

문서 분석을 위해 LangChain 및 OpenAI API를 사용하는 방법

번역자가 다시 작성해야 하는 콘텐츠는 다음과 같습니다. |다시 작성해야 하는 콘텐츠는: Bugatti
리뷰어가 다시 작성해야 하는 콘텐츠는 다음과 같습니다. |필요한 콘텐츠는 다음과 같습니다. 다시 작성하는 방법은 다음과 같습니다. Chonglou
문서와 데이터에서 insights를 추출하는 것은 you정보에 입각한 결정을 내리는 데 매우 중요합니다. 그러나 민감한 정보를 다루는 경우 개인정보 문제가 발생할 수 있습니다. LangChain과 OpenAI를 함께 사용하려면 API를 다시 작성해야 합니다. 로컬 문서를 인터넷에 업로드하지 않고도 분석할 수 있습니다.
이 작업은 데이터를 로컬에 유지하고, 분석을 위해 임베딩 및 벡터화를 사용하고, 환경에서 프로세스를 실행하여 이를 수행합니다. OpenAI는 모델 교육이나 서비스 개선을 위해 고객이 API를 통해 제출한 데이터를 사용하지 않습니다. Build
Environment새
Python가상 환경을 만듭니다. 이렇게 하면 라이브러리 버전 충돌이 발생하지 않습니다. 그런 다음 다음 터미널 명령을 실행하여 필요한 라이브러리를 설치하십시오. pip需要改写的内容是:install需要改写的内容是:langchain需要改写的内容是:openai需要改写的内容是:tiktoken需要改写的内容是:faiss-cpu需要改写的内容是:pypdf
:
LangChain- : 이를 사용하여 생성하고 관리합니다. 텍스트 처리 및 언어 응용 프로그램 분석 체인. 문서 로딩, 텍스트 분할, 삽입 및 볼륨 저장을 위한 모듈을 제공합니다. OpenAI:
- 이를 사용하여 쿼리, 를 실행하고 언어 모델에서 결과를 얻습니다. tiktoken:
- 이를 사용하여 주어진 텍스트에서 토큰( 텍스트 단위 ) 의 수를 계산합니다. 사용하는 토큰의 수에 따라 을 청구하는 OpenAI와 상호 작용할 때 token 수를 추적하기 위해 다시 작성해야 하는 것은 API 입니다. FAISS: 이를 사용하여 벡터 저장소를 만들고 관리하므로 임베딩을 기반으로 유사한 벡터를 빠르게 검색할 수 있습니다.
- PyPDF: 이 라이브러리는 PDF
- 에서 텍스트를 추출합니다. 이는 파일을 PDF 로드하고 추가 처리를 위해 텍스트 , 추출하는 데 도움이 됩니다. 모든 라이브러리를 설치한 후 환경 이 이제 준비 준비
Get OpenAI 다시 작성해야 할 것은: API 키
OpenAI에 요청할 때 다시 작성해야 할 것은: API 입니다. 요청의 일부로
APIKey를 추가하세요. 이 키를 사용하면 API제공자가 해당 요청이 합법적인 소스에서 왔는지, 사용자가 해당 기능에 액세스하는 데 필요한 권한을 가지고 있는지 확인할 수 있습니다. OpenAI를 얻기 위해 다시 작성해야 하는 것은 API 키, OpenAI 플랫폼을 입력하는 것입니다. 그런 다음 오른쪽 상단의 계정
"
APIKey"을 클릭하면 이 나타납니다. API비밀 핵심 페이지. "새 키 만들기" 버튼을 클릭하세요. 키 이름을
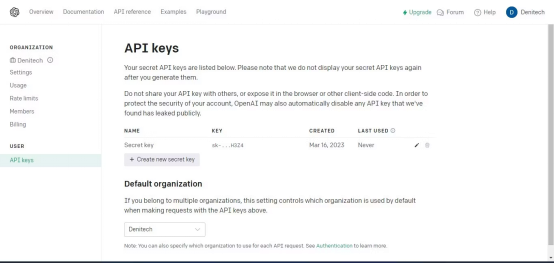
