
머신러닝 분야에서는 훈련 과정에서 해당 모델이 과적합되거나 과소적합될 수 있습니다. 이러한 일이 발생하지 않도록 하기 위해 우리는 기계 학습의 정규화 작업을 사용하여 테스트 세트에 모델을 적절하게 맞춥니다. 일반적으로 정규화 작업은 과적합 및 과소적합 가능성을 줄여 모든 사람이 최상의 모델을 얻는 데 도움이 됩니다.
이 글에서는 정규화가 무엇인지, 정규화 유형에 대해 알아 보겠습니다. 또한 편향(bias), 분산(variance), 과소적합(underfitting), 과적합(overfitting)과 같은 관련 개념에 대해서도 논의합니다.
더 이상 헛소리는 그만하고 시작해 보세요!
편향과 분산은 우리가 학습한 모델과 실제 모델 사이의 차이를 설명하는 데 사용되는 두 가지 측면입니다.
다시 작성해야 할 것은 다음과 같습니다.
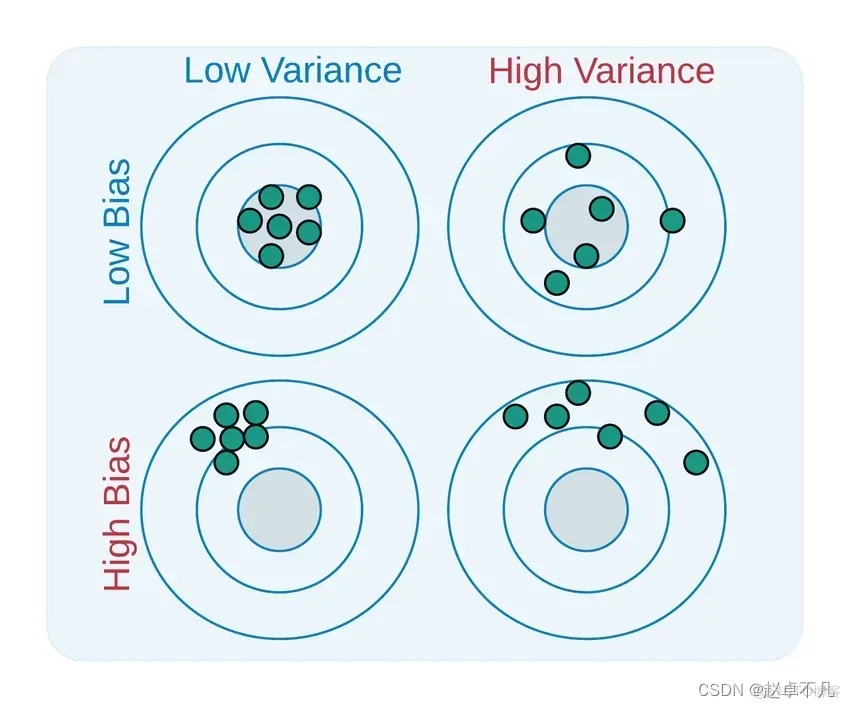
편향은 개별 데이터 포인트에 대한 모델의 민감도를 줄이는 동시에 데이터의 일반화를 높이고 격리된 데이터 포인트에 대한 모델의 민감도를 줄입니다. 필요한 기능이 덜 복잡하기 때문에 교육 시간도 줄일 수 있습니다. 높은 편향은 대상 함수가 더 신뢰할 수 있는 것으로 가정되지만 때로는 모델의 과소적합으로 이어질 수 있음을 나타냅니다.
