

네트워크 케이블을 타고 올라가는 것이 현실이 되었습니다. Audio2Photoreal은 대화를 통해 사실적인 표현과 움직임을 생성할 수 있습니다.

친구들과 차가운 모바일 화면 너머로 채팅을 하고 있을 때, 상대방의 말투를 추측해야 합니다. 그가 말할 때, 그의 표정은 물론 심지어 행동까지도 당신의 마음 속에 나타날 수 있습니다. 물론 영상통화를 할 수 있다면 가장 좋겠지만, 실제 상황에서는 아무 때나 영상통화를 할 수는 없습니다.
원격 친구와 채팅을 하고 있다면 차가운 화면의 문자나 표정이 부족한 아바타가 아닌, 현실적이고 역동적이며 표현력이 풍부한 디지털 가상 인물입니다. 이 가상 인물은 친구의 미소, 눈, 심지어 미묘한 신체 움직임까지 완벽하게 재현할 수 있습니다. 좀 더 친절하고 따뜻해지는 느낌이 들지 않을까요? "당신을 찾기 위해 네트워크 케이블을 따라 기어갈 것입니다"라는 문장을 실제로 구현합니다.
이것은 SF 판타지가 아닌 현실에서 구현 가능한 기술입니다.
얼굴 표정과 신체 움직임에는 많은 양의 정보가 포함되어 있어 콘텐츠의 의미에 큰 영향을 미칩니다. 예를 들어, 항상 상대방을 바라보며 말하는 것은 눈을 마주치지 않고 말하는 것과는 전혀 다른 느낌을 주게 되고, 이는 상대방이 의사소통 내용을 이해하는 데에도 영향을 미치게 됩니다. 우리는 의사소통 중에 이러한 미묘한 표정과 움직임을 감지하고 이를 사용하여 대화 상대의 의도, 편안함 정도 또는 이해에 대한 높은 수준의 이해를 발전시키는 매우 예리한 능력을 가지고 있습니다. 따라서 이러한 미묘함을 포착하는 매우 사실적인 대화형 아바타를 개발하는 것은 상호 작용에 매우 중요합니다.
이를 위해 Meta와 University of California의 연구진은 두 사람의 대화 음성 오디오를 기반으로 사실적인 가상 인간을 생성하는 방법을 제안했습니다. 음성과 밀접하게 동기화되는 다양한 고주파 제스처와 표정이 풍부한 얼굴 움직임을 합성할 수 있습니다. 신체와 손의 경우 자동 회귀 VQ 기반 접근 방식과 확산 모델의 장점을 활용합니다. 얼굴의 경우 오디오를 조건으로 한 확산 모델을 사용합니다. 예측된 얼굴, 몸, 손의 움직임은 현실적인 가상 인간으로 렌더링됩니다. 확산 모델에 안내 제스처 조건을 추가하면 이전 작업보다 더 다양하고 합리적인 대화 제스처가 생성될 수 있음을 보여줍니다.

- 논문 주소: https://huggingface.co/papers/2401.01885
- 프로젝트 주소: https://people.eecs.berkeley.edu/~evonne_ng / projects/audio2photoreal/
연구원들은 대인 대화를 위해 사실적인 얼굴, 몸, 손 움직임을 생성하는 방법을 연구한 최초의 팀이라고 말합니다. 연구진은 기존 연구에 비해 VQ와 확산 방식을 기반으로 보다 현실적이고 다양한 액션을 합성했다.
방법 개요
연구진은 녹화된 다시점 데이터에서 잠재 표정 코드를 추출하여 얼굴을 표현하고, 운동학적 골격의 관절 각도를 사용하여 신체 자세를 표현했습니다. 그림 3에서 볼 수 있듯이 이 시스템은 두 사람의 대화 오디오를 입력할 때 표정 코드와 신체 자세 시퀀스를 생성하는 두 개의 생성 모델로 구성됩니다. 그런 다음 표현 코드와 신체 포즈 시퀀스는 신경 아바타 렌더러를 사용하여 프레임별로 렌더링될 수 있습니다. 이 렌더러는 주어진 카메라 뷰에서 얼굴, 신체, 손이 포함된 완전히 질감이 있는 아바타를 생성할 수 있습니다.
