

PyTorch를 사용하여 혼합 전문가 모델(MoE) 구현

Mixtral 8x7B의 출시는 개방형 AI 분야, 특히 모두에게 잘 알려진 MoE(Mixture-of-Experts) 개념에서 광범위한 관심을 끌었습니다. MoE(Hybrid Expertise) 개념은 협업 지능을 상징하며 전체가 부분의 합보다 크다는 생각을 구현합니다. MoE 모델은 여러 전문가 모델의 장점을 통합하여 보다 정확한 예측을 제공합니다. 이는 게이트 네트워크와 전문가 네트워크 세트로 구성되며, 각 전문가 네트워크는 특정 작업의 다양한 측면을 처리하는 데 능숙합니다. MoE 모델은 작업과 가중치를 적절하게 할당함으로써 전문가의 전문 지식을 활용하여 전반적인 예측 성능을 향상시킬 수 있습니다. 이 협업 지능형 모델은 AI 분야 개발에 새로운 혁신을 가져왔으며 향후 응용 분야에서 중요한 역할을 할 것입니다.
이 기사에서는 PyTorch를 사용하여 MoE 모델을 구현합니다. 구체적인 코드를 소개하기에 앞서 하이브리드 전문가의 아키텍처에 대해 간략히 소개하겠습니다.
MoE 아키텍처
MoE는 (1) 전문가 네트워크와 (2) 게이트 네트워크의 두 가지 유형의 네트워크로 구성됩니다.
Expert Network는 데이터 하위 집합에서 우수한 성능을 발휘하는 독점 모델을 사용하는 방법입니다. 핵심 개념은 문제에 대한 포괄적인 솔루션을 보장하기 위해 보완적인 강점을 가진 여러 전문가를 통해 문제 공간을 다루는 것입니다. 각 전문가 모델은 고유한 기능과 경험으로 교육되어 전반적인 시스템 성능과 효율성이 향상됩니다. 전문가 네트워크를 활용하면 복잡한 작업과 요구 사항을 효과적으로 처리하고 더 나은 솔루션을 제공할 수 있습니다.
게이트 네트워크는 전문가의 기여를 지시, 조정 또는 관리하는 데 사용되는 네트워크입니다. 다양한 유형의 입력에 대해 다양한 네트워크의 기능을 학습하고 평가하여 특정 입력을 처리하는 데 가장 적합한 네트워크를 결정합니다. 잘 훈련된 게이팅 네트워크는 새로운 입력 벡터를 평가하고 숙련도에 따라 가장 적절한 전문가 또는 전문가 조합에 처리 작업을 할당할 수 있습니다. 게이팅 네트워크는 전문가의 출력과 현재 입력의 관련성에 따라 가중치를 동적으로 조정하여 개인화된 응답을 보장합니다. 가중치를 동적으로 조정하는 이 메커니즘을 통해 게이팅 네트워크가 다양한 상황과 요구 사항에 유연하게 적응할 수 있습니다.
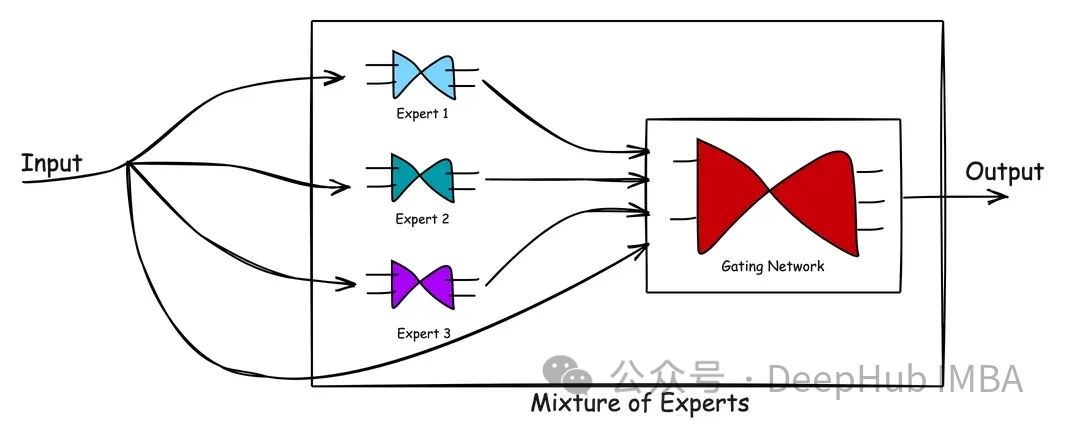
위 그림은 MoE의 처리 흐름을 보여줍니다. 혼합 전문가 모델의 장점은 단순성입니다. 문제를 해결하는 동안 복잡한 문제 공간과 전문가의 반응을 학습함으로써 MoE 모델은 단일 전문가보다 더 나은 솔루션을 생성하는 데 도움이 됩니다. Gating Network는 시나리오를 평가하고 최고의 전문가에게 작업을 전달하는 효과적인 관리자 역할을 합니다. 새로운 데이터가 입력되면 모델은 새로운 입력에 대한 전문가의 강점을 재평가하여 적응할 수 있으므로 유연한 학습 접근 방식이 가능해집니다. 