본 글은 자율주행하트 공개계정의 승인을 받아 재인쇄되었습니다. 재인쇄시 출처를 꼭 밝혀주세요
앞에 쓰세요&&작가의 개인적인 이해입니다
현재 Transformer 구조를 기반으로 한 알고리즘 모델이 널리 사용되고 있습니다. 컴퓨터 비전(CV) 분야가 큰 영향을 미쳤습니다. 이는 많은 기본 컴퓨터 비전 작업에서 이전 CNN(컨벌루션 신경망) 알고리즘 모델을 능가합니다. 다음은 제가 찾은 다양한 기본 컴퓨터 비전 작업의 최신 LeaderBoard 목록 순위입니다. LeaderBoard를 통해 다양한 컴퓨터 비전 작업에서 Transformer 알고리즘 모델의 우위를 확인할 수 있습니다
ImageNet LeaderBoard에서 첫 번째, 상위 5개 모델 중 각 모델은 Transformer 구조를 사용하는 반면 CNN 구조는 부분적으로만 사용되거나 Transformer와 결합되어 있음을 목록에서 볼 수 있습니다.

이미지 분류 작업을 위한 LeaderBoard
다음은 COCO 테스트 개발의 LeaderBoard입니다. 목록에서 볼 수 있듯이 상위 5개 중 절반 이상이 DETR을 기반으로 합니다. 알고리즘과 유사한 구조가 확장되었습니다.
대상 감지 작업을 위한 LeaderBoard
마지막 것은 ADE20K val의 LeaderBoard입니다. 또한 목록의 상위 몇 개 중 Transformer 구조가 여전히 현재를 차지하고 있음을 알 수 있습니다. 위치.
의미론적 분할 작업을 위한 리더보드
Transformer는 현재 중국에서 큰 개발 잠재력을 보여주고 있지만, 현재 컴퓨터 비전 커뮤니티는 Vision Transformer의 내부 작동이나 의사결정(출력 예측 결과)을 완전히 파악하지 못했습니다. 해석 가능성에 대한 필요성이 점차 나타났습니다. 이러한 모델이 어떻게 결정을 내리는지 이해해야만 성능을 향상하고 인공 지능 시스템에 대한 신뢰를 구축할 수 있습니다.
이 기사의 주요 목적은 Vision Transformer의 다양한 해석 방법을 연구하고 다양한 알고리즘, 구조 유형 및 구조의 연구 동기를 기반으로 하는 것입니다. 응용 시나리오를 분류하여 리뷰 기사를 구성합니다
Vision Transformer 분석
지금 언급한 것처럼 Vision Transformer의 구조는 다양한 기본 컴퓨터 비전 작업에서 매우 좋은 결과를 얻었습니다. 해석 가능성을 향상시키기 위해 컴퓨터 비전 커뮤니티에는 수많은 방법이 등장했습니다. 이 기사에서는 주로 분류 작업에 중점을 두고 Common Attribution Methods, Attention-based Methods, Pruning-based Methods, Inherently explainable Methods, Other의 다섯 가지 측면에서 최신 및 최신 항목을 선택합니다. Tasks 고전 작품이 소개됩니다. 논문에 나온 마인드맵은 관심 있는 내용을 바탕으로 더 자세히 읽어보시면 됩니다~
이 글의 마인드맵
일반적인 어트리뷰션 방법
보통 속성 방법을 기반으로 한 설명이 시작됩니다. 모델에서 입력 특성이 점차 최종 출력 결과를 얻는 과정을 설명하는 것부터 시작하겠습니다. 이러한 방식은 주로 모델의 예측 결과와 입력 특성 간의 상관 관계를 측정하는 데 사용됩니다. 이 중
Grad-CAM
및 Integrated Gradients 알고리즘은 Visual Transformer 기반 알고리즘에 직접 적용됩니다. SHAP 및 Layer-Wise Relevance Propagation(LRP)과 같은 다른 방법이 ViT 기반 아키텍처를 탐색하는 데 사용되었습니다. 그러나 SHAP와 같은 방법의 계산 비용이 매우 높기 때문에 최근 ViT Shapely 알고리즘은 ViT 관련 응용 연구에 적합하도록 설계되었습니다. Attention-based Methods
Vision Transformer는 Attention 메커니즘을 통해 강력한 특징 추출 기능을 얻었습니다. Attention 기반 해석 방법 중 Attention Weight 결과를 시각화하는 것은 매우 효과적인 방법입니다. 이 기사에서는 몇 가지 시각화 기술을 소개합니다
-
Raw Attention: 이름에서 알 수 있듯이 이 방법은 네트워크 모델의 중간 계층에서 얻은 Attention 가중치 맵을 시각화하여 모델의 효과를 분석하는 것입니다.
