
작성자: 왕동
CreditEase 기술 R&D 센터 설계자
테마 소개:
안녕하세요 여러분, 저는 CreditEase Technology R&D Center의 Wang Dong입니다. 처음으로 커뮤니티에 부족한 점이 있으면 지적해 주시고 양해해 주시기 바랍니다.
이 공유의 주제는 "로그 기반 DWS 플랫폼의 구현 및 적용"이며, 주로 CreditEase에서 현재 진행 중인 작업 중 일부를 공유합니다. 이 주제에는 두 팀의 많은 형제자매들의 노력의 결과(우리 팀과 Shanwei 팀의 결과)가 포함되어 있습니다. 이번에는 제가 대신해서 글을 써서 여러분께 소개할 수 있도록 최선을 다하겠습니다.
사실 전체 구현은 원칙적으로 비교적 간단하며, 물론 많은 기술도 필요합니다. 나는 모든 사람이 이 문제의 원리와 의의를 이해할 수 있도록 가능한 한 가장 간단한 방법으로 표현하려고 노력할 것입니다. 그 과정에서 궁금한 점이 있으시면 언제든지 질문해 주시면 최선을 다해 답변해 드리겠습니다.
DWS는 약어이며 3개의 하위 프로젝트로 구성되어 있는데 이에 대해서는 나중에 설명하겠습니다.
1. 배경문제는 얼마 전 회사의 요구에서 시작되었습니다. CreditEase가 인터넷 금융 회사라는 것은 누구나 알고 있습니다. 우리의 데이터는 일반적으로 다음과 같습니다.

과거에는 몇 가지 일반적인 관행이 있었습니다.
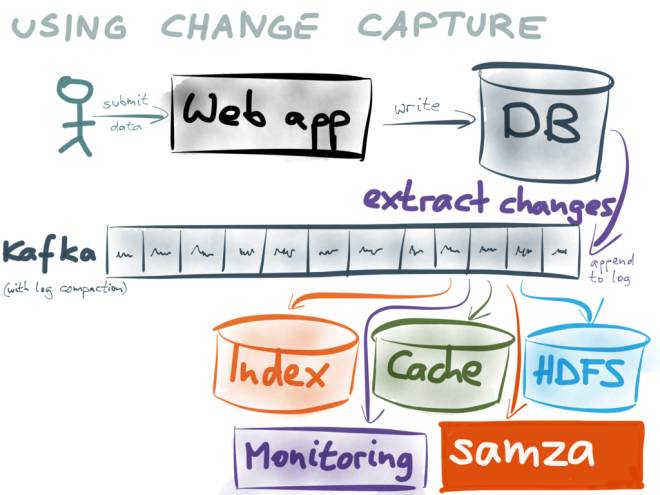
증분 로그를 모든 시스템의 기초로 사용하세요. 후속 데이터 사용자는 kafka를 구독하여 로그를 사용합니다.
예:
이중 쓰기를 사용하지 않는 이유는 무엇인가요? , https://www.confluent.io/blog/using-logs-to-build-a-solid-data-infrastructure-or-why-dual-writes-are-a-bad-idea/
를 참조하세요.
 여기서는 자세히 설명하지 않겠습니다.
여기서는 자세히 설명하지 않겠습니다.
그래서 우리는 로그를 기반으로 기업 차원의 플랫폼을 구축하자는 아이디어를 생각해 냈습니다.
다음은 DWS 플랫폼에 대한 설명입니다. DWS 플랫폼은 3개의 하위 프로젝트로 구성됩니다.
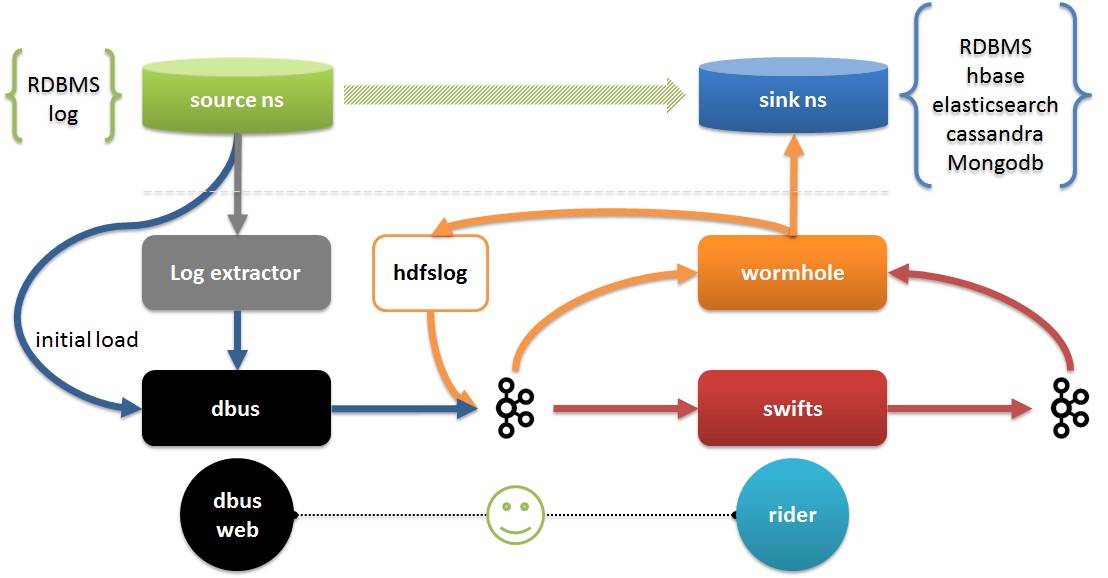 사진 속:
사진 속:
사진 출처: https://github.com/alibaba/canal
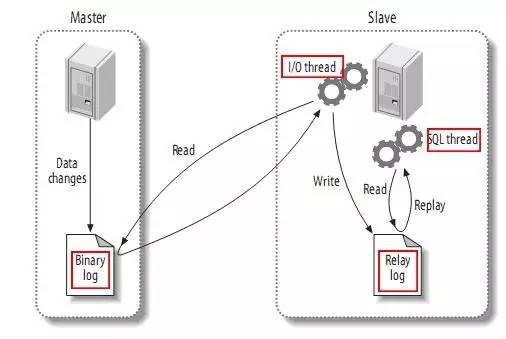 binlog에는 세 가지 모드가 있습니다:
binlog에는 세 가지 모드가 있습니다:
출처: http://www.jquerycn.cn/a_13625
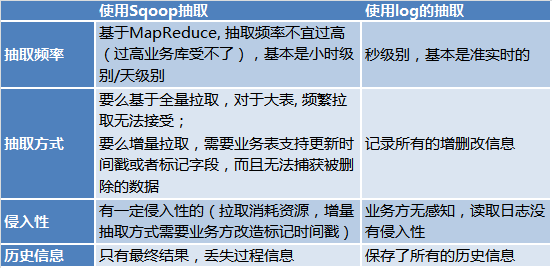
 Statement 모드의 단점으로 인해 DBA와의 커뮤니케이션 과정에서 실제 제작 과정에서 복제에 Row 모드가 사용된다는 사실을 알게 되었습니다. 이렇게 하면 전체 로그를 읽을 수 있습니다.