즉, MoE 모델은 여러 전문가의 지식과 경험을 활용하여 복잡한 문제를 해결합니다. 게이트형 네트워크 관리를 통해 모델은 다양한 시나리오에 따라 작업을 처리하는 데 가장 적합한 전문가를 선택할 수 있습니다. 이 접근 방식의 장점은 단일 전문가보다 더 나은 솔루션을 생성할 수 있는 능력과 새로운 입력 데이터에 적응할 수 있는 유연성입니다. 전반적으로 MoE 모델은 다양하고 복잡한 문제를 해결하는 데 사용할 수 있는 효과적이고 간단한 방법입니다.
MoE는 기계 학습 모델 배포에 큰 이점을 제공합니다. 여기에는 두 가지 주목할만한 이점이 있습니다.
MoE의 핵심 강점은 다양하고 전문적인 전문가 네트워크에 있습니다. MoE의 설정은 단일 모델로는 달성하기 어려운 여러 분야의 문제를 높은 정확도로 처리할 수 있습니다.
MoE는 본질적으로 확장 가능합니다. 작업 복잡성이 증가함에 따라 더 많은 전문가가 시스템에 원활하게 통합되어 다른 전문가 모델을 변경할 필요 없이 전문 지식의 범위를 확장할 수 있습니다. 즉, MoE는 사전 교육을 받은 전문가를 기계 학습 시스템에 패키지하여 시스템이 증가하는 작업 요구 사항에 대처할 수 있도록 도울 수 있습니다.
혼합 전문가 모델은 추천 시스템, 언어 모델링, 다양하고 복잡한 예측 작업을 비롯한 다양한 분야에 적용됩니다. GPT-4가 다수의 전문가로 구성되어 있다는 소문이 돌고 있다. 확인할 수는 없지만 gpt-4와 같은 모델은 MoE 접근 방식을 통해 여러 모델의 기능을 활용하여 최상의 결과를 제공합니다.
Pytorch code
여기에서는 Mixtral 8x7B와 같은 대형 모델에 사용되는 MOE 기술을 논의하지 않고 대신 모든 작업에 적용할 수 있는 간단한 사용자 정의 MOE를 작성합니다. code MOE의 작동 원리는 MOE가 대형 모델에서 어떻게 작동하는지 이해하는 데 매우 도움이 됩니다.
아래에서는 PyTorch의 코드 구현을 하나씩 소개하겠습니다.
라이브러리 가져오기:
import torch import torch.nn as nn import torch.optim as optim
전문가 모델 정의:
class Expert(nn.Module): def __init__(self, input_dim, hidden_dim, output_dim): super(Expert, self).__init__() self.layer1 = nn.Linear(input_dim, hidden_dim) self.layer2 = nn.Linear(hidden_dim, output_dim) def forward(self, x): x = torch.relu(self.layer1(x)) return torch.softmax(self.layer2(x), dim=1)
여기서 간단한 전문가 모델을 정의합니다. Relu 활성화를 사용하고 마지막으로 소프트맥스 출력을 사용하는 2계층 MLP임을 알 수 있습니다. 분류 확률.
