

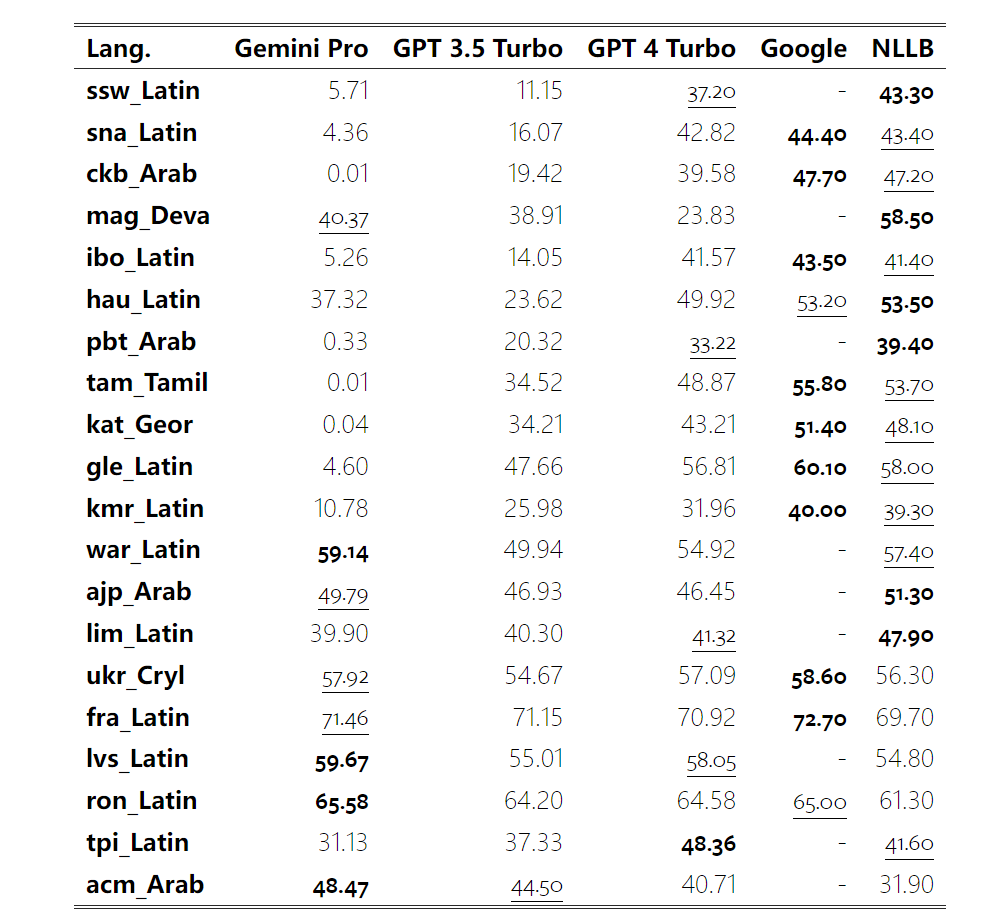
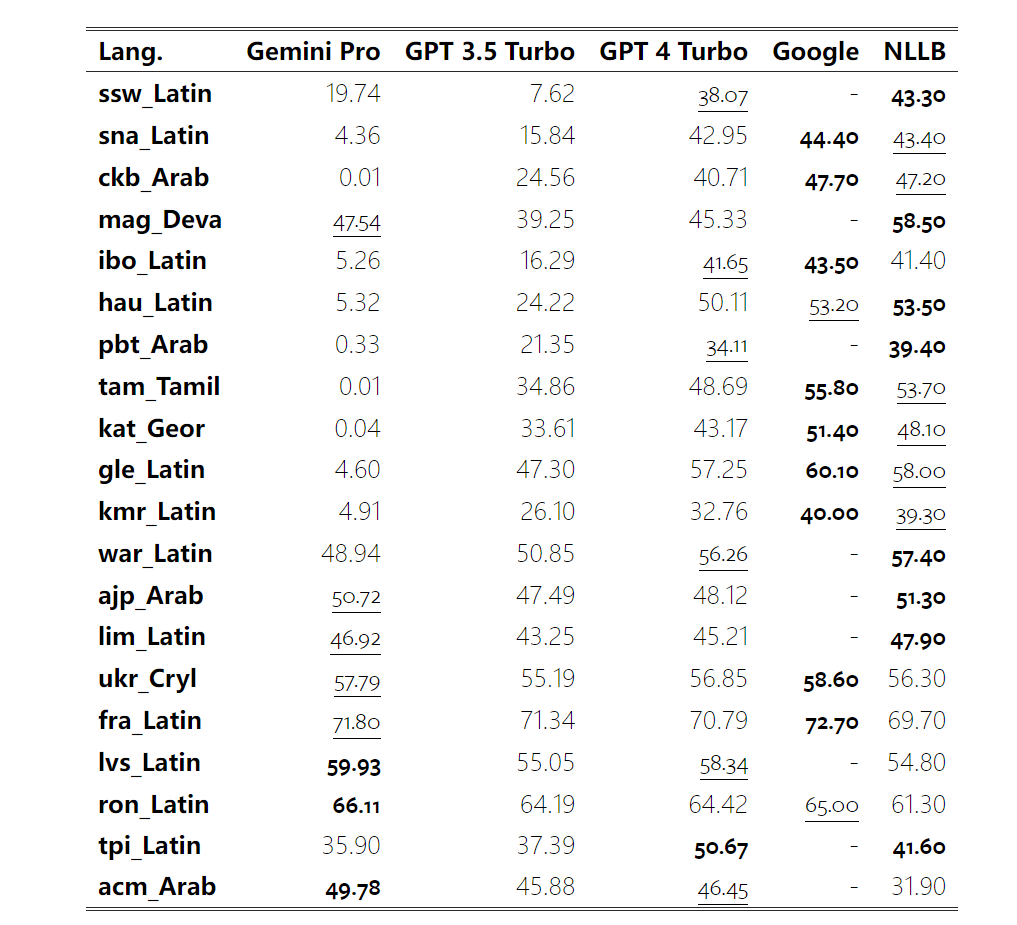
Gemini 전체 검토: CMU에서 GPT 3.5 Turbo까지 Gemini Pro는 패배합니다.

