

다중 모드 RAG 시스템 구축 방법: CLIP 및 LLM 사용

오픈소스 Large Language Multi-Modal을 활용하여 RAG(Retrieval Augmented Generation) 시스템을 구축하는 방법에 대해 논의하겠습니다. 우리의 초점은 더 많은 프레임워크 종속성을 추가하지 않기 위해 LangChain 또는 LLlama 인덱스에 의존하지 않고 이를 달성하는 것입니다.

RAG란 무엇입니까
인공지능 분야에서 RAG(Recovery-Augmented Generation) 기술의 등장은 대규모 언어 모델(Large Language Models)에 혁명적인 발전을 가져왔습니다. RAG의 핵심은 모델이 외부 소스로부터 실시간 정보를 동적으로 검색할 수 있도록 하여 인공지능의 반응성을 높이는 것입니다. 이 기술의 도입으로 AI는 사용자 요구에 보다 구체적으로 대응할 수 있게 됐다. RAG는 외부 소스에서 정보를 검색하고 융합함으로써 보다 정확하고 포괄적인 답변을 생성하여 사용자에게 보다 가치 있는 콘텐츠를 제공할 수 있습니다. 이러한 기능 향상으로 지능형 고객 서비스, 지능형 검색, 지식 질의응답 시스템 등 인공지능 응용 분야에 대한 전망이 더욱 넓어졌습니다. RAG의 출현은 언어 모델의 추가 개발을 의미하며
을 인공 지능에 도입합니다. 이 아키텍처는 동적 검색 프로세스와 생성 기능을 원활하게 결합하여 인공 지능이 다양한 분야에서 변화하는 정보에 적응할 수 있도록 합니다. 미세 조정 및 재훈련과 달리 RAG는 AI가 전체 모델을 변경하지 않고도 최신 관련 정보를 얻을 수 있는 비용 효율적인 솔루션을 제공합니다. 이러한 기능의 조합은 RAG가 급변하는 정보 환경에 대응하는 데 있어 이점을 제공합니다.
RAG의 역할
1. 정확성과 신뢰성 향상:
LLM을 신뢰할 수 있는 지식 소스로 전달하여 예측 불가능성 문제를 해결합니다. 허위이거나 오래된 정보는 응답을 더욱 정확하고 신뢰할 수 있게 만듭니다.
2. 투명성과 신뢰도 향상:
LLM과 같은 생성형 AI 모델은 투명성이 부족한 경우가 많아 사람들이 결과물을 신뢰하기 어렵습니다. RAG는 더 강력한 제어 기능을 제공하여 편향, 신뢰성 및 규정 준수에 대한 우려를 해결합니다.
3. 환각 감소:
LLM은 환각 반응을 일으키기 쉽습니다. 즉, 일관되지만 부정확하거나 조작된 정보를 제공합니다. RAG는 대응을 보장하기 위해 권위 있는 소스에 의존함으로써 주요 부문에 대한 오해의 소지가 있는 조언의 위험을 줄입니다.
4. 비용 효율적인 적응성:
RAG는 광범위한 재교육/미세 조정 없이 AI 출력을 향상시킬 수 있는 비용 효율적인 방법을 제공합니다. 필요에 따라 특정 세부 정보를 동적으로 검색하여 정보를 최신 상태로 유지하고 변화하는 정보에 대한 AI 적응성을 보장할 수 있습니다.
멀티모달 모달 모델
멀티모달은 여러 입력을 갖고 이를 단일 출력으로 결합하는 것을 포함하며 CLIP을 예로 들어 보겠습니다. CLIP의 학습 데이터는 텍스트-이미지 쌍이며 대조 학습을 통해 모델은 텍스트-이미지 쌍 간의 일치 관계를 학습합니다.