Statement 모드의 단점으로 인해 DBA와의 커뮤니케이션 과정에서 실제 제작 과정에서 복제에 Row 모드가 사용된다는 사실을 알게 되었습니다. 이렇게 하면 전체 로그를 읽을 수 있습니다.
일반적으로 우리의 MySQL 레이아웃은 마스터 데이터베이스(vip) 2개 + 슬레이브 데이터베이스 1개 + 백업 재해 복구 데이터베이스 1개로 구성된 솔루션입니다. 재해 복구 데이터베이스는 일반적으로 원격 재해 복구에 사용되므로 실시간 성능이 높지 않습니다. 배치하다, 파견하다.
소스 측에 미치는 영향을 최소화하려면 당연히 슬레이브 라이브러리에서 binlog 로그를 읽어야 합니다.
binlog를 읽을 수 있는 솔루션이 많이 있으며, github에도 많이 있습니다. https://github.com/search?utf8=%E2%9C%93&q=binlog를 참조하세요. 결국 우리는 로그 추출 방법으로 Alibaba의 운하를 선택했습니다.
Canal은 Alibaba의 중국과 미국 컴퓨터실을 동기화하는 데 처음 사용되었습니다. Canal의 원리는 비교적 간단합니다.
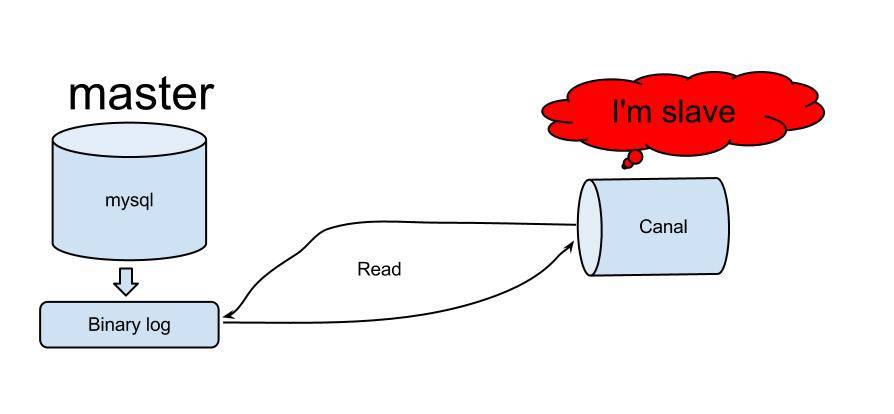
사진 출처: https://github.com/alibaba/canal
솔루션MySQL 버전 Dbus의 주요 솔루션은 다음과 같습니다.
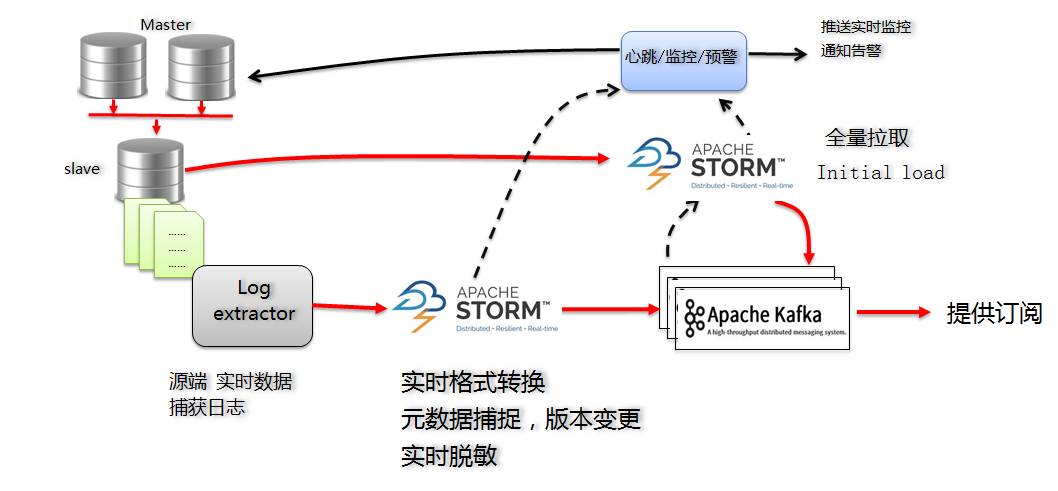
증분 로그의 경우 Canal Server에 가입하면 MySQL의 증분 로그를 얻을 수 있습니다.
Storm을 솔루션으로 사용할 때 주로 Storm의 장점은 다음과 같습니다.
초기 로드(첫 번째 로드)를 위해 jdbc 연결을 통해 원본 데이터베이스의 대기 데이터베이스에서 가져오는 전체 추출 Storm 프로그램도 개발했습니다. 초기 로드는 모든 데이터를 가져오는 것이므로 업무량이 적은 시간대에 수행하는 것이 좋습니다. 다행히도 한 번만 하면 되고 매일 할 필요는 없습니다.
