된 버전으로, 짧은 대기 시간이 필요하거나 리소스가 제한된 환경에서 사용하기에 이상적입니다. 그러나 여러 언어를 처리할 수 있는 원래 Whisper 모델과 달리 Distil-Whisper는 영어
Paper 링크: https://arxiv.org/pdf/2311.00430.pdf
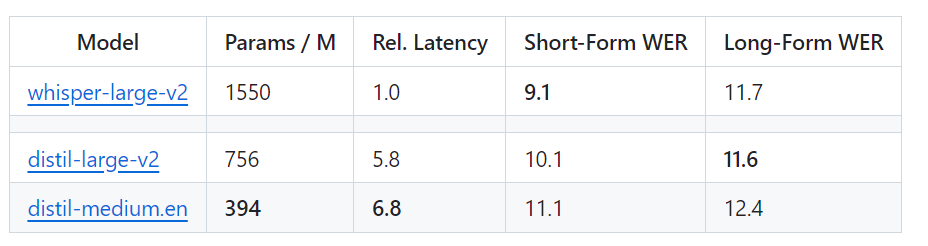
Specific 및 In만 처리할 수 있습니다. 즉, Distil-Whisper에는 매개변수 크기가 756M(distil-large-v2)과 394M(distil-medium.en)인 두 가지 버전이 있습니다. OpenAI의 Whisper-large-v2와 비교하면 756M 버전은 distil의 매개변수 수입니다. -large-v2는 절반 이상 감소했지만 6배의 가속도를 달성했으며 정확도는 Whisper-large-v2에 매우 가깝습니다. 짧은 오디오의 WER(Word Error Rate) 차이는 1% 이내입니다. 긴 오디오에서는 Whisper-large-v2보다 훨씬 좋습니다. 신중한 데이터 선택과 필터링을 통해 Whisper의 견고성은 유지되고 환각이 줄어들기 때문입니다.
Whisper 웹 버전의 속도는 Distil-Whisper와 직관적으로 비교됩니다. 이미지 출처: https://twitter.com/xenovacom/status/1720460890560975103
그래서 출시된 지 2~3일밖에 안 됐음에도 불구하고 Distil-Whisper는 이미 별 천개를 넘어섰습니다. 