이 모델은 동일한 것을 나타내는 다양한 입력에 대해 동일한(매우 유사한) 임베딩 벡터를 생성합니다. multi-modal
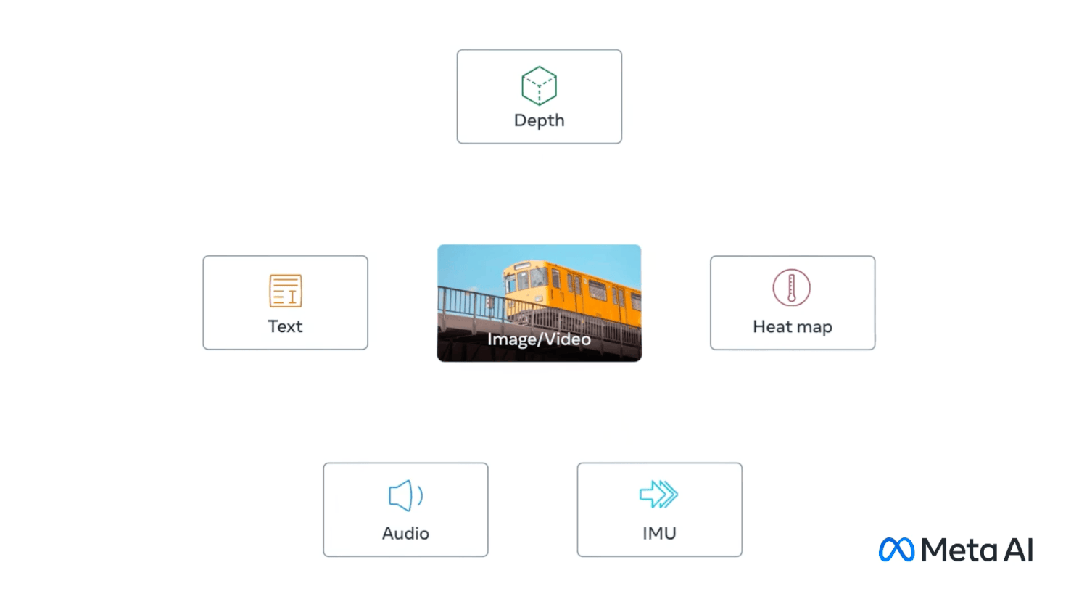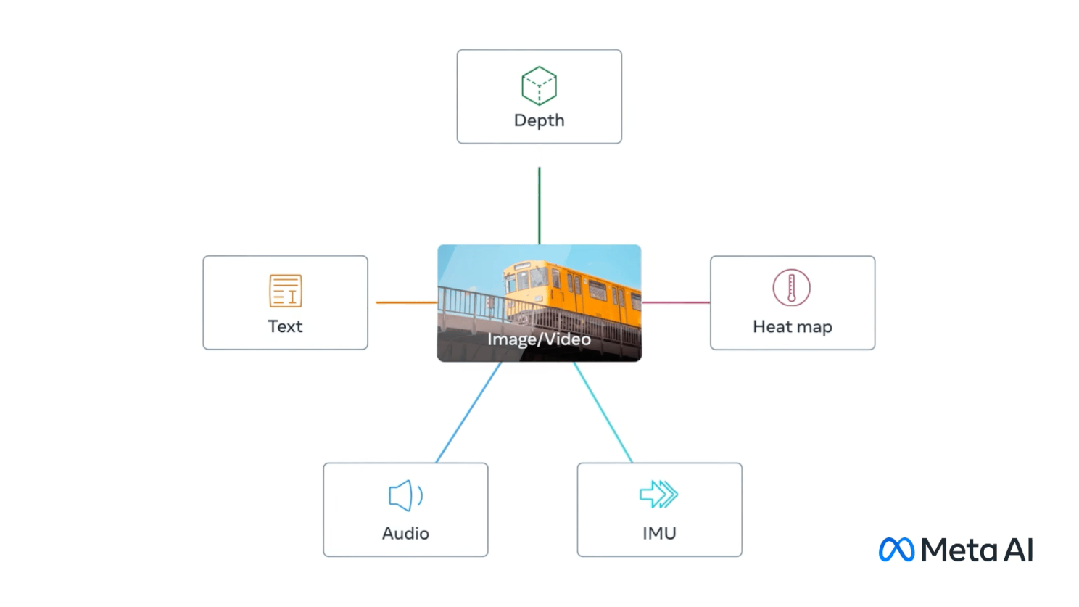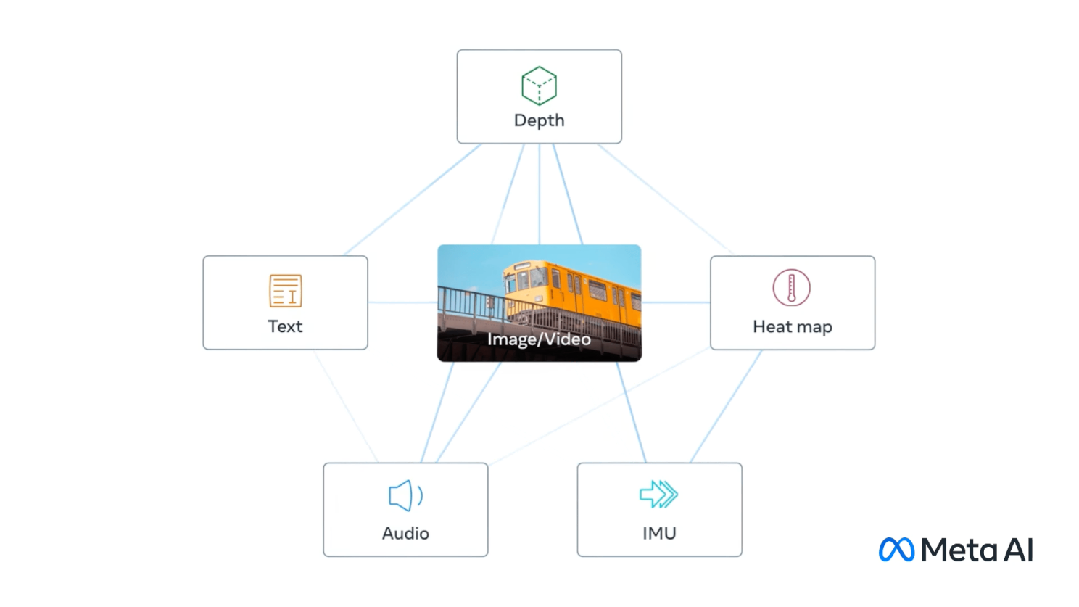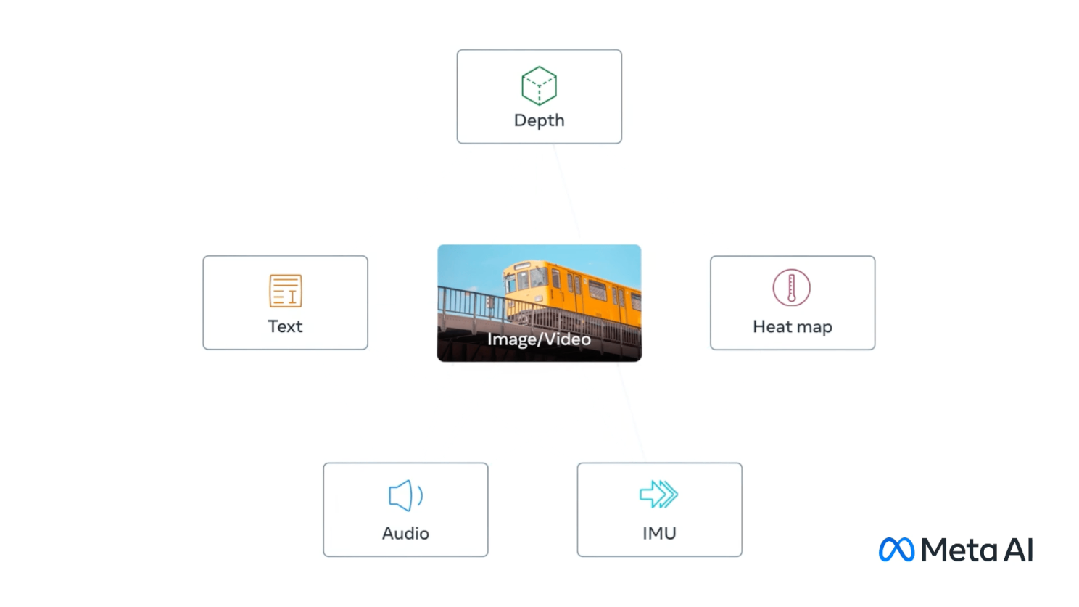
모달 대형 언어 (멀티 모달 큰 언어)
GPT4V 및 Gemini Vision은 다양한 데이터 유형 (이미지, 텍스트, 포함 포함)을 탐색하고 통합합니다. 언어, 오디오 등) MLLM(다중 모드 언어 모델). GPT-3, BERT, RoBERTa와 같은 대규모 언어 모델(LLM)은 텍스트 기반 작업에서는 잘 수행되지만 다른 데이터 유형을 이해하고 처리하는 데 어려움을 겪습니다. 이러한 한계를 해결하기 위해 다중 모드 모델은 다양한 양식을 결합하여 다양한 데이터를 보다 포괄적으로 이해할 수 있도록 합니다.
