

Java 스레드 풀 작동 방식

| 소개 | 우리 개발에서는 "풀"이라는 개념이 흔합니다. 데이터베이스 연결 풀, 스레드 풀, 개체 풀, 상수 풀 등이 있습니다. 아래에서는 스레드 풀의 베일을 단계별로 밝히기 위해 주로 스레드 풀에 중점을 둡니다. |
1. 자원 소비를 줄입니다
생성된 스레드를 재사용하여 스레드 생성 및 소멸로 인한 소비를 줄일 수 있습니다.
2. 응답 속도 향상
작업이 도착하면 스레드가 생성될 때까지 기다리지 않고 즉시 작업을 실행할 수 있습니다.
3. 스레드 관리 효율성 향상
스레드는 희소한 리소스이므로 제한 없이 생성하면 시스템 리소스를 소모할 뿐만 아니라 시스템의 안정성도 저하됩니다. 스레드 풀을 사용하여 통합 할당, 튜닝 및 모니터링을 해보세요.
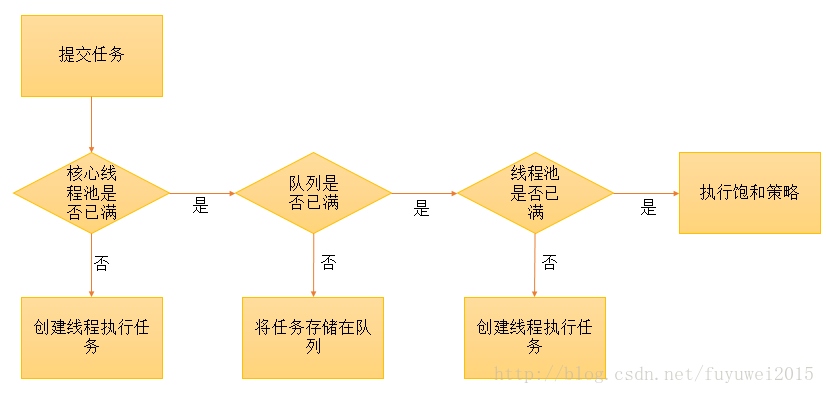
스레드 풀 작동 방식 먼저 스레드 풀에 제출된 새 작업을 스레드 풀이 어떻게 처리하는지 살펴보겠습니다1. 스레드 풀은 코어 스레드 풀의 모든 스레드가 작업을 실행하는지 여부를 결정합니다. 그렇지 않은 경우 작업을 수행하기 위해 새 작업자 스레드가 생성됩니다. 코어 스레드 풀의 모든 스레드가 작업을 실행 중인 경우 두 번째 단계를 수행합니다.
2. 스레드 풀은 작업 대기열이 가득 찼는지 여부를 결정합니다. 작업 대기열이 가득 차지 않으면 새로 제출된 작업이 이 작업 대기열에 저장되고 대기됩니다. 작업 대기열이 가득 찬 경우 3단계로 진행하세요
3. 스레드 풀은 스레드 풀의 모든 스레드가 작동 상태인지 확인합니다. 그렇지 않은 경우 작업을 수행하기 위해 새 작업자 스레드가 생성됩니다. 가득 차면 포화 전략에 넘겨 이 작업을 처리하세요
스레드 풀 포화 전략 여기서는 스레드 풀의 포화 전략이 언급되어 있으므로 포화 전략을 간략하게 소개하겠습니다.
AbortPolicy
Java 스레드 풀의 기본 차단 전략입니다. 이 작업을 수행하지 않고 런타임 예외를 직접 발생시킵니다. ThreadPoolExecutor.execute에는 try catch가 필요합니다. 그렇지 않으면 프로그램이 직접 종료됩니다.
DiscardPolicy
직접 포기하면 태스크가 실행되지 않고 메소드가 비어있습니다
가장 오래된 정책 버리기
큐에서 선두의 작업을 취소하고 이 작업을 다시 실행하세요.
