

NVIDIA가 AMD를 강타했습니다. 소프트웨어 지원을 통해 H100의 AI 성능은 MI300X보다 47% 빠릅니다!


12월 14일 뉴스에 따르면 AMD는 이달 초 가장 강력한 AI 칩인 Instinct MI300X를 출시했습니다. 8-GPU 서버의 AI 성능은 NVIDIA H100 8-GPU보다 60% 더 높습니다. 이와 관련해 엔비디아는 최근 H100과 MI300X의 최신 성능 비교 데이터 세트를 공개해 H100이 어떻게 올바른 소프트웨어를 사용해 MI300X보다 빠른 AI 성능을 제공할 수 있는지 보여줬다.
AMD가 이전에 발표한 데이터에 따르면 MI300X의 FP8/FP16 성능은 NVIDIA H100의 1.3배에 달했으며 Llama 2 70B 및 FlashAttention 2 모델의 실행 속도는 H100보다 20% 빠릅니다. 8v8 서버에서 Llama 2 70B 모델을 실행할 때 MI300X는 H100보다 40% 빠르며 Bloom 176B 모델을 실행할 때 MI300X는 H100보다 60% 빠릅니다.
그러나 AMD가 MI300X를 NVIDIA H100과 비교할 때 AMD는 최신 ROCm 6.0 제품군(희소성 등을 포함하여 FP16, Bf16 및 FP8과 같은 최신 컴퓨팅 형식을 지원할 수 있음)의 최적화 라이브러리를 사용했다는 점을 지적해야 합니다. ) , 이 숫자를 얻으려면. 대조적으로, NVIDIA H100은 NVIDIA의 TensorRT-LLM과 같은 최적화 소프트웨어를 사용하지 않고 테스트되지 않았습니다.
NVIDIA H100 테스트에 대한 AMD의 암시적 진술은 vLLM v.02.2.2 추론 소프트웨어와 NVIDIA DGX H100 시스템을 사용하여 Llama 2 70B 쿼리의 입력 시퀀스 길이가 2048이고 출력 시퀀스 길이가 128임을 보여줍니다
DGX H100(8개의 NVIDIA H100 Tensor Core GPU, 80GB HBM3 포함)에 대해 NVIDIA가 발표한 최신 테스트 결과에 따르면 공용 NVIDIA TensorRT LLM 소프트웨어가 사용되었으며, 그 중 v0.5.0이 Batch-1 테스트, v0에 사용되었습니다. .6.1 대기 시간 임계값 측정. 테스트의 작업 부하 세부 사항은 이전 AMD 테스트와 동일합니다
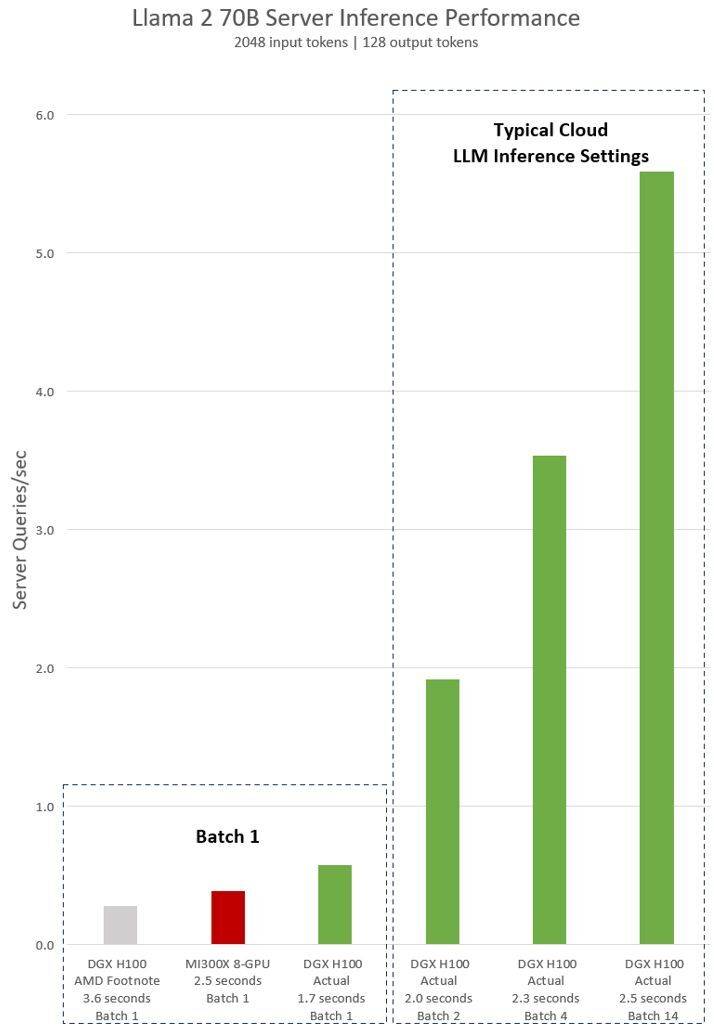
결과에 따르면, 최적화된 소프트웨어를 사용한 후 NVIDIA DGX H100 서버의 성능이 2배 이상 향상되었으며, AMD가 시연한 MI300X 8-GPU 서버보다 47% 더 빠릅니다
DGX H100은 단일 추론 작업을 1.7초 만에 처리할 수 있습니다. 응답 시간과 데이터 센터 처리량을 최적화하기 위해 클라우드 서비스는 특정 서비스에 대해 고정된 응답 시간을 설정합니다. 이를 통해 여러 추론 요청을 더 큰 "배치"로 결합하여 서버의 초당 전체 추론 수를 늘릴 수 있습니다. MLPerf와 같은 업계 표준 벤치마크에서도 이 고정 응답 시간 측정항목을 사용하여 성능을 측정합니다
응답 시간의 약간의 절충으로 인해 서버가 실시간으로 처리할 수 있는 추론 요청 수에 불확실성이 생길 수 있습니다. 고정된 2.5초 응답 시간 예산을 사용하여 NVIDIA DGX H100 서버는 초당 5개 이상의 Llama 2 70B 추론을 처리할 수 있는 반면 Batch-1은 초당 1개 미만을 처리할 수 있습니다.