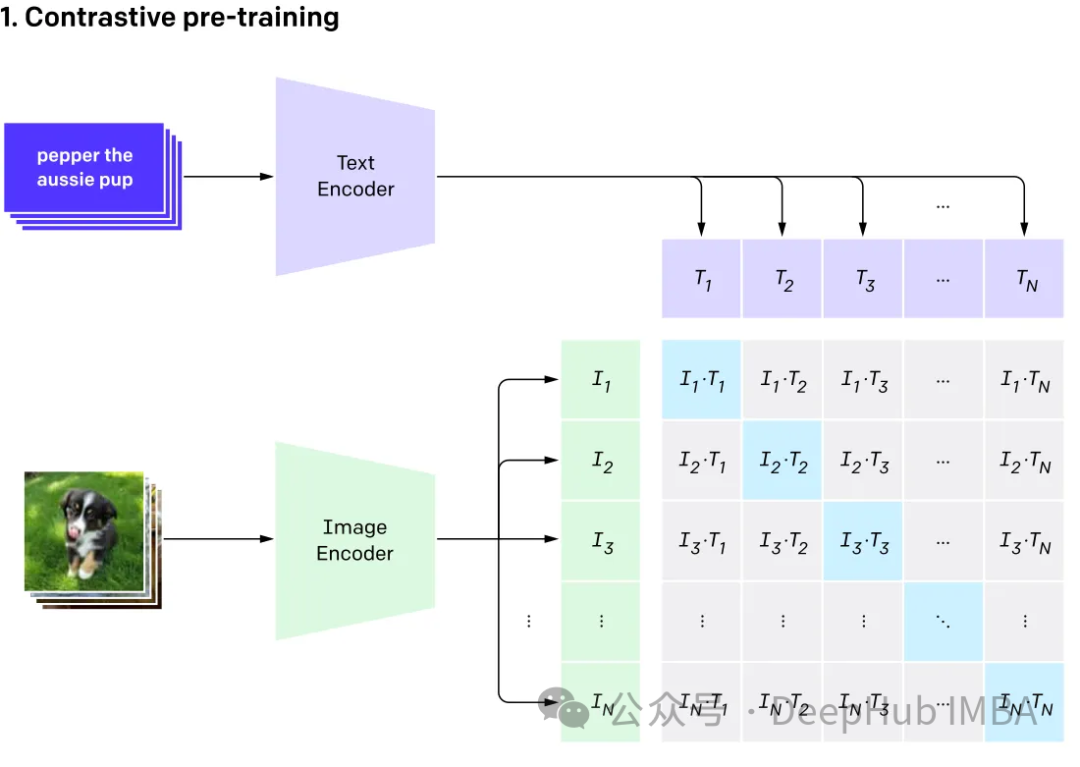
RAG
여기에서는 Clip을 사용하여 이미지와 텍스트를 삽입하고 이러한 삽입을 ChromDB 벡터 데이터베이스에 저장합니다. 그런 다음 대규모 모델을 활용하여 검색된 정보를 기반으로 사용자 채팅 세션에 참여합니다.
Kaggle의 이미지와 Wikipedia의 정보를 사용하여 꽃 전문가 챗봇을 만듭니다.
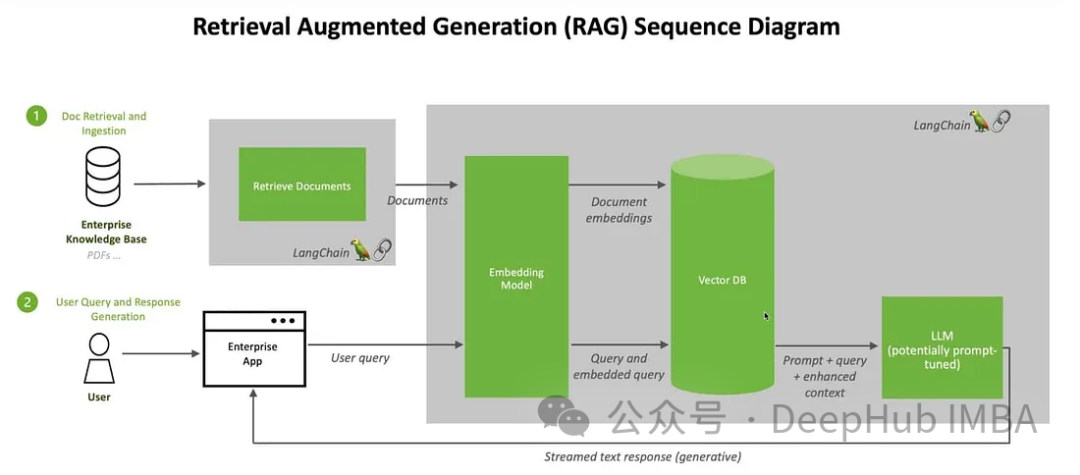 먼저 패키지를 설치합니다.
먼저 패키지를 설치합니다.