CallerRunsPolicy
실행을 호출하는 스레드에서 이 명령을 실행하면 진입이 차단됩니다
사용자 정의 거부 정책(가장 일반적으로 사용됨)
RejectedExecutionHandler를 구현하고 전략 패턴을 직접 정의하세요스레드 풀의 워크플로우 다이어그램을 보여주기 위해 ThreadPoolExecutor를 예로 들어보겠습니다
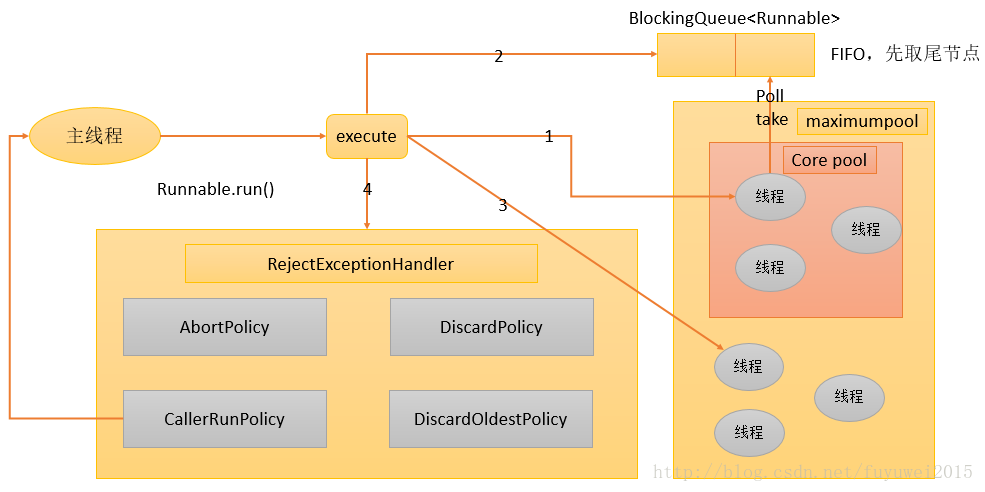
2. 실행 중인 스레드가 corePoolSize 이상인 경우 BlockingQueue에 작업을 추가합니다.
3. 작업을 BlockingQueue에 추가할 수 없는 경우(큐가 가득 찬 경우) 비corePool에 새 스레드를 생성하여 작업을 처리합니다(이 단계를 수행하려면 전역 잠금을 얻어야 합니다).
4. 새 스레드를 생성하면 현재 실행 중인 스레드가 maximumPoolSize를 초과하는 경우 작업이 거부되고 RejectedExecutionHandler.rejectedExecution() 메서드가 호출됩니다.
위 단계를 수행하는 ThreadPoolExecutor의 전반적인 설계 아이디어는 Execute() 메서드를 실행할 때 전역 잠금을 최대한 획득하지 않는 것입니다(이는 심각한 확장성 병목 현상이 발생함). ThreadPoolExecutor가 워밍업을 완료한 후(현재 실행 중인 스레드 수가 corePoolSize보다 크거나 같음) 거의 모든 Execution() 메서드 호출은 2단계를 실행하며 2단계에서는 전역 잠금을 획득할 필요가 없습니다.
핵심 메소드 소스코드 분석 스레드 풀 메소드 실행에 추가된 코어 메소드의 소스코드를 살펴보면 다음과 같습니다.
으아악
addWorker가 어떻게 구현되는지 계속 살펴보겠습니다.으아악
AddWorker 뒤에는 runWorker가 있습니다. 처음 시작되면 초기화 중에 전달된 firstTask 작업을 실행한 다음 workQueue에서 작업을 가져와서 실행합니다. keepAliveTime이기만 하면 으아악
getTask가 어떻게 실행되는지 볼까요으아악
processWorkerExit가 어떻게 작동하는지 살펴보겠습니다으아악
TryTurminateprocessWorkerExit 메서드는 스레드 풀을 종료하기 위해 tryTerminate를 호출하려고 시도합니다. 이 메소드는 스레드 풀을 종료시킬 수 있는 조치(예: wakerCount 감소 또는 SHUTDOWN 상태의 큐에서 작업 제거 등) 후에 실행됩니다.