-
Attention Rollout: 이 기술은 네트워크의 다양한 계층에서 주의 가중치를 확장하여 입력 토큰에서 중간 임베딩으로의 정보 전송을 추적합니다.
-
Attention Flow: 이 방법은 Attention Map을 플로우 네트워크로 취급하고 최대 플로우 알고리즘을 사용하여 중간 임베딩부터 입력 토큰까지의 최대 플로우 값을 계산합니다.
-
partialLRP: 이 방법은 Vision Transformer의 다중 헤드 어텐션 메커니즘을 시각화하는 동시에 각 어텐션 헤드의 중요성을 고려하기 위해 제안되었습니다.
-
Grad-SAM: 이 방법은 모델 예측을 설명하기 위해 원래 Attention 매트릭스에만 의존하는 한계를 완화하는 데 사용되며, 연구자는 원래 Attention 가중치에 그래디언트를 사용하도록 유도합니다.
-
Beyond Intuition: 이 방법은 주의력 인식과 추론 피드백의 두 단계를 포함하여 주의력을 설명하는 방법이기도 합니다.
마지막으로 다양한 해석 방법에 대한 주의 시각화 다이어그램이 있습니다. 다양한 시각화 방법의 차이를 직접 느껴보실 수 있습니다.
다양한 시각화 방법의 주의 지도 비교
가지치기 기반 방법
가지치기는 변압기 구조의 효율성과 복잡성을 최적화하는 데 널리 사용되는 매우 효과적인 방법입니다. 가지치기 방법은 중복되거나 쓸모 없는 정보를 삭제하여 모델의 매개변수 수와 계산 복잡성을 줄입니다. 가지치기 알고리즘은 모델의 계산 효율성을 향상시키는 데 중점을 두지만 이러한 유형의 알고리즘은 여전히 모델의 해석성을 달성할 수 있습니다.
이 기사에서 Vision-Transformer를 기반으로 한 가지치기 방법은 대략 세 가지 범주로 나눌 수 있습니다: explicitly explainable(explicitly explainable), implicitly explainable(implicitly explainable), posssible explainable(posssible explainable) explain).
-
명시적으로 설명 가능
가지치기 기반 방법 중에는 더 간단하고 설명하기 쉬운 모델을 제공할 수 있는 여러 유형의 방법이 있습니다.
-
IA-RED^2: 이 방법의 목표는 알고리즘 모델의 계산 효율성과 해석 가능성 간의 최적의 균형을 달성하는 것입니다. 그리고 이 과정에서 원래 ViT 알고리즘 모델의 유연성이 유지됩니다.
-
X-Pruner: 이 방법은 특정 클래스를 예측하는 데 있어 예측 가능한 각 단위의 기여도를 측정하는 해석 가능한 지각 마스크를 생성하여 돌출 단위를 잘라내는 방법입니다.
-
Vision DiffMask: 이 가지치기 방법에는 각 ViT 레이어에 게이팅 메커니즘을 추가하는 것이 포함됩니다. 게이팅 메커니즘을 통해 입력을 보호하면서 모델의 출력을 유지할 수 있습니다. 이 외에도 알고리즘 모델은 나머지 이미지의 하위 집합을 명확하게 트리거할 수 있으므로 모델 예측을 더 잘 이해할 수 있습니다.
-
암시적으로 설명 가능
가지치기 기반 방법 중에는 암시적 설명 모델 범주로 나눌 수 있는 몇 가지 고전적인 방법도 있습니다.
-
Dynamic ViT: 이 방법은 경량 예측 모듈을 사용하여 현재 특성을 기반으로 각 토큰의 중요성을 추정합니다. 그런 다음 이 경량 모듈을 ViT의 여러 계층에 추가하여 계층적 방식으로 중복 토큰을 정리합니다. 가장 중요한 것은 이 방법이 분류에 가장 많이 기여하는 주요 이미지 부분을 점진적으로 찾아 해석 가능성을 향상시킨다는 것입니다.