! pip install -q timm einops wikipedia chromadb open_clip_torch !pip install -q transformers==4.36.0 !pip install -q bitsandbytes==0.41.3 accelerate==0.25.0
데이터 전처리 단계는 매우 간단합니다. 그냥 폴더에 이미지와 텍스트를 넣으세요
可以随意使用任何矢量数据库,这里我们使用ChromaDB。 ChromaDB需要自定义嵌入函数 这里将创建2个集合,一个用于文本,另一个用于图像 对于Clip,我们可以像这样使用文本检索图像 也可以使用图像检索相关的图像 文本集合如下所示 然后使用上面的文本集合获取嵌入 结果如下: 或使用图片获取文本 上图的结果如下: 这样我们就完成了文本和图像的匹配工作,其实这里都是CLIP的工作,下面我们开始加入LLM。 我们是用visheratin/LLaVA-3b 加载tokenizer 然后定义处理器,方便我们以后调用 下面就可以直接使用了 得到的结果如下: 结果还包含了我们需要的大部分信息 这样我们整合就完成了,最后就是创建聊天模板, 如何创建聊天过程我们这里就不详细介绍了,完整代码在这里:
import chromadb from chromadb.utils.embedding_functions import OpenCLIPEmbeddingFunction from chromadb.utils.data_loaders import ImageLoader from chromadb.config import Settings client = chromadb.PersistentClient(path="DB") embedding_function = OpenCLIPEmbeddingFunction() image_loader = ImageLoader() # must be if you reads from URIs
from chromadb import Documents, EmbeddingFunction, Embeddings class MyEmbeddingFunction(EmbeddingFunction):def __call__(self, input: Documents) -> Embeddings:# embed the documents somehow or imagesreturn embeddings
collection_images = client.create_collection(name='multimodal_collection_images', embedding_functinotallow=embedding_function, data_loader=image_loader) collection_text = client.create_collection(name='multimodal_collection_text', embedding_functinotallow=embedding_function, ) # Get the Images IMAGE_FOLDER = '/kaggle/working/all_data' image_uris = sorted([os.path.join(IMAGE_FOLDER, image_name) for image_name in os.listdir(IMAGE_FOLDER) if not image_name.endswith('.txt')]) ids = [str(i) for i in range(len(image_uris))] collection_images.add(ids=ids, uris=image_uris) #now we have the images collectionfrom matplotlib import pyplot as plt retrieved = collection_images.query(query_texts=["tulip"], include=['data'], n_results=3) for img in retrieved['data'][0]:plt.imshow(img)plt.axis("off")plt.show()

# now the text DB from chromadb.utils import embedding_functions default_ef = embedding_functions.DefaultEmbeddingFunction() text_pth = sorted([os.path.join(IMAGE_FOLDER, image_name) for image_name in os.listdir(IMAGE_FOLDER) if image_name.endswith('.txt')]) list_of_text = [] for text in text_pth:with open(text, 'r') as f:text = f.read()list_of_text.append(text) ids_txt_list = ['id'+str(i) for i in range(len(list_of_text))] ids_txt_list collection_text.add(documents = list_of_text,ids =ids_txt_list )results = collection_text.query(query_texts=["What is the bellflower?"],n_results=1 ) results
{'ids': [['id0']],'distances': [[0.6072186183744086]],'metadatas': [[None]],'embeddings': None,'documents': [['Campanula () is the type genus of the Campanulaceae family of flowering plants. Campanula are commonly known as bellflowers and take both their common and scientific names from the bell-shaped flowers—campanula is Latin for "little bell".\nThe genus includes over 500 species and several subspecies, distributed across the temperate and subtropical regions of the Northern Hemisphere, with centers of diversity in the Mediterranean region, Balkans, Caucasus and mountains of western Asia. The range also extends into mountains in tropical regions of Asia and Africa.\nThe species include annual, biennial and perennial plants, and vary in habit from dwarf arctic and alpine species under 5 cm high, to large temperate grassland and woodland species growing to 2 metres (6 ft 7 in) tall.']],'uris': None,'data': None}query_image = '/kaggle/input/flowers/flowers/rose/00f6e89a2f949f8165d5222955a5a37d.jpg' raw_image = Image.open(query_image) doc = collection_text.query(query_embeddings=embedding_function(query_image), n_results=1, )['documents'][0][0]

A rose is either a woody perennial flowering plant of the genus Rosa (), in the family Rosaceae (), or the flower it bears. There are over three hundred species and tens of thousands of cultivars. They form a group of plants that can be erect shrubs, climbing, or trailing, with stems that are often armed with sharp prickles. Their flowers vary in size and shape and are usually large and showy, in colours ranging from white through yellows and reds. Most species are native to Asia, with smaller numbers native to Europe, North America, and northwestern Africa. Species, cultivars and hybrids are all widely grown for their beauty and often are fragrant. Roses have acquired cultural significance in many societies. Rose plants range in size from compact, miniature roses, to climbers that can reach seven meters in height. Different species hybridize easily, and this has been used in the development of the wide range of garden roses.