Create New Key"을 클릭하세요. OpenAI는 API키를 생성하며, 이 키를 복사하여 안전한 곳에 보관해야 합니다. 보안상의 이유로 OpenAI 계정을 통해 다시 볼 수 없습니다. 키를 분실한 경우 새 키를 생성해야 합니다. 为了能够使用安装在虚拟环境中的库,您需要导入它们。 注意,您从LangChain导入了依赖项库,这让您可以使用LangChain框架的特定功能。 先创建一个含有API密钥的变量。稍后,您将在代码中使用该变量用于身份验证。 如果您打算与第三方共享您的代码,不建议对API密钥进行硬编码。对于打算分发的生产级代码,则改而使用环境变量。 接下来,创建一个加载文档的函数。该函数应该加载PDF或文本文件。如果文档既不是PDF文件,也不是文本文件,该函数会抛出值错误。 加载文档后,创建一个CharacterTextSplitter。该分割器将基于字符将已加载的文档分隔成更小的块。 需要改写的内容是: 分割文档可确保块的大小易于管理,仍与一些重叠的上下文相连接。这对于文本分析和信息检索之类的任务非常有用。 您需要一种方法来查询上传的文档,以便从中获得洞察力。为此,创建一个以查询字符串和检索器作为输入的函数。然后,它使用检索器和OpenAI语言模型的实例创建一个RetrievalQA实例。 该函数使用创建的QA实例来运行查询并输出结果。 主函数将控制整个程序流。它将接受用户输入的文档文件名并加载该文档。然后为文本嵌入创建OpenAIEmbeddings实例,并基于已加载的文档和文本嵌入构造一个向量存储。将该向量存储保存到本地文件。 接下来,从本地文件加载持久的向量存储。然后输入一个循环,用户可以在其中输入查询。主函数将这些查询与持久化向量存储的检索器一起传递给query_pdf函数。循环将继续,直到用户输入“exit”。 嵌入捕获词之间的语义关系。向量是一种可以表示一段文本的形式。 这段代码使用OpenAIEmbeddings生成的嵌入将文档中的文本数据转换成向量。然后使用FAISS对这些向量进行索引,以便高效地检索和比较相似的向量。这便于对上传的文档进行分析。 最后,如果用户独立运行程序,使用__name__需要改写的内容是:==需要改写的内容是:"__main__"构造函数来调用主函数: 这个应用程序是一个命令行应用程序。作为一个扩展,您可以使用Streamlit为该应用程序添加Web界面。 要执行文档分析,将所要分析的文档存储在项目所在的同一个文件夹中,然后运行该程序。它将询问所要分析的文档的名称。输入全名,然后输入查询,以便程序分析。 以下截图展示了对PDF进行分析的结果 아래 출력은 소스 코드와 가 포함된 텍스트 파일을 분석한 결과를 보여줍니다. 분석하려는 파일이 PDF 또는 텍스트 형식인지 확인하세요. 문서 가 다른 형식 인 경우 온라인 도구를 사용하여 해당 문서를 PDF 형식 으로 변환할 수 있습니다. 전체 소스 코드는 GitHub 코드 저장소에서 확인할 수 있습니다: https://github.com/makeuseofcode/Document-analytics-using-LangChain-and-OpenAI 원제: How need to 다시 작성해야 할 내용은 다음과 같습니다. to 다시 작성해야 할 내용은 다음과 같습니다. 분석 다시 작성해야 할 내용은 다음과 같습니다. 문서 다시 작성해야 할 내용은 다음과 같습니다. With 다시 작성해야 할 내용은 다음과 같습니다. : LangChain 다시 작성해야 하는 콘텐츠는 다음과 같습니다. 다시 작성해야 하는 콘텐츠는 다음과 같습니다. 다시 작성해야 하는 콘텐츠는 다음과 같습니다. the 콘텐츠는: OpenAI 다시 작성해야 하는 콘텐츠는: API , 작성자: Denis 다시 작성해야 하는 콘텐츠는 다음과 같습니다. Kuria 다시 작성해야 하는 콘텐츠는 다음과 같습니다.