-
Efficient Vision Transformer (EViT): 이 방법의 핵심 아이디어는 토큰을 재구성하여 EViT를 가속화하는 것입니다. 주의 점수를 계산함으로써 EViT는 가장 관련성이 높은 토큰을 유지하는 동시에 관련성이 낮은 토큰을 추가 토큰으로 융합합니다. 동시에, 논문 작성자는 EViT의 해석 가능성을 평가하기 위해 여러 입력 이미지에 대한 토큰 인식 프로세스를 시각화했습니다.
-
설명 가능
이러한 유형의 방법은 원래 ViT의 해석 가능성을 향상시키기 위해 설계된 것은 아니지만, 이러한 유형의 방법은 모델의 해석 가능성에 대한 추가 연구에 대한 큰 잠재력을 제공합니다.
-
패치 슬리밍: 하향식 접근 방식을 통해 이미지의 중복 패치에 집중하여 ViT를 가속화합니다. 알고리즘은 중요한 시각적 특징을 강조하는 주요 패치 기능을 선택적으로 유지하여 해석 가능성을 향상시킵니다.
-
HVT(Hierarchical Visual Transformer): 이 방법은 ViT의 확장성과 성능을 향상시키기 위해 도입되었습니다. 모델 깊이가 증가함에 따라 시퀀스 길이는 점차 감소합니다. 또한 ViT 블록을 여러 단계로 나누고 각 단계에서 풀링 작업을 적용함으로써 계산 효율성이 크게 향상됩니다. 모델의 가장 중요한 구성 요소에 대한 점진적인 집중을 고려할 때 해석 가능성 및 설명 가능성 향상에 대한 잠재적 영향을 탐색할 수 있는 기회가 있습니다.
본질적으로 설명 가능한 방법
다양한 해석 가능한 방법 중에는 이를 본질적으로 설명할 수 있는 알고리즘 모델을 주로 개발하는 방법이 있습니다. 그러나 이러한 모델은 더 복잡한 블랙박스와 동일한 수준의 정확도를 달성하는 데 어려움을 겪는 경우가 많습니다. 모델. 따라서 해석 가능성과 성능 사이에 신중한 균형을 고려해야 합니다. 다음으로 몇 가지 고전 작품을 간략하게 소개합니다.
-
ViT-CX: 이 방법은 ViT 모델에 맞게 맞춤화된 마스크 기반 해석 방법입니다. 이 접근 방식은 패치 임베딩과 패치 임베딩이 모델 출력에 미치는 영향에 초점을 맞추기보다는 의존합니다. 이 방법은 마스크 생성과 마스크 집계의 두 단계로 구성되어 보다 의미 있는 돌출 맵을 제공합니다.
-
ViT-NeT: 이 방법은 트리 구조와 프로토타입을 통해 의사 결정 과정을 설명하는 새로운 신경 트리 디코더입니다. 동시에 이 알고리즘은 결과를 시각적으로 해석할 수도 있습니다.
-
R-Cut: 이 방법은 Relationship Weighted Out 및 Cut을 통해 ViT의 해석 가능성을 향상시킵니다. 이 방법에는 Relationship Weighted Out 및 Cut 모듈이라는 두 가지 모듈이 포함됩니다. 전자는 중간 계층에서 특정 클래스의 정보를 추출하는 데 중점을 두고 관련 기능을 강조합니다. 후자는 세분화된 특징 분해를 수행합니다. 두 모듈을 통합하면 조밀한 클래스별 해석 가능성 맵이 생성될 수 있습니다.
기타 작업
ViT 기반 아키텍처는 탐색의 다른 컴퓨터 비전 작업에 대해 여전히 설명이 필요합니다. 일부 해석 가능성 방법은 다른 작업을 위해 특별히 제안되었으며 관련 분야의 최신 작업은 아래에서 소개됩니다
-
eX-ViT: 이 알고리즘은 약한 지도 의미론적 분할을 기반으로 하는 새로운 해석 가능한 시각적 변환기입니다. 또한, 해석성을 향상시키기 위해 속성 지향 손실 모듈이 도입되었으며, 이 모듈에는 전역 수준 속성 지향 손실, 로컬 수준 속성 식별성 손실, 속성 다양성 손실의 세 가지 손실이 포함되어 있습니다. 전자는 주의 지도를 사용하여 해석 가능한 특징을 생성하는 반면, 후자의 두 가지는 속성 학습을 향상시킵니다.