from huggingface_hub import hf_hub_download hf_hub_download(repo_, filename="configuration_llava.py", local_dir="./", force_download=True) hf_hub_download(repo_, filename="configuration_phi.py", local_dir="./", force_download=True) hf_hub_download(repo_, filename="modeling_llava.py", local_dir="./", force_download=True) hf_hub_download(repo_, filename="modeling_phi.py", local_dir="./", force_download=True) hf_hub_download(repo_, filename="processing_llava.py", local_dir="./", force_download=True)
from modeling_llava import LlavaForConditionalGeneration import torch model = LlavaForConditionalGeneration.from_pretrained("visheratin/LLaVA-3b") model = model.to("cuda")from transformers import AutoTokenizer tokenizer = AutoTokenizer.from_pretrained("visheratin/LLaVA-3b")from processing_llava import LlavaProcessor, OpenCLIPImageProcessor image_processor = OpenCLIPImageProcessor(model.config.preprocess_config) processor = LlavaProcessor(image_processor, tokenizer)
question = 'Answer with organized answers: What type of rose is in the picture? Mention some of its characteristics and how to take care of it ?' query_image = '/kaggle/input/flowers/flowers/rose/00f6e89a2f949f8165d5222955a5a37d.jpg' raw_image = Image.open(query_image) doc = collection_text.query(query_embeddings=embedding_function(query_image), n_results=1, )['documents'][0][0] plt.imshow(raw_image) plt.show() imgs = collection_images.query(query_uris=query_image, include=['data'], n_results=3) for img in imgs['data'][0][1:]:plt.imshow(img)plt.axis("off")plt.show()

prompt = """system A chat between a curious human and an artificial intelligence assistant. The assistant is an exprt in flowers , and gives helpful, detailed, and polite answers to the human's questions. The assistant does not hallucinate and pays very close attention to the details. user <image> {question} Use the following article as an answer source. Do not write outside its scope unless you find your answer better {article} if you thin your answer is better add it after document. assistant """.format(questinotallow='question', article=doc)</image>
위 내용은 다중 모드 RAG 시스템 구축 방법: CLIP 및 LLM 사용의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7434
7434
 15
1359
52
76
11
29
19
15
1359
52
76
11
29
19

 Bytedance Cutting, SVIP 슈퍼 멤버십 출시: 연간 연속 구독료 499위안, 다양한 AI 기능 제공
Jun 28, 2024 am 03:51 AM
Bytedance Cutting, SVIP 슈퍼 멤버십 출시: 연간 연속 구독료 499위안, 다양한 AI 기능 제공
Jun 28, 2024 am 03:51 AM
이 사이트는 6월 27일에 Jianying이 ByteDance의 자회사인 FaceMeng Technology에서 개발한 비디오 편집 소프트웨어라고 보도했습니다. 이 소프트웨어는 Douyin 플랫폼을 기반으로 하며 기본적으로 플랫폼 사용자를 위한 짧은 비디오 콘텐츠를 제작합니다. Windows, MacOS 및 기타 운영 체제. Jianying은 멤버십 시스템 업그레이드를 공식 발표하고 지능형 번역, 지능형 하이라이트, 지능형 패키징, 디지털 인간 합성 등 다양한 AI 블랙 기술을 포함하는 새로운 SVIP를 출시했습니다. 가격면에서 SVIP 클리핑 월 요금은 79위안, 연간 요금은 599위안(본 사이트 참고: 월 49.9위안에 해당), 월간 연속 구독료는 월 59위안, 연간 연속 구독료는 59위안입니다. 연간 499위안(월 41.6위안)입니다. 또한, 컷 관계자는 "사용자 경험 향상을 위해 기존 VIP에 가입하신 분들도
 Rag 및 Sem-Rag를 사용한 상황 증강 AI 코딩 도우미
Jun 10, 2024 am 11:08 AM
Rag 및 Sem-Rag를 사용한 상황 증강 AI 코딩 도우미
Jun 10, 2024 am 11:08 AM
검색 강화 생성 및 의미론적 메모리를 AI 코딩 도우미에 통합하여 개발자 생산성, 효율성 및 정확성을 향상시킵니다. EnhancingAICodingAssistantswithContextUsingRAGandSEM-RAG에서 번역됨, 저자 JanakiramMSV. 기본 AI 프로그래밍 도우미는 자연스럽게 도움이 되지만, 소프트웨어 언어에 대한 일반적인 이해와 소프트웨어 작성의 가장 일반적인 패턴에 의존하기 때문에 가장 관련성이 높고 정확한 코드 제안을 제공하지 못하는 경우가 많습니다. 이러한 코딩 도우미가 생성한 코드는 자신이 해결해야 할 문제를 해결하는 데 적합하지만 개별 팀의 코딩 표준, 규칙 및 스타일을 따르지 않는 경우가 많습니다. 이로 인해 코드가 애플리케이션에 승인되기 위해 수정되거나 개선되어야 하는 제안이 나타나는 경우가 많습니다.