导入所需的库
from需要改写的内容是:langchain.document_loaders需要改写的内容是:import需要改写的内容是:PyPDFLoader,需要改写的内容是:TextLoaderfrom需要改写的内容是:langchain.text_splitter需要改写的内容是:import需要改写的内容是:CharacterTextSplitterfrom需要改写的内容是:langchain.embeddings.openai需要改写的内容是:import需要改写的内容是:OpenAIEmbeddingsfrom需要改写的内容是:langchain.vectorstores需要改写的内容是:import需要改写的内容是:FAISSfrom需要改写的内容是:langchain.chains需要改写的内容是:import需要改写的内容是:RetrievalQAfrom需要改写的内容是:langchain.llms需要改写的内容是:import需要改写的内容是:OpenAI
加载用于分析的文档
#需要改写的内容是:Hardcoded需要改写的内容是:API需要改写的内容是:keyopenai_api_key需要改写的内容是:=需要改写的内容是:"Your需要改写的内容是:API需要改写的内容是:key"
def需要改写的内容是:load_document(filename):if需要改写的内容是:filename.endswith(".pdf"):需要改写的内容是:loader需要改写的内容是:=需要改写的内容是:PyPDFLoader(filename)需要改写的内容是:documents需要改写的内容是:=需要改写的内容是:loader.load()需要改写的内容是:elif需要改写的内容是:filename.endswith(".txt"):需要改写的内容是:loader需要改写的内容是:=需要改写的内容是:TextLoader(filename)需要改写的内容是:documents需要改写的内容是:=需要改写的内容是:loader.load()需要改写的内容是:else:需要改写的内容是:raise需要改写的内容是:ValueError("Invalid需要改写的内容是:file需要改写的内容是:type")text_splitter需要改写的内容是:=需要改写的内容是:CharacterTextSplitter(chunk_size=1000,需要改写的内容是:需要改写的内容是:chunk_overlap=30,需要改写的内容是:separator="\n")需要改写的内容是:return需要改写的内容是:text_splitter.split_documents(documents=documents)
查询文档
def需要改写的内容是:query_pdf(query,需要改写的内容是:retriever):qa需要改写的内容是:=需要改写的内容是:RetrievalQA.from_chain_type(llm=OpenAI(openai_api_key=openai_api_key),需要改写的内容是:chain_type="stuff",需要改写的内容是:retriever=retriever)result需要改写的内容是:=需要改写的内容是:qa.run(query)需要改写的内容是:print(result)
创建主函数
def需要改写的内容是:main():需要改写的内容是:filename需要改写的内容是:=需要改写的内容是:input("Enter需要改写的内容是:the需要改写的内容是:name需要改写的内容是:of需要改写的内容是:the需要改写的内容是:document需要改写的内容是:(.pdf需要改写的内容是:or需要改写的内容是:.txt):\n")docs需要改写的内容是:=需要改写的内容是:load_document(filename)embeddings需要改写的内容是:=需要改写的内容是:OpenAIEmbeddings(openai_api_key=openai_api_key)vectorstore需要改写的内容是:=需要改写的内容是:FAISS.from_documents(docs,需要改写的内容是:embeddings)需要改写的内容是:vectorstore.save_local("faiss