 프로젝트 주소: https://github.com/huggingface/distil-whisper#1-usage
프로젝트 주소: https://github.com/huggingface/distil-whisper#1-usage
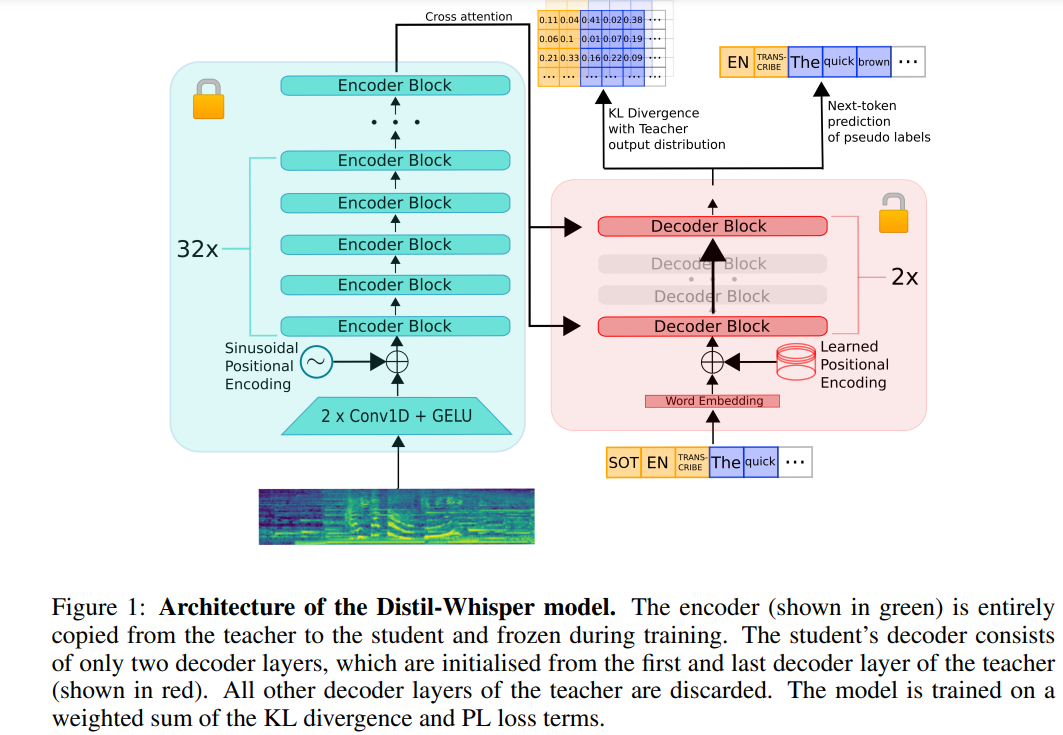
다음은 원본 콘텐츠를 다시 작성한 것입니다. Distil-Whisper의 아키텍처는 아래 그림 1에 나와 있습니다. 연구원들은 교사 모델에서 전체 인코더를 복사하여 학생 모델을 초기화하고 훈련 중에 동결했습니다. 그들은 OpenAI의 Whisper-medium.en 및 Whisper-large-v2 모델에서 첫 번째 및 마지막 디코더 레이어를 복사하고 증류 후 distil-medium.en이라는 이름의 2개의 디코더 체크포인트를 얻었습니다. Large-v2
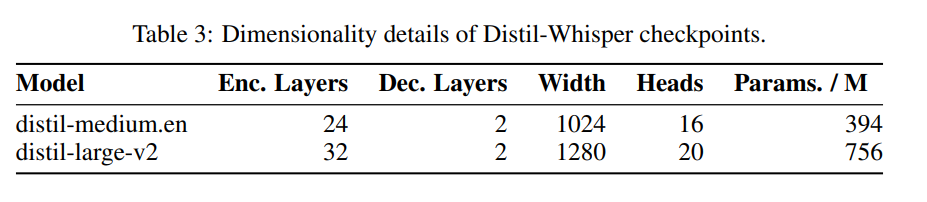
은 표 3에 나와 있습니다.
데이터 측면에서 이 모델은 9개의 서로 다른 오픈 소스 데이터 세트에서 22,000시간 동안 훈련되었습니다(표 2 참조). 의사 태그는 Whisper에 의해 생성됩니다. WER 필터를 사용했으며 WER 점수가 10% 이상인 태그만 유지되었다는 점은 주목할 가치가 있습니다. 저자는 이것이 성능을 유지하는 열쇠라고 말합니다!
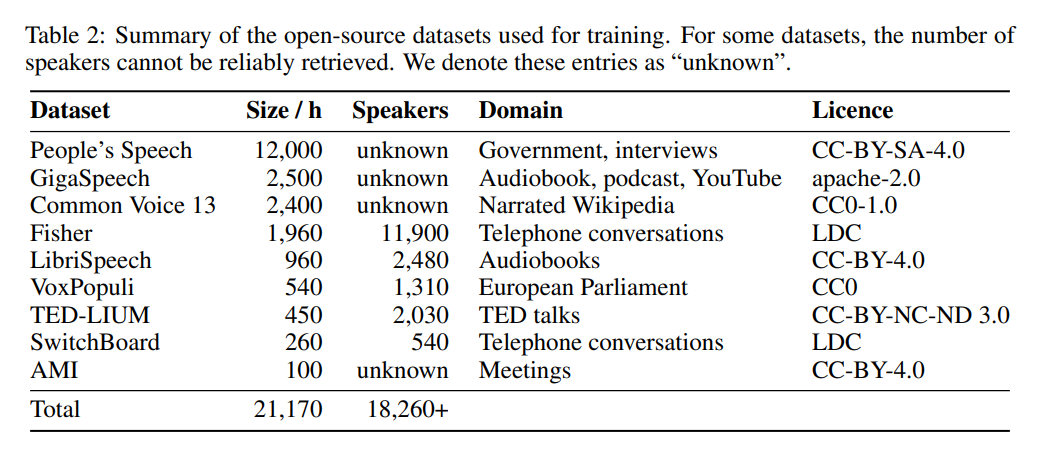
아래 표 5는 Distil-Whisper의 주요 성능 결과를 보여줍니다.