분명히 Nvidia가 이러한 새로운 벤치마크를 사용하는 것은 상대적으로 공정합니다. 결국 AMD도 GPU 성능을 평가하기 위해 최적화된 소프트웨어를 사용하므로 Nvidia H100을 테스트할 때 동일한 작업을 수행하는 것은 어떨까요?
NVIDIA의 소프트웨어 스택은 CUDA 생태계를 중심으로 이루어지며 수년간의 노력과 개발 끝에 인공 지능 시장에서 매우 강력한 위치를 차지하고 있는 반면, AMD의 ROCm 6.0은 새로운 것이며 아직 실제 시나리오에서 테스트되지 않았습니다.
AMD가 이전에 공개한 정보에 따르면 MI300X GPU를 Nvidia의 H100 솔루션을 대체하는 것으로 간주하는 Microsoft 및 Meta와 같은 주요 회사와의 거래의 상당 부분을 달성했습니다.
AMD의 최신 Instinct MI300X는 2024년 상반기에 대량 출하될 예정입니다. 하지만 NVIDIA의 더욱 강력한 H200 GPU도 그때쯤 출하될 예정이며, NVIDIA도 하반기에 차세대 Blackwell B100을 출시할 예정입니다. 2024. 또한 인텔은 차세대 AI 칩인 가우디 3(Gaudi 3)도 출시할 예정이다. 다음으로 인공지능 분야의 경쟁은 더욱 치열해질 것으로 보인다.
편집자: 핵심 지능 - 루로니 검
위 내용은 NVIDIA가 AMD를 강타했습니다. 소프트웨어 지원을 통해 H100의 AI 성능은 MI300X보다 47% 빠릅니다!의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7529
7529
 15
1378
52
81
11
54
19
21
76
15
1378
52
81
11
54
19
21
76

 ASUS, AMD Ryzen 9 8945H와 호기심 많은 향 디스펜서를 탑재한 Adol Book 14 Air 공개
Aug 01, 2024 am 11:12 AM
ASUS, AMD Ryzen 9 8945H와 호기심 많은 향 디스펜서를 탑재한 Adol Book 14 Air 공개
Aug 01, 2024 am 11:12 AM
ASUS는 이미 Zenbook 14 OLED(Amazon에서 현재 $1,079.99)를 포함하여 다양한 14인치 노트북을 제공하고 있습니다. 이제 겉보기에는 전형적인 14인치 노트북처럼 보이는 아돌 북 14 에어(Adol Book 14 Air)를 출시하기로 결정했습니다. 그러나 눈에 띄지 않는 메타
 OneXGPU 2의 AMD Radeon RX 7800M은 Nvidia RTX 4070 노트북 GPU보다 성능이 뛰어납니다.
Sep 09, 2024 am 06:35 AM
OneXGPU 2의 AMD Radeon RX 7800M은 Nvidia RTX 4070 노트북 GPU보다 성능이 뛰어납니다.
Sep 09, 2024 am 06:35 AM
OneXGPU 2는 AMD조차 아직 발표하지 않은 GPU인 Radeon RX 7800M을 탑재한 최초의 eGPU입니다. 외장 그래픽 카드 솔루션 제조업체인 One-Netbook에서 밝힌 바와 같이 새로운 AMD GPU는 RDNA 3 아키텍처를 기반으로 하며 Navi
 Ryzen AI 소프트웨어는 새로운 Strix Halo 및 Kraken Point AMD Ryzen 프로세서를 지원합니다.
Aug 01, 2024 am 06:39 AM
Ryzen AI 소프트웨어는 새로운 Strix Halo 및 Kraken Point AMD Ryzen 프로세서를 지원합니다.