Google Gemini의 무게는 얼마나 되나요? OpenAI의 GPT 모델과 어떻게 비교됩니까? 이 CMU 논문에는 명확한 측정 결과가 있습니다
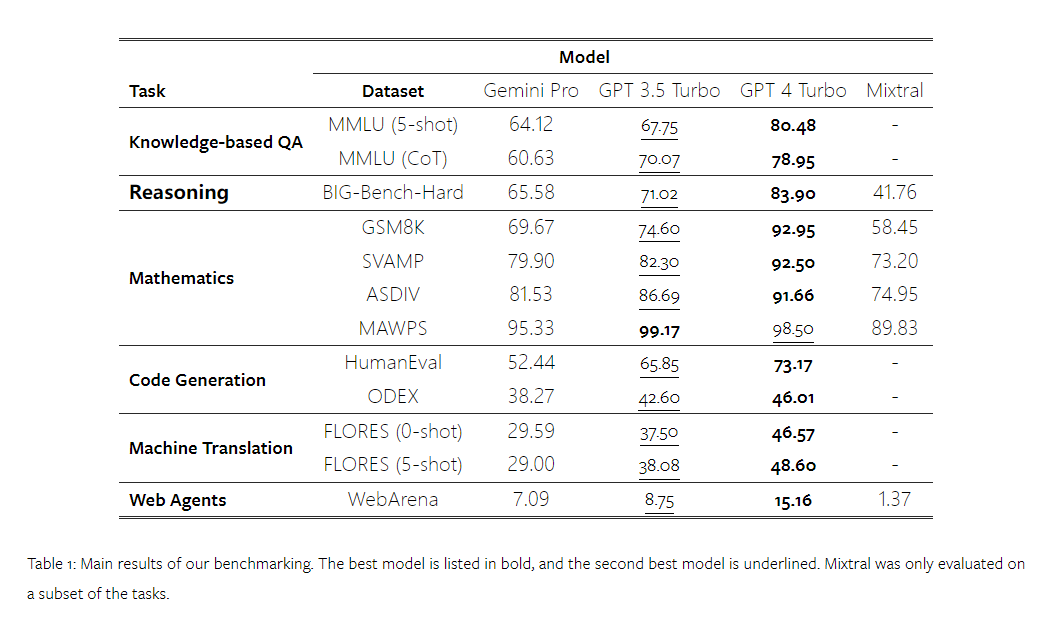

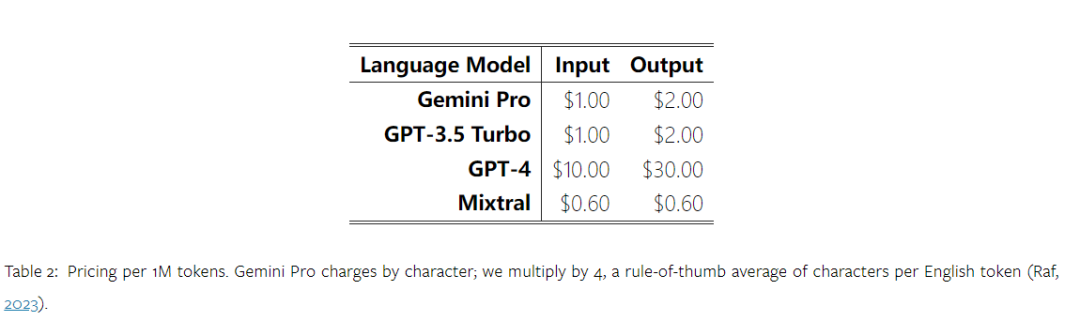
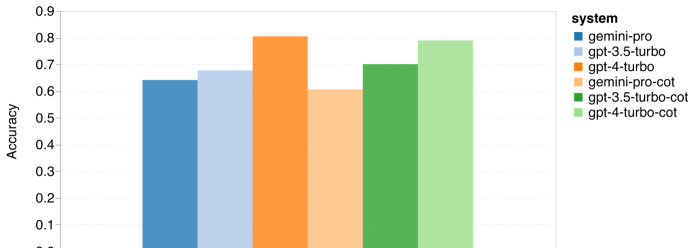
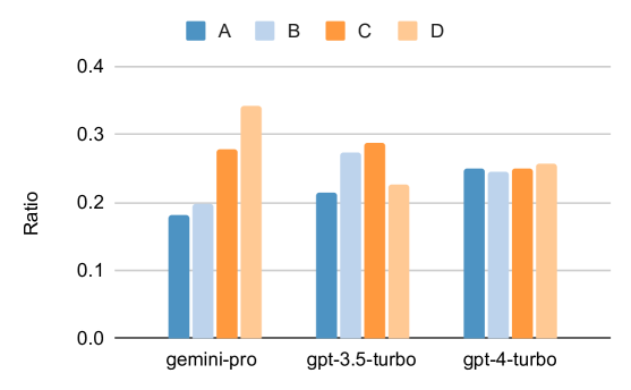
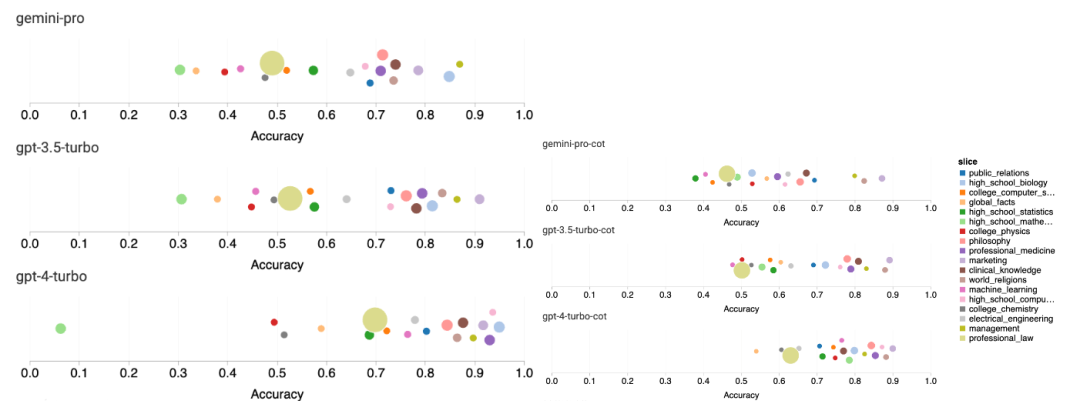
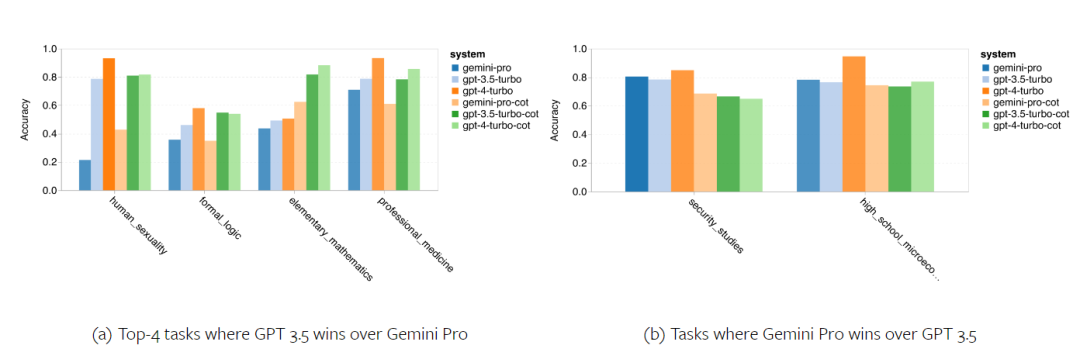