저자에 따르면, Distil-Whisper는 인코더의 작동을 정지시켜 소음에 대해 매우 견고한 성능을 발휘한다고 합니다. 아래 그림에 표시된 것처럼 Distil-Whisper는 시끄러운 조건에서 Whisper와 유사한 견고성 곡선을 따르며 Wav2vec2
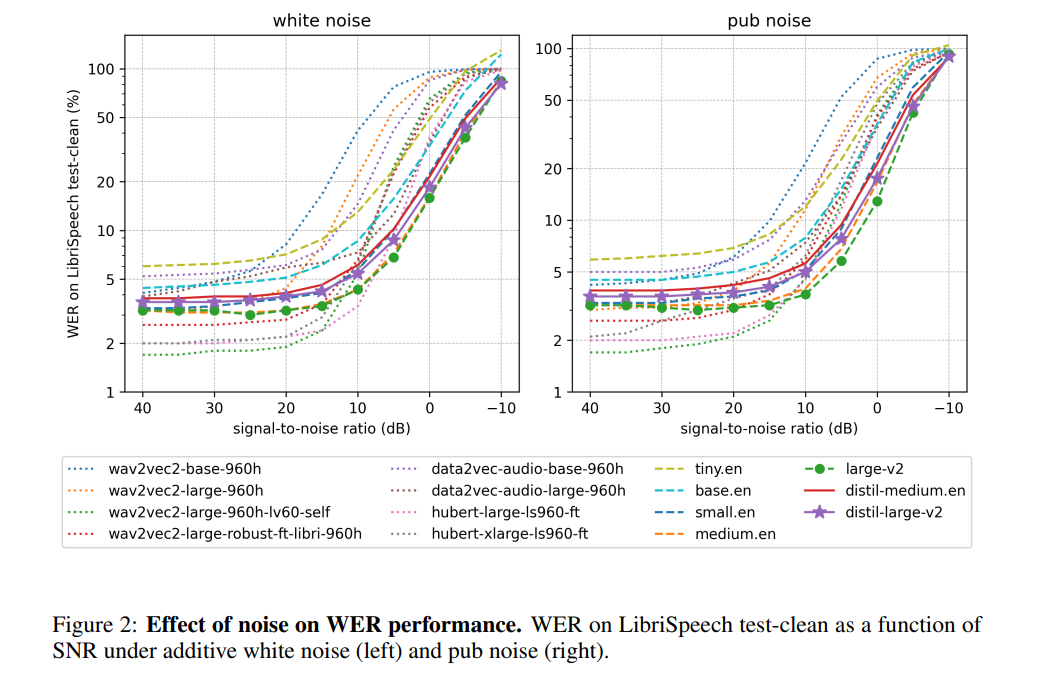
와 같은 다른 모델보다 더 나은 성능을 발휘합니다. 긴 오디오 파일을 처리할 때 Whisper와 비교할 때 Distil-Whisper는 효과적으로 환각. 저자에 따르면 이는 주로 WER 필터링 때문이라고 합니다. 동일한 인코더를 공유함으로써 Distil-Whisper는 추측 디코딩을 위해 Whisper와 쌍을 이룰 수 있습니다. 결과적으로 Whisper와 정확히 동일한 출력을 생성하면서 매개변수가 8%만 증가하여 속도가 2배 향상되었습니다.
위 내용은 OpenAI의 Whisper 증류 이후 음성 인식 속도가 크게 향상되어 이틀 만에 별 수가 1,000개를 넘었습니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