게이트 모델 정의:
# Define the gating model class Gating(nn.Module): def __init__(self, input_dim,num_experts, dropout_rate=0.1): super(Gating, self).__init__() # Layers self.layer1 = nn.Linear(input_dim, 128) self.dropout1 = nn.Dropout(dropout_rate) self.layer2 = nn.Linear(128, 256) self.leaky_relu1 = nn.LeakyReLU() self.dropout2 = nn.Dropout(dropout_rate) self.layer3 = nn.Linear(256, 128) self.leaky_relu2 = nn.LeakyReLU() self.dropout3 = nn.Dropout(dropout_rate) self.layer4 = nn.Linear(128, num_experts) def forward(self, x): x = torch.relu(self.layer1(x)) x = self.dropout1(x) x = self.layer2(x) x = self.leaky_relu1(x) x = self.dropout2(x) x = self.layer3(x) x = self.leaky_relu2(x) x = self.dropout3(x) return torch.softmax(self.layer4(x), dim=1)
门控模型更复杂,有三个线性层和dropout层用于正则化以防止过拟合。它使用ReLU和LeakyReLU激活函数引入非线性。最后一层的输出大小等于专家的数量,并对这些输出应用softmax函数。输出权重,这样可以将专家的输出与之结合。
说明:其实门控网络,或者叫路由网络是MOE中最复杂的部分,因为它涉及到控制输入到那个专家模型,所以门控网络也有很多个设计方案,例如(如果我没记错的话)Mixtral 8x7B 只是取了8个专家中的top2。所以我们这里不详细讨论各种方案,只是介绍其基本原理和代码实现。
完整的MOE模型:
class MoE(nn.Module): def __init__(self, trained_experts): super(MoE, self).__init__() self.experts = nn.ModuleList(trained_experts) num_experts = len(trained_experts) # Assuming all experts have the same input dimension input_dim = trained_experts[0].layer1.in_features self.gating = Gating(input_dim, num_experts) def forward(self, x): # Get the weights from the gating network weights = self.gating(x) # Calculate the expert outputs outputs = torch.stack([expert(x) for expert in self.experts], dim=2) # Adjust the weights tensor shape to match the expert outputs weights = weights.unsqueeze(1).expand_as(outputs) # Multiply the expert outputs with the weights and # sum along the third dimension return torch.sum(outputs * weights, dim=2)
这里主要看前向传播的代码,通过输入计算出权重和每个专家给出输出的预测,最后使用权重将所有专家的结果求和最终得到模型的输出。
这个是不是有点像“集成学习”。
测试
下面我们来对我们的实现做个简单的测试,首先生成一个简单的数据集:
# Generate the dataset num_samples = 5000 input_dim = 4 hidden_dim = 32 # Generate equal numbers of labels 0, 1, and 2 y_data = torch.cat([ torch.zeros(num_samples // 3), torch.ones(num_samples // 3), torch.full((num_samples - 2 * (num_samples // 3),), 2)# Filling the remaining to ensure exact num_samples ]).long() # Biasing the data based on the labels x_data = torch.randn(num_samples, input_dim) for i in range(num_samples): if y_data[i] == 0: x_data[i, 0] += 1# Making x[0] more positive elif y_data[i] == 1: x_data[i, 1] -= 1# Making x[1] more negative elif y_data[i] == 2: x_data[i, 0] -= 1# Making x[0] more negative # Shuffle the data to randomize the order indices = torch.randperm(num_samples) x_data = x_data[indices] y_data = y_data[indices] # Verify the label distribution y_data.bincount() # Shuffle the data to ensure x_data and y_data remain aligned shuffled_indices = torch.randperm(num_samples) x_data = x_data[shuffled_indices] y_data = y_data[shuffled_indices] # Splitting data for training