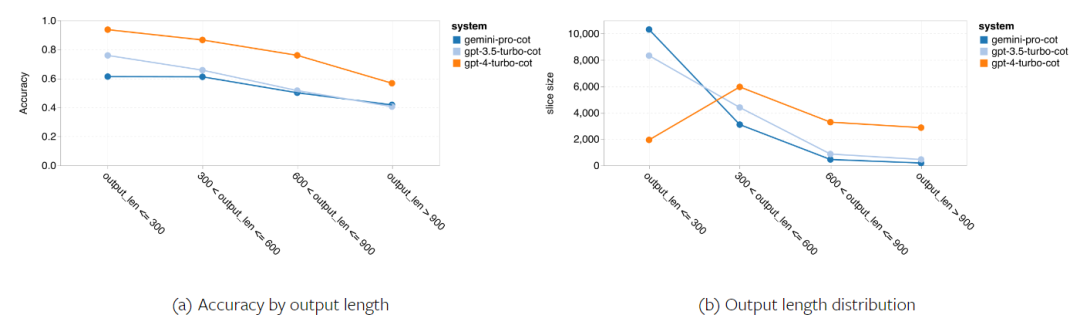
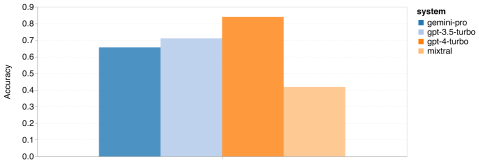
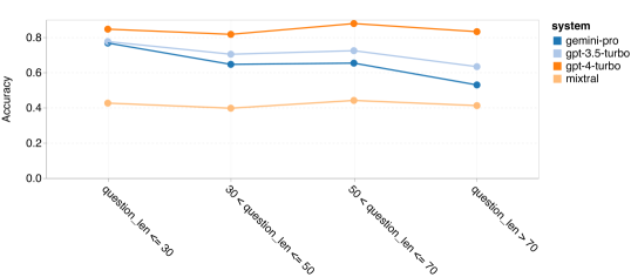
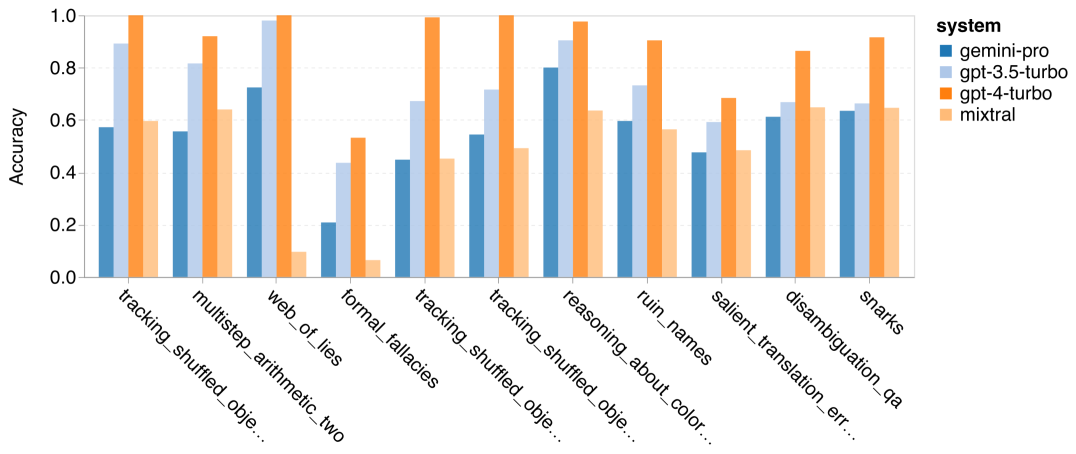
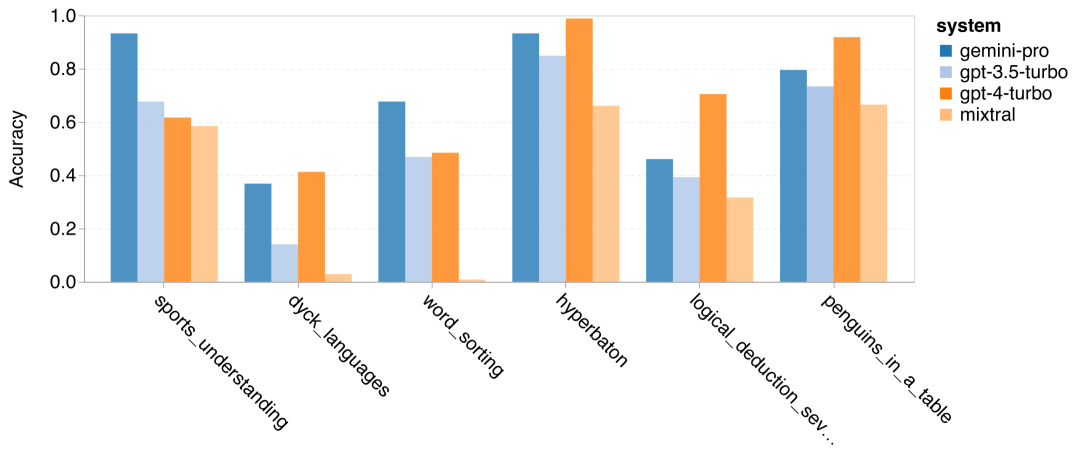
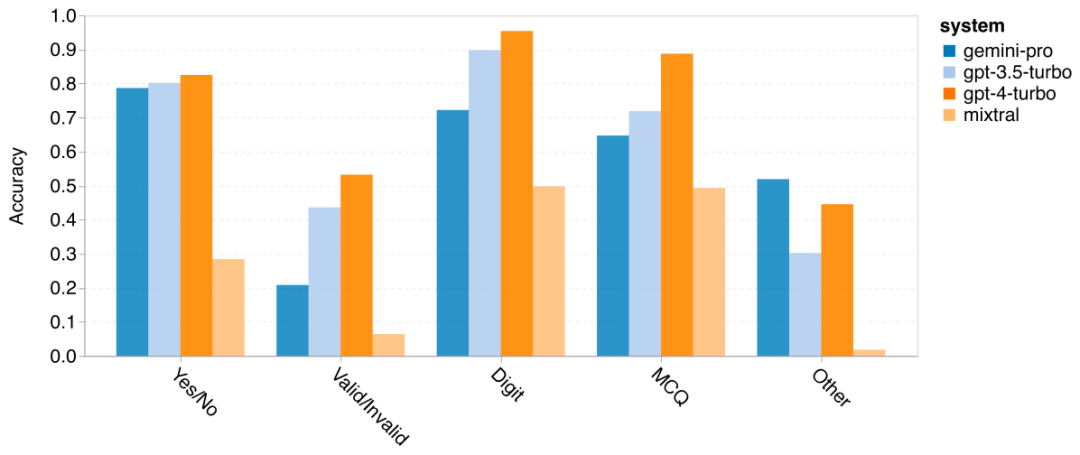
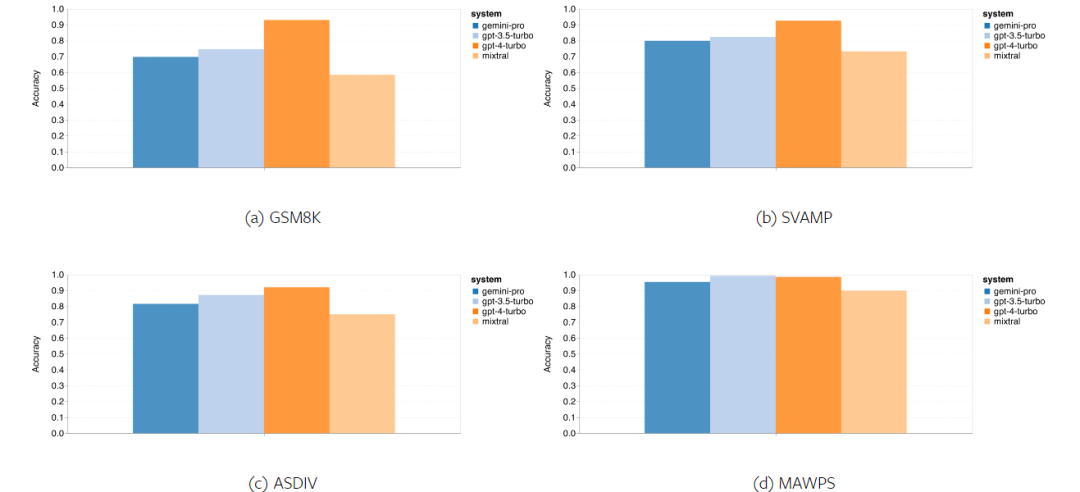
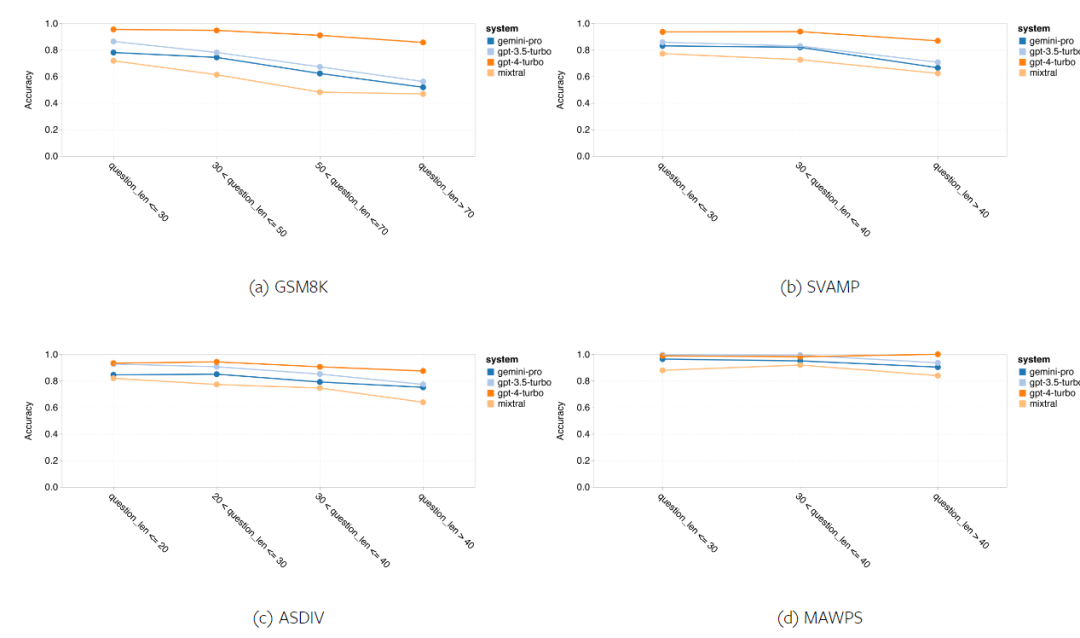
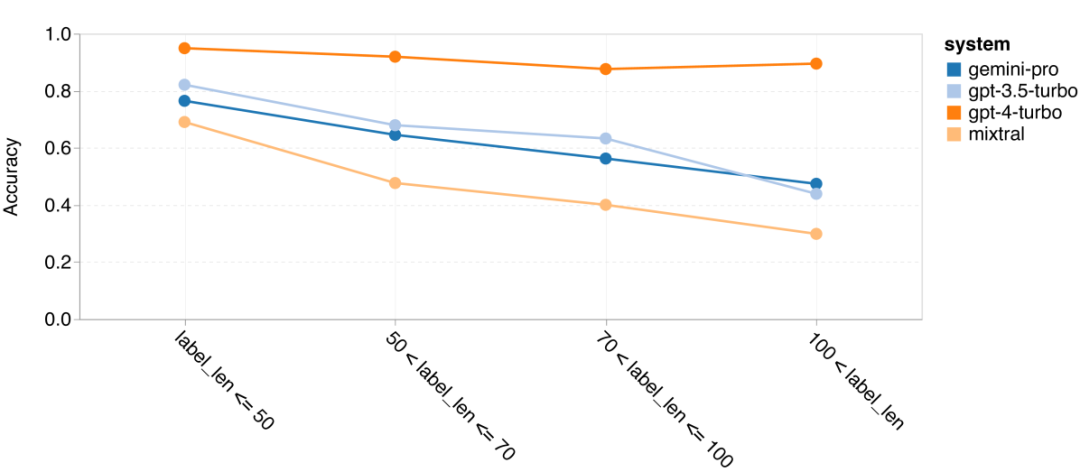