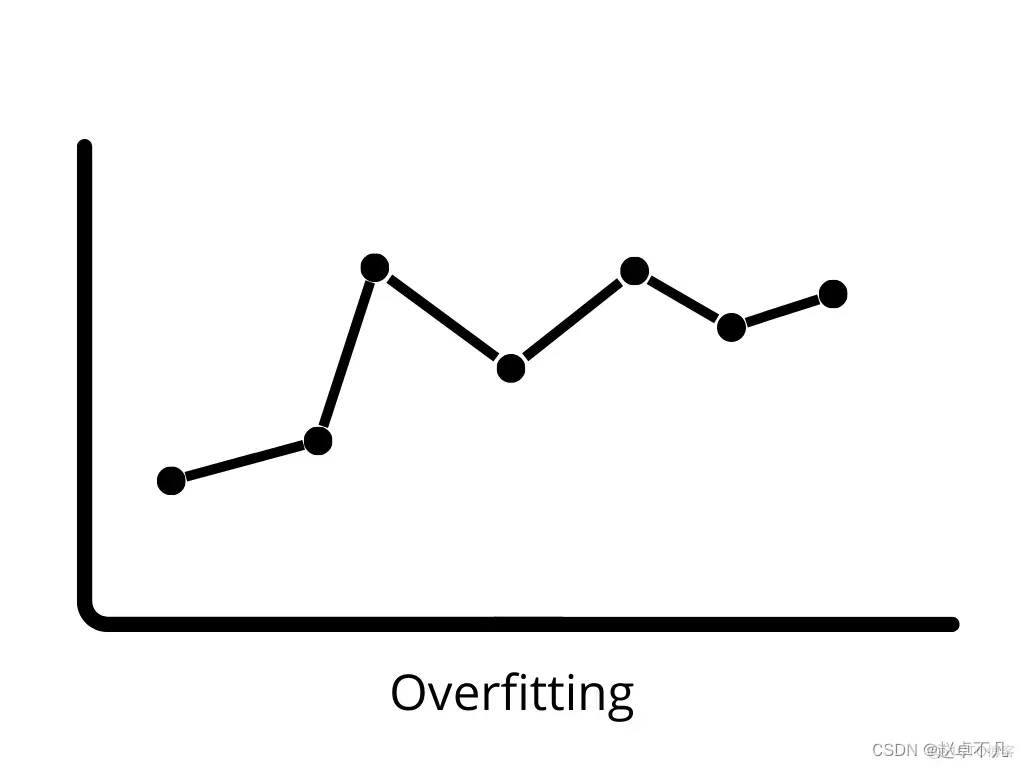
기계 학습의 분산(Variance)은 데이터의 작은 변화에 대한 모델의 민감도로 인해 발생하는 오류를 나타냅니다. 세트. 데이터 세트에 상당한 변화가 있기 때문에 알고리즘은 훈련 세트의 노이즈와 이상값을 모델링합니다. 이러한 상황을 종종 과적합이라고 합니다. 새로운 데이터 세트를 평가할 때 모델은 기본적으로 모든 데이터 포인트를 학습하므로 정확한 예측을 제공할 수 없습니다.
상대적으로 균형 잡힌 모델은 편향이 낮고 분산이 낮은 반면, 편향이 높고 분산이 높으면 다음과 같은 결과가 발생합니다. 과소적합과 과적합.
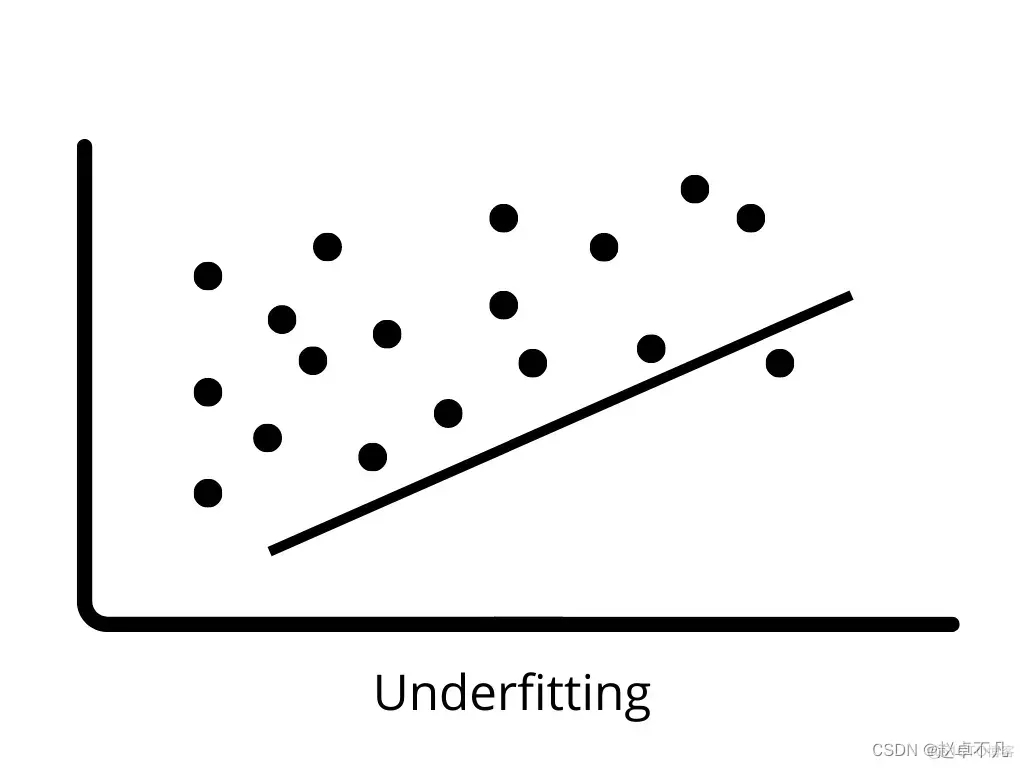
과소적합은 모델이 훈련 데이터의 패턴을 올바르게 학습하고 새 데이터로 일반화할 수 없을 때 발생합니다. 과소적합 모델은 훈련 데이터에서 성능이 저하되어 잘못된 예측으로 이어질 수 있습니다. 높은 편향과 낮은 분산이 발생하면 과소적합이 발생하기 쉽습니다
5. 정규화 개념
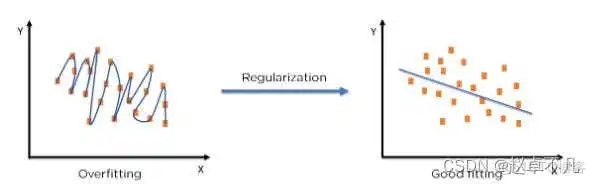
정규화 기술을 사용하면 머신러닝 모델을 특정 테스트 세트에 더욱 정확하게 맞춰 테스트 세트의 오류를 효과적으로 줄일 수 있습니다
6. L1 정규화
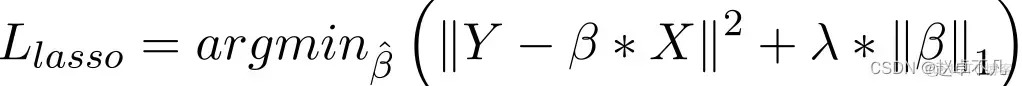
Lasso 회귀 모델에서는 능선 회귀와 유사한 방식으로 회귀 계수의 절대값에 대한 페널티 항을 늘려 이를 달성합니다. 또한 L1 정규화는 선형 회귀 모델의 정확도를 향상시키는 데 좋은 성능을 발휘합니다. 동시에 L1 정규화는 모든 매개변수에 동일하게 페널티를 적용하므로 일부 가중치를 0으로 만들 수 있으므로 특정 특징을 제거할 수 있는 희소 모델이 생성됩니다(가중치 0은 제거와 동일함).
