

동의하지 않으면 점수를 얻게 된다. 국내 대형 AI 모델은 왜 '순위 스와핑'에 중독되는 걸까?

휴대폰계에 관심을 갖고 있는 친구들이라면 '안 받아도 점수를 준다'는 말이 낯설지 않을 거라 믿습니다. 예를 들어 AnTuTu, GeekBench와 같은 이론적인 성능 테스트 소프트웨어는 휴대폰의 성능을 어느 정도 반영할 수 있기 때문에 플레이어들로부터 많은 관심을 받았습니다. 마찬가지로 성능을 측정하기 위한 PC 프로세서 및 그래픽 카드용 벤치마킹 소프트웨어도 있습니다
'모든 것이 벤치마킹 가능'하기 때문에 가장 인기 있는 대형 AI 모델도 벤치마킹 대회에 참가하기 시작했습니다. 특히 '100모델 전쟁'이 시작된 이후에는 거의 매일 획기적인 발전이 이루어지고 있으며 각 회사는 스스로를 '벤치마'라고 부릅니다. 벤치마킹 1위".一"
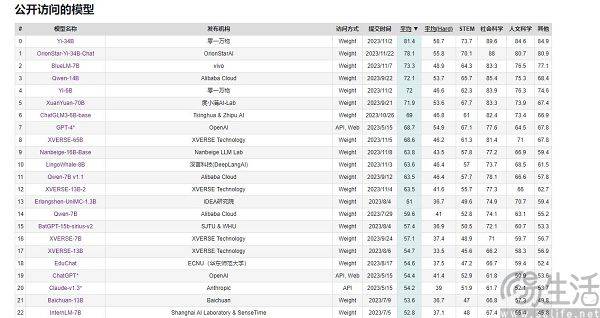
국내 대형 AI 모델은 성능 점수 측면에서는 거의 뒤처지지 않지만, 사용자 경험 측면에서는 결코 GPT-4를 능가할 수 없습니다. 이는 주요 판매 지점에서 각 휴대폰 제조업체가 항상 자신의 제품이 "판매 1위"라고 주장할 수 있다는 의문을 제기합니다. 하지만 AI 대형 모델 분야에서는 상황이 다르다. 결국 이들의 평가 기준은 기본적으로 MMLU(멀티태스킹 언어 이해 능력을 측정하는 데 사용), Big-Bench(LLM 능력을 정량화하고 추정하는 데 사용), AGIEval(대화 능력을 평가하는 데 사용) 등 기본적으로 통일되어 있습니다. 인간 수준의 문제).
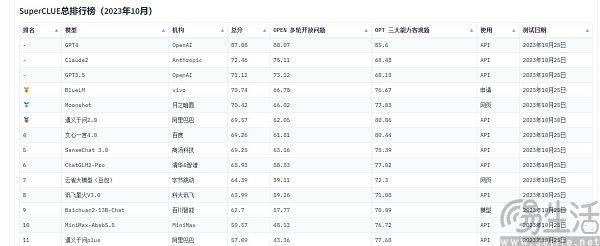
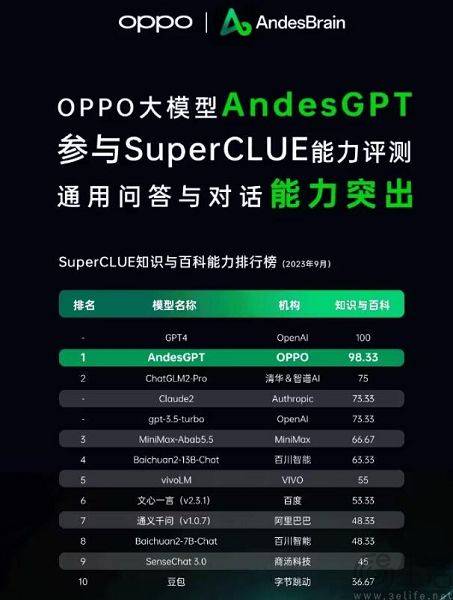
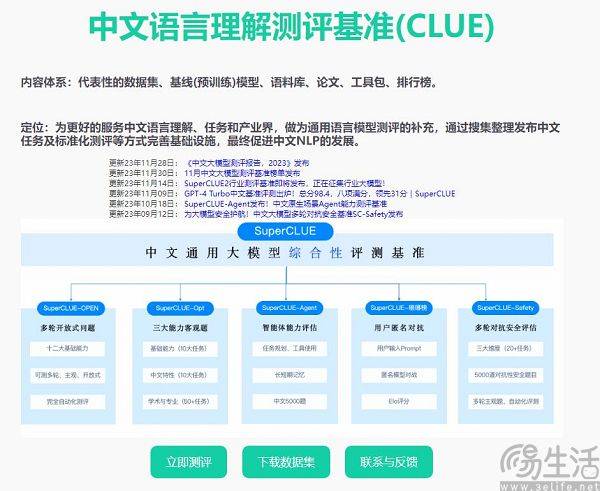
현재 중국에서 자주 인용되는 대규모 모델 평가 목록으로는 SuperCLUE, CMMLU, C-Eval 등이 있습니다. 그 중 CMMLU와 C-Eval은 칭화대학교, 상하이 교통대학교, 에든버러대학교가 공동으로 구축한 종합 시험 평가 세트입니다. CMMLU는 MBZUAI, Shanghai Jiao Tong University 및 Microsoft Research Asia가 공동으로 출범했습니다. SuperCLUE는 주요 대학 인공지능 전문가들이 공동 집필했습니다