_index_constitution")persisted_vectorstore需要改写的内容是:=需要改写的内容是:FAISS.load_local("faiss_index_constitution",需要改写的内容是:embeddings)query需要改写的内容是:=需要改写的内容是:input("Type需要改写的内容是:in需要改写的内容是:your需要改写的内容是:query需要改写的内容是:(type需要改写的内容是:'exit'需要改写的内容是:to需要改写的内容是:quit):\n")while需要改写的内容是:query需要改写的内容是:!=需要改写的内容是:"exit":query_pdf(query,需要改写的内容是:persisted_vectorstore.as_retriever())query需要改写的内容是:=需要改写的内容是:input("Type需要改写的内容是:in需要改写的内容是:your需要改写的内容是:query需要改写的内容是:(type需要改写的内容是:'exit'需要改写的内容是:to需要改写的内容是:quit):\n")if需要改写的内容是:__name__需要改写的内容是:==需要改写的内容是:"__main__":需要改写的内容是:main()
执行文件分析
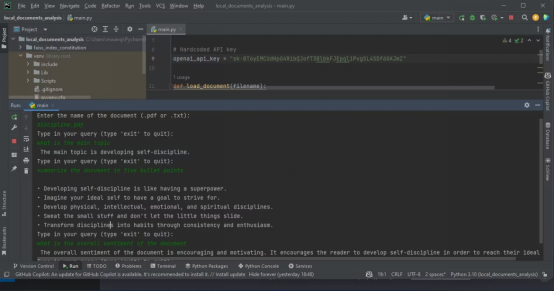
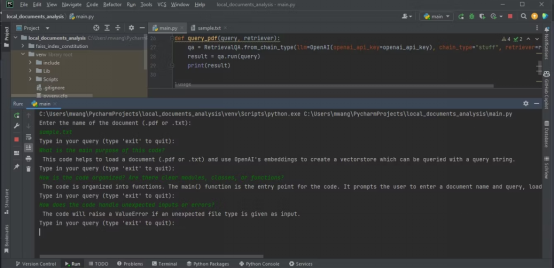
위 내용은 문서 분석을 위해 LangChain 및 OpenAI API를 사용하는 방법의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7451
7451
 15
1374
52
77
11
40
19
14
9
15
1374
52
77
11
40
19
14
9

 데이터에 가장 적합한 임베딩 모델 선택: OpenAI와 오픈 소스 다국어 임베딩 비교 테스트
Feb 26, 2024 pm 06:10 PM
데이터에 가장 적합한 임베딩 모델 선택: OpenAI와 오픈 소스 다국어 임베딩 비교 테스트
Feb 26, 2024 pm 06:10 PM
OpenAI는 최근 최신 세대 임베딩 모델 embeddingv3의 출시를 발표했습니다. 이는 더 높은 다국어 성능을 갖춘 가장 성능이 뛰어난 임베딩 모델이라고 주장합니다. 이 모델 배치는 더 작은 text-embeddings-3-small과 더 강력하고 더 큰 text-embeddings-3-large의 두 가지 유형으로 나뉩니다. 이러한 모델이 어떻게 설계되고 학습되는지에 대한 정보는 거의 공개되지 않으며 모델은 유료 API를 통해서만 액세스할 수 있습니다. 그렇다면 오픈소스 임베딩 모델이 많이 있습니다. 그러나 이러한 오픈소스 모델은 OpenAI 폐쇄소스 모델과 어떻게 비교됩니까? 이 기사에서는 이러한 새로운 모델의 성능을 오픈 소스 모델과 실증적으로 비교할 것입니다. 데이터를 만들 계획입니다.
 Spring Boot가 OpenAI를 만났을 때 새로운 프로그래밍 패러다임
Feb 01, 2024 pm 09:18 PM
Spring Boot가 OpenAI를 만났을 때 새로운 프로그래밍 패러다임
Feb 01, 2024 pm 09:18 PM
2023년에는 AI 기술이 화두가 되면서 다양한 산업, 특히 프로그래밍 분야에 큰 영향을 미치고 있다. 사람들은 AI 기술의 중요성을 점점 더 인식하고 있으며 Spring 커뮤니티도 예외는 아닙니다. GenAI(일반 인공 지능) 기술이 지속적으로 발전함에 따라 AI 기능을 갖춘 애플리케이션 생성을 단순화하는 것이 중요하고 시급해졌습니다. 이러한 배경에서 AI 기능 애플리케이션 개발 프로세스를 단순화하고 간단하고 직관적이며 불필요한 복잡성을 피하는 것을 목표로 하는 "SpringAI"가 등장했습니다. 'SpringAI'를 통해 개발자는 AI 기능이 포함된 애플리케이션을 더욱 쉽게 구축할 수 있어 사용 및 운영이 더욱 쉬워진다.
