

IBD 파일을 사용한 MySQL 데이터 복구 팁?

| 소개 | 디스크 불량 섹터, 정전 및 기타 사고는 일반적이지 않지만 이러한 사고를 겪는 것만으로도 "스릴"이 생길 수 있습니다! 데이터베이스 손상으로 인해 데이터가 손실되어 Binlog를 더 이상 사용할 수 없는 경우 어떻게 해야 합니까? 단시간에 데이터를 무손실로 복원하여 비즈니스 안정성을 확보하기 위해 binlog를 활용하는 것 외에도 새로운 복구 기술도 연습했습니다! |
전에 우리가 쓴 "통제 불가능한 R&D가 당신을 사랑하게 만드는 단 하나의 비법"을 기억하시나요? 앞서 언급했듯이 우리가 매일 가장 많이 사용하는 두 가지 데이터베이스 복구 방법은 다음과 같습니다.
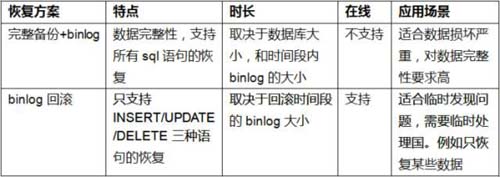
위 두 가지 방법 모두 실시간 롤백이 가능하지만, 이 두 가지 기술만 있으면 충분하다고 생각하시나요?
안돼….!
이 복잡한 온라인 아키텍처에는 실제로 우리가 예측할 수 없는 알 수 없는 많은 이유가 있습니다. 예:
열심히 작업하여 수명을 잃은 디스크는 배드섹터가 발생하여 데이터베이스가 손상될 수 있습니다. 그리고 ibdata 파일과 binlog 파일이 손상되는 일이 일어났습니다. 그렇다면 아직도 예약 백업 + binlog 복구 솔루션을 생각한다면 고정 소수점 백업만 사용하여 복원할 수는 없나요? 운영 및 유지 관리 담당자로서 신중하게 고려한 후에는 비즈니스에 큰 영향을 미치기 때문에 최후의 수단으로 손실 롤백을 구현하지 않을 것입니다. 하지만 또 무엇을 할 수 있습니까? 다음으로 우리는 큰 움직임을 공개할 예정입니다! ! !
먼저 데이터베이스 환경을 확인하여 독립 테이블스페이스가 활성화되어 있는지 확인하세요. 활성화된 경우 축하합니다. 모든 데이터를 복구할 수 있는 가능성이 높습니다. 데이터 복구를 위해 각 데이터베이스 디렉토리의 frm 및 ibd 파일을 사용할 수 있습니다. 일반적으로 InnoDB를 사용하지만 독립 테이블 공간이 활성화되지 않은 경우 모든 데이터베이스 테이블 정보와 메타데이터가 ibdata 파일에 기록됩니다. 오랫동안 실행하면 ibdata 파일이 점점 커지고 데이터베이스 성능이 저하됩니다. InnoDB는 데이터를 독립적으로 저장할 수 있는 독립 테이블스페이스를 활성화하는 매개 변수를 제공합니다. 이러한 방식으로 ibdata 파일은 일부 엔진 관련 인덱스 정보를 저장하는 데만 사용되며 실제 데이터는 독립된 frm 및 ibd 파일에 기록됩니다.
좋아요, frm 및 ibd 파일을 사용하여 데이터 복구를 시도해 볼 수 있습니다. 이 과정은 binlog 복원보다 더 스릴 있고 흥미로워요! 먼저 ibd 및 frm에 대한 지침을 살펴보겠습니다.
.frm 파일: 테이블 구조 정의 등 각 테이블의 메타데이터를 저장합니다. 이 파일은 데이터베이스 엔진과 아무런 관련이 없습니다.
.ibd 파일: 테이블의 데이터와 인덱스를 저장하기 위해 독립 테이블스페이스가 활성화될 때(innodb_file_per_table = 1 in my.ini) InnoDB 엔진에서 생성되는 파일입니다.
InnoDB 데이터베이스의 경우 전체 데이터 디렉터리를 복사하지 않고 지정된 데이터베이스 디렉터리만 새 인스턴스에 복사하면 데이터베이스가 인식되지 않는다는 것은 모두가 알고 있는 사실입니다. 그렇다면 이 두 파일을 기반으로 데이터베이스를 복원하는 방법은 무엇입니까?