우리 모두 알고 있듯이 스마트폰 SoC, 컴퓨터 CPU 및 그래픽 카드는 수명을 보호하기 위해 고온에서 자동으로 주파수를 낮추고 저온에서는 칩 성능을 향상시킬 수 있습니다. 따라서 일부 사람들은 휴대폰을 냉장고에 넣거나 컴퓨터에 더 강력한 냉각 시스템을 장착하여 성능 테스트를 수행하며 일반적으로 평소보다 더 높은 점수를 얻을 수 있습니다. 또한, 주요 휴대폰 제조사에서도 표준 운영이 된 다양한 벤치마킹 소프트웨어에 대해 '전용 최적화'를 실시할 예정입니다
시험 전, 우연히 시험지와 표준 답안을 보고, 예상치 못한 문제를 외우면 시험 점수가 크게 향상될 것이라고 상상할 수 있습니다. 따라서 대형 모델 목록에서 미리 설정된 문제 은행이 훈련 세트에 추가되어 대형 모델이 벤치마크 데이터에 맞는 모델이 됩니다. 게다가 현재 LLM 자체가 기억력이 뛰어나기로 유명해서, 표준 답변을 암기하는 것이 식은 죽 먹기입니다
Hillhouse 팀의 연구원들은 벤치마크 누출로 인해 대형 모델이 과장된 결과를 실행하게 될 수 있다는 사실을 발견했습니다. 예를 들어 1.3B 모델은 일부 작업에서 크기가 10배 더 큰 모델을 능가할 수 있지만 부작용은 " 시험 응시" 대형 모델의 경우 다른 일반적인 테스트 작업의 성능에 부정적인 영향을 미칩니다. 결국, 생각해보면 대형 AI 모델은 원래 '질문 작성기'였으나 특정 목록에서 높은 점수를 얻기 위해 '질문 암기기'가 되었다는 사실을 알 수 있습니다. 목록의 특정 지식과 출력 스타일을 사용하면 확실히 대규모 모델을 오도할 수 있습니다.

훈련 세트, 검증 세트, 테스트 세트가 교차하지 않는 것은 분명 이상적인 상태일 뿐입니다. 결국 현실은 매우 희박하며, 데이터 유출 문제는 근본적으로 거의 불가피합니다. 관련 기술이 지속적으로 발전하면서 현재 대형 모델의 초석이 되는 트랜스포머 구조의 메모리와 수신 능력이 지속적으로 향상되고 있다. 올여름 마이크로소프트 리서치의 일반 AI 전략을 통해 모델이 1억 개의 토큰을 부담 없이 받을 수 있게 됐다. 건망증은 용납할 수 없습니다. 즉, 미래에는 대형 AI 모델이 인터넷 전체를 읽을 수 있는 능력을 갖게 될 가능성이 높다.
기술적 진보를 제쳐두더라도, 현재의 기술 수준으로는 고품질의 데이터가 항상 부족하고 생산 능력도 제한되어 있기 때문에 데이터 오염을 피하기가 사실상 어렵습니다. AI 연구팀인 에포크(Epoch)가 올해 초 발표한 논문에 따르면 AI는 5년 이내에 고품질의 인간 언어 데이터를 모두 소진할 것이며, 이 결과는 인간 언어의 성장률을 높일 것이라는 점이다. 즉, 앞으로 5년 안에 모든 인류가 출판하게 될 책, 쓰여진 논문, 쓰여진 코드를 모두 고려하여 결과를 예측합니다.