으아악
shutdown 메소드는 runState를 SHUTDOWN으로 설정하고 모든 유휴 스레드를 종료합니다. shutdownNow 메서드는 runState를 STOP으로 설정합니다. 종료 방법과의 차이점은 이 방법이 모든 스레드를 종료한다는 것입니다. 주요 차이점은 shutdown이 InterruptIdleWorkers 메서드를 호출하는 반면 shutdownNow는 실제로 Worker 클래스의 InterruptIfStarted 메서드를 호출한다는 것입니다.구현은 다음과 같습니다:
으아악
스레드 풀 사용법 스레드 풀 생성 ThreadPoolExecutor를 통해 스레드 풀을 생성할 수 있습니다
/**
* @param corePoolSize 线程池基本大小,核心线程池大小,活动线程小于corePoolSize则直接创建,大于等于则先加到workQueue中,
* 队列满了才创建新的线程。当提交一个任务到线程池时,线程池会创建一个线程来执行任务,即使其他空闲的基本线程能够执行新任务也会创建线程,
* 等到需要执行的任务数大于线程池基本大小时就不再创建。如果调用了线程池的prestartAllCoreThreads()方法,
* 线程池会提前创建并启动所有基本线程。
* @param maximumPoolSize 最大线程数,超过就reject;线程池允许创建的最大线程数。如果队列满了,
* 并且已创建的线程数小于最大线程数,则线程池会再创建新的线程执行任务
* @param keepAliveTime
* 线程池的工作线程空闲后,保持存活的时间。所以,如果任务很多,并且每个任务执行的时间比较短,可以调大时间,提高线程的利用率
* @param unit 线程活动保持时间的单位):可选的单位有天(DAYS)、小时(HOURS)、分钟(MINUTES)、
* 毫秒(MILLISECONDS)、微秒(MICROSECONDS,千分之一毫秒)和纳秒(NANOSECONDS,千分之一微秒)
* @param workQueue 工作队列,线程池中的工作线程都是从这个工作队列源源不断的获取任务进行执行
*/
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue) {
// threadFactory用于设置创建线程的工厂,可以通过线程工厂给每个创建出来的线程设置更有意义的名字
this(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue,
Executors.defaultThreadFactory(), defaultHandler);
}可以使用两个方法向线程池提交任务,分别为execute()和submit()方法。execute()方法用于提交不需要返回值的任务,所以无法判断任务是否被线程池执行成功。通过以下代码可知execute()方法输入的任务是一个Runnable类的实例。
threadsPool.execute(new Runnable() {
@Override
public void run() {
}
});submit()方法用于提交需要返回值的任务。线程池会返回一个future类型的对象,通过这个future对象可以判断任务是否执行成功,并且可以通过future的get()方法来获取返回值,get()方法会阻塞当前线程直到任务完成,而使用get(long timeout,TimeUnit unit)方法则会阻塞当前线程一段时间后立即返回,这时候有可能任务没有执行完。
Future<Object> future = executor.submit(harReturnValuetask);
try
{
Object s = future.get();
}catch(
InterruptedException e)
{
// 处理中断异常
}catch(
ExecutionException e)
{
// 处理无法执行任务异常
}finally
{
// 关闭线程池
executor.shutdown();