 미세 조정을 통해 LLM이 실제로 새로운 것을 배울 수 있습니까? 새로운 지식을 도입하면 모델이 더 많은 환각을 생성할 수 있습니다.
Jun 11, 2024 pm 03:57 PM
미세 조정을 통해 LLM이 실제로 새로운 것을 배울 수 있습니까? 새로운 지식을 도입하면 모델이 더 많은 환각을 생성할 수 있습니다.
Jun 11, 2024 pm 03:57 PM
LLM(대형 언어 모델)은 대규모 텍스트 데이터베이스에서 훈련되어 대량의 실제 지식을 습득합니다. 이 지식은 매개변수에 내장되어 필요할 때 사용할 수 있습니다. 이러한 모델에 대한 지식은 훈련이 끝나면 "구체화"됩니다. 사전 훈련이 끝나면 모델은 실제로 학습을 중단합니다. 모델을 정렬하거나 미세 조정하여 이 지식을 활용하고 사용자 질문에 보다 자연스럽게 응답하는 방법을 알아보세요. 그러나 때로는 모델 지식만으로는 충분하지 않을 때도 있으며, 모델이 RAG를 통해 외부 콘텐츠에 접근할 수 있더라도 미세 조정을 통해 모델을 새로운 도메인에 적응시키는 것이 유익한 것으로 간주됩니다. 이러한 미세 조정은 인간 주석 작성자 또는 기타 LLM 생성자의 입력을 사용하여 수행됩니다. 여기서 모델은 추가적인 실제 지식을 접하고 이를 통합합니다.
 7가지 멋진 GenAI 및 LLM 기술 인터뷰 질문
Jun 07, 2024 am 10:06 AM
7가지 멋진 GenAI 및 LLM 기술 인터뷰 질문
Jun 07, 2024 am 10:06 AM
AIGC에 대해 자세히 알아보려면 다음을 방문하세요. 51CTOAI.x 커뮤니티 https://www.51cto.com/aigc/Translator|Jingyan Reviewer|Chonglou는 인터넷 어디에서나 볼 수 있는 전통적인 문제 은행과 다릅니다. 고정관념에서 벗어나 생각해야 합니다. LLM(대형 언어 모델)은 데이터 과학, 생성 인공 지능(GenAI) 및 인공 지능 분야에서 점점 더 중요해지고 있습니다. 이러한 복잡한 알고리즘은 인간의 기술을 향상시키고 많은 산업 분야에서 효율성과 혁신을 촉진하여 기업이 경쟁력을 유지하는 데 핵심이 됩니다. LLM은 자연어 처리, 텍스트 생성, 음성 인식 및 추천 시스템과 같은 분야에서 광범위하게 사용될 수 있습니다. LLM은 대량의 데이터로부터 학습하여 텍스트를 생성할 수 있습니다.
 지식 그래프 검색을 위해 향상된 GraphRAG(Neo4j 코드를 기반으로 구현됨)
Jun 12, 2024 am 10:32 AM
지식 그래프 검색을 위해 향상된 GraphRAG(Neo4j 코드를 기반으로 구현됨)
Jun 12, 2024 am 10:32 AM
GraphRAG(Graph Retrieval Enhanced Generation)는 점차 대중화되고 있으며 기존 벡터 검색 방법을 강력하게 보완하는 수단이 되었습니다. 이 방법은 그래프 데이터베이스의 구조적 특성을 활용하여 데이터를 노드와 관계의 형태로 구성함으로써 검색된 정보의 깊이와 맥락적 관련성을 향상시킵니다. 그래프는 다양하고 상호 연관된 정보를 표현하고 저장하는 데 자연스러운 이점을 가지며, 다양한 데이터 유형 간의 복잡한 관계와 속성을 쉽게 캡처할 수 있습니다. 벡터 데이터베이스는 이러한 유형의 구조화된 정보를 처리할 수 없으며 고차원 벡터로 표현되는 구조화되지 않은 데이터를 처리하는 데 더 중점을 둡니다. RAG 애플리케이션에서 구조화된 그래프 데이터와 구조화되지 않은 텍스트 벡터 검색을 결합하면 이 기사에서 논의할 내용인 두 가지 장점을 동시에 누릴 수 있습니다. 구조
 대형 모델에 대한 새로운 과학적이고 복잡한 질문 답변 벤치마크 및 평가 시스템을 제공하기 위해 UNSW, Argonne, University of Chicago 및 기타 기관이 공동으로 SciQAG 프레임워크를 출시했습니다.