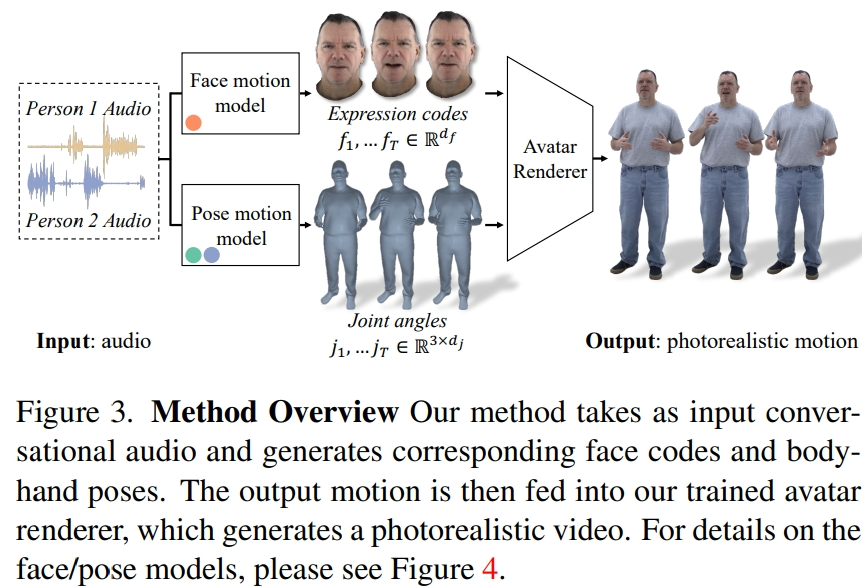
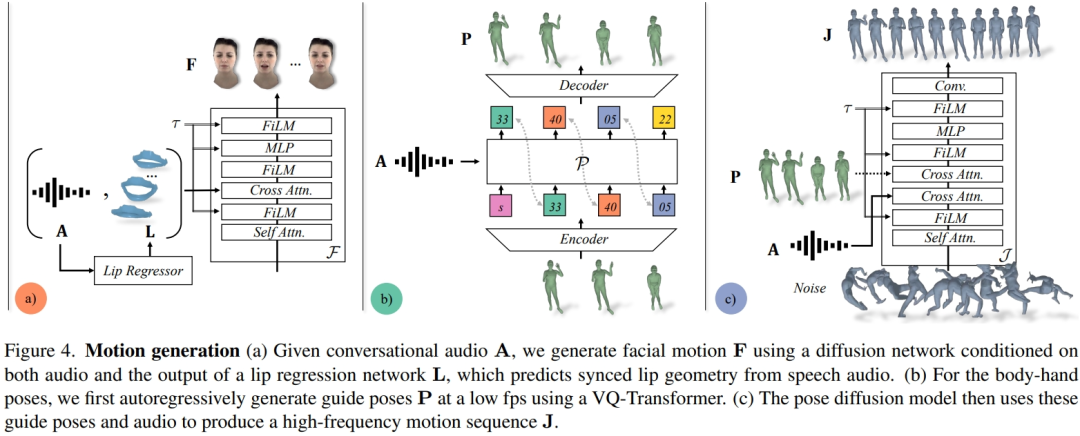
몸과 얼굴의 역학은 매우 다르다는 점에 유의해야 합니다. 첫째, 얼굴은 입력 오디오, 특히 입술 움직임과 강한 상관관계가 있는 반면 신체는 음성과 약한 상관관계가 있습니다. 이로 인해 주어진 음성 입력에서 신체 제스처가 더욱 복잡해지고 다양해집니다. 둘째, 얼굴과 신체는 서로 다른 두 공간에 표현되기 때문에 각각 서로 다른 시간적 역학을 따릅니다. 따라서 연구원들은 얼굴과 신체를 시뮬레이션하기 위해 두 개의 독립적인 모션 모델을 사용했습니다. 이러한 방식으로 얼굴 모델은 말과 일치하는 얼굴 세부 사항에 "집중"할 수 있는 반면 신체 모델은 다양하지만 합리적인 신체 움직임을 생성하는 데 더 집중할 수 있습니다.