}可以通过调用线程池的shutdown或shutdownNow方法来关闭线程池。它们的原理是遍历线程池中的工作线程,然后逐个调用线程的interrupt方法来中断线程,所以无法响应中断的任务可能永远无法终止。但是它们存在一定的区别,shutdownNow首先将线程池的状态设置成STOP,然后尝试停止所有的正在执行或暂停任务的线程,并返回等待执行任务的列表,而shutdown只是将线程池的状态设置成SHUTDOWN状态,然后中断所有没有正在执行任务的线程。
只要调用了这两个关闭方法中的任意一个,isShutdown方法就会返回true。当所有的任务都已关闭后,才表示线程池关闭成功,这时调用isTerminaed方法会返回true。至于应该调用哪一种方法来关闭线程池,应该由提交到线程池的任务特性决定,通常调用shutdown方法来关闭线程池,如果任务不一定要执行完,则可以调用shutdownNow方法。
合理的配置线程池要想合理地配置线程池,就必须首先分析任务特性,可以从以下几个角度来分析。
1、任务的性质:CPU密集型任务、IO密集型任务和混合型任务。
2、任务的优先级:高、中和低。
3、任务的执行时间:长、中和短。
4、任务的依赖性:是否依赖其他系统资源,如数据库连接。
性质不同的任务可以用不同规模的线程池分开处理。CPU密集型任务应配置尽可能小的线程,如配置Ncpu+1个线程的线程池。由于IO密集型任务线程并不是一直在执行任务,则应配置尽可能多的线程,如2*Ncpu。混合型的任务,如果可以拆分,将其拆分成一个CPU密集型任务和一个IO密集型任务,只要这两个任务执行的时间相差不是太大,那么分解后执行的吞吐量将高于串行执行的吞吐量。如果这两个任务执行时间相差太大,则没必要进行分解。可以通过Runtime.getRuntime().availableProcessors()方法获得当前设备的CPU个数。优先级不同的任务可以使用优先级队列PriorityBlockingQueue来处理。它可以让优先级高的任务先执行
如果一直有优先级高的任务提交到队列里,那么优先级低的任务可能永远不能执行。执行时间不同的任务可以交给不同规模的线程池来处理,或者可以使用优先级队列,让执行时间短的任务先执行。依赖数据库连接池的任务,因为线程提交SQL后需要等待数据库返回结果,等待的时间越长,则CPU空闲时间就越长,那么线程数应该设置得越大,这样才能更好地利用CPU。
바운드 큐를 사용하는 것이 좋습니다. 제한된 대기열은 시스템의 안정성과 조기 경고 기능을 향상시킬 수 있으며 필요에 따라 수천 개와 같이 더 크게 설정할 수 있습니다. 때때로 우리 시스템의 백그라운드 작업 스레드 풀의 대기열과 스레드 풀이 가득 차서 버려진 작업에 대한 예외가 지속적으로 발생하는 경우가 있습니다. 조사 결과 데이터베이스에 문제가 있어 SQL 실행이 매우 느려지는 것으로 나타났습니다. 속도가 느립니다. 백그라운드 작업 스레드 풀에는 모든 작업을 쿼리하고 데이터베이스에 데이터를 삽입해야 하므로 스레드 풀에서 작업 중인 모든 스레드가 차단되고 작업이 스레드 풀에 백로그됩니다. 그 당시 무제한 대기열로 설정하면 스레드 풀에 점점 더 많은 대기열이 생겨 메모리가 가득 차서 백그라운드 작업뿐만 아니라 전체 시스템을 사용할 수 없게 될 수 있습니다. 물론 우리 시스템의 모든 작업은 별도의 서버에 배포되며 다양한 크기의 스레드 풀을 사용하여 다양한 유형의 작업을 완료하지만 이러한 문제가 발생하면 다른 작업에도 영향을 미칩니다.
스레드 풀 모니터링시스템에서 스레드 풀을 광범위하게 사용하는 경우, 문제가 발생했을 때 스레드 풀의 사용량을 기반으로 문제를 빠르게 찾을 수 있도록 스레드 풀을 모니터링하는 것이 필요합니다. 스레드 풀에서 제공하는 매개변수를 통해 모니터링할 수 있으며, 스레드 풀 모니터링 시 다음 속성을 사용할 수 있습니다
- taskCount: 스레드 풀이 실행해야 하는 작업 수입니다.