 OpenAI Super Alignment Team의 사후 작업: 두 개의 대형 모델이 게임을 하고 출력이 더 이해하기 쉬워졌습니다.
Jul 19, 2024 am 01:29 AM
OpenAI Super Alignment Team의 사후 작업: 두 개의 대형 모델이 게임을 하고 출력이 더 이해하기 쉬워졌습니다.
Jul 19, 2024 am 01:29 AM
AI 모델이 내놓은 답변이 전혀 이해하기 어렵다면 감히 사용해 보시겠습니까? 기계 학습 시스템이 더 중요한 영역에서 사용됨에 따라 우리가 그 결과를 신뢰할 수 있는 이유와 신뢰할 수 없는 경우를 보여주는 것이 점점 더 중요해지고 있습니다. 복잡한 시스템의 출력에 대한 신뢰를 얻는 한 가지 가능한 방법은 시스템이 인간이나 다른 신뢰할 수 있는 시스템이 읽을 수 있는 출력 해석을 생성하도록 요구하는 것입니다. 즉, 가능한 오류가 발생할 수 있는 지점까지 완전히 이해할 수 있습니다. 설립하다. 예를 들어, 사법 시스템에 대한 신뢰를 구축하기 위해 우리는 법원이 자신의 결정을 설명하고 뒷받침하는 명확하고 읽기 쉬운 서면 의견을 제공하도록 요구합니다. 대규모 언어 모델의 경우 유사한 접근 방식을 채택할 수도 있습니다. 그러나 이 접근 방식을 사용할 때는 언어 모델이 다음을 생성하는지 확인하세요.
 Rust 기반 Zed 편집기는 OpenAI 및 GitHub Copilot에 대한 기본 지원을 포함하여 오픈 소스로 제공되었습니다.
Feb 01, 2024 pm 02:51 PM
Rust 기반 Zed 편집기는 OpenAI 및 GitHub Copilot에 대한 기본 지원을 포함하여 오픈 소스로 제공되었습니다.
Feb 01, 2024 pm 02:51 PM
작성자丨컴파일: TimAnderson丨제작: Noah|51CTO Technology Stack(WeChat ID: blog51cto) Zed 편집기 프로젝트는 아직 출시 전 단계에 있으며 AGPL, GPL 및 Apache 라이선스에 따라 오픈 소스로 제공됩니다. 이 편집기는 고성능과 다양한 AI 지원 옵션을 제공하지만 현재는 Mac 플랫폼에서만 사용할 수 있습니다. Nathan Sobo는 게시물에서 GitHub의 Zed 프로젝트 코드 베이스에서 편집기 부분은 GPL에 따라 라이선스가 부여되고 서버 측 구성 요소는 AGPL에 따라 라이선스가 부여되며 GPUI(GPU Accelerated User) 인터페이스) 부분은 GPL에 따라 라이선스가 부여된다고 설명했습니다. Apache2.0 라이센스. GPUI는 Zed 팀에서 개발한 제품입니다.
 OpenAI를 기다리지 말고 Open-Sora가 완전한 오픈 소스가 될 때까지 기다리십시오.
Mar 18, 2024 pm 08:40 PM
OpenAI를 기다리지 말고 Open-Sora가 완전한 오픈 소스가 될 때까지 기다리십시오.