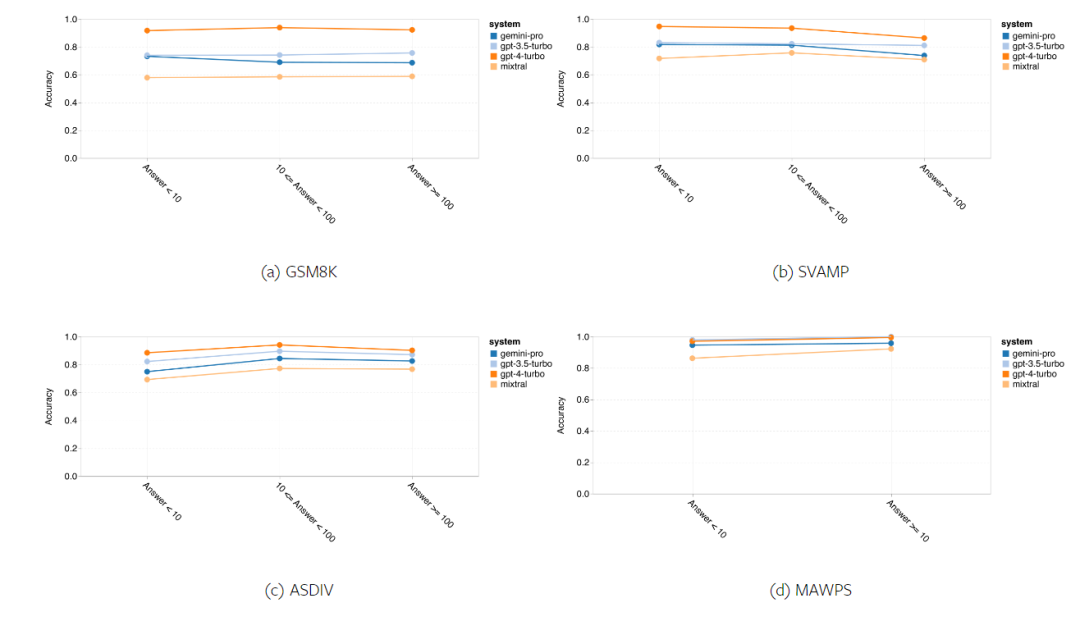
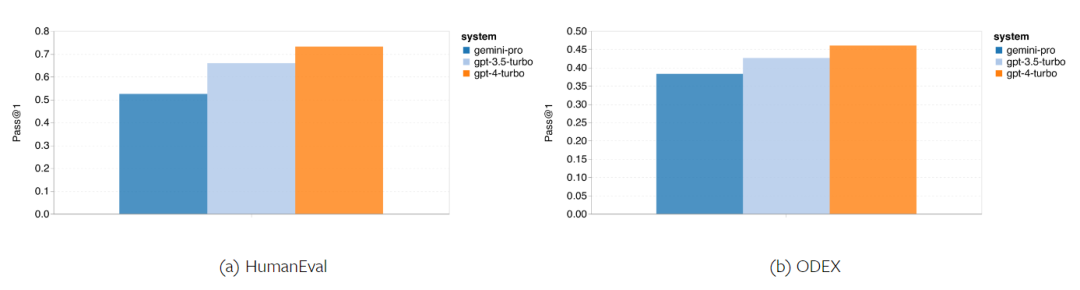
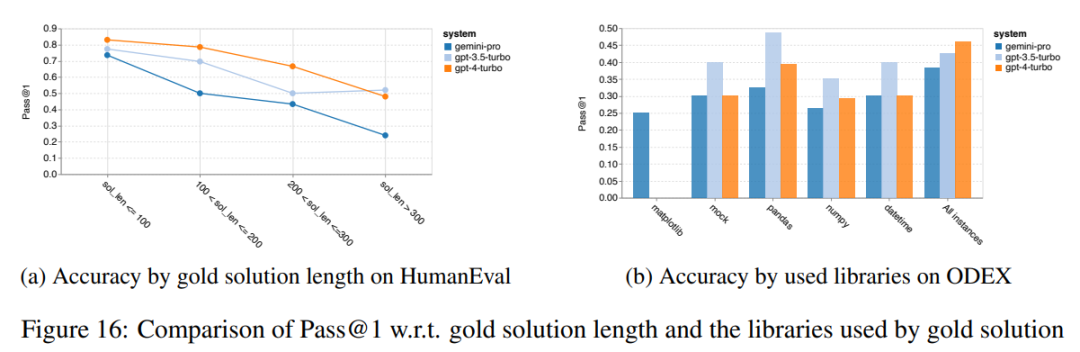
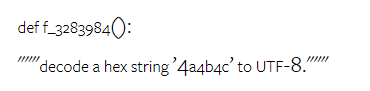


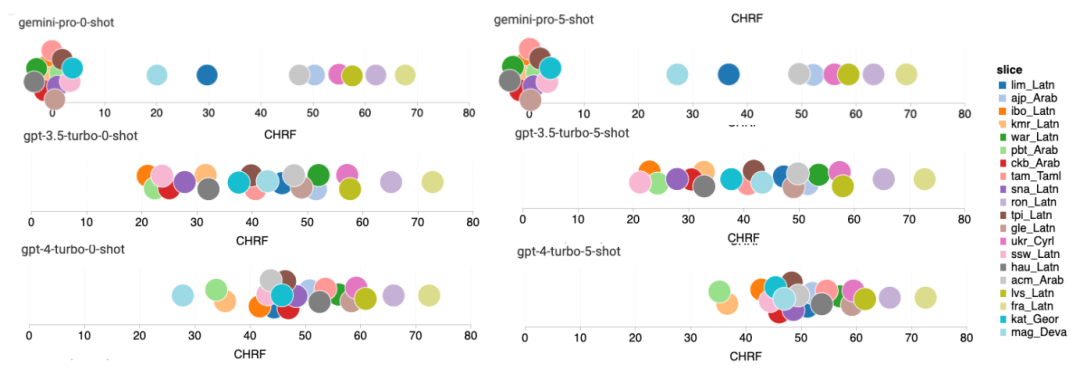
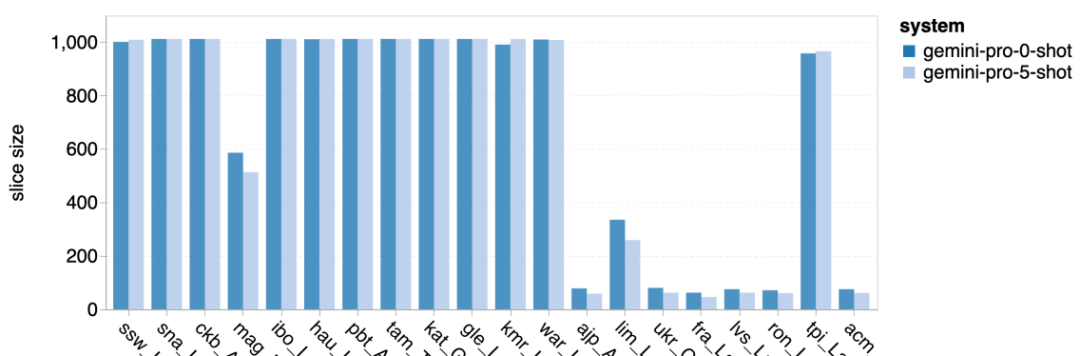
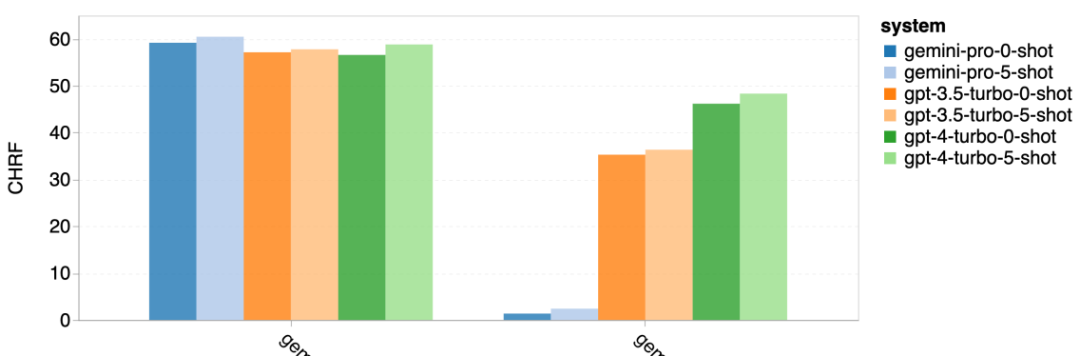
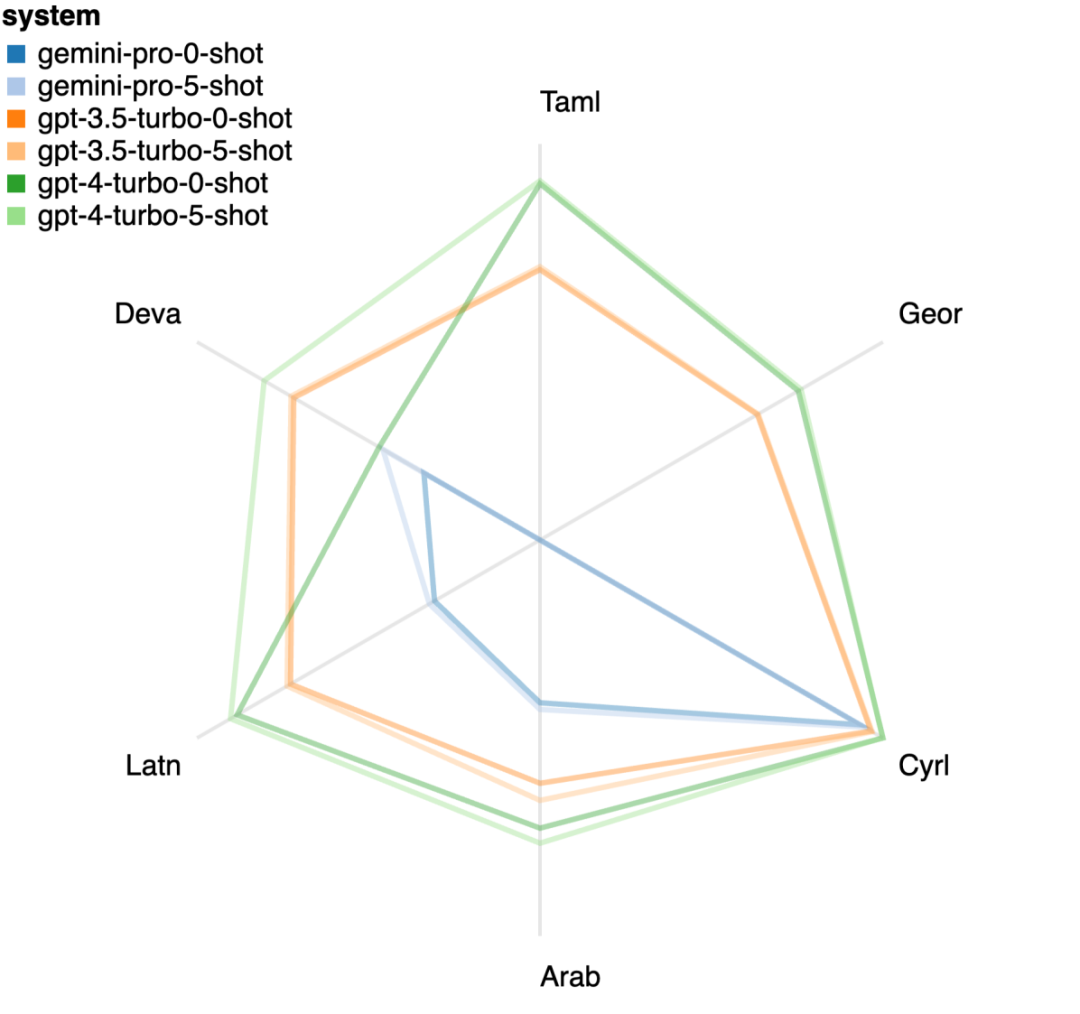