전체 금액을 추출하려면 Sqoop의 아이디어를 활용하세요. Storm의 전체 추출은 두 부분으로 나뉩니다:
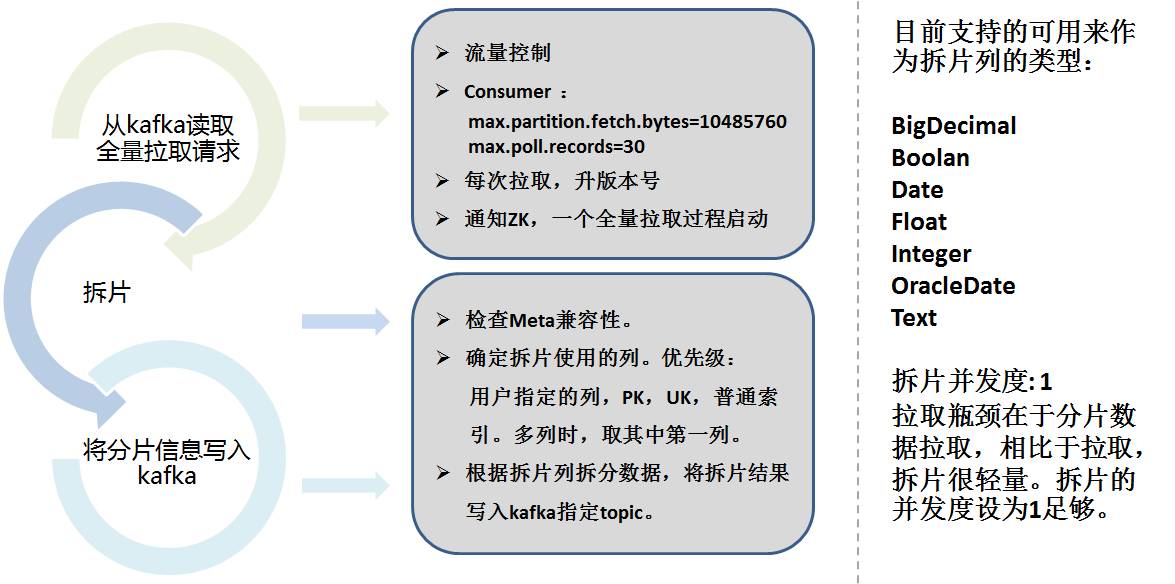
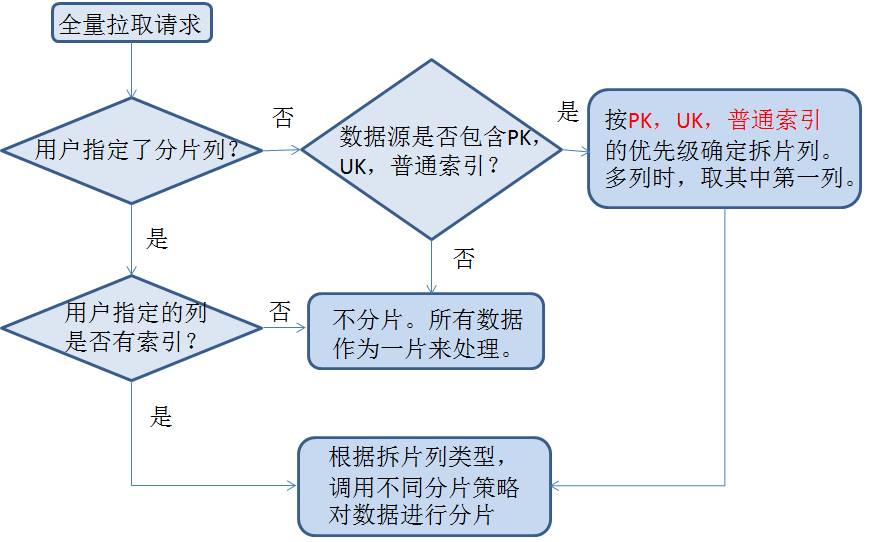
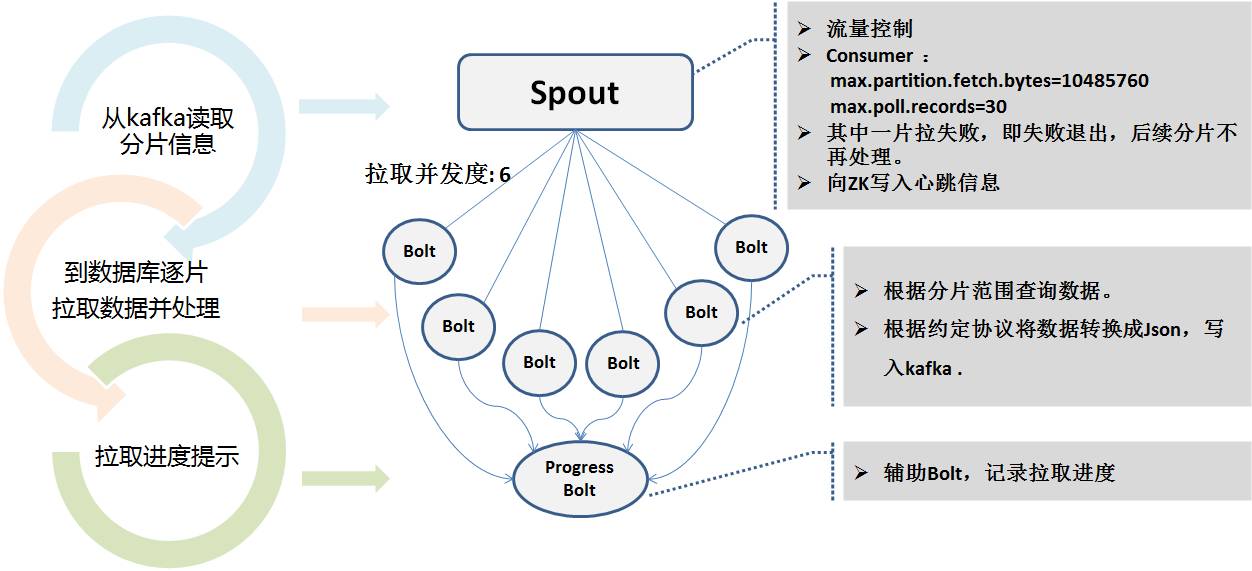
아래 그림과 같이:
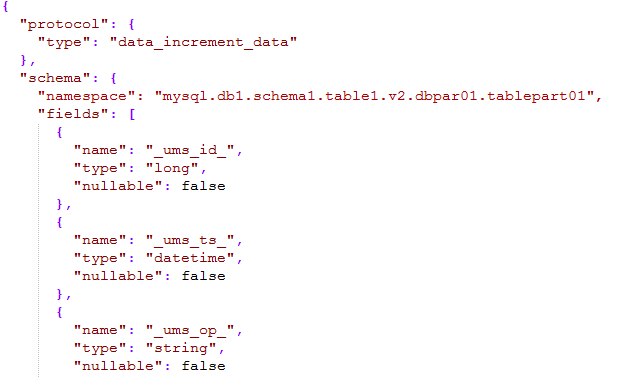

메시지의 스키마 부분은 네임스페이스를 정의하며, 이는 유형 + 데이터 소스 이름 + 스키마 이름 + 테이블 이름 + 버전 번호 + 하위 라이브러리 번호 + 하위 테이블 번호로 구성되며 회사 전체의 모든 테이블을 설명할 수 있습니다. 네임스페이스를 통해 고유하게 찾을 수 있습니다.