얼굴 동작 모델은 사전 훈련된 입술 회귀기에 의해 생성된 입력 오디오 및 입술 꼭짓점을 조건으로 한 확산 모델입니다(그림 4a). 사지 움직임 모델의 경우, 연구원들은 오디오에만 조건을 맞춘 순수 확산 모델에 의해 생성된 움직임이 다양성이 부족하고 시간 순서에서 충분히 조정되지 않는다는 것을 발견했습니다. 그러나 연구자들이 다양한 안내 자세를 조건으로 했을 때 품질이 향상되었습니다. 따라서 신체 동작 모델을 두 부분으로 나눕니다. 첫째, 자동회귀 오디오 컨디셔너는 1fp에서 대략적인 안내 포즈를 예측하고(그림 4b), 확산 모델은 이러한 대략적인 안내 포즈를 활용하여 세밀하고 높은 수준의 정보를 채웁니다. 주파수 운동(그림 4c). 방법 설정에 대한 자세한 내용은 원본 기사를 참조하세요.
실험 및 결과
연구원들은 실제 데이터를 기반으로 사실적인 대화 동작을 효과적으로 생성하는 Audio2Photoreal의 능력을 정량적으로 평가했습니다. 정량적 결과를 확증하고 주어진 대화 상황에서 제스처를 생성하는 데 있어 Audio2Photoreal의 적절성을 측정하기 위해 지각 평가도 수행되었습니다. 실험 결과 평가자는 3D 메쉬가 아닌 현실적인 아바타에 제스처가 제시되었을 때 미묘한 제스처에 더 민감하다는 것을 보여주었습니다.
연구원들은 이 방법으로 생성된 결과를 훈련 세트의 무작위 모션 시퀀스를 기반으로 하는 KNN, SHOW 및 LDA의 세 가지 기본 방법과 비교했습니다. 오디오나 안내 제스처 없이, 안내 제스처 없이 오디오를 기반으로 하고, 오디오 없이 안내 제스처를 기반으로 하는 Audio2Photoreal의 각 구성 요소의 효율성을 테스트하기 위해 절제 실험이 수행되었습니다.
정량적 결과
표 1은 이전 연구와 비교하여 가장 다양성이 높은 모션을 생성할 때 우리 방법이 가장 낮은 FD 점수를 갖는다는 것을 보여줍니다. 랜덤은 GT와 일치하는 좋은 다양성을 가지고 있지만, 랜덤 세그먼트는 해당 대화 역학과 일치하지 않아 FD_g가 높습니다.
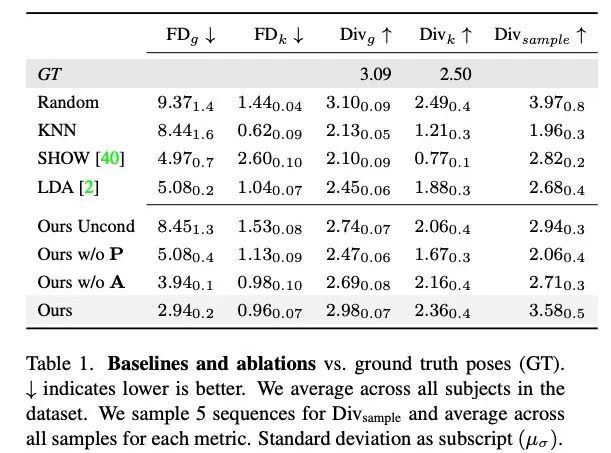
그림 5는 우리 방법으로 생성된 다양한 안내 포즈를 보여줍니다. VQ 기반 트랜스포머 P-샘플링을 사용하면 동일한 오디오 입력으로 매우 다양한 제스처를 생성할 수 있습니다.