복구 아이디어:엔진에 대한 일부 인덱스 정보가 ibdata 파일에 저장되어 있기 때문에 ibdata 파일이 손상되어 테이블 이름 인덱스가 손실되어 시작할 수 없게 됩니다. 그런 다음 먼저 전체 이전 데이터 디렉터리의 이름을 바꾸고 백업한 다음 데이터베이스를 다시 초기화하여 새 ibdata 파일을 생성한 다음 원본 데이터베이스와 해당 테이블을 다시 생성하고 마지막으로 백업 테이블스페이스 ID 번호를 다음으로 변경할 수 있습니다. 새 테이블스페이스 ID 번호(ibdata 파일에는 생성된 새 테이블 수만큼 증가되는 각 테이블에 대한 고유한 테이블스페이스 인덱스 ID가 포함되어 있음)를 사용하여 원래 데이터베이스를 복원할 수 있습니다.
예:
라이브러리 이름: test_restore
테이블 구조: db_struc.sql
테이블 파일: G_RESTORE.ibd, G_RESTORE.frm
#mysql -uroot –p**** -e “데이터베이스 test_restore 생성”
#mysql -uroot –p**** test_restore 2. 새 인스턴스의 test_restore 라이브러리에 있는 테이블 ID를 보고 수정합니다 으아아아
깨진 문자로 직접 열어서 16진수로 변환하여 볼 수 있습니다. Vi에서 :%!xxd를 실행하여 16진수로 변환합니다. 결과는 :
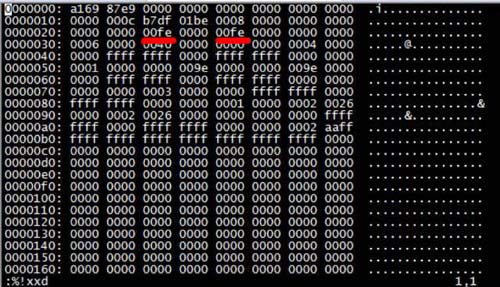
사진과 같습니다. mysql 데이터베이스의 G_RESTORE 테이블 ID는 00fe입니다.
백업된 G_RESTORE.ibd 파일을 수정하세요. 조작은 위와 동일하지만, 먼저 백업을 해야 한다는 점에 유의하세요.
으아아아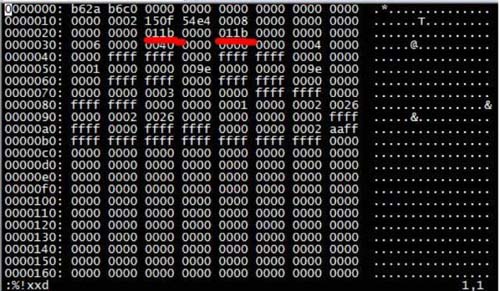
011b를 00fe로 변경하세요. 알아채다. 수정이 완료되면 먼저 vim에서 실행해야 합니다: %!xxd -r
Wq를 다시 눌러 파일을 저장하고 종료하세요. 그렇지 않으면 저장된 결과는 16진수 보기입니다.
다음과 같이 결과를 저장하세요.
수정된 G_RESTORE.ibd 파일을 새 데이터베이스의 G_RESTORE.ibd 파일로 바꾸세요.
ibdata 테이블 ID에 대한 설명:

参考官方文档解释,每个表空间分配了4个字节存储了表空间id信息,最后偏移量地址为38。还有一组预留的表空间id,同样是4个字节,最后偏移量地址为42。
3. 验证并还原mysql数据关闭mysql。修改my.conf。
innodb_force_recovery=6 innodb_purge_threads=0
启动数据库。如果不修改。数据库会认为G_RESTORE已被损坏。
Select 一下,即可查看到还原结果,但此时插入数据会报错,应尽快将数据dump出来 ,导回原来的实例中。
导出数据,再导入数据,恢复完毕!