데이터 세트가 평가에 적합하다면 사전 훈련에 확실히 더 효과적일 것입니다. 예를 들어 OpenAI의 GPT-4는 권위 있는 추론 평가 데이터 세트 GSM8K를 사용합니다. 따라서 현재 대규모 모델 평가 분야에서는 대규모 모델의 데이터에 대한 수요가 끝이 없어 평가기관이 인공지능 대규모 모델보다 더 빠르고 더 멀리 나아가야 하는 난처한 문제가 있다. 제조업 자. 하지만 오늘날 평가기관은 이런 일을 전혀 할 수 없는 것 같습니다
일부 제조사에서는 왜 대형 모델의 주행 점수에 주목하고, 순위를 잇달아 올리려고 노력하는 걸까요? 실제로 이 동작의 이면에 있는 논리는 앱 개발자가 자신의 앱 사용자 수에 물을 주입하는 것과 정확히 동일합니다. 결국 앱의 가치를 측정하는 데 있어 사용자 규모는 핵심 요소이며, 현재 대규모 AI 모델의 초기 단계에서는 평가 목록의 결과가 결국 상대적으로 객관적인 유일한 기준이 됩니다. 대중의 인식, 높은 점수는 강력한 성과와 동일함을 의미합니다.
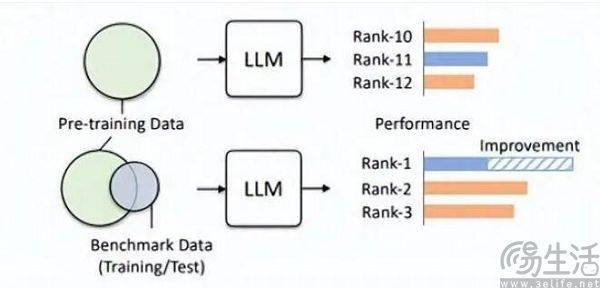
순위를 브러싱하면 강력한 홍보 효과를 가져올 수 있고 심지어 자금 조달의 기반을 마련할 수도 있지만, 상업적 이익이 추가되면 대형 AI 모델 제조업체가 순위를 브러싱하기 위해 서두르게 될 것입니다.
위 내용은 동의하지 않으면 점수를 얻게 된다. 국내 대형 AI 모델은 왜 '순위 스와핑'에 중독되는 걸까?의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7519
7519
 15
1378
52
81
11
53
19
21
68
15
1378
52
81
11
53
19
21
68

 2023년 최신 그래픽 카드 성능 순위 목록
Jan 05, 2024 pm 11:12 PM
2023년 최신 그래픽 카드 성능 순위 목록
Jan 05, 2024 pm 11:12 PM
2023년 최신 그래픽 카드 벤치마크 순위가 공개되었습니다. 그래픽 카드 래더 차트를 팔로우하는 사용자는 최근 그래픽 카드 제조업체가 계속해서 새로운 그래픽 카드를 출시하고, 이전 시리즈에도 새로운 그래픽 카드를 출시함에 따라 새로운 목록을 발표했습니다. ~2023년 최신 그래픽 카드 벤치마크 순위, 그래픽 카드 래더 순위, 2023년 컴퓨터 그래픽 카드 구매 제안: 1. 저가형 그래픽 카드: RTX3050, 5600XT 및 2060S는 모두 좋은 보급형 선택과 동일합니다. 그래픽 카드를 구입하고 LOL, Cf, Overwatch 및 기타 경량 3D 온라인 게임을 플레이하는 데 사용할 수 있는 뛰어난 가성비의 CPU를 구입하세요. 2. 보급형 그래픽 카드: 3060, 대부분의 일반 주류 3D 게임에 적합, 중형 그리고 낮은 이미지 품질. 3. 중급 그래픽 카드: NVIDIA: RTX3060Ti, RTX2
 Kirin 9000S 잠금 해제 벤치마크 노출: 놀라운 성능이 기대치를 뛰어넘습니다.
Sep 05, 2023 pm 12:45 PM
Kirin 9000S 잠금 해제 벤치마크 노출: 놀라운 성능이 기대치를 뛰어넘습니다.