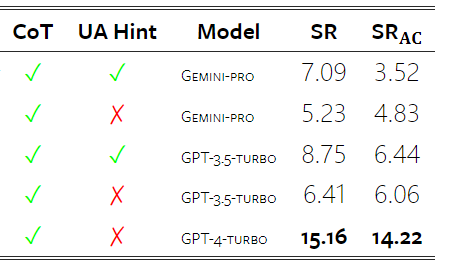
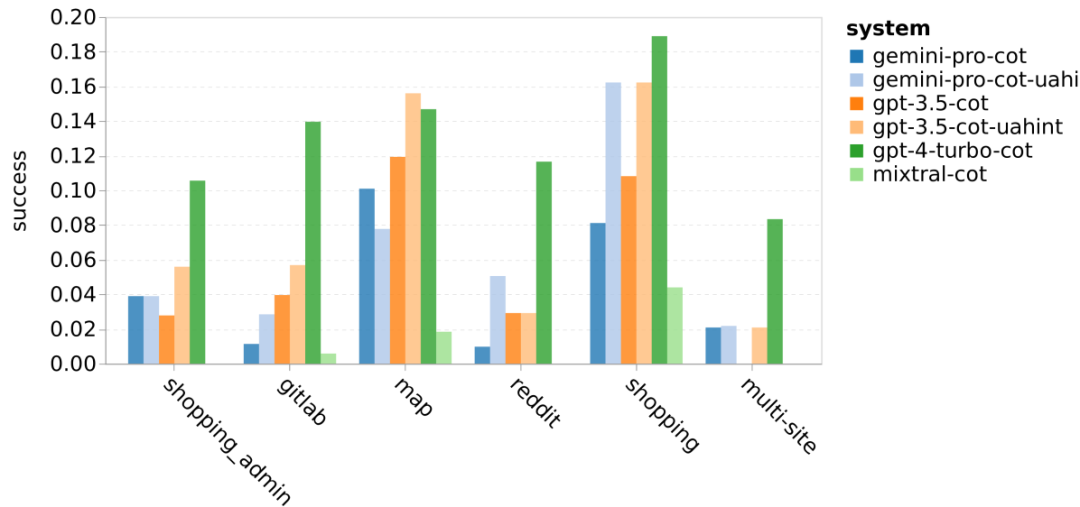
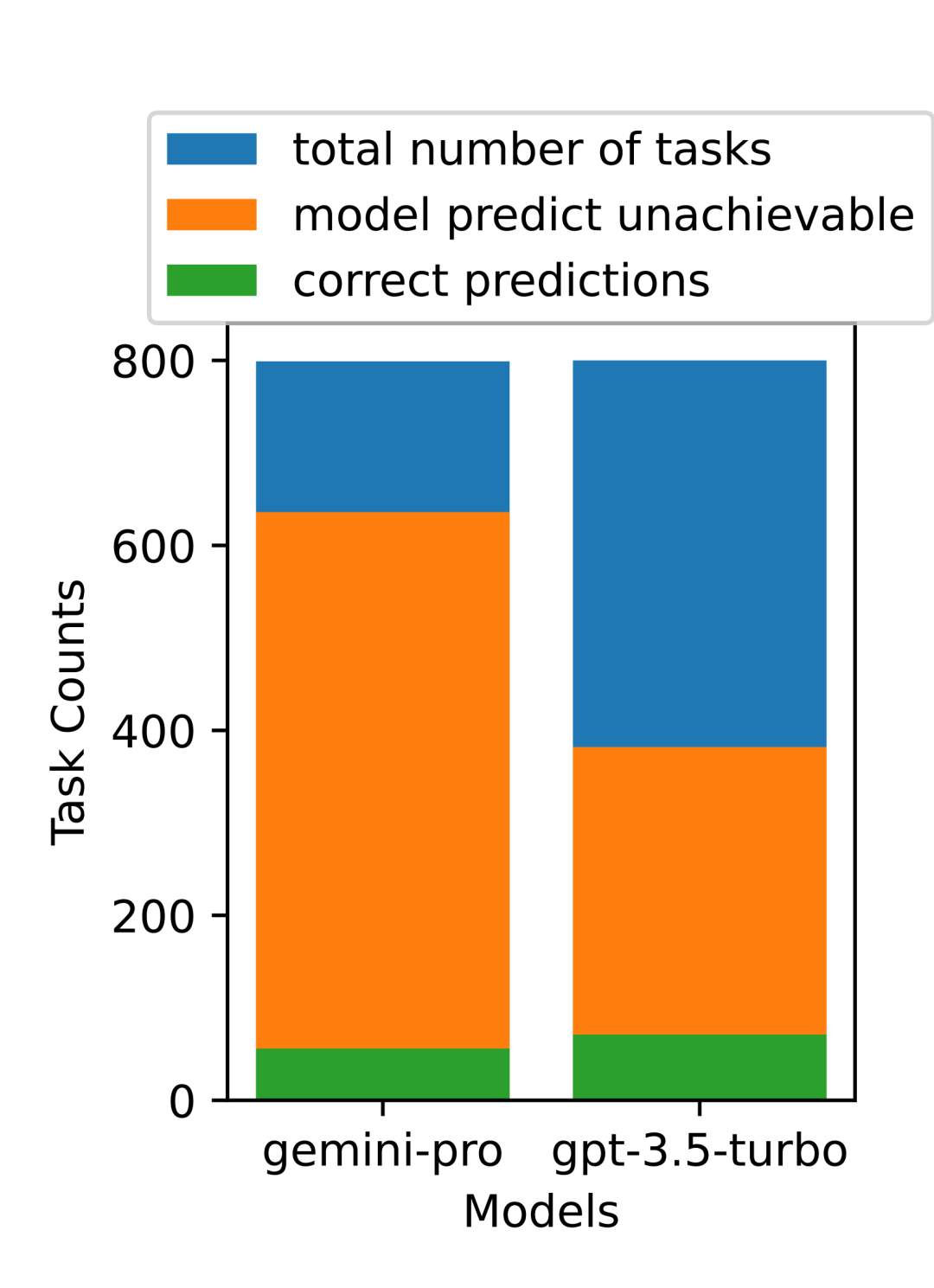
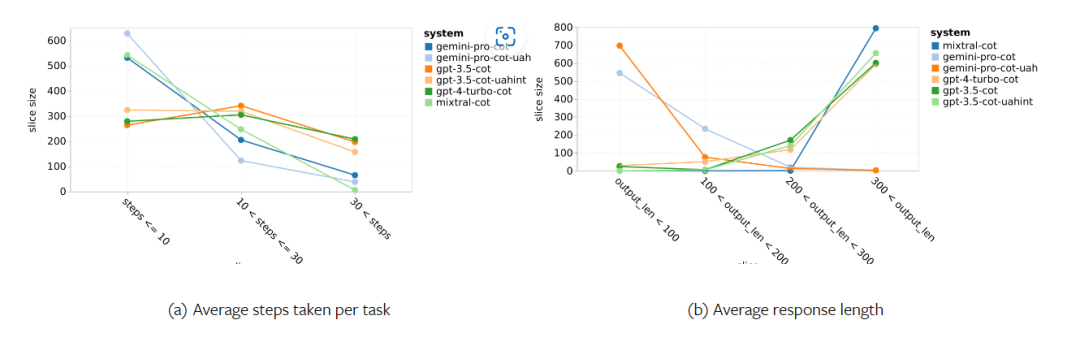
위 내용은 Gemini 전체 검토: CMU에서 GPT 3.5 Turbo까지 Gemini Pro는 패배합니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

Video Face Swap
완전히 무료인 AI 얼굴 교환 도구를 사용하여 모든 비디오의 얼굴을 쉽게 바꾸세요!