전체 볼륨과 증분 볼륨의 일관성
전체 데이터 전송에서 로그 메시지의 순서를 최대한 보장하기 위해 Kafka는 파티션 방식을 사용합니다. 일반적으로 기본적으로 순차적이고 고유합니다. 하지만 Kafka 작성은 실패하고 다시 작성될 수 있다는 점을 알고 있습니다. Storm도 다시 실행 메커니즘을 사용하므로 엄격히 한 번과 전체 시퀀스를 보장하지는 않지만 적어도 한 번은 보장합니다.그래서 _ums_id_가 특히 중요해집니다.
전체 추출의 경우 _ums_id_는 고유합니다. zk의 각 동시성 수준에서 서로 다른 ID 슬라이스를 가져오므로 고유성과 성능이 증분 데이터와 충돌하지 않고 증분 데이터보다 이전인지도 확인됩니다. 뉴스의 양.
증분 추출의 경우 MySQL의 로그 파일 번호 + 로그 오프셋을 고유 ID로 사용합니다. Id는 64비트의 긴 정수로 사용되며, 상위 7비트는 로그 파일 번호로, 하위 12비트는 로그 오프셋으로 사용된다.
예: 000103000012345678. 103은 로그 파일 번호이고 12345678은 로그 오프셋입니다.
이렇게 하면 로그 수준에서 물리적 고유성이 보장되고(다시 작성해도 ID 번호는 변경되지 않음) 순서도 보장됩니다(로그 위치도 찾을 수 있음). _ums_id_ 소비 로그를 비교하면 _ums_id_를 비교하여 어떤 메시지가 업데이트되는지 알 수 있습니다.
실제로 _ums_ts_와 _ums_id_의 의도는 비슷하지만 가끔 _ums_ts_가 반복될 수 있다는 점, 즉 1밀리초 안에 여러 작업이 발생할 수 있으므로 _ums_id_를 비교해야 합니다.
심장박동 모니터링 및 조기 경고
전체 시스템에는 데이터베이스, Canal Server, 다중 동시성 Storm 프로세스 및 기타 측면의 기본 및 백업 동기화가 포함됩니다. 따라서 프로세스를 모니터링하고 조기 경고하는 것이 특히 중요합니다.예를 들어 하트비트 모듈을 통해 추출된 각 테이블에 멘탈리티 데이터 조각을 매분마다 삽입하고(구성 가능) 전송 시간을 저장합니다. 이 하트비트 테이블도 추출되어 전체 프로세스를 따르는데 이는 실제로 동기화된 테이블과 동일합니다. 표의 논리(여러 개의 동시 Storm이 서로 다른 분기를 가질 수 있으므로), 하트비트 패킷이 수신되면 추가, 삭제 또는 수정된 데이터가 없더라도 전체 링크가 열려 있음을 증명할 수 있습니다.
Storm 프로그램과 heartbeat 프로그램은 공개된 통계 주제로 데이터를 보내고, 통계 프로그램은 이를 influxdb에 저장하여 표시하면 다음과 같은 효과를 볼 수 있습니다.
사진은 특정 업무 시스템의 실시간 모니터링 정보를 보여줍니다. 위는 실시간 교통상황이고, 아래는 실시간 지연상황입니다. 실시간 성능은 여전히 매우 좋은 것을 볼 수 있는데, 기본적으로 1~2초 안에 데이터가 단말 Kafka로 전송됐다.
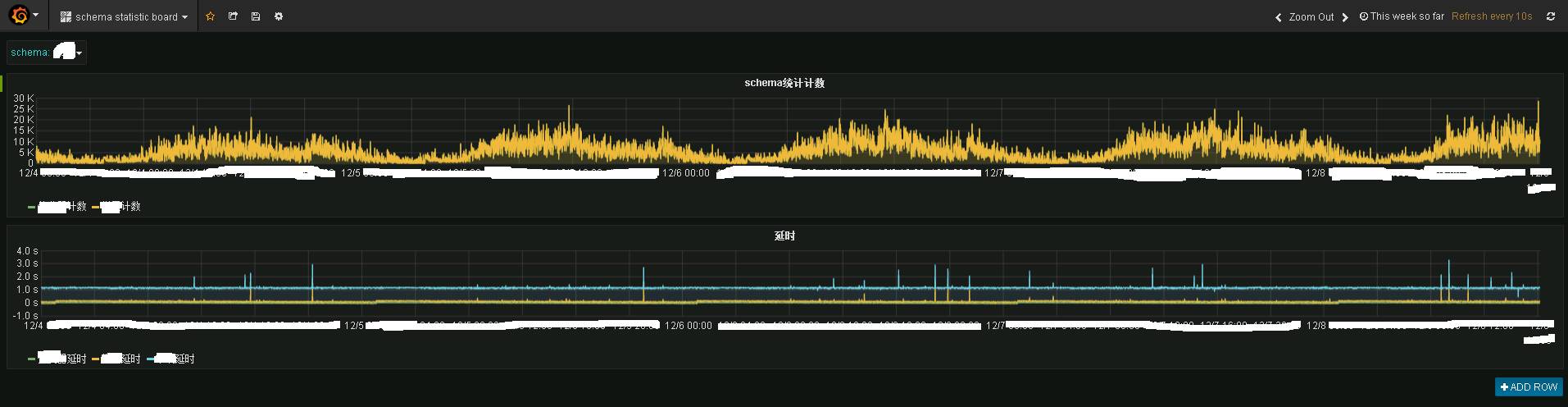 Granfana는 실시간 모니터링 기능을 제공합니다.