individual experts # Use the first half samples for training individual experts x_train_experts = x_data[:int(num_samples/2)] y_train_experts = y_data[:int(num_samples/2)] mask_expert1 = (y_train_experts == 0) | (y_train_experts == 1) mask_expert2 = (y_train_experts == 1) | (y_train_experts == 2) mask_expert3 = (y_train_experts == 0) | (y_train_experts == 2) # Select an almost equal number of samples for each expert num_samples_per_expert = \ min(mask_expert1.sum(), mask_expert2.sum(), mask_expert3.sum()) x_expert1 = x_train_experts[mask_expert1][:num_samples_per_expert] y_expert1 = y_train_experts[mask_expert1][:num_samples_per_expert] x_expert2 = x_train_experts[mask_expert2][:num_samples_per_expert] y_expert2 = y_train_experts[mask_expert2][:num_samples_per_expert] x_expert3 = x_train_experts[mask_expert3][:num_samples_per_expert] y_expert3 = y_train_experts[mask_expert3][:num_samples_per_expert] # Splitting the next half samples for training MoE model and for testing x_remaining = x_data[int(num_samples/2)+1:] y_remaining = y_data[int(num_samples/2)+1:] split = int(0.8 * len(x_remaining)) x_train_moe = x_remaining[:split] y_train_moe = y_remaining[:split] x_test = x_remaining[split:] y_test = y_remaining[split:] print(x_train_moe.shape,"\n", x_test.shape,"\n", x_expert1.shape,"\n", x_expert2.shape,"\n", x_expert3.shape)
这段代码创建了一个合成数据集,其中包含三个类标签——0、1和2。基于类标签对特征进行操作,从而在数据中引入一些模型可以学习的结构。
数据被分成针对个别专家的训练集、MoE模型和测试集。我们确保专家模型是在一个子集上训练的,这样第一个专家在标签0和1上得到很好的训练,第二个专家在标签1和2上得到更好的训练,第三个专家看到更多的标签2和0。
我们期望的结果是:虽然每个专家对标签0、1和2的分类准确率都不令人满意,但通过结合三位专家的决策,MoE将表现出色。
模型初始化和训练设置:
# Define hidden dimension output_dim = 3 hidden_dim = 32 epochs = 500 learning_rate = 0.001 # Instantiate the experts expert1 = Expert(input_dim, hidden_dim, output_dim) expert2 = Expert(input_dim, hidden_dim, output_dim) expert3 = Expert(input_dim, hidden_dim, output_dim) # Set up loss criterion = nn.CrossEntropyLoss() # Optimizers for experts optimizer_expert1 = optim.Adam(expert1.parameters(), lr=learning_rate) optimizer_expert2 = optim.Adam(expert2.parameters(), lr=learning_rate) optimizer_expert3 = optim.Adam(expert3.parameters(), lr=learning_rate)
实例化了专家模型和MoE模型。定义损失函数来计算训练损失,并为每个模型设置优化器,在训练过程中执行权重更新。
训练的步骤也非常简单
# Training loop for expert 1 for epoch in range(epochs):optimizer_expert1.zero_grad()outputs_expert1 = expert1(x_expert1)loss_expert1 = criterion(outputs_expert1, y_expert1)loss_expert1.backward()optimizer_expert1.step() # Training loop for expert 2 for epoch in range(epochs):optimizer_expert2.zero_grad()outputs_expert2 = expert2(x_expert2)loss_expert2 = criterion(outputs_expert2, y_expert2)loss_expert2.backward()optimizer_expert2.step() # Training loop for expert 3 for epoch in range(epochs):optimizer_expert3.zero_grad()outputs_expert3 = expert3(x_expert3)loss_expert3 = criterion(outputs_expert3, y_expert3)loss_expert3.backward()
每个专家使用基本的训练循环在不同的数据子集上进行单独的训练。循环迭代指定数量的epoch。