#mysqldump -uroot –p****** test_restore > test_restore.sql
#mysql -uroot –p****** test_restore
<p>说明:变更了新的space id后的.ibd表文件,启动数据库后只能认出数据,但不能写入,这是因为原ibdata文件不仅保存了space id索引,还同时保存了一些其它的元数据。为了使元数据补全,所以采取导出、再导入的操作。</p>
<p>以上举例为单个库表的恢复过程,看到这里大家一定会产生另一个疑问吧?线上的场景不可能是只有一个表的,数据库表很多的情况下,这样一个个表的修改,速度无疑是太慢了。那么存在大量表的情况下如何恢复呢?思路是,取得备份的ibd文件的id值,按id值顺序来建表,中间跨度随便建表语句来凑够数(每个表空间索引id由创建新表的数量依次递增)。实现方式如下:</p>
<p><span style="color: #339966;"><strong>1. 获取备份数据库ibd文件的space id号,并排序。</strong></span></p>
<pre class="brush:php;toolbar:false">for ibd in `find test_restore/ -name “*.ibd”` ; do echo -e “${ibd///// } /c” ;hexdump -C ${ibd} |head -n 3 |tail -n 1|awk ‘{print strtonum(“0x”$6$7)}’ ;done | sort -n -k 3 | column -t > /tmp/生成的ibd.txt文件,格式如下:(库名–表名–SpaceId)
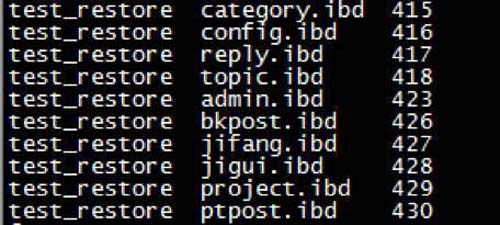
2. 新建表,查看当前表空间id(假设space id为10)
#mysql -uroot –p****** -e”create table test.tt(a bool)”
#hexdump -C mysql/test/tt.ibd |head -n 3 |tail -n 1|awk ‘{print strtonum(“0x”$6$7)}’3. 先创建所有库,准备所有表结构,写脚本,依据space id号自动创建新表
准备好数据库表结构,可以从备份文件里取出来(我们备份方式是把结构和数据分开备份的),或者从其他有相同表结构的服务器上备份再拷贝过来。
参考备份语句:
mysqldump -uroot –p****** -d ${db} –T /data/backup/${db}/创建原有的数据库:
mysql -uroot –p****** -e “create database ${db}”恢复表id创建表脚本:
#!/bin/bash
#因为前面假设为10,所以从11开始创建
oid=11
#打开前面生成的ibd.txt文件,按行读取”库名–表名–SpaceId”
cat /tmp/ibd.txt | while read db tb id ;do
#假如我们需要恢复catetory表,他的id为415,基于id是创表自增的原则,即415-11=404,
#我们还需要循环创建404个表后,才真正导入catetory表结构。
for ((oid;oid<id do mysql table test.t bool echo ok done let oid="oid+1">
<p><span style="color: #339966;"><strong>4. 检查表空间id 和备份的是否一致</strong></span></p>
<pre class="brush:php;toolbar:false">for ibd in `find test_restore/ -name “*.ibd”` ; do echo -e “${ibd///// } /c” ;hexdump -C ${ibd} |head -n 3 |tail -n 1|awk ‘{print strtonum(“0x”$6$7)}’ ;done | sort -n -k 3 | column -t > /tmp/ibd2.txt确认一致后,拷贝备份的.ibd文件到新数据库实例目录下,修改my.cnf
innodb_force_recovery=6
innodb_purge_threads=0
启动数据库。后续步骤如同单表恢复,直接导出恢复到原来实例中即可。
当然,这种方式是在数据库出现极端情况下,不得不采取的一种方式,线上最重要的还是做好主从同步和定时备份,从而规避此类风险。
关于InnoDB引擎独立表空间说明:使用过MySQL的同学,刚开始接触最多的莫过于MyISAM表引擎了,这种引擎的数据库会分别创建三个文件:表结构、表索引、表数据空间。我们可以将某个数据库目录直接迁移到其他数据库也可以正常工作。然而当你使用InnoDB的时候,一切都变了。
InnoDB默认会将所有的数据库InnoDB引擎的表数据存储在一个共享空间中:ibdata1,这样就感觉不爽,增删数据库的时候,ibdata1文件不会自动收缩,单个数据库的备份也将成为问题。通常只能将数据使用mysqldump导出,然后再导入解决这个问题。
但是可以通过修改MySQL配置文件[mysqld]部分中innodb_file_per_table的参数来开启独立表空间模式,每个数据库的每个表都会生成一个数据空间。
优点:1.每个表都有自已独立的表空间。
2.每个表的数据和索引都会存在自已的表空间中。
3.可以实现单表在不同的数据库中移动。
4.空间可以回收(除drop table操作处,表空不能自已回收)
a) Drop table操作自动回收表空间,如果对于统计分析或是日值表,删除大量数据后可以通过:alter table TableName engine=innodb;回缩不用的空间。
b) 对于使innodb-plugin的Innodb使用turncate table也会使空间收缩。
c) 对于使用独立表空间的表,不管怎么删除,表空间的碎片不会太严重的影响性能,而且还有机会处理。
단점:싱글 테이블이 100G가 넘는 등 너무 큽니다.