Granfana는 실시간 모니터링 기능을 제공합니다.
지연되는 경우 dbus의 하트비트 모듈을 통해 이메일 알람 또는 SMS 알람이 전송됩니다.
실시간 둔감화 데이터 보안을 고려하여 Dbus의 전체 폭풍 및 증분 폭풍 프로그램은 둔감화가 필요한 시나리오에 대한 실시간 둔감화 기능도 완료합니다. 둔감화에는 3가지 방법이 있습니다:요약하자면, Dbus는 다양한 소스에서 실시간으로 데이터를 내보내고 UMS 형식으로 구독을 제공하여 실시간 둔감화, 실제 모니터링 및 경보를 지원합니다.

가장 큰 이유 중 하나는 Kafka가 자연스러운 분리 기능을 갖고 있으며, 프로그램이 Kafka를 통해 비동기 메시지 전달을 직접 수행할 수 있기 때문입니다. Dbus와 Wornhole은 메시지 전달 및 분리를 위해 내부적으로 kafka를 사용합니다.
또 다른 이유는 UMS가 자기 설명적이라는 점입니다. kafka를 구독하면 능력 있는 사용자라면 누구나 직접 UMS를 소비하여 사용할 수 있습니다.
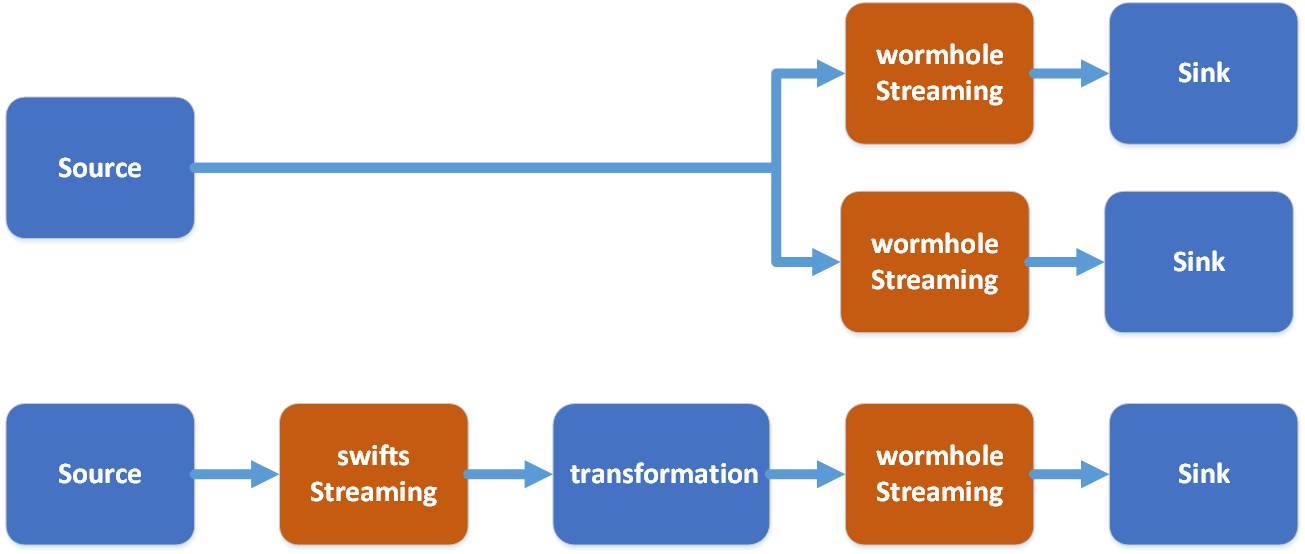
UMS의 결과를 직접 구독할 수는 있지만 여전히 개발 작업이 필요합니다. Wormhole이 해결하는 것은 Kafka의 데이터를 다양한 시스템에 구현할 수 있는 원클릭 구성을 제공하여 개발 능력이 없는 데이터 사용자가 Wormhole을 통해 데이터를 사용할 수 있도록 하는 것입니다.
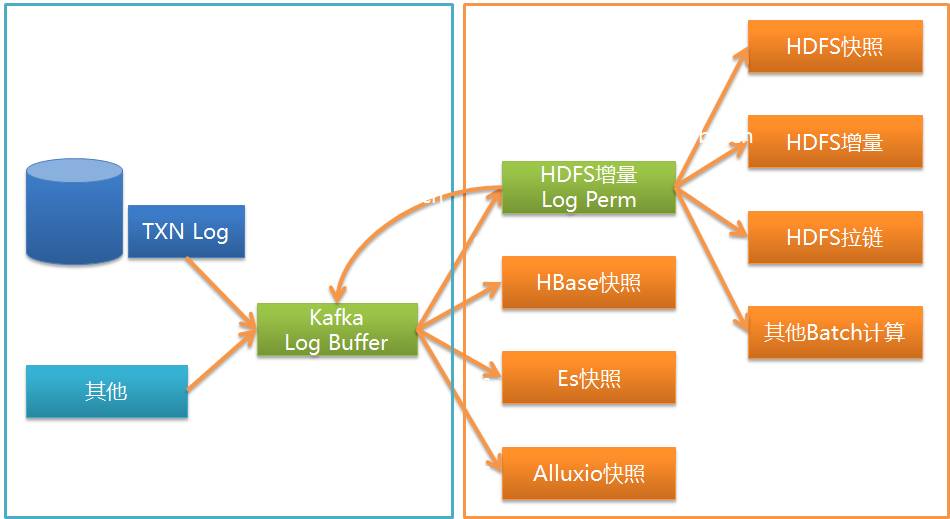
그림에서 볼 수 있듯이 Wormhole은 kafka의 UMS를 다양한 시스템에 구현할 수 있으며, 현재 가장 일반적으로 사용되는 것은 HDFS, JDBC 데이터베이스 및 HBase입니다.
기술 스택 측면에서 웜홀은 스파크 스트리밍을 사용하기로 선택합니다.
웜홀에서 흐름은 소스에서 타겟까지의 나마스페이스를 의미합니다. 하나의 스파크 스트리밍은 여러 흐름을 제공합니다.