Mar 18, 2024 pm 08:40 PM
얼마 전 OpenAISOra는 놀라운 비디오 생성 효과로 빠르게 인기를 얻었으며 많은 문학적 비디오 모델들 사이에서 눈에 띄었고 전 세계의 관심의 초점이 되었습니다. Colossal-AI 팀은 2주 전 46% 비용 절감으로 Sora 훈련 추론 재현 프로세스를 출시한 데 이어 세계 최초의 Sora 유사 아키텍처 비디오 생성 모델 "Open-Sora1.0"을 완전 오픈 소스화했습니다. 데이터 처리, 모든 훈련 세부 사항 및 모델 가중치를 포함한 훈련 프로세스를 다루고, 글로벌 AI 애호가들과 협력하여 비디오 제작의 새로운 시대를 촉진합니다. 미리보기로 Colossal-AI 팀이 공개한 'Open-Sora1.0' 모델이 생성한 번화한 도시의 영상을 살펴보겠습니다. 오픈소라1.0
 Embedding 서비스의 로컬 실행 성능은 OpenAI Text-Embedding-Ada-002를 능가하므로 매우 편리합니다!
Apr 15, 2024 am 09:01 AM
Embedding 서비스의 로컬 실행 성능은 OpenAI Text-Embedding-Ada-002를 능가하므로 매우 편리합니다!
Apr 15, 2024 am 09:01 AM
Ollama는 Llama2, Mistral, Gemma와 같은 오픈 소스 모델을 로컬에서 쉽게 실행할 수 있는 매우 실용적인 도구입니다. 이번 글에서는 Ollama를 사용하여 텍스트를 벡터화하는 방법을 소개하겠습니다. Ollama를 로컬에 설치하지 않은 경우 이 문서를 읽을 수 있습니다. 이 기사에서는 nomic-embed-text[2] 모델을 사용합니다. 짧은 컨텍스트 및 긴 컨텍스트 작업에서 OpenAI text-embedding-ada-002 및 text-embedding-3-small보다 성능이 뛰어난 텍스트 인코더입니다. o를 성공적으로 설치한 후 nomic-embed-text 서비스를 시작하십시오.
 Microsoft와 OpenAI는 휴머노이드 로봇에 1억 달러를 투자할 계획입니다! 네티즌들은 머스크에게 전화하고 있다
Feb 01, 2024 am 11:18 AM
Microsoft와 OpenAI는 휴머노이드 로봇에 1억 달러를 투자할 계획입니다! 네티즌들은 머스크에게 전화하고 있다
Feb 01, 2024 am 11:18 AM
마이크로소프트(MS)와 오픈AI(OpenAI)가 올해 초 휴머노이드 로봇 스타트업에 거액을 투자한 것으로 알려졌다. 이 중 마이크로소프트는 9500만달러, 오픈AI는 500만달러를 투자할 계획이다. 블룸버그에 따르면 회사는 이번 라운드에서 총 5억 달러를 조달할 것으로 예상되며, 자금 조달 전 가치는 19억 달러에 이를 수 있습니다. 무엇이 그들을 끌어들이나요? 먼저 이 회사의 로봇공학 성과를 살펴보자. 이 로봇은 온통 은색과 검은색이며, 외관은 헐리우드 공상 과학 블록버스터에 나오는 로봇의 이미지와 유사합니다. 이제 그는 커피 캡슐을 커피 머신에 넣고 있습니다. 올바르게 배치되지 않으면 아무런 문제 없이 스스로 조정됩니다. 휴먼 리모콘 : 하지만 잠시 후 커피 한 잔을 꺼내서 즐길 수 있습니다. 가족 중 혹시 알아본 사람이 있나요? 네, 이 로봇은 얼마 전에 만들어졌습니다.
 전용 앱 출시로 이제 macOS에서 ChatGPT를 사용할 수 있습니다.
Jun 27, 2024 am 10:05 AM
전용 앱 출시로 이제 macOS에서 ChatGPT를 사용할 수 있습니다.
Jun 27, 2024 am 10:05 AM
Open AI의 ChatGPT Mac 애플리케이션은 이제 모든 사람이 사용할 수 있게 되었으며, 지난 몇 달 동안 ChatGPT Plus를 구독하는 사용자에게만 제한되었습니다. 최신 Apple S가 있는 한 앱은 다른 기본 Mac 앱과 마찬가지로 설치됩니다.
