

11월 10일 뉴스에 LLM(대형 언어 모델)이 급부상하면서 언어 생성 및 이해 분야에서 밝은 전망을 보이고 있으며 그 영향력은 언어 분야를 넘어 논리, 수학, 물리학 및 기타 분야로 확장됩니다.
그러나 이러한 "특별한 에너지"를 잠금 해제하려면 높은 가격을 지불해야 합니다. 예를 들어 540B 모델을 교육하려면 Project PaLM의 TPUv4 칩이 6144개 필요하고 175B GPT-3을 교육하려면 수천 페타플롭/초가 필요합니다. 낮.
좋은 해결책은 정밀도가 낮은 훈련을 수행하는 것인데, 이를 통해 처리 속도를 높이고 메모리 사용량과 통신 비용을 줄일 수 있습니다. 현재 주류 교육 시스템에는 Megatron-LM, MetaSeq 및 Colossal-AI가 포함되며 기본적으로 FP16/BF16 혼합 정밀도 또는 FP32 완전 정밀도를 사용하여 대규모 언어 모델을 교육합니다
이러한 정확도 수준은 대규모 언어 모델에 필수적이지만 계산적으로 비용이 많이 듭니다.
FP8 저정밀도를 채택하면 속도는 2배 향상, 메모리 비용은 50~75% 절감, 통신비용 절감이 가능합니다.
현재 Nvidia Transformer Engine만 FP8 프레임워크와 호환됩니다. 주로 GEMM(일반 행렬 곱셈) 계산에 이 정밀도를 활용하는 동시에 FP16 또는 FP32 고정밀도로 마스터 가중치 및 그라데이션을 유지합니다.
이 과제를 해결하기 위해 Microsoft Azure 및 Microsoft Research의 연구진 팀은 대규모 언어 모델 훈련에 맞춰진 효율적인 FP8 혼합 정밀도 프레임워크를 도입했습니다.
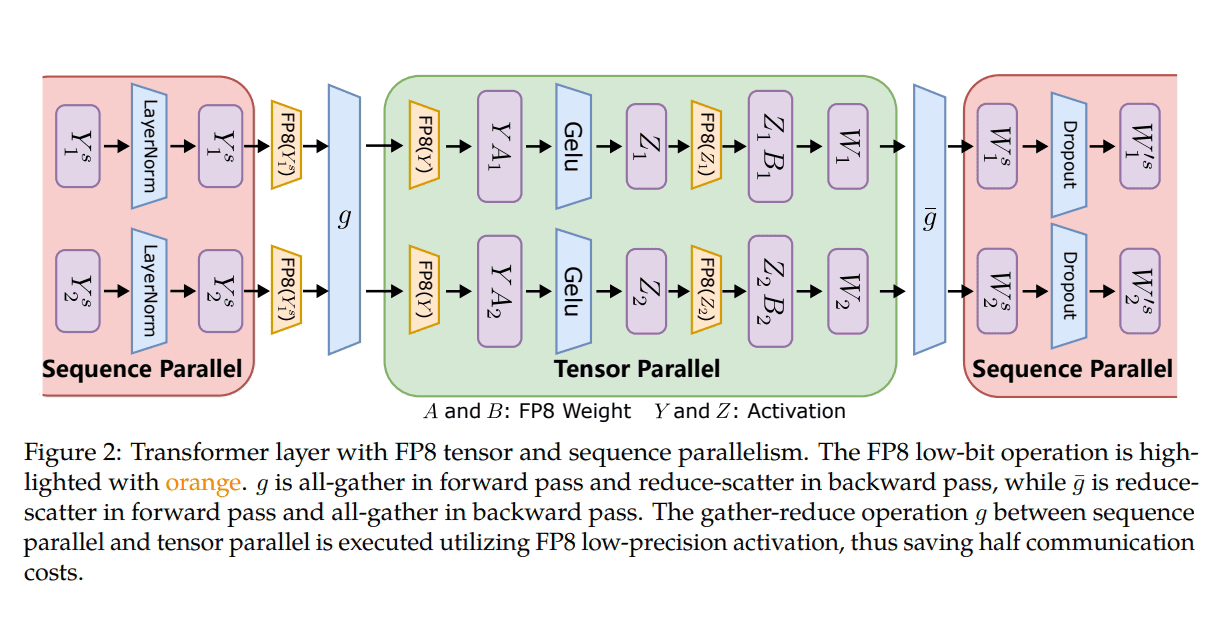
Microsoft는 분산 및 혼합 정밀 교육에 FP8을 활용하기 위해 세 가지 최적화 단계를 도입했습니다. 이러한 수준이 진행됨에 따라 FP8의 통합 증가가 분명해지며 LLM 교육 프로세스에 더 큰 영향을 미치게 됩니다.