결론:공유 테이블 공간은 삽입 작업에서 장점이 거의 없습니다. 다른 테이블스페이스는 독립 테이블스페이스만큼 성능이 좋지 않습니다. 독립 테이블스페이스를 활성화하는 경우 적절하게 조정하십시오: innodb_open_files.
구성 방법:
1.innodb_file_per_table 설정 방법:
my.cnf
의 [mysqld] 아래에 설정하세요.innodb_file_per_table=1
2. 활성화되어 있는지 확인하세요:
mysql> '%per_table%'와 같은 변수 표시;
3. 전용 테이블 공간을 닫습니다
innodb_file_per_table=0은 독립 테이블 공간을 끕니다
mysql> '%per_table%'와 같은 변수 표시;
위 내용은 IBD 파일을 사용한 MySQL 데이터 복구 팁?의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7549
7549
 15
1382
52
83
11
58
19
22
90
15
1382
52
83
11
58
19
22
90

 Centos와 Ubuntu의 차이
Apr 14, 2025 pm 09:09 PM
Centos와 Ubuntu의 차이
Apr 14, 2025 pm 09:09 PM
Centos와 Ubuntu의 주요 차이점은 다음과 같습니다. Origin (Centos는 Red Hat, Enterprise의 경우, Ubuntu는 Debian에서 시작하여 개인의 경우), 패키지 관리 (Centos는 안정성에 중점을 둡니다. Ubuntu는 APT를 사용하여 APT를 사용합니다), 지원주기 (Ubuntu는 5 년 동안 LTS 지원을 제공합니다), 커뮤니티에 중점을 둔다 (Centos Conciors on ubuntu). 튜토리얼 및 문서), 사용 (Centos는 서버에 편향되어 있으며 Ubuntu는 서버 및 데스크탑에 적합), 다른 차이점에는 설치 단순성 (Centos는 얇음)이 포함됩니다.
 Centos를 설치하는 방법
Apr 14, 2025 pm 09:03 PM
Centos를 설치하는 방법
Apr 14, 2025 pm 09:03 PM
CentOS 설치 단계 : ISO 이미지를 다운로드하고 부팅 가능한 미디어를 실행하십시오. 부팅하고 설치 소스를 선택하십시오. 언어 및 키보드 레이아웃을 선택하십시오. 네트워크 구성; 하드 디스크를 분할; 시스템 시계를 설정하십시오. 루트 사용자를 만듭니다. 소프트웨어 패키지를 선택하십시오. 설치를 시작하십시오. 설치가 완료된 후 하드 디스크에서 다시 시작하고 부팅하십시오.
 유지 보수를 중단 한 후 Centos의 선택
Apr 14, 2025 pm 08:51 PM
유지 보수를 중단 한 후 Centos의 선택
Apr 14, 2025 pm 08:51 PM
Centos는 중단되었으며 대안은 다음과 같습니다. 1. Rocky Linux (Best Compatibility); 2. Almalinux (Centos와 호환); 3. Ubuntu 서버 (구성 필수); 4. Red Hat Enterprise Linux (상업용 버전, 유료 라이센스); 5. Oracle Linux (Centos 및 Rhel과 호환). 마이그레이션시 고려 사항은 호환성, 가용성, 지원, 비용 및 커뮤니티 지원입니다.