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7706
7706
 15
1640
14
1394
52
1288
25
1231
29
15
1640
14
1394
52
1288
25
1231
29

 주요 디지털 통화 거래 플랫폼의 공식 웹 사이트 입력 2025
Mar 31, 2025 pm 05:33 PM
주요 디지털 통화 거래 플랫폼의 공식 웹 사이트 입력 2025
Mar 31, 2025 pm 05:33 PM
이 기사는 Binance, OKX, 참깨 도어 (Gate.io), Coinbase, Kraken, Bitstamp, Gemini, Bittrex, Kucoin 및 Bitfinex를 포함한 10 개의 주류 암호 화폐 거래소를 권장합니다. 이러한 거래소에는 Binance와 같은 고유 한 이점이 있습니다. Binance는 세계에서 가장 큰 거래량과 풍부한 통화 선택으로 유명합니다. OKX는 그리드 거래 및 다양한 파생 상품과 같은 혁신적인 도구를 제공합니다. Coinbase는 미국 규정 준수에 중점을 둡니다. 크라켄은 높은 보안 및 서약 수익으로 사용자를 유치합니다. 다른 거래소에는 화폐 통화 거래, 대체 거래, 고주파 거래 도구 등과 같은 다양한 측면에서 자체 특성이 있습니다. 귀하에게 적합한 거래소를 선택하면 자신의 투자 경험을 사용해야합니다.