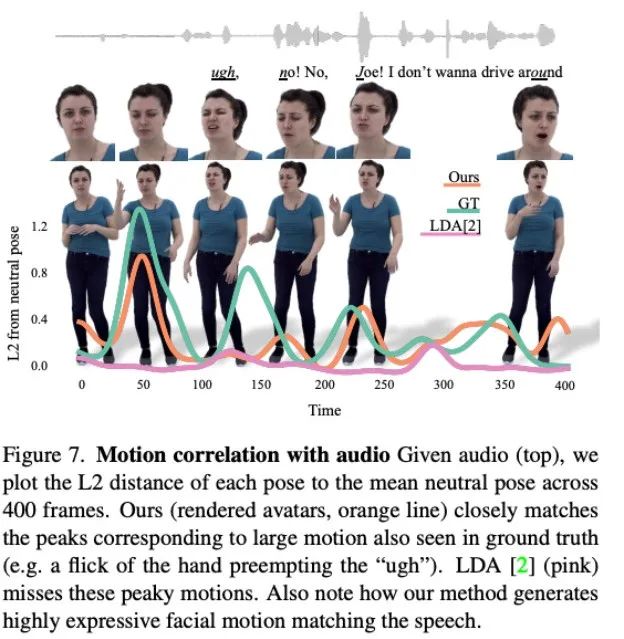
그림 6에서 볼 수 있듯이 확산 모델은 동적 동작을 생성하는 방법을 학습하며, 여기서 동작은 대화 오디오와 더 잘 일치합니다.

그림 7을 보면 LDA에 의해 생성된 모션은 활력이 부족하고 움직임이 적은 것을 알 수 있습니다. 대조적으로, 이 방법으로 합성된 모션 변화는 실제 상황과 더 일치합니다.
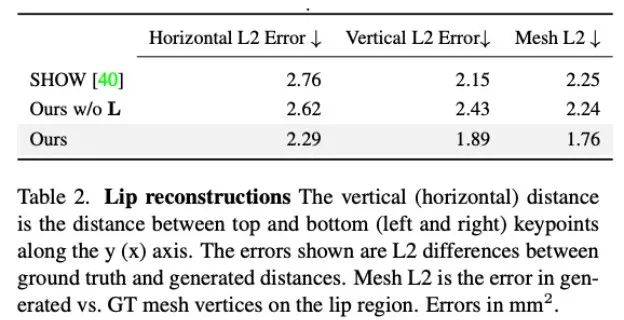
또한 연구원들은 입술 움직임을 생성하는 데 있어 이 방법의 정확성도 분석했습니다. 표 2의 통계에서 알 수 있듯이 Audio2Photoreal은 기본 방법인 SHOW의 성능뿐만 아니라 절제 실험에서 사전 훈련된 립 회귀자를 제거한 후의 성능도 크게 능가합니다. 이 디자인은 말할 때 입 모양의 동기화를 개선하고, 말하지 않을 때 입이 임의로 열리고 닫히는 움직임을 효과적으로 방지하며, 모델이 더 나은 입술 움직임 재구성을 달성할 수 있도록 하며 동시에 얼굴 메시 정점을 줄입니다(그리드 L2). 오류.
정성적 평가
대화에서 몸짓의 일관성은 정량화하기 어렵기 때문에 연구자들은 정성적 평가 방법을 사용하여 평가했습니다. 그들은 MTurk에서 두 세트의 A/B 테스트를 실시했습니다. 구체적으로 평가자들에게 우리 방법과 기준 방법으로 생성된 결과 또는 우리 방법과 실제 장면의 비디오 쌍을 보고 어떤 비디오에서 모션이 더 합리적으로 보이는지 평가하도록 요청했습니다.
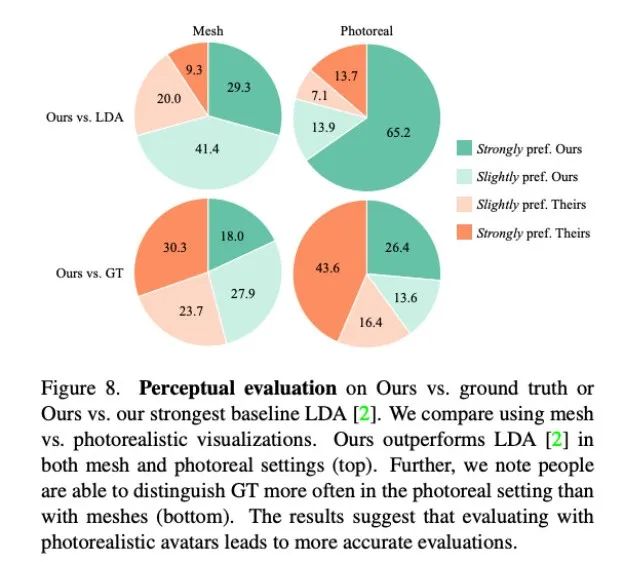
그림 8에서 볼 수 있듯이 이 방법은 이전 기본 방법인 LDA보다 훨씬 우수하며 평가자의 약 70%가 그리드 및 사실성 측면에서 Audio2Photoreal을 선호합니다.