 Docker Desktop을 사용하는 방법
Apr 15, 2025 am 11:45 AM
Docker Desktop을 사용하는 방법
Apr 15, 2025 am 11:45 AM
Docker Desktop을 사용하는 방법? Docker Desktop은 로컬 머신에서 Docker 컨테이너를 실행하는 도구입니다. 사용 단계는 다음과 같습니다. 1. Docker Desktop 설치; 2. Docker Desktop을 시작하십시오. 3. Docker 이미지를 만듭니다 (Dockerfile 사용); 4. Docker Image 빌드 (Docker 빌드 사용); 5. 도커 컨테이너를 실행하십시오 (Docker Run 사용).
 Docker 원리에 대한 자세한 설명
Apr 14, 2025 pm 11:57 PM
Docker 원리에 대한 자세한 설명
Apr 14, 2025 pm 11:57 PM
Docker는 Linux 커널 기능을 사용하여 효율적이고 고립 된 응용 프로그램 실행 환경을 제공합니다. 작동 원리는 다음과 같습니다. 1. 거울은 읽기 전용 템플릿으로 사용되며, 여기에는 응용 프로그램을 실행하는 데 필요한 모든 것을 포함합니다. 2. Union 파일 시스템 (Unionfs)은 여러 파일 시스템을 스택하고 차이점 만 저장하고 공간을 절약하고 속도를 높입니다. 3. 데몬은 거울과 컨테이너를 관리하고 클라이언트는 상호 작용을 위해 사용합니다. 4. 네임 스페이스 및 CGroup은 컨테이너 격리 및 자원 제한을 구현합니다. 5. 다중 네트워크 모드는 컨테이너 상호 연결을 지원합니다. 이러한 핵심 개념을 이해 함으로써만 Docker를 더 잘 활용할 수 있습니다.
 Centos 후해야 할 일은 유지 보수를 중단합니다
Apr 14, 2025 pm 08:48 PM
Centos 후해야 할 일은 유지 보수를 중단합니다
Apr 14, 2025 pm 08:48 PM
Centos가 중단 된 후 사용자는 다음과 같은 조치를 취할 수 있습니다. Almalinux, Rocky Linux 및 Centos 스트림과 같은 호환되는 분포를 선택하십시오. Red Hat Enterprise Linux, Oracle Linux와 같은 상업 분포로 마이그레이션합니다. Centos 9 Stream : 롤링 분포로 업그레이드하여 최신 기술을 제공합니다. Ubuntu, Debian과 같은 다른 Linux 배포판을 선택하십시오. 컨테이너, 가상 머신 또는 클라우드 플랫폼과 같은 다른 옵션을 평가하십시오.
 VSCODE에 필요한 컴퓨터 구성
Apr 15, 2025 pm 09:48 PM
VSCODE에 필요한 컴퓨터 구성
Apr 15, 2025 pm 09:48 PM
대 코드 시스템 요구 사항 : 운영 체제 : Windows 10 이상, MacOS 10.12 이상, Linux 배포 프로세서 : 최소 1.6GHz, 권장 2.0GHz 이상의 메모리 : 최소 512MB, 권장 4GB 이상의 저장 공간 : 최소 250MB, 권장 1GB 및 기타 요구 사항 : 안정 네트워크 연결, Xorg/Wayland (LINUX)
 Docker 이미지가 실패하면해야 할 일
Apr 15, 2025 am 11:21 AM
Docker 이미지가 실패하면해야 할 일
Apr 15, 2025 am 11:21 AM
실패한 Docker 이미지 빌드에 대한 문제 해결 단계 : Dockerfile 구문 및 종속성 버전을 확인하십시오. 빌드 컨텍스트에 필요한 소스 코드 및 종속성이 포함되어 있는지 확인하십시오. 오류 세부 사항에 대한 빌드 로그를보십시오. -표적 옵션을 사용하여 계층 적 단계를 구축하여 실패 지점을 식별하십시오. 최신 버전의 Docker Engine을 사용하십시오. -t [image-name] : 디버그 모드로 이미지를 빌드하여 문제를 디버깅하십시오. 디스크 공간을 확인하고 충분한 지 확인하십시오. 빌드 프로세스에 대한 간섭을 방지하기 위해 Selinux를 비활성화하십시오. 커뮤니티 플랫폼에 도움을 요청하고 Dockerfiles를 제공하며보다 구체적인 제안을 위해 로그 설명을 구축하십시오.