下面是我们MOE的训练
# Create the MoE model with the trained experts moe_model = MoE([expert1, expert2, expert3]) # Train the MoE model optimizer_moe = optim.Adam(moe_model.parameters(), lr=learning_rate) for epoch in range(epochs):optimizer_moe.zero_grad()outputs_moe = moe_model(x_train_moe)loss_moe = criterion(outputs_moe, y_train_moe)loss_moe.backward()optimizer_moe.step()
MoE模型是由先前训练过的专家创建的,然后在单独的数据集上进行训练。训练过程类似于单个专家的训练,但现在门控网络的权值在训练过程中更新。
最后我们的评估函数:
# Evaluate all models def evaluate(model, x, y):with torch.no_grad():outputs = model(x)_, predicted = torch.max(outputs, 1)correct = (predicted == y).sum().item()accuracy = correct / len(y)return accuracy
evaluate函数计算模型在给定数据上的精度(x代表样本,y代表预期标签)。准确度计算为正确预测数与预测总数之比。
结果如下:
accuracy_expert1 = evaluate(expert1, x_test, y_test) accuracy_expert2 = evaluate(expert2, x_test, y_test) accuracy_expert3 = evaluate(expert3, x_test, y_test) accuracy_moe = evaluate(moe_model, x_test, y_test) print("Expert 1 Accuracy:", accuracy_expert1) print("Expert 2 Accuracy:", accuracy_expert2) print("Expert 3 Accuracy:", accuracy_expert3) print("Mixture of Experts Accuracy:", accuracy_moe) #Expert 1 Accuracy: 0.466 #Expert 2 Accuracy: 0.496 #Expert 3 Accuracy: 0.378 #Mixture of Experts Accuracy: 0.614可以看到
专家1正确预测了测试数据集中大约46.6%的样本的类标签。
专家2表现稍好,正确预测率约为49.6%。
专家3在三位专家中准确率最低,正确预测的样本约为37.8%。
而MoE模型显著优于每个专家,总体准确率约为61.4%。
总结
我们测试的输出结果显示了混合专家模型的强大功能。该模型通过门控网络将各个专家模型的优势结合起来,取得了比单个专家模型更高的精度。门控网络有效地学习了如何根据输入数据权衡每个专家的贡献,以产生更准确的预测。混合专家利用了各个模型的不同专业知识,在测试数据集上提供了更好的性能。
同时也说明我们可以在现有的任务上尝试使用MOE来进行测试,也可以得到更好的结果。
위 내용은 PyTorch를 사용하여 혼합 전문가 모델(MoE) 구현의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7504
7504
 15
1378
52
78
11
52
19
19
55
15
1378
52
78
11
52
19
19
55

 Bytedance Cutting, SVIP 슈퍼 멤버십 출시: 연간 연속 구독료 499위안, 다양한 AI 기능 제공
Jun 28, 2024 am 03:51 AM
Bytedance Cutting, SVIP 슈퍼 멤버십 출시: 연간 연속 구독료 499위안, 다양한 AI 기능 제공
Jun 28, 2024 am 03:51 AM
이 사이트는 6월 27일에 Jianying이 ByteDance의 자회사인 FaceMeng Technology에서 개발한 비디오 편집 소프트웨어라고 보도했습니다. 이 소프트웨어는 Douyin 플랫폼을 기반으로 하며 기본적으로 플랫폼 사용자를 위한 짧은 비디오 콘텐츠를 제작합니다. Windows, MacOS 및 기타 운영 체제. Jianying은 멤버십 시스템 업그레이드를 공식 발표하고 지능형 번역, 지능형 하이라이트, 지능형 패키징, 디지털 인간 합성 등 다양한 AI 블랙 기술을 포함하는 새로운 SVIP를 출시했습니다. 가격면에서 SVIP 클리핑 월 요금은 79위안, 연간 요금은 599위안(본 사이트 참고: 월 49.9위안에 해당), 월간 연속 구독료는 월 59위안, 연간 연속 구독료는 59위안입니다. 연간 499위안(월 41.6위안)입니다. 또한, 컷 관계자는 "사용자 경험 향상을 위해 기존 VIP에 가입하신 분들도
 Rag 및 Sem-Rag를 사용한 상황 증강 AI 코딩 도우미
Jun 10, 2024 am 11:08 AM
Rag 및 Sem-Rag를 사용한 상황 증강 AI 코딩 도우미
Jun 10, 2024 am 11:08 AM
검색 강화 생성 및 의미론적 메모리를 AI 코딩 도우미에 통합하여 개발자 생산성, 효율성 및 정확성을 향상시킵니다. EnhancingAICodingAssistantswithContextUsingRAGandSEM-RAG에서 번역됨, 저자 JanakiramMSV. 기본 AI 프로그래밍 도우미는 자연스럽게 도움이 되지만, 소프트웨어 언어에 대한 일반적인 이해와 소프트웨어 작성의 가장 일반적인 패턴에 의존하기 때문에 가장 관련성이 높고 정확한 코드 제안을 제공하지 못하는 경우가 많습니다. 이러한 코딩 도우미가 생성한 코드는 자신이 해결해야 할 문제를 해결하는 데 적합하지만 개별 팀의 코딩 표준, 규칙 및 스타일을 따르지 않는 경우가 많습니다. 이로 인해 코드가 애플리케이션에 승인되기 위해 수정되거나 개선되어야 하는 제안이 나타나는 경우가 많습니다.