Sep 05, 2023 pm 12:45 PM
화웨이의 최신 Mate60Pro 휴대폰이 국내 시장에 출시된 후 큰 관심을 끌었습니다. 그러나 최근 벤치마크 플랫폼에서는 해당 기기에 탑재된 Kirin 9000S 프로세서의 성능에 대한 논란이 있었습니다. 플랫폼의 테스트 결과에 따르면 Kirin 9000S의 실행 점수가 불완전하고 GPU 실행 점수가 누락되어 일부 벤치마킹 소프트웨어가 적응할 수 없게 되었습니다. 온라인에 노출된 정보에 따르면 Kirin 9000S는 놀라운 결과를 얻었습니다. 잠금 해제된 달리기 점수 테스트의 총점은 950935점입니다. 구체적으로 CPU 점수는 279,677점으로 높은데, 앞서 누락된 GPU 점수는 251,152점이다. 이전 AnTuTu 공식 테스트의 총점 699783점과 비교하면 Kirin 9000S의 성능 향상을 보여줍니다.
 AI 대형 모델의 물결로 인해 컴퓨팅 성능에 대한 수요가 폭발적으로 증가했습니다. SenseTime의 '대형 모델 + 대형 컴퓨팅 성능'은 여러 산업의 발전을 지원합니다.
Jun 09, 2023 pm 07:35 PM
AI 대형 모델의 물결로 인해 컴퓨팅 성능에 대한 수요가 폭발적으로 증가했습니다. SenseTime의 '대형 모델 + 대형 컴퓨팅 성능'은 여러 산업의 발전을 지원합니다.
Jun 09, 2023 pm 07:35 PM
최근에는 'AI가 시대를 선도하고, 컴퓨팅 파워가 미래를 주도한다'라는 주제로 '린강 신구 지능형 컴퓨팅 컨퍼런스'가 열렸다. 회의에서 신지역 지능형 컴퓨팅 산업 연합이 공식적으로 설립되었으며, SenseTime은 컴퓨팅 파워 제공업체로서 이 연합의 회원이 되었습니다. 동시에 SenseTime은 "신지역 지능형 컴퓨팅 산업 체인 마스터" 기업이라는 칭호를 받았습니다. Lingang 컴퓨팅 파워 생태계의 적극적인 참여자로서 SenseTime은 현재 아시아 최대 지능형 컴퓨팅 플랫폼 중 하나인 SenseTime AIDC를 구축했습니다. SenseTime AIDC는 총 5,000페타플롭의 컴퓨팅 파워를 출력하고 수천억 개의 매개변수를 갖춘 20개의 초대형 모델을 지원할 수 있습니다. 동시에 훈련하십시오. AIDC를 기반으로 구축된 미래지향적인 대규모 디바이스인 SenseCore는 인공지능에 힘을 실어주는 고효율, 저비용, 대규모 차세대 AI 인프라 및 서비스를 만드는 데 전념하고 있습니다.
 연구원: AI 모델 추론은 더 많은 전력을 소비하며, 2027년 산업 전력 소비량은 네덜란드와 비슷할 것
Oct 14, 2023 am 08:25 AM
연구원: AI 모델 추론은 더 많은 전력을 소비하며, 2027년 산업 전력 소비량은 네덜란드와 비슷할 것
Oct 14, 2023 am 08:25 AM
IT하우스는 '셀(Cell)'의 자매지 '줄(Joule)'이 이번 주 '인공지능의 성장하는 에너지 발자국(The getting Energy Footprint of Artificial Intelligence)'이라는 제목의 논문을 게재했다고 13일 보도했다. 문의를 통해 우리는 이 논문이 과학 연구 기관인 Digiconomist의 설립자인 Alex DeVries에 의해 출판되었다는 것을 알게 되었습니다. 그는 앞으로 인공지능의 추론 성능이 많은 전력을 소비할 수 있다고 주장했다. 2027년까지 인공지능의 전력 소비량은 네덜란드의 1년 전력 소비량과 맞먹을 것으로 추정된다. 외부 세계에서는 항상 AI 모델을 훈련하는 것이 "AI에서 가장 중요한 것"이라고 믿어왔습니다.
 OPPO Reno11 F가 Geekbench에 등장: Dimensity 7050 장착
Feb 06, 2024 pm 11:10 PM
OPPO Reno11 F가 Geekbench에 등장: Dimensity 7050 장착
Feb 06, 2024 pm 11:10 PM
2월 6일 언론 보도에 따르면 OPPO는 작년에 OPPOReno11 시리즈를 출시하여 표준 버전과 Pro 버전의 두 가지 버전을 제공했습니다. 이제 OPPO는 Reno11 시리즈의 새 버전인 Reno11F도 출시할 예정입니다. 현재 OPPOReno11F는 Geekbench6 데이터베이스에 등장했습니다. 새 시스템의 단일 코어 실행 점수는 897점, 멀티 코어 실행 점수는 2329점입니다. 벤치마크 테스트에 따르면 새 전화기에는 Mali-G68MC4 GPU 및 8GB RAM과 쌍을 이루는 MediaTek Dimensity 7050 SoC가 장착되어 있으며 Android 14 기반 ColorOS14 시스템이 사전 설치되어 있습니다. 뉴스에 따르면 OPPOReno11F는 6.7인치 A를 사용할 예정이다.