Jul 25, 2024 am 06:42 AM
대형 모델에 대한 새로운 과학적이고 복잡한 질문 답변 벤치마크 및 평가 시스템을 제공하기 위해 UNSW, Argonne, University of Chicago 및 기타 기관이 공동으로 SciQAG 프레임워크를 출시했습니다.
Jul 25, 2024 am 06:42 AM
편집자 |ScienceAI 질문 응답(QA) 데이터 세트는 자연어 처리(NLP) 연구를 촉진하는 데 중요한 역할을 합니다. 고품질 QA 데이터 세트는 모델을 미세 조정하는 데 사용될 수 있을 뿐만 아니라 LLM(대형 언어 모델)의 기능, 특히 과학적 지식을 이해하고 추론하는 능력을 효과적으로 평가하는 데에도 사용할 수 있습니다. 현재 의학, 화학, 생물학 및 기타 분야를 포괄하는 과학적인 QA 데이터 세트가 많이 있지만 이러한 데이터 세트에는 여전히 몇 가지 단점이 있습니다. 첫째, 데이터 형식이 비교적 단순하고 대부분이 객관식 질문이므로 평가하기 쉽지만 모델의 답변 선택 범위가 제한되고 모델의 과학적 질문 답변 능력을 완전히 테스트할 수 없습니다. 이에 비해 개방형 Q&A는
 당신이 모르는 머신러닝의 5가지 학교
Jun 05, 2024 pm 08:51 PM
당신이 모르는 머신러닝의 5가지 학교
Jun 05, 2024 pm 08:51 PM
머신 러닝은 명시적으로 프로그래밍하지 않고도 컴퓨터가 데이터로부터 학습하고 능력을 향상시킬 수 있는 능력을 제공하는 인공 지능의 중요한 분야입니다. 머신러닝은 이미지 인식, 자연어 처리, 추천 시스템, 사기 탐지 등 다양한 분야에서 폭넓게 활용되며 우리의 삶의 방식을 변화시키고 있습니다. 기계 학습 분야에는 다양한 방법과 이론이 있으며, 그 중 가장 영향력 있는 5가지 방법을 "기계 학습의 5개 학교"라고 합니다. 5개 주요 학파는 상징학파, 연결주의 학파, 진화학파, 베이지안 학파, 유추학파이다. 1. 상징주의라고도 알려진 상징주의는 논리적 추론과 지식 표현을 위해 상징을 사용하는 것을 강조합니다. 이 사고 학교는 학습이 기존을 통한 역연역 과정이라고 믿습니다.
 SOTA 성능, 샤먼 다중 모드 단백질-리간드 친화성 예측 AI 방법, 최초로 분자 표면 정보 결합
Jul 17, 2024 pm 06:37 PM
SOTA 성능, 샤먼 다중 모드 단백질-리간드 친화성 예측 AI 방법, 최초로 분자 표면 정보 결합
Jul 17, 2024 pm 06:37 PM
Editor | KX 약물 연구 및 개발 분야에서 단백질과 리간드의 결합 친화도를 정확하고 효과적으로 예측하는 것은 약물 스크리닝 및 최적화에 매우 중요합니다. 그러나 현재 연구에서는 단백질-리간드 상호작용에서 분자 표면 정보의 중요한 역할을 고려하지 않습니다. 이를 기반으로 Xiamen University의 연구자들은 처음으로 단백질 표면, 3D 구조 및 서열에 대한 정보를 결합하고 교차 주의 메커니즘을 사용하여 다양한 양식 특징을 비교하는 새로운 다중 모드 특징 추출(MFE) 프레임워크를 제안했습니다. 조정. 실험 결과는 이 방법이 단백질-리간드 결합 친화도를 예측하는 데 있어 최첨단 성능을 달성한다는 것을 보여줍니다. 또한 절제 연구는 이 프레임워크 내에서 단백질 표면 정보와 다중 모드 기능 정렬의 효율성과 필요성을 보여줍니다. 관련 연구는 "S"로 시작된다