그림 8의 상단 차트에서 볼 수 있듯이 LDA와 비교하여 이 방법에 대한 평가자의 평가는 '약간 선호'에서 '강하게 선호'로 변경되었습니다. 실제 상황과 비교해도 같은 평가가 제시된다. 그럼에도 불구하고 평가자들은 현실감 측면에서 Audio2Photoreal보다 실제를 선호했습니다.
더 자세한 기술적인 내용은 원본 논문을 읽어보세요.
위 내용은 네트워크 케이블을 타고 올라가는 것이 현실이 되었습니다. Audio2Photoreal은 대화를 통해 사실적인 표현과 움직임을 생성할 수 있습니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7521
7521
 15
1378
52
81
11
54
19
21
70
15
1378
52
81
11
54
19
21
70

 데비안 메일 서버 방화벽 구성 팁
Apr 13, 2025 am 11:42 AM
데비안 메일 서버 방화벽 구성 팁
Apr 13, 2025 am 11:42 AM
데비안 메일 서버의 방화벽 구성은 서버 보안을 보장하는 데 중요한 단계입니다. 다음은 iptables 및 방화구 사용을 포함하여 일반적으로 사용되는 여러 방화벽 구성 방법입니다. iptables를 사용하여 iptables를 설치하도록 방화벽을 구성하십시오 (아직 설치되지 않은 경우) : sudoapt-getupdatesudoapt-getinstalliptablesview 현재 iptables 규칙 : sudoiptables-l configuration
 데비안 아파치 로그 레벨을 설정하는 방법
Apr 13, 2025 am 08:33 AM
데비안 아파치 로그 레벨을 설정하는 방법
Apr 13, 2025 am 08:33 AM
이 기사에서는 데비안 시스템에서 Apacheweb 서버의 로깅 레벨을 조정하는 방법에 대해 설명합니다. 구성 파일을 수정하면 Apache가 기록한 로그 정보 수준을 제어 할 수 있습니다. 메소드 1 : 구성 파일을 찾으려면 기본 구성 파일을 수정합니다. 구성 파일 : APACHE2.X의 구성 파일은 일반적으로/etc/apache2/디렉토리에 있습니다. 파일 이름은 설치 방법에 따라 apache2.conf 또는 httpd.conf 일 수 있습니다. 구성 파일 편집 : 텍스트 편집기 (예 : Nano)를 사용하여 루트 권한이있는 구성 파일 열기 : sudonano/etc/apache2/apache2.conf
 Debian Readdir의 성능을 최적화하는 방법
Apr 13, 2025 am 08:48 AM
Debian Readdir의 성능을 최적화하는 방법
Apr 13, 2025 am 08:48 AM
Debian Systems에서 ReadDir 시스템 호출은 디렉토리 내용을 읽는 데 사용됩니다. 성능이 좋지 않은 경우 다음과 같은 최적화 전략을 시도해보십시오. 디렉토리 파일 수를 단순화하십시오. 대규모 디렉토리를 가능한 한 여러 소규모 디렉토리로 나누어 읽기마다 처리 된 항목 수를 줄입니다. 디렉토리 컨텐츠 캐싱 활성화 : 캐시 메커니즘을 구축하고 정기적으로 캐시를 업데이트하거나 디렉토리 컨텐츠가 변경 될 때 캐시를 업데이트하며 readDir로 자주 호출을 줄입니다. 메모리 캐시 (예 : Memcached 또는 Redis) 또는 로컬 캐시 (예 : 파일 또는 데이터베이스)를 고려할 수 있습니다. 효율적인 데이터 구조 채택 : 디렉토리 트래버스를 직접 구현하는 경우 디렉토리 정보를 저장하고 액세스하기 위해보다 효율적인 데이터 구조 (예 : 선형 검색 대신 해시 테이블)를 선택하십시오.