 Web3 Transaction은 어떤 플랫폼에서?
Mar 31, 2025 pm 07:54 PM
Web3 Transaction은 어떤 플랫폼에서?
Mar 31, 2025 pm 07:54 PM
이 기사에는 Binance, Okx, Gate.io, Kraken, Bybit, Coinbase, Kucoin, Bitget, Gemini 및 Bitstamp를 포함한 상위 10 개의 잘 알려진 Web3 Trading 플랫폼이 나와 있습니다. 이 기사는 통화 수, 거래 유형 (스팟, 선물, 옵션, NFT 등), 처리 수수료, 보안, 규정 준수, 사용자 그룹 등과 같은 각 플랫폼의 특성을 투자자가 가장 적합한 거래 플랫폼을 선택할 수 있도록 도와줍니다. 고주파 거래자, 계약 거래 애호가 또는 규정 준수 및 보안에 중점을 둔 투자자이든, 참조 정보를 찾을 수 있습니다.
 공식 Web3 Trading Platform App Rankings의 상위 10 개 (2025 년에 출시)
Mar 31, 2025 pm 08:09 PM
공식 Web3 Trading Platform App Rankings의 상위 10 개 (2025 년에 출시)
Mar 31, 2025 pm 08:09 PM
시장 데이터 및 일반적인 평가 기준을 기반 으로이 기사에는 2025 년에 Top 10 공식 Web3 Trading 플랫폼 앱이 나열되어 있습니다.이 목록은 Binance, OKX, Gate.io, Huobi (현재 HTX), Crypto.com, Coinbase, Kraken, Gemini, Bitmex 및 Bybit과 같은 잘 알려진 플랫폼을 포함합니다. 이러한 플랫폼은 사용자 규모, 거래량, 보안, 규정 준수, 제품 혁신 등의 장점이 있습니다. 예를 들어 Binance는 거대한 사용자 기반 및 풍부한 제품 서비스로 유명하며 Coinbase는 보안 및 규정 준수에 중점을 둡니다. 적절한 플랫폼을 선택하려면 자신의 요구와 위험 허용량에 따라 포괄적 인 고려가 필요합니다.
 블록 체인 개인 정보 보호 통화 란 무엇입니까? 거래는 무엇입니까?
Apr 20, 2025 pm 07:09 PM
블록 체인 개인 정보 보호 통화 란 무엇입니까? 거래는 무엇입니까?
Apr 20, 2025 pm 07:09 PM
Blockchain Privacy Coin은 개인 정보 보호 기술을 통해 사용자 거래 개인 정보 보호를 보호합니다. 거래 개인 정보 동전 거래는 다음과 같습니다. 1. Binance, 2. OKX, 3. Gate.io, 4. Huobi, 5. Coinbase, 6. Kraken, 7. Kucoin, 8. Bitfinex, 9. Gemini, 10. Xbit.
 어떤 2025 환전소가 더 안전합니까?
Apr 20, 2025 pm 06:09 PM
어떤 2025 환전소가 더 안전합니까?
Apr 20, 2025 pm 06:09 PM
2025 Cryptocurrency Circle의 상위 10 개 안전하고 신뢰할 수있는 교환에는 다음이 포함됩니다. 1. Binance, 2. Okx, 3. Gate.io (Sesame Open), 4. Coinbase, 5. Kraken, 6. Huobi Global, 7. Gemini, 8. crypto.com, 9. Bitfinex, 10. Kucoin. 이러한 거래소는 규정 준수, 기술 강점 및 사용자 피드백을 기반으로 안전하고 신뢰할 수있는 것으로 평가됩니다.
 가상 통화 거래를위한 법적 플랫폼 앱 순위
Apr 21, 2025 am 09:27 AM
가상 통화 거래를위한 법적 플랫폼 앱 순위
Apr 21, 2025 am 09:27 AM
이 기사는 가상 통화 트랜잭션을위한 법적 플랫폼에 대한 앱 순위를 나열하며, 규정 준수는 플랫폼을 선택하는 데 중요한 고려 사항임을 강조합니다. 이 기사는 Coinbase, Gemini 및 Kraken과 같은 플랫폼을 권장하고 투자자에게 규제 정보를 연구하고 선택할 때 보안 기록에주의를 기울 이도록 상기시킵니다. 동시에이 기사는 가상 통화 거래가 위험이 높고 투자가 신중해야한다고 강조합니다.
 하이브리드 블록 체인 거래 플랫폼은 무엇입니까?
Apr 21, 2025 pm 11:36 PM
하이브리드 블록 체인 거래 플랫폼은 무엇입니까?
Apr 21, 2025 pm 11:36 PM
cryptocurrency 교환 선택에 대한 제안 : 1. 유동성 요구 사항의 경우 우선 순위는 순서 깊이와 강한 변동성 저항으로 인해 Binance, Gate.io 또는 Okx입니다. 2. 규정 준수 및 보안, 코인베이스, 크라켄 및 쌍둥이 자리는 엄격한 규제 승인을 받았습니다. 3. Kucoin의 소프트 스테이 킹 및 Bybit의 파생 설계 혁신적인 기능은 고급 사용자에게 적합합니다.
 세계 10 대 통화 앱 2025
Mar 31, 2025 pm 06:33 PM
세계 10 대 통화 앱 2025
Mar 31, 2025 pm 06:33 PM
2025 년에 가장 좋은 글로벌 가상 통화 거래 앱은 무엇입니까? 이 기사에는 Binance, OKX, Huobi, Gate.io, Coinbase, Kraken, Kucoin, Bitfinex, Gemini 및 Bybit을 포함한 전 세계 10 대의 가상 통화 거래 앱이 나와 있습니다. 이 플랫폼은 거래 쌍 수량, 거래 속도, 보안, 규정 준수, 사용자 경험 등의 관점에서 고유 한 장점이 있습니다. 일부는 초보자에게 적합하지만 다른 일부는 전문 거래자에게 더 인기가 있습니다. 당신이 베테랑 상인이든 cryptocurrency 필드에 새로 온 사람이든,이 기사에서 당신에게 적합한 플랫폼을 찾을 수 있습니다. 이 상위 가상 통화 앱에 대해 배우고 가장 적합한 거래 도구를 선택하십시오!