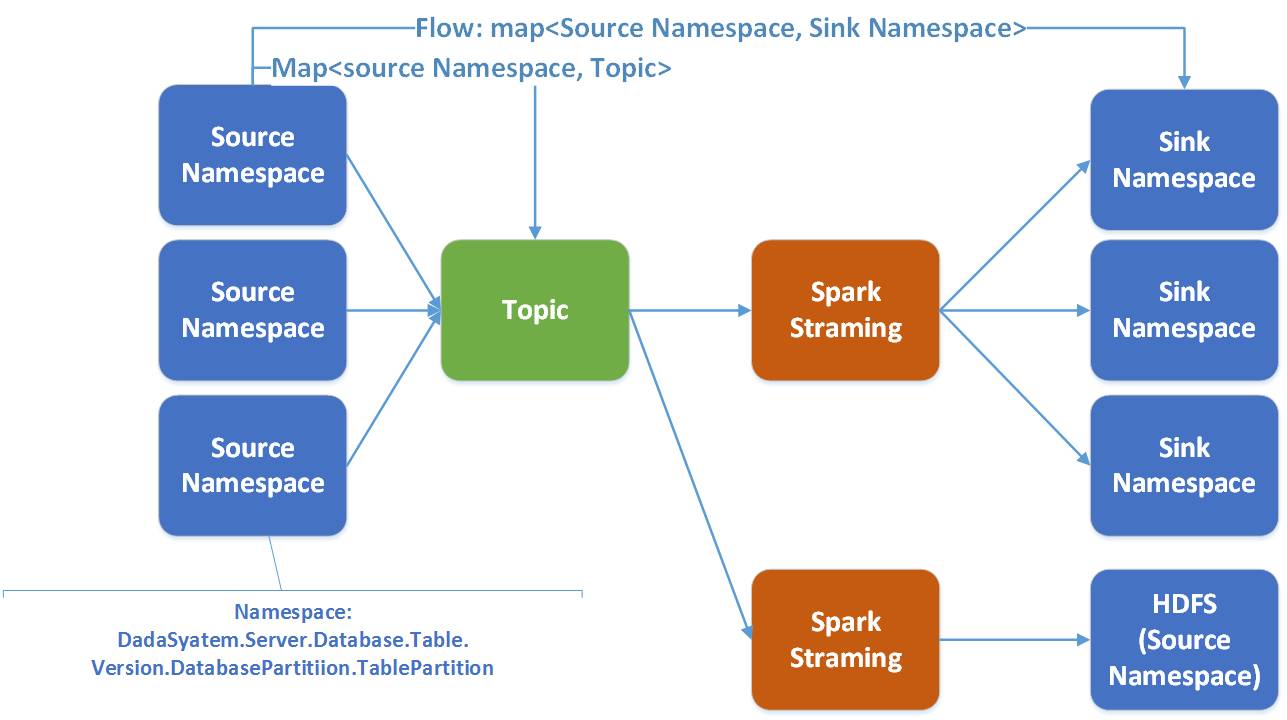
Spark를 선택해야 하는 이유는 다음과 같습니다.
 HDFS 삭제
HDFS 삭제
웜홀 스파크 스트리밍은 네임스페이스에 따라 데이터를 서로 다른 디렉터리에 배포하고 저장합니다. 즉, 서로 다른 테이블과 버전이 서로 다른 디렉터리에 배치됩니다.
매번 작성되는 Parquet 파일은 작은 파일이기 때문에 HDFS가 작은 파일에는 성능이 좋지 않다는 사실은 모두가 알고 있으므로 매일 정기적으로 이러한 Parquet 파일을 큰 파일로 병합하는 또 다른 작업이 있습니다.
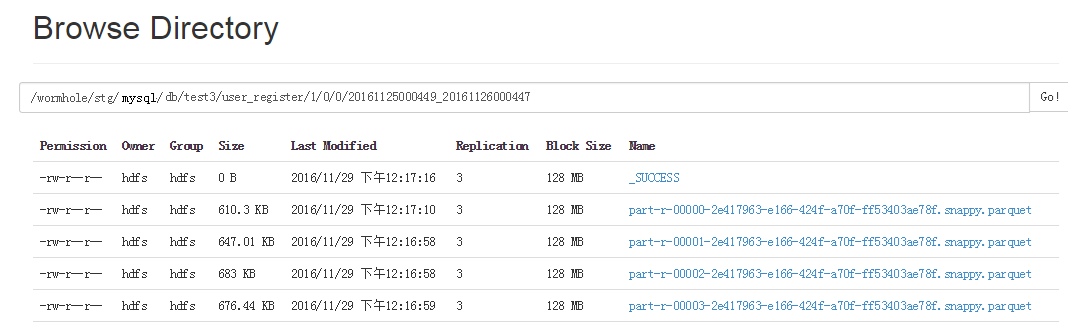 각 Parquet 파일 디렉터리에는 파일 데이터의 시작 시간과 종료 시간이 함께 제공됩니다. 이러한 방식으로 데이터를 다시 채울 때 모든 데이터를 읽지 않고도 선택한 시간 범위를 기준으로 읽어야 할 Parquet 파일을 결정할 수 있습니다.
각 Parquet 파일 디렉터리에는 파일 데이터의 시작 시간과 종료 시간이 함께 제공됩니다. 이러한 방식으로 데이터를 다시 채울 때 모든 데이터를 읽지 않고도 선택한 시간 범위를 기준으로 읽어야 할 Parquet 파일을 결정할 수 있습니다.
데이터를 추가, 삭제 또는 수정할 때 직면하는 문제는 다음과 같습니다.
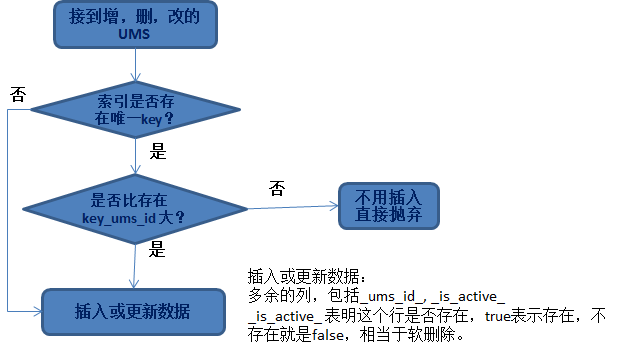
삽입된 _ums_id_가 상대적으로 크면 삭제된 데이터입니다(데이터가 삭제되었음을 나타냄). 이때 소프트 삭제가 아닌 경우 작은 _ums_id_ 데이터(기존 데이터)를 삽입하면 실제로 삽입됩니다. .