 Debian Readdir의 파일 정렬을 구현하는 방법
Apr 13, 2025 am 09:06 AM
Debian Readdir의 파일 정렬을 구현하는 방법
Apr 13, 2025 am 09:06 AM
Debian Systems에서 readDIR 함수는 디렉토리 내용을 읽는 데 사용되지만 반환하는 순서는 사전 정의되지 않습니다. 디렉토리에 파일을 정렬하려면 먼저 모든 파일을 읽은 다음 QSORT 기능을 사용하여 정렬해야합니다. 다음 코드는 데비안 시스템에서 readdir 및 qsort를 사용하여 디렉토리 파일을 정렬하는 방법을 보여줍니다.#포함#포함#포함#포함#포함 // QsortIntCompare (constvoid*a, constVoid*b) {returnStrcmp (*(*)
 데비안을 오류하는 방법은 중간 중간의 공격을 방해합니다
Apr 13, 2025 am 10:30 AM
데비안을 오류하는 방법은 중간 중간의 공격을 방해합니다
Apr 13, 2025 am 10:30 AM
Debian Systems에서 OpenSSL은 암호화, 암호 해독 및 인증서 관리를위한 중요한 라이브러리입니다. MITM (Man-in-the-Middle Attack)을 방지하려면 다음 측정을 수행 할 수 있습니다. HTTPS 사용 : 모든 네트워크 요청이 HTTP 대신 HTTPS 프로토콜을 사용하도록하십시오. HTTPS는 TLS (Transport Layer Security Protocol)를 사용하여 통신 데이터를 암호화하여 전송 중에 데이터가 도난 당하거나 변조되지 않도록합니다. 서버 인증서 확인 : 클라이언트의 서버 인증서를 수동으로 확인하여 신뢰할 수 있는지 확인하십시오. 서버는 대의원 메소드를 통해 수동으로 확인할 수 있습니다.
 데비안 메일 서버 SSL 인증서 설치 방법
Apr 13, 2025 am 11:39 AM
데비안 메일 서버 SSL 인증서 설치 방법
Apr 13, 2025 am 11:39 AM
Debian Mail 서버에 SSL 인증서를 설치하는 단계는 다음과 같습니다. 1. OpenSSL 툴킷을 먼저 설치하십시오. 먼저 OpenSSL 툴킷이 이미 시스템에 설치되어 있는지 확인하십시오. 설치되지 않은 경우 다음 명령을 사용하여 설치할 수 있습니다. 개인 키 및 인증서 요청 생성 다음에 다음, OpenSSL을 사용하여 2048 비트 RSA 개인 키 및 인증서 요청 (CSR)을 생성합니다.
 Debian Readdir가 다른 도구와 통합하는 방법
Apr 13, 2025 am 09:42 AM
Debian Readdir가 다른 도구와 통합하는 방법
Apr 13, 2025 am 09:42 AM
데비안 시스템의 readdir 함수는 디렉토리 컨텐츠를 읽는 데 사용되는 시스템 호출이며 종종 C 프로그래밍에 사용됩니다. 이 기사에서는 ReadDir를 다른 도구와 통합하여 기능을 향상시키는 방법을 설명합니다. 방법 1 : C 언어 프로그램을 파이프 라인과 결합하고 먼저 C 프로그램을 작성하여 readDir 함수를 호출하고 결과를 출력하십시오.#포함#포함#포함#포함#includinTmain (intargc, char*argv []) {dir*dir; structdirent*entry; if (argc! = 2) {
 데비안 하프 로그 관리를 수행하는 방법
Apr 13, 2025 am 10:45 AM
데비안 하프 로그 관리를 수행하는 방법
Apr 13, 2025 am 10:45 AM
Debian에서 Hadoop 로그 관리하면 다음 단계 및 모범 사례를 따라갈 수 있습니다. 로그 집계 로그 집계 : Yarn-site.xml 파일에서 Ture에서 True로 설정 할 수 있도록 설정 : 로그 집계를 활성화하십시오. 로그 보유 정책 구성 : 172800 초 (2 일)와 같이 로그의 유지 시간을 정의하기 위해 yarn.log-aggregation.retain-seconds를 설정하십시오. 로그 저장 경로를 지정하십시오 : Yarn.n을 통해