-
DINO: 이 방법은 간단한 자기주도법이자 라벨이 없는 자가증류법입니다. 최종 학습된 어텐션 맵은 이미지의 의미 영역을 효과적으로 유지하여 해석 가능한 목적을 달성할 수 있습니다.
-
Generic Attention-model: 이 방법은 Transformer 아키텍처를 기반으로 하는 예측을 위한 알고리즘 모델입니다. 이 방법은 가장 일반적으로 사용되는 세 가지 아키텍처, 즉 순수 셀프 어텐션, 조인트 어텐션과 결합된 셀프 어텐션, 인코더-디코더 어텐션에 적용됩니다. 모델의 해석 가능성을 테스트하기 위해 저자는 시각적 질문 응답 작업을 사용했지만 객체 감지 및 이미지 분할과 같은 다른 CV 작업에도 적용할 수 있습니다.
-
ATMAN: 이는 주의 메커니즘을 사용하여 출력 예측과 관련된 입력의 상관 관계 맵을 생성하는 양식에 구애받지 않는 섭동 방법입니다. 이 접근 방식은 메모리 효율적인 주의 작업을 통해 변형 예측을 이해하려고 시도합니다.
-
Concept-Transformer: 이 알고리즘은 사용자가 정의한 상위 수준 개념에 대한 주의 점수를 강조하여 모델 출력에 대한 설명을 생성하고 신뢰성을 보장합니다.
미래 전망
현재 Transformer 아키텍처를 기반으로 한 알고리즘 모델은 다양한 컴퓨터 비전 작업에서 탁월한 결과를 얻었습니다. 그러나 현재 특히 ViT 애플리케이션에서 해석 가능성 방법을 사용하여 모델 디버깅 및 개선을 촉진하고 모델 공정성과 신뢰성을 향상시키는 방법에 대한 명확한 연구가 부족합니다.