이로 인해 오래된 데이터가 삽입됩니다. 더 이상 멱등성이 없습니다. 따라서 삭제된 데이터가 여전히 유지(소프트 삭제)되는 것이 중요하며, 데이터의 멱등성을 보장하는 데 사용할 수 있습니다.
HBase 절약 Hbase에 데이터를 삽입하는 것은 매우 간단합니다. 차이점은 HBase가 여러 버전의 데이터를 유지할 수 있다는 것입니다(물론 하나의 버전만 유지할 수도 있음). 기본값은 3개 버전을 유지하는 것입니다.
따라서 HBase에 데이터를 삽입할 때 해결해야 할 문제는 다음과 같습니다.
성능 향상의 관점에서 전체 Spark Streaming Dataset 컬렉션을 비교 없이 HBase에 직접 삽입할 수 있습니다. 버전에 따라 HBase가 보관할 수 있는 데이터와 보관할 필요가 없는 데이터를 자동으로 결정하도록 하세요.
Jdbc에 데이터 삽입:
데이터를 데이터베이스에 삽입합니다. 멱등성을 보장하는 원리는 간단하지만 성능을 향상시키려면 구현이 훨씬 더 복잡해집니다. 하나씩 비교한 다음 삽입하거나 업데이트할 수는 없습니다.
Spark의 RDD/데이터세트는 성능 향상을 위해 수집 방식으로 운영된다는 것을 알고 있습니다. 마찬가지로 컬렉션 운영 방식에서도 멱등성을 달성해야 합니다.
구체적인 아이디어는 다음과 같습니다.
Spark를 사용하는 학생들은 RDD/데이터세트를 분할할 수 있고, 여러 작업자를 사용하고 운영하여 효율성을 높일 수 있다는 것을 알고 있습니다.
예: 다른 작업자가 이미 삽입했고 고유 제약 조건으로 인해 삽입이 실패했기 때문에 대신 업데이트하고 _ums_id_를 비교하여 업데이트할 수 있는지 확인해야 합니다.
삽입이 불가능한 기타 상황(예: 대상 시스템 문제)의 경우 Wormhole에는 재시도 메커니즘도 있습니다. 세부 사항이 너무 많습니다. 여기에는 소개가 별로 없습니다.
일부는 아직 개발 중입니다.
다른 저장소에 삽입하는 것에 대해서는 자세히 설명하지 않겠습니다. 일반적인 원칙은 각 저장소의 특성에 따라 컬렉션 기반 동시 데이터 삽입 구현을 설계하는 것입니다. 이는 성능을 위한 Wormhole의 노력이며 Wormhole을 사용하는 사용자는 이에 대해 걱정할 필요가 없습니다.
그렇게 말했지만 DWS의 실제 응용 프로그램은 무엇입니까? 다음으로 DWS를 이용하여 특정 시스템으로 구현되는 실시간 마케팅을 소개하겠습니다.
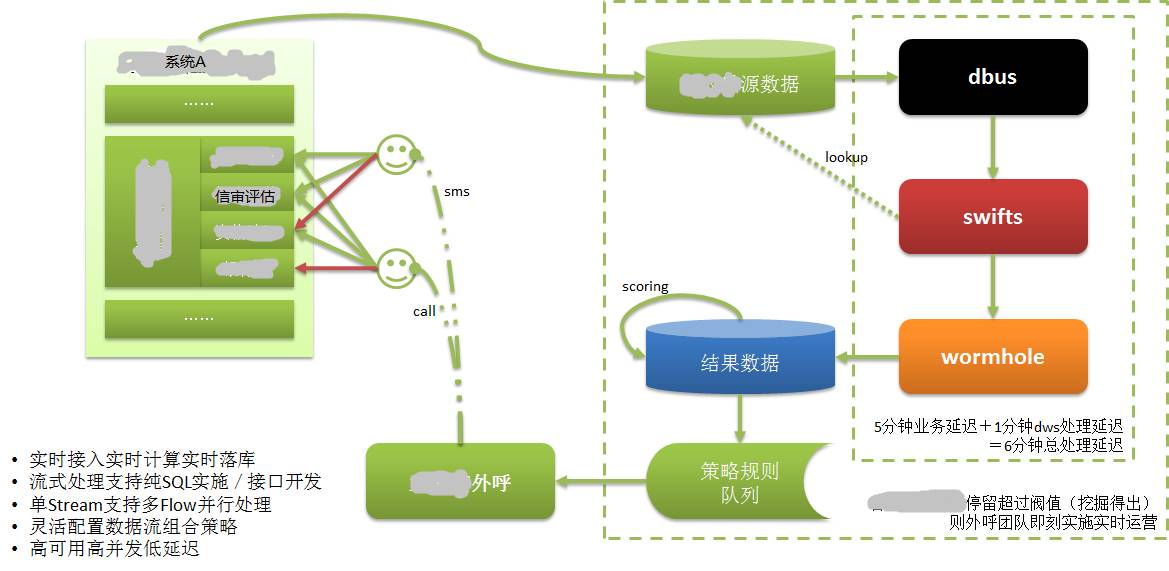
위 그림과 같이:
시스템 A의 데이터는 자체 데이터베이스에 저장되며 CreditEase는 대출을 포함한 다양한 금융 서비스를 제공하며 대출 과정에서 매우 중요한 것은 신용 검토입니다.
차용자는 가장 강력한 신용 데이터를 보유한 데이터인 중앙은행 신용 보고서 등 자신의 신용도를 입증하는 정보를 제공해야 합니다. 은행 거래나 온라인 쇼핑 거래도 신용 속성이 강한 데이터이다.
대출자가 웹이나 모바일 앱을 통해 시스템 A에 신용 정보를 입력할 때 어떤 이유로 인해 계속 진행하지 못할 수도 있습니다. 비록 이 대출자가 우량 잠재 고객일지라도 과거에는 이 정보를 사용할 수 없었습니다. 또는 오랫동안만 알 수 있었던 고객은 길을 잃습니다.