7. L2 정규화
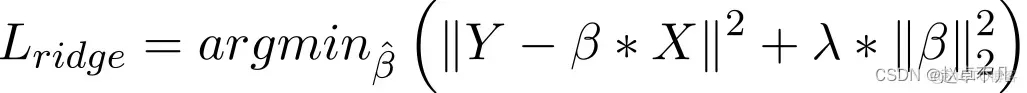
일반적으로 데이터가 다중공선성(독립변수의 상관관계가 높음)을 나타낼 때 채택하는 방법으로 간주됩니다. 다중 공선성의 최소 제곱 추정(OLS)은 편향되지 않지만, 큰 분산으로 인해 관측된 값이 실제 값과 크게 다를 수 있습니다. L2는 회귀 추정의 오류를 어느 정도 줄입니다. 일반적으로 다중 공선성 문제를 해결하기 위해 수축 매개변수를 사용합니다. L2 정규화는 고정된 가중치 비율을 줄이고 가중치를 평활화합니다.
위 분석 후 이 기사의 관련 정규화 지식은 다음과 같이 요약됩니다.
L1 정규화는 희소 가중치 행렬, 즉 희소 모델을 생성할 수 있습니다. , 기능 선택에 사용할 수 있습니다.
L2 정규화는 모델의 과적합을 어느 정도 방지하고 모델의 일반화 능력을 향상시킬 수 있습니다.
L1 정규화 가설 매개변수는 다음과 같습니다. 모델의 희소성을 보장할 수 있는 라플라스 분포, 즉 일부 매개변수는 0과 같습니다.
L2(능선 회귀)의 가정은 매개변수의 사전 분포가 가우스 분포이므로 안정성을 보장할 수 있습니다. 즉, 매개변수의 값은 너무 크거나 작지 않습니다.
실제 응용에서 특성이 고차원이고 희소한 경우 특성이 저차원이고 밀도가 높은 경우 L1 정규화를 사용해야 합니다. , L2 정규화를 사용해야 합니다
위 내용은 머신러닝에서 정규화란 무엇인가요?의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