Aug 01, 2024 am 06:39 AM
AMD Strix Point 노트북은 이제 막 시장에 출시되었으며, 차세대 Strix Halo 프로세서는 내년쯤 출시될 것으로 예상됩니다. 그러나 회사는 이미 Ryzen AI 소프트웨어에 Strix Halo 및 Krackan Point APU에 대한 지원을 추가했습니다.
 휴대용 콘솔용 AMD Z2 익스트림 칩, 2025년 초 출시 예정
Sep 07, 2024 am 06:38 AM
휴대용 콘솔용 AMD Z2 익스트림 칩, 2025년 초 출시 예정
Sep 07, 2024 am 06:38 AM
AMD가 Ryzen Z1 Extreme(및 익스트림이 아닌 변형)을 휴대용 콘솔용으로 맞춤 제작했음에도 불구하고 이 칩은 Asus ROG Ally(현재 Amazon에서 569달러)와 Lenovo Legion Go(3개)라는 두 개의 주류 휴대용 단말기에서만 발견되었습니다. R을 세면
 AMD는 수백만 개의 Ryzen 및 EPYC 프로세서에 영향을 미치는 심각도가 높은 'Sinkclose' 취약점을 발표했습니다.
Aug 10, 2024 pm 10:31 PM
AMD는 수백만 개의 Ryzen 및 EPYC 프로세서에 영향을 미치는 심각도가 높은 'Sinkclose' 취약점을 발표했습니다.
Aug 10, 2024 pm 10:31 PM
8월 10일 이 사이트의 뉴스에 따르면 AMD는 일부 EPYC 및 Ryzen 프로세서에 전 세계 수백만 명의 AMD 사용자가 관련될 수 있는 코드 "CVE-2023-31315"가 포함된 "Sinkclose"라는 새로운 취약점이 있음을 공식 확인했습니다. 그렇다면 싱크클로즈란 무엇일까요? WIRED의 보고서에 따르면 이 취약점으로 인해 침입자는 "시스템 관리 모드(SMM)"에서 악성 코드를 실행할 수 있습니다. 침입자는 부트킷이라는 일종의 악성코드를 이용해 상대방의 시스템을 제어할 수 있으며, 이 악성코드는 안티바이러스 소프트웨어로 탐지할 수 없는 것으로 알려졌다. 이 사이트의 참고 사항: 시스템 관리 모드(SMM)는 고급 전원 관리 및 운영 체제 독립적 기능을 달성하도록 설계된 특수 CPU 작업 모드입니다.
 Ryzen AI 9 HX 370을 탑재한 최초의 미니포럼 미니 PC, 높은 가격으로 출시 루머
Sep 29, 2024 am 06:05 AM
Ryzen AI 9 HX 370을 탑재한 최초의 미니포럼 미니 PC, 높은 가격으로 출시 루머
Sep 29, 2024 am 06:05 AM
Aoostar는 Strix Point 미니 PC를 최초로 발표한 회사 중 하나였으며 이후 Beelink는 999달러의 치솟는 시작 가격으로 SER9를 출시했습니다. Minisforum은 EliteMini AI370을 예고하며 파티에 합류했으며 이름에서 알 수 있듯이 회사가 될 것입니다.
 Beelink SER9: Radeon 890M iGPU를 탑재한 컴팩트 AMD Zen 5 미니 PC가 발표되었지만 eGPU 옵션이 제한됨
Sep 12, 2024 pm 12:16 PM
Beelink SER9: Radeon 890M iGPU를 탑재한 컴팩트 AMD Zen 5 미니 PC가 발표되었지만 eGPU 옵션이 제한됨
Sep 12, 2024 pm 12:16 PM
Beelink는 계속해서 새로운 미니 PC와 함께 제공되는 액세서리를 엄청난 속도로 소개하고 있습니다. 요약하면 EQi12, EQR6 및 EX eGPU 도크를 출시한 지 한 달이 조금 넘었습니다. 이제 회사는 AMD의 새로운 Strix에 관심을 돌렸습니다.
 거래 | 120Hz OLED, 64GB RAM, AMD Ryzen 7 Pro를 탑재한 Lenovo ThinkPad P14s Gen 5가 지금 60% 할인됩니다.
Sep 07, 2024 am 06:31 AM
거래 | 120Hz OLED, 64GB RAM, AMD Ryzen 7 Pro를 탑재한 Lenovo ThinkPad P14s Gen 5가 지금 60% 할인됩니다.
Sep 07, 2024 am 06:31 AM
요즘 많은 학생들이 학교로 돌아가고 있으며 일부 학생들은 오래된 노트북이 더 이상 작업을 수행할 수 없다는 것을 알게 될 수도 있습니다. 일부 대학생은 화려한 OLED 화면을 갖춘 고급 비즈니스 노트북을 구매할 수도 있습니다.
