
| 소개 | DBA에 의해 최적화된 데이터베이스 환경에서는 실제로 대부분의 성능 문제는 잘못된 SQL 작성으로 인해 발생합니다. SQL의 세계는 경이로움으로 가득 차 있습니다. 오늘은 피를 토하고 싶게 만드는 킬러 SQL을 살펴보겠습니다. |
보험 고객의 경우 ETL에 몇 시간이 걸렸습니다. SQL 보고서를 작성해본 결과 주로 SQL 중 하나에 압력이 가해진 것으로 나타났습니다.
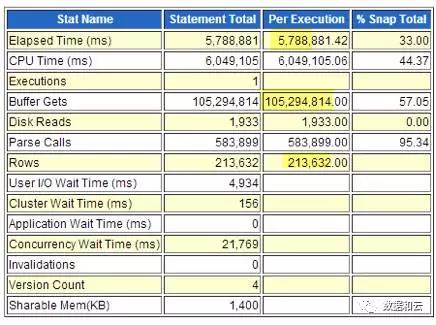
단일 실행 시간: 5788(초)
단일 논리적 읽기: 10억(블록)
한 번에 반환되는 행 수: 210,000(행)
먼저 SQL 문을 살펴보겠습니다. 내용이 꽤 길어서 여기서는 일부만 발췌하겠습니다.

실행 계획 보기:
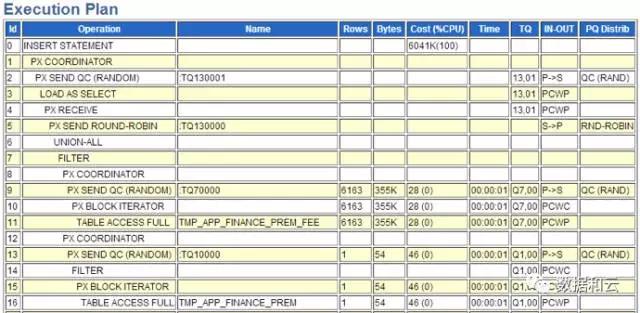
우리는 주로 7~16행에 초점을 맞췄습니다. 두 개의 전체 테이블 스캔이 있다는 것을 발견했습니다. 중간에 필터가 만들어졌습니다.
다년간의 경험에 따르면 두 개의 전체 테이블 스캔으로 구성된 필터는 데이터를 하나씩 처리해야 하기 때문에 심각한 문제가 있습니다. 이 실행 계획에서는 구동 테이블 전체가 계속 스캔됩니다.
Not In/In 작업은 때때로 필터 작업을 생성합니다. 11g 이전 버전에서는 not in 문을 안티 조인으로 변환해야 합니다. not in 조건의 열에는 Not null 속성이 있어야 합니다. 그렇지 않으면 not null이 포함되어야 합니다. 그렇지 않으면 필터를 사용하여 하나씩만 필터링할 수 있습니다.
예를 들어보겠습니다:
T_OBJ의 속성 보기:

세 개의 열에 null이 아닌 제한이 없음을 확인했습니다.
현재 우리는 10G 옵티마이저인 척하고 있습니다.
SQL> 세션 설정 변경 Optimizer_features_enable=”10.2.0.5″;
다음 SQL을 실행하세요:
SQL> 자동 추적 exp 설정
SQL> SELECT * FROM T_TABLE WHERE TABLE_NAME NOT IN(SELECT OBJECT_NAME FROM T_OBJ);
이번 실행 계획을 살펴보면 다음과 같은 필터가 사용된 것을 확인했습니다.
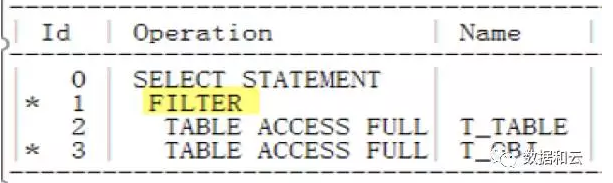
그러나 11g 버전에서는 옵티마이저가 자동으로 Not in Operation을 고가의 Filter에서 Null-Aware-Anti-Join으로 변환할 수 있습니다.
Not null 조건을 추가하거나 필드 속성을 not null로 설정하는 경우
SQL> 테이블 변경 T_OBJ 수정(OBJECT_NAME NOT NULL);
같은 문장을 다시 실행하세요:
SQL> SELECT * FROM T_TABLE WHERE TABLE_NAME
NOT IN(T_OBJ에서 OBJECT_NAME 선택
WHEREOOBJECT_NAME은 NULL이 아닙니다);
실행 계획 다시 보기:

이때 실행 계획에서 Hash Join Anti를 발견했습니다.
그리고 11g에서는 not null 제한 없이 not in columns가 허용되며 Anti-Join 변환도 가능합니다.
SQL> 세션 설정 변경 Optimizer_features_enable=”11.2.0.4″;
SQL> 테이블 변경 T_OBJ 수정(OBJECT_NAME NULL);
SQ> SELECT * FROM T_TABLE WHERE TABLE_NAME
NOT IN (SELECTOBJECT_NAMEFROM T_OBJ);
실행 계획 보기:
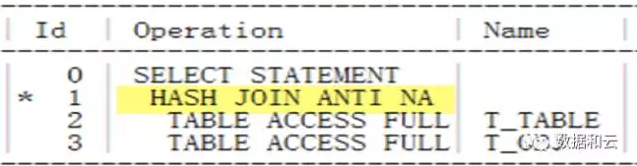
이때 hash Join anti.
도 non-empty 제한 없이 사용되는 것을 알 수 있습니다.이 기능은 최적화 매개변수를 통해 제어할 수 있습니다.
SQL>alter session set “_optimizer_null_aware_antijoin”=FALSE;
위 명령문을 다시 실행하고 실행 계획을 확인하세요.
SQL> SELECT * FROM T_TABLE WHERE TABLE_NAME
NOT IN (SELECTOBJECT_NAMEFROM T_OBJ);
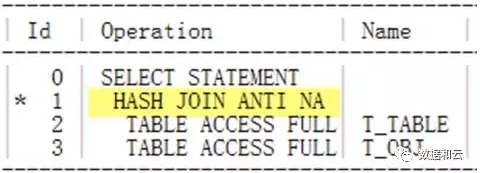
저는 아직도 해시 조인 방지를 사용하고 있는 것을 발견했습니다.
본 파라미터 설정에는 문제가 없는 것으로 확인되었습니다
Not in의 논리는 결과 세트 간의 상호 배제입니다. 실제로 이를 다시 작성하는 방법은 다음과 같습니다.
—존재하지 않음
— 외부 조인 +는 null입니다
—마이너스
not in과 위의 세 가지 작성 방법의 차이점은 not in이 null 값을 제외한다는 것입니다.
다시 쓰려고 노력합니다.
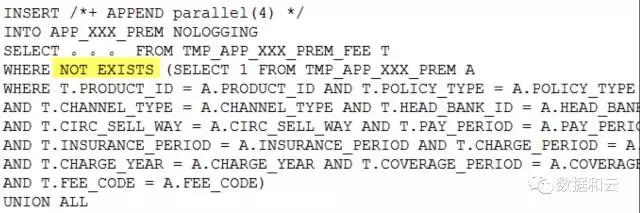
그러다가 기적이 일어날 거라고 생각한 순간, 진술서에 오류가 보고됐어요!

오류가 보고되는 이유는 무엇인가요?
이 명령문을 not in으로 변환하면:

not in의 논리에 따르면 이때 fee_code 앞에 'A.'를 추가해야 합니다. 물론 문제는 없지만 이 문장을 다시 보면 다음과 같습니다.

TMP_APP_xxx_PREM A에는 FEE_CODE 필드가 없으므로 Not in을 Null Aware ANTI JOIN으로 자동 변경할 수 없습니다.
그럼 이제 정답이 공개됐으니 실수로 판명됐다는 건가요? ! 시작은 짐작했지만 끝은 아니었습니다.
그러나 이 경우에는 SQL 문에 해당 문이 명시적으로 작성되지 않았기 때문에 초기 분석 과정에서 이 오류가 발견되지 않았습니다.
당신도 말문이 막히나요? 사실 더 묻고 싶은 것은 킬러 SQL을 자주 쓰시나요? 하지만 아프면 약이 있어요. (순진한 얼굴, 때리지 마세요)
DBA에 의해 최적화된 데이터베이스 환경에서는 실제로 대부분의 성능 문제가 잘못된 SQL 작성으로 인해 발생한다는 사실은 모두가 알고 있습니다.
온라인이 아닌 시스템의 경우 초기 SQL 감사 및 제어를 통해 초기 단계에서 SQL 문제의 80%가 제거됩니다. 온라인으로 실행되는 시스템의 경우 잠재적인 성능 문제를 조기에 발견하고 해결하여 이를 예방할 수 있습니다.
SQL 감사를 통해 DBA는 시스템의 응급 의사에서 시스템의 의료 의사로 전환할 수 있습니다.
1. DBA는 애플리케이션 코드 개발 및 테스트 프로세스에 참여합니다. 개발자에게 전문적인 데이터베이스 개발 및 최적화 제안 제공
2. 프런트엔드 최적화: 애플리케이션 코드가 온라인 상태가 되기 전에 비즈니스 요구에 따라 효율적인 SQL 및 인덱스를 설계하세요
3. 변경 위험 제어: 실행 중인 애플리케이션에 대한 애플리케이션 개발 중 테이블 구조 변경 및 SQL 변경이 미치는 영향을 사전 평가하고 적절한 변경 기간과 변경 계획을 결정합니다.
위 내용은 SQL 쿼리를 최적화하여 'Not in' 런타임을 줄입니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