- completedTaskCount: 작업 중에 스레드 풀이 완료한 작업 수로, taskCount보다 작거나 같습니다.
- largestPoolSize: 스레드 풀에서 생성된 최대 스레드 수입니다. 이 데이터를 통해 스레드 풀이 가득 찼는지 여부를 알 수 있습니다. 이 값이 스레드 풀의 최대 크기와 같다면 스레드 풀이 가득 찼다는 의미입니다.
- getPoolSize: 스레드 풀에 있는 스레드 수입니다. 스레드 풀이 소멸되지 않으면 스레드 풀에 있는 스레드가 자동으로 소멸되지 않으므로 크기가 증가할 뿐 줄어들지는 않습니다.
- getActiveCount: 활성 스레드 수를 가져옵니다.
스레드 풀을 확장하여 모니터링합니다. 스레드 풀을 상속하고 스레드 풀의 beforeExecute, afterExecute 및 종료된 메서드를 다시 작성하여 스레드 풀을 사용자 정의하거나 스레드 풀이 닫히기 전, 후, 전에 모니터링하기 위해 일부 코드를 실행할 수 있습니다. 예를 들어 작업의 평균 실행 시간, 최대 실행 시간, 최소 실행 시간을 모니터링합니다.
위 내용은 Java 스레드 풀 작동 방식의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7563
7563
 15
1385
52
84
11
61
19
28
99
15
1385
52
84
11
61
19
28
99

 Centos와 Ubuntu의 차이
Apr 14, 2025 pm 09:09 PM
Centos와 Ubuntu의 차이
Apr 14, 2025 pm 09:09 PM
Centos와 Ubuntu의 주요 차이점은 다음과 같습니다. Origin (Centos는 Red Hat, Enterprise의 경우, Ubuntu는 Debian에서 시작하여 개인의 경우), 패키지 관리 (Centos는 안정성에 중점을 둡니다. Ubuntu는 APT를 사용하여 APT를 사용합니다), 지원주기 (Ubuntu는 5 년 동안 LTS 지원을 제공합니다), 커뮤니티에 중점을 둔다 (Centos Conciors on ubuntu). 튜토리얼 및 문서), 사용 (Centos는 서버에 편향되어 있으며 Ubuntu는 서버 및 데스크탑에 적합), 다른 차이점에는 설치 단순성 (Centos는 얇음)이 포함됩니다.
 유지 보수를 중단 한 후 Centos의 선택
Apr 14, 2025 pm 08:51 PM
유지 보수를 중단 한 후 Centos의 선택
Apr 14, 2025 pm 08:51 PM
Centos는 중단되었으며 대안은 다음과 같습니다. 1. Rocky Linux (Best Compatibility); 2. Almalinux (Centos와 호환); 3. Ubuntu 서버 (구성 필수); 4. Red Hat Enterprise Linux (상업용 버전, 유료 라이센스); 5. Oracle Linux (Centos 및 Rhel과 호환). 마이그레이션시 고려 사항은 호환성, 가용성, 지원, 비용 및 커뮤니티 지원입니다.
 Centos를 설치하는 방법
Apr 14, 2025 pm 09:03 PM
Centos를 설치하는 방법
Apr 14, 2025 pm 09:03 PM
CentOS 설치 단계 : ISO 이미지를 다운로드하고 부팅 가능한 미디어를 실행하십시오. 부팅하고 설치 소스를 선택하십시오. 언어 및 키보드 레이아웃을 선택하십시오. 네트워크 구성; 하드 디스크를 분할; 시스템 시계를 설정하십시오. 루트 사용자를 만듭니다. 소프트웨어 패키지를 선택하십시오. 설치를 시작하십시오. 설치가 완료된 후 하드 디스크에서 다시 시작하고 부팅하십시오.