 미세 조정을 통해 LLM이 실제로 새로운 것을 배울 수 있습니까? 새로운 지식을 도입하면 모델이 더 많은 환각을 생성할 수 있습니다.
Jun 11, 2024 pm 03:57 PM
미세 조정을 통해 LLM이 실제로 새로운 것을 배울 수 있습니까? 새로운 지식을 도입하면 모델이 더 많은 환각을 생성할 수 있습니다.
Jun 11, 2024 pm 03:57 PM
LLM(대형 언어 모델)은 대규모 텍스트 데이터베이스에서 훈련되어 대량의 실제 지식을 습득합니다. 이 지식은 매개변수에 내장되어 필요할 때 사용할 수 있습니다. 이러한 모델에 대한 지식은 훈련이 끝나면 "구체화"됩니다. 사전 훈련이 끝나면 모델은 실제로 학습을 중단합니다. 모델을 정렬하거나 미세 조정하여 이 지식을 활용하고 사용자 질문에 보다 자연스럽게 응답하는 방법을 알아보세요. 그러나 때로는 모델 지식만으로는 충분하지 않을 때도 있으며, 모델이 RAG를 통해 외부 콘텐츠에 접근할 수 있더라도 미세 조정을 통해 모델을 새로운 도메인에 적응시키는 것이 유익한 것으로 간주됩니다. 이러한 미세 조정은 인간 주석 작성자 또는 기타 LLM 생성자의 입력을 사용하여 수행됩니다. 여기서 모델은 추가적인 실제 지식을 접하고 이를 통합합니다.
 7가지 멋진 GenAI 및 LLM 기술 인터뷰 질문
Jun 07, 2024 am 10:06 AM
7가지 멋진 GenAI 및 LLM 기술 인터뷰 질문
Jun 07, 2024 am 10:06 AM
AIGC에 대해 자세히 알아보려면 다음을 방문하세요. 51CTOAI.x 커뮤니티 https://www.51cto.com/aigc/Translator|Jingyan Reviewer|Chonglou는 인터넷 어디에서나 볼 수 있는 전통적인 문제 은행과 다릅니다. 고정관념에서 벗어나 생각해야 합니다. LLM(대형 언어 모델)은 데이터 과학, 생성 인공 지능(GenAI) 및 인공 지능 분야에서 점점 더 중요해지고 있습니다. 이러한 복잡한 알고리즘은 인간의 기술을 향상시키고 많은 산업 분야에서 효율성과 혁신을 촉진하여 기업이 경쟁력을 유지하는 데 핵심이 됩니다. LLM은 자연어 처리, 텍스트 생성, 음성 인식 및 추천 시스템과 같은 분야에서 광범위하게 사용될 수 있습니다. LLM은 대량의 데이터로부터 학습하여 텍스트를 생성할 수 있습니다.
 대형 모델에 대한 새로운 과학적이고 복잡한 질문 답변 벤치마크 및 평가 시스템을 제공하기 위해 UNSW, Argonne, University of Chicago 및 기타 기관이 공동으로 SciQAG 프레임워크를 출시했습니다.
Jul 25, 2024 am 06:42 AM
대형 모델에 대한 새로운 과학적이고 복잡한 질문 답변 벤치마크 및 평가 시스템을 제공하기 위해 UNSW, Argonne, University of Chicago 및 기타 기관이 공동으로 SciQAG 프레임워크를 출시했습니다.