 4배 더 빨라진 Bytedance의 오픈소스 고성능 훈련 추론 엔진 LightSeq 기술 공개
May 02, 2023 pm 05:52 PM
4배 더 빨라진 Bytedance의 오픈소스 고성능 훈련 추론 엔진 LightSeq 기술 공개
May 02, 2023 pm 05:52 PM
Transformer 모델은 Google 팀이 2017년에 발표한 논문 "Attentionisallyouneed"에서 나왔습니다. 이 논문은 Seq2Seq 모델의 순환 구조를 대체하기 위해 Attention을 사용하는 개념을 처음 제안했으며, 이는 NLP 분야에 큰 영향을 미쳤습니다. 그리고 최근 연구의 지속적인 발전으로 Transformer 관련 기술은 점차 자연어 처리에서 다른 분야로 흘러가고 있습니다. 지금까지 Transformer 시리즈 모델은 NLP, CV, ASR 및 기타 분야의 주류 모델이 되었습니다. 따라서 Transformer 모델을 어떻게 더 빠르게 훈련하고 추론할 것인가가 업계에서는 중요한 연구 방향이 되었습니다. 정밀도가 낮은 양자화 기술은
 China Unicom, 텍스트에서 이미지와 비디오 클립을 생성할 수 있는 대형 이미지 및 텍스트 AI 모델 출시
Jun 29, 2023 am 09:26 AM
China Unicom, 텍스트에서 이미지와 비디오 클립을 생성할 수 있는 대형 이미지 및 텍스트 AI 모델 출시
Jun 29, 2023 am 09:26 AM
Driving China News 2023년 6월 28일, 오늘 상하이에서 열린 모바일 월드 콩그레스에서 China Unicom은 그래픽 모델 "Honghu Graphic Model 1.0"을 출시했습니다. China Unicom은 Honghu 그래픽 모델이 통신업체의 부가가치 서비스를 위한 최초의 대형 모델이라고 밝혔습니다. China Business News 기자는 Honghu의 그래픽 모델이 현재 8억 개의 훈련 매개변수와 20억 개의 훈련 매개변수의 두 가지 버전을 가지고 있으며 텍스트 기반 사진, 비디오 편집, 사진 기반 사진과 같은 기능을 실현할 수 있다는 사실을 알게 되었습니다. 또한, China Unicom Liu Liehong 회장도 오늘 기조연설에서 생성 AI가 발전의 특이점을 가져오고 향후 2년 내에 일자리의 50%가 인공 지능에 의해 심각한 영향을 받을 것이라고 말했습니다.
 OnePlus Ace 3V가 Geekbench 플랫폼에 등장: Snapdragon 7+ Gen3의 세계 초연
Mar 12, 2024 pm 10:34 PM
OnePlus Ace 3V가 Geekbench 플랫폼에 등장: Snapdragon 7+ Gen3의 세계 초연
Mar 12, 2024 pm 10:34 PM
3월 12일 뉴스에 따르면 OnePlus Ace3V 휴대폰이 모델 번호 PJF110으로 Geekbench 벤치마킹 플랫폼에 등장했습니다. Geekbench6 실행 점수에서 OnePlus Ace3V는 최고 싱글 코어 점수 1848점과 멀티 코어 점수 5007점을 달성했으며, Geekbench5에서는 싱글 코어 점수 1416점과 멀티 코어 점수 4829점을 달성하여 Dimensity 9200에 근접했습니다. +. OnePlus Ace3V는 세계 최초의 Snapdragon 7+Gen3 모바일 플랫폼이 될 것으로 알려졌습니다. TSMC의 4nm 공정을 기반으로 제조되며 "1+4+3" 코어 구성을 채택합니다. Cortex-X4 초대형 코어 주파수는 2.9입니다. GHz이며 Adreno732 GPU를 통합합니다. 배터리 수명 측면에서 항공기에는 55개가 장착되어 있습니다.