 Docker Desktop을 사용하는 방법
Apr 15, 2025 am 11:45 AM
Docker Desktop을 사용하는 방법
Apr 15, 2025 am 11:45 AM
Docker Desktop을 사용하는 방법? Docker Desktop은 로컬 머신에서 Docker 컨테이너를 실행하는 도구입니다. 사용 단계는 다음과 같습니다. 1. Docker Desktop 설치; 2. Docker Desktop을 시작하십시오. 3. Docker 이미지를 만듭니다 (Dockerfile 사용); 4. Docker Image 빌드 (Docker 빌드 사용); 5. 도커 컨테이너를 실행하십시오 (Docker Run 사용).
 Docker 원리에 대한 자세한 설명
Apr 14, 2025 pm 11:57 PM
Docker 원리에 대한 자세한 설명
Apr 14, 2025 pm 11:57 PM
Docker는 Linux 커널 기능을 사용하여 효율적이고 고립 된 응용 프로그램 실행 환경을 제공합니다. 작동 원리는 다음과 같습니다. 1. 거울은 읽기 전용 템플릿으로 사용되며, 여기에는 응용 프로그램을 실행하는 데 필요한 모든 것을 포함합니다. 2. Union 파일 시스템 (Unionfs)은 여러 파일 시스템을 스택하고 차이점 만 저장하고 공간을 절약하고 속도를 높입니다. 3. 데몬은 거울과 컨테이너를 관리하고 클라이언트는 상호 작용을 위해 사용합니다. 4. 네임 스페이스 및 CGroup은 컨테이너 격리 및 자원 제한을 구현합니다. 5. 다중 네트워크 모드는 컨테이너 상호 연결을 지원합니다. 이러한 핵심 개념을 이해 함으로써만 Docker를 더 잘 활용할 수 있습니다.
 VSCODE에 필요한 컴퓨터 구성
Apr 15, 2025 pm 09:48 PM
VSCODE에 필요한 컴퓨터 구성
Apr 15, 2025 pm 09:48 PM
대 코드 시스템 요구 사항 : 운영 체제 : Windows 10 이상, MacOS 10.12 이상, Linux 배포 프로세서 : 최소 1.6GHz, 권장 2.0GHz 이상의 메모리 : 최소 512MB, 권장 4GB 이상의 저장 공간 : 최소 250MB, 권장 1GB 및 기타 요구 사항 : 안정 네트워크 연결, Xorg/Wayland (LINUX)
 Docker 프로세스를 보는 방법
Apr 15, 2025 am 11:48 AM
Docker 프로세스를 보는 방법
Apr 15, 2025 am 11:48 AM
도커 프로세스보기 방법 : 1. Docker CLI 명령 : Docker PS; 2. Systemd Cli 명령 : SystemCTL 상태 Docker; 3. Docker Compose CLI 명령 : Docker-Compose PS; 4. 프로세스 탐색기 (Windows); 5. /Proc Directory (Linux).
 Docker 이미지가 실패하면해야 할 일
Apr 15, 2025 am 11:21 AM
Docker 이미지가 실패하면해야 할 일
Apr 15, 2025 am 11:21 AM
실패한 Docker 이미지 빌드에 대한 문제 해결 단계 : Dockerfile 구문 및 종속성 버전을 확인하십시오. 빌드 컨텍스트에 필요한 소스 코드 및 종속성이 포함되어 있는지 확인하십시오. 오류 세부 사항에 대한 빌드 로그를보십시오. -표적 옵션을 사용하여 계층 적 단계를 구축하여 실패 지점을 식별하십시오. 최신 버전의 Docker Engine을 사용하십시오. -t [image-name] : 디버그 모드로 이미지를 빌드하여 문제를 디버깅하십시오. 디스크 공간을 확인하고 충분한 지 확인하십시오. 빌드 프로세스에 대한 간섭을 방지하기 위해 Selinux를 비활성화하십시오. 커뮤니티 플랫폼에 도움을 요청하고 Dockerfiles를 제공하며보다 구체적인 제안을 위해 로그 설명을 구축하십시오.