DWS 적용 후, 차용자가 작성하는 정보는 데이터베이스에 기록되며, DWS를 통해 실시간으로 대상 데이터베이스에 추출, 계산 및 구현됩니다. 고객 평점을 바탕으로 우수 고객을 평가합니다. 그런 다음 고객 정보를 즉시 고객 서비스 시스템에 출력합니다.
고객지원 담당자가 아주 짧은 시간(몇분 이내)에 전화로 차용자(잠재고객)에게 연락하여 고객관리를 진행하고 잠재고객을 실제 고객으로 전환시켰습니다. 우리는 대출이 시간에 민감하고 너무 오래 걸리면 아무 가치도 없다는 것을 알고 있습니다.
실시간으로 추출/계산/드롭하는 기능이 없었다면 이 모든 것은 불가능했을 것입니다.
실시간 신고 시스템또 다른 실시간 신고 신청은 다음과 같습니다.
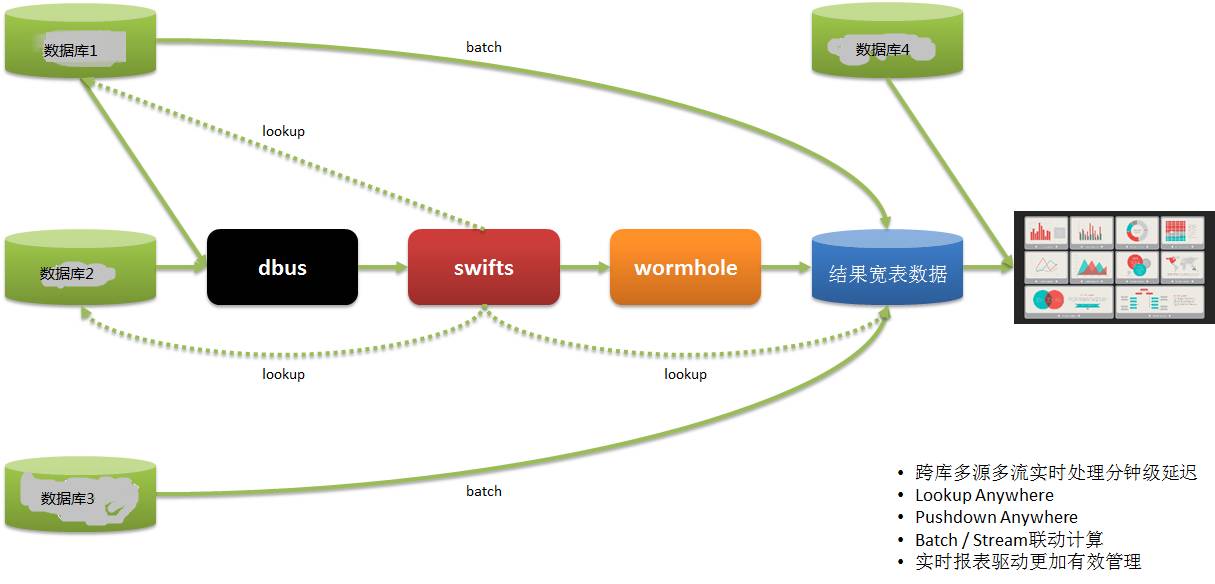
저희 데이터 사용자의 데이터는 여러 시스템에서 나옵니다. 과거에는 T+1을 사용하여 보고서 정보를 얻은 후 다음날 작업을 안내했기 때문에 적시성이 떨어졌습니다.
DWS를 통해 여러 시스템에서 실시간으로 데이터를 추출하여 계산, 구현하고 보고서를 제공함으로써 운영이 적시에 배포 및 조정하고 신속하게 대응할 수 있도록 합니다.
너무 많이 말씀드렸으니 대략적으로 요약해 보겠습니다.
적합한 시나리오는 다음과 같습니다. 실시간 동기화/실시간 계산/실시간 모니터링/실시간 보고/실시간 분석/실시간 통찰력/실시간 관리/실시간 운영/실시간 의사결정
들어주신 모든 분들께 감사드리며 이번 공유는 여기서 마치겠습니다.
Q1: Oracle 로그 리더용 오픈 소스 솔루션이 있습니까?
A1: Oracle GoldenGate(원래 Goldengate), Oracle Xstream, IBM InfoSphere Change Data Capture(원래 DataMirror), Dell SharePlex(원래 Quest), 국내 DSG superSync Wait 등 Oracle 업계를 위한 많은 상용 솔루션도 있습니다. , 사용하기 쉬운 오픈 소스 솔루션은 거의 없습니다.
Q2: 이 프로젝트에 얼마나 많은 인력과 물적 자원이 투자되었나요? 조금 복잡한 느낌이 듭니다.
Q2: DWS는 3개의 하위 프로젝트로 구성되어 있으며, 프로젝트당 평균 5~7명이 참여합니다. 조금 복잡하지만 실제로는 우리 회사가 직면하고 있는 어려움을 빅데이터 기술을 활용하여 해결하려는 시도입니다.
빅데이터 관련 기술을 연구하고 있어서 팀원 모두가 무척 기뻐하고 있어요 :)
사실 Dbus와 Wormhole은 상대적으로 고정된 패턴이고 재사용이 쉽습니다. Swift의 실시간 컴퓨팅은 각 비즈니스와 관련이 있고 강력한 사용자 정의 기능이 있으며 상대적으로 번거롭습니다.
Q3: CreditEase의 DWS 시스템은 오픈 소스인가요?
A3: Yixin의 다른 오픈 소스 프로젝트와 마찬가지로 이 프로젝트도 이제 막 구체화되었으며 향후 어느 시점에는 추가 개발이 필요하다고 생각합니다.
Q4: 건축가를 어떻게 이해하나요? 그는 시스템 엔지니어인가요?
A4: CreditEase에는 여러 명의 설계자가 있습니다. 그들은 기술로 비즈니스를 추진하는 기술 관리자로 간주되어야 합니다. 제품 디자인, 기술 관리 등을 포함합니다.
Q5: 복제 방식이 OGG인가요?
A5: OGG 및 위에 언급된 기타 상용 솔루션은 옵션입니다.
기사 출처: DBAplus 커뮤니티(dbaplus)
위 내용은 실시간 추출 및 로그 기반 데이터 동기화 일관성의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