Jul 25, 2024 am 06:42 AM
편집자 |ScienceAI 질문 응답(QA) 데이터 세트는 자연어 처리(NLP) 연구를 촉진하는 데 중요한 역할을 합니다. 고품질 QA 데이터 세트는 모델을 미세 조정하는 데 사용될 수 있을 뿐만 아니라 LLM(대형 언어 모델)의 기능, 특히 과학적 지식을 이해하고 추론하는 능력을 효과적으로 평가하는 데에도 사용할 수 있습니다. 현재 의학, 화학, 생물학 및 기타 분야를 포괄하는 과학적인 QA 데이터 세트가 많이 있지만 이러한 데이터 세트에는 여전히 몇 가지 단점이 있습니다. 첫째, 데이터 형식이 비교적 단순하고 대부분이 객관식 질문이므로 평가하기 쉽지만 모델의 답변 선택 범위가 제한되고 모델의 과학적 질문 답변 능력을 완전히 테스트할 수 없습니다. 이에 비해 개방형 Q&A는
 당신이 모르는 머신러닝의 5가지 학교
Jun 05, 2024 pm 08:51 PM
당신이 모르는 머신러닝의 5가지 학교
Jun 05, 2024 pm 08:51 PM
머신 러닝은 명시적으로 프로그래밍하지 않고도 컴퓨터가 데이터로부터 학습하고 능력을 향상시킬 수 있는 능력을 제공하는 인공 지능의 중요한 분야입니다. 머신러닝은 이미지 인식, 자연어 처리, 추천 시스템, 사기 탐지 등 다양한 분야에서 폭넓게 활용되며 우리의 삶의 방식을 변화시키고 있습니다. 기계 학습 분야에는 다양한 방법과 이론이 있으며, 그 중 가장 영향력 있는 5가지 방법을 "기계 학습의 5개 학교"라고 합니다. 5개 주요 학파는 상징학파, 연결주의 학파, 진화학파, 베이지안 학파, 유추학파이다. 1. 상징주의라고도 알려진 상징주의는 논리적 추론과 지식 표현을 위해 상징을 사용하는 것을 강조합니다. 이 사고 학교는 학습이 기존을 통한 역연역 과정이라고 믿습니다.
 PRO | MoE 기반의 대형 모델이 더 주목받는 이유는 무엇인가요?
Aug 07, 2024 pm 07:08 PM
PRO | MoE 기반의 대형 모델이 더 주목받는 이유는 무엇인가요?
Aug 07, 2024 pm 07:08 PM
2023년에는 AI의 거의 모든 분야가 전례 없는 속도로 진화하고 있다. 동시에 AI는 구체화된 지능, 자율주행 등 핵심 트랙의 기술적 한계를 지속적으로 확장하고 있다. 멀티모달 추세 하에서 AI 대형 모델의 주류 아키텍처인 Transformer의 상황이 흔들릴까요? MoE(Mixed of Experts) 아키텍처를 기반으로 한 대형 모델 탐색이 업계에서 새로운 트렌드가 된 이유는 무엇입니까? 대형 비전 모델(LVM)이 일반 비전 분야에서 새로운 돌파구가 될 수 있습니까? ...지난 6개월 동안 공개된 본 사이트의 2023 PRO 회원 뉴스레터에서 위 분야의 기술 동향과 산업 변화에 대한 심층 분석을 제공하여 새로운 환경에서 귀하의 목표 달성에 도움이 되는 10가지 특별 해석을 선택했습니다. 년. 준비하세요. 이 해석은 2023년 50주차에 나온 것입니다.
 SOTA 성능, 샤먼 다중 모드 단백질-리간드 친화성 예측 AI 방법, 최초로 분자 표면 정보 결합
Jul 17, 2024 pm 06:37 PM
SOTA 성능, 샤먼 다중 모드 단백질-리간드 친화성 예측 AI 방법, 최초로 분자 표면 정보 결합
Jul 17, 2024 pm 06:37 PM
Editor | KX 약물 연구 및 개발 분야에서 단백질과 리간드의 결합 친화도를 정확하고 효과적으로 예측하는 것은 약물 스크리닝 및 최적화에 매우 중요합니다. 그러나 현재 연구에서는 단백질-리간드 상호작용에서 분자 표면 정보의 중요한 역할을 고려하지 않습니다. 이를 기반으로 Xiamen University의 연구자들은 처음으로 단백질 표면, 3D 구조 및 서열에 대한 정보를 결합하고 교차 주의 메커니즘을 사용하여 다양한 양식 특징을 비교하는 새로운 다중 모드 특징 추출(MFE) 프레임워크를 제안했습니다. 조정. 실험 결과는 이 방법이 단백질-리간드 결합 친화도를 예측하는 데 있어 최첨단 성능을 달성한다는 것을 보여줍니다. 또한 절제 연구는 이 프레임워크 내에서 단백질 표면 정보와 다중 모드 기능 정렬의 효율성과 필요성을 보여줍니다. 관련 연구는 "S"로 시작된다