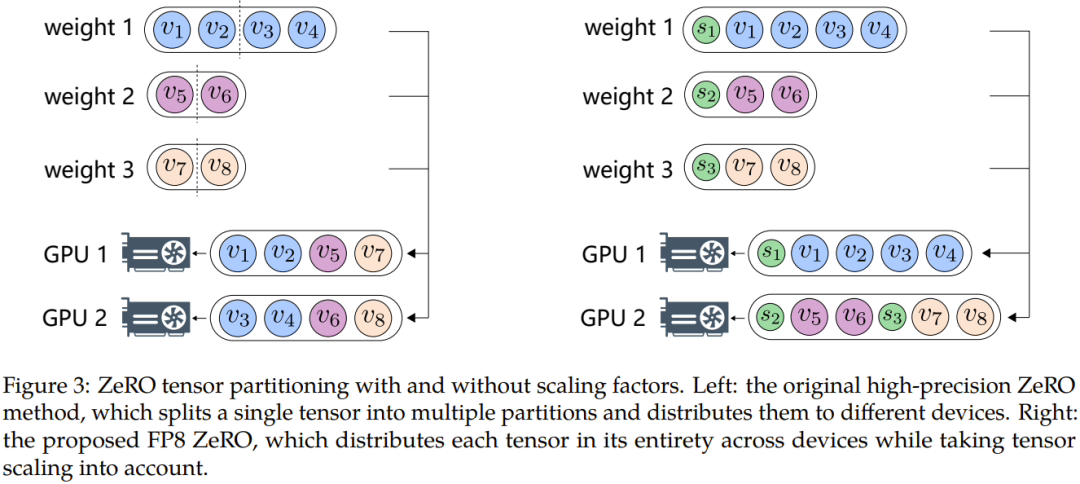
또한 데이터 오버플로 또는 언더플로와 같은 문제를 극복하기 위해 Microsoft 연구원은 자동 샘플링과 정밀한 디커플링이라는 두 가지 주요 방법을 제안했습니다. 전자는 정확도에 민감하지 않고 정확도를 낮추며 Tensor 샘플링을 동적으로 조정하는 구성 요소를 포함합니다. FP8 표현 범위 내에서 기울기 값이 유지되도록 하는 요소입니다. 이는 통신 중 언더플로 및 오버플로 이벤트를 방지하여 보다 원활한 교육 프로세스를 보장합니다.
Microsoft는 널리 채택된 BF16 혼합 정밀도 방법과 비교하여 메모리 사용량이 27%~42% 감소하고, 중량 경사 통신 오버헤드가 63%~65% 크게 감소하는 것으로 테스트했습니다. Megatron-LM과 같이 널리 채택된 BF16 프레임워크보다 64% 더 빠르게 실행되고 Nvidia Transformer Engine보다 17% 더 빠르게 실행됩니다.
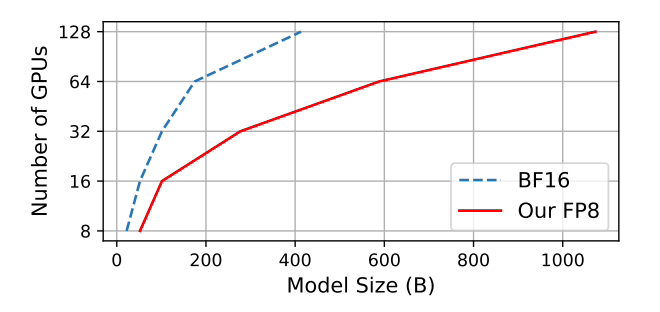
GPT-175B 모델을 훈련할 때 하이브리드 FP8 정밀 프레임워크는 H100 GPU 플랫폼에서 메모리를 21% 절약하고 TE(Transformer Engine)에 비해 훈련 시간을 17% 단축합니다.
이 사이트는 여기에 GitHub 주소와 논문 주소를 첨부합니다:https://www.php.cn/link/7b3564b05f78b6739d06a2ea3187f5ca
위 내용은 Microsoft, 새로운 혼합 정밀 훈련 프레임워크 FP8 출시: BF16보다 64% 빠르고 메모리 사용량은 42% 적음의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!


















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