이 문서는 이미지 분류 작업을 사용하여 공정성과 신뢰성을 향상시키는 것을 목표로 합니다. Vision Transformer의 해석 가능성 알고리즘 모델은 독자들이 그러한 모델의 아키텍처를 더 잘 이해할 수 있도록 분류하고 정리했습니다. 모든 사람에게 도움이 되기를 바랍니다
다시 작성해야 할 내용은 다음과 같습니다. // mp.weixin.qq.com/s/URkobeRNB8dEYzrECaC7tQ
위 내용은 Visual Transformer에 대한 깊은 이해, Visual Transformer 분석의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!


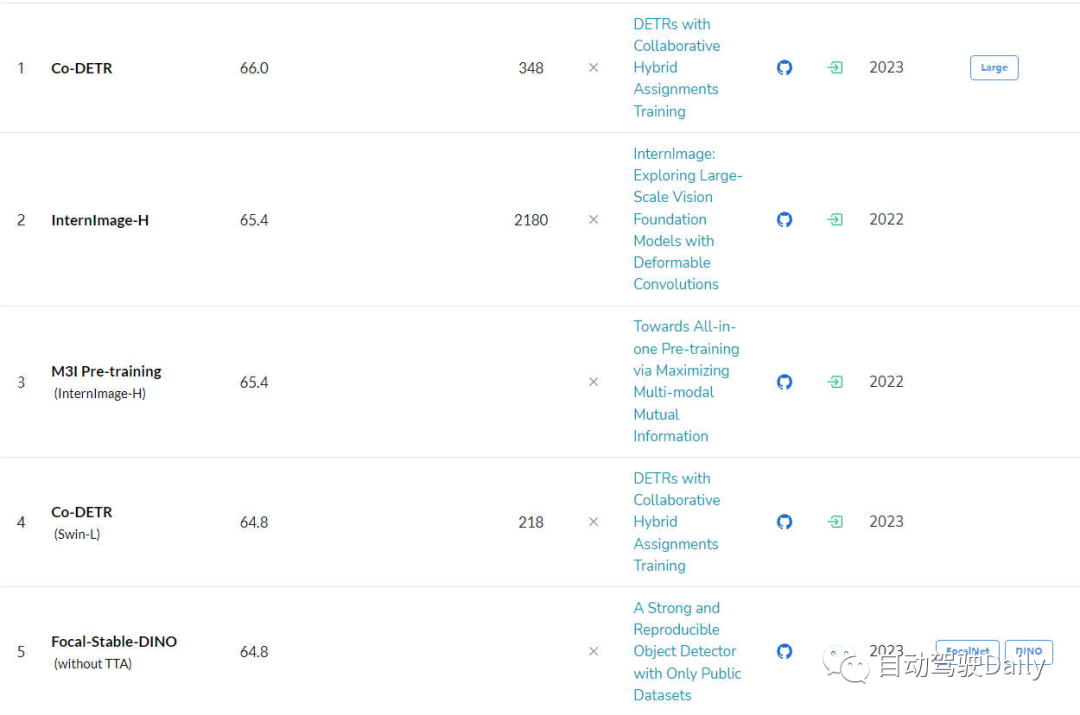 대상 감지 작업을 위한 LeaderBoard
대상 감지 작업을 위한 LeaderBoard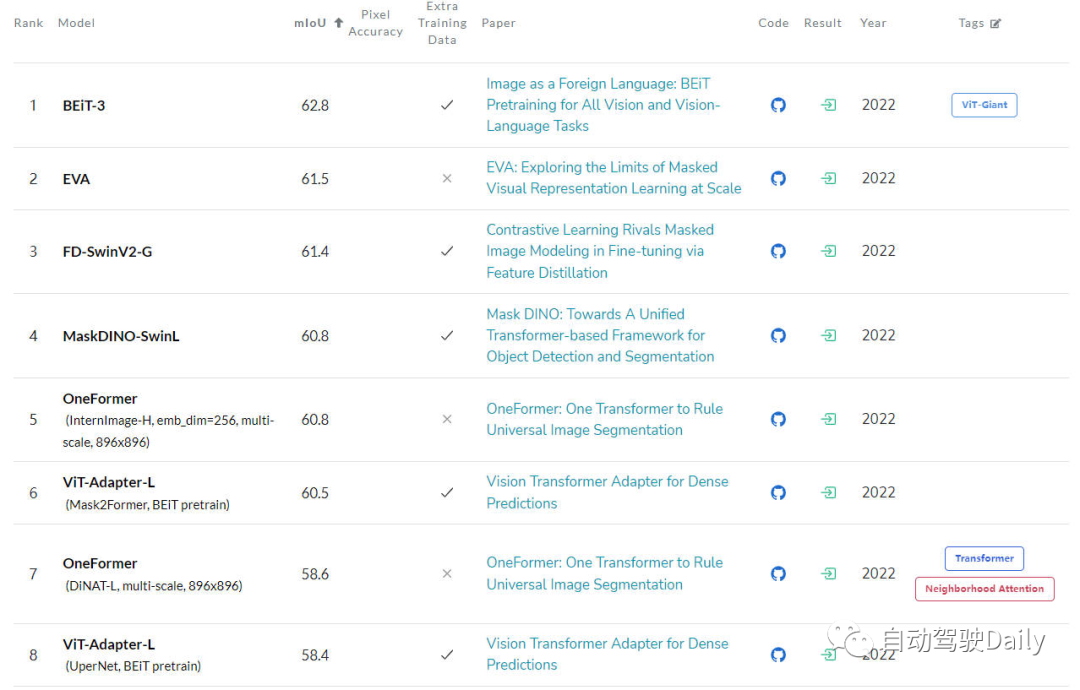 의미론적 분할 작업을 위한 리더보드
의미론적 분할 작업을 위한 리더보드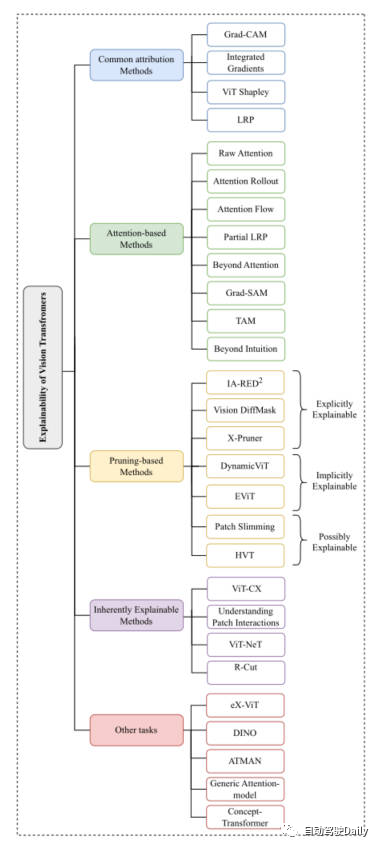




















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



