

Google은 AI가 오류 수정 기능을 개선하는 데 도움이 되는 BIG-Bench Mistake 데이터 세트를 출시했습니다.

Google Research는 최근 자체 BIG-Bench 벤치마크와 새로 구축된 "BIG-Bench Mistake" 데이터 세트를 사용하여 인기 있는 언어 모델에 대한 평가 연구를 수행했습니다. 그들은 주로 언어 모델의 오류 확률과 오류 수정 능력에 중점을 두었습니다. 이 연구는 시장에서 언어 모델의 성능을 더 잘 이해하는 데 유용한 데이터를 제공합니다.
Google 연구원들은 대규모 언어 모델의 '오류 확률'과 '자기 수정 능력'을 평가하기 위해 'BIG-Bench Mistake'라는 특별한 벤치마크 데이터 세트를 만들었다고 밝혔습니다. 이는 과거에 이러한 주요 지표를 효과적으로 평가하고 테스트할 수 있는 해당 데이터 세트가 부족했기 때문입니다.
연구원들은 PaLM 언어 모델을 사용하여 자체 BIG-Bench 벤치마크 작업에서 5가지 작업을 실행하고, 생성된 "사고 사슬" 궤적을 "논리 오류" 부분에 추가하여 모델 정확도를 다시 테스트했습니다.
데이터 세트의 정확성을 높이기 위해 Google 연구원들은 위 과정을 반복하여 마침내 "BIG-Bench Mistake"라고 불리는 255개의 논리적 오류가 포함된 평가용 벤치마크 데이터 세트를 만들었습니다.
연구원들은 "BIG-Bench Mistake" 데이터 세트의 논리적 오류가 매우 명백하므로 언어 모델 테스트의 좋은 표준으로 사용될 수 있다고 지적했습니다. 이 데이터 세트는 모델이 단순한 오류로부터 학습하고 오류를 식별하는 능력을 점진적으로 향상시키는 데 도움이 됩니다.
연구원들은 이 데이터 세트를 사용하여 시장에서 모델을 테스트한 결과 대부분의 언어 모델이 추론 과정에서 논리적 오류를 식별하고 스스로 수정할 수 있지만 이 과정은 그리 이상적이지 않다는 것을 발견했습니다. 모델이 출력하는 내용을 수정하려면 사람의 개입이 필요한 경우도 많습니다.
▲ 사진 출처 구글리서치 보도자료
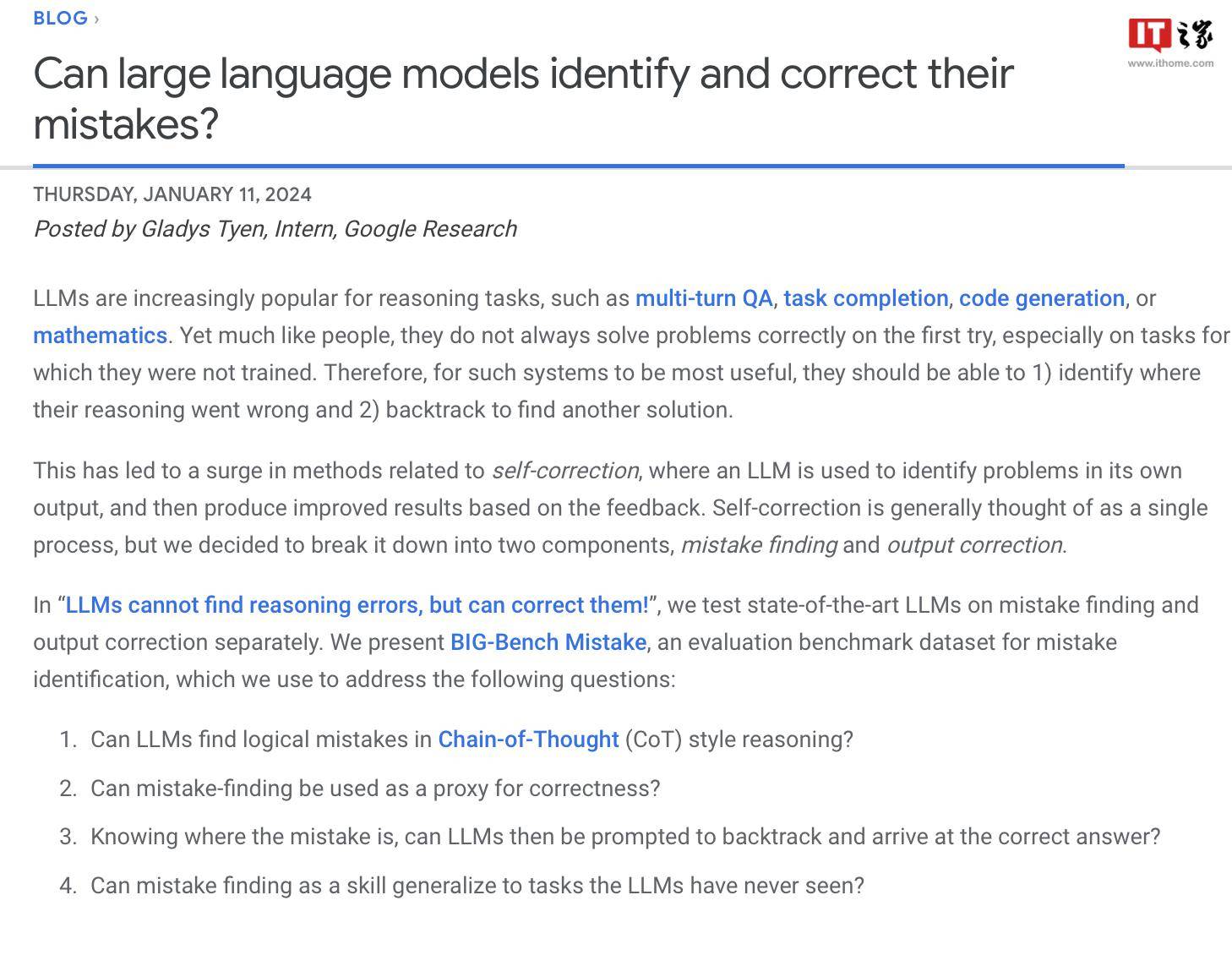
보고서에 따르면 Google은 현재 가장 발전된 대형 언어 모델로 간주되지만 자체 수정 능력이 상대적으로 제한적이라고 주장합니다. 테스트에서 가장 성능이 좋은 모델은 논리적 오류의 52.9%만을 발견했습니다.

Google 연구자들은 또한 이 BIG-Bench Mistake 데이터 세트가 모델의 자체 수정 능력을 향상시키는 데 도움이 된다고 주장했습니다. 관련 테스트 작업에 대해 모델을 미세 조정한 후에는 "작은 모델이라도 일반적으로 샘플 프롬프트가 없는 대형 모델보다 더 나은 성능을 발휘합니다." " ".
이에 따르면 Google은 모델 오류 수정 측면에서 대규모 언어 모델이 '자체 오류 수정'을 학습하도록 하는 것과 비교하여 감독 전용 소규모 전용 모델을 배포하는 데 독점 소형 모델을 사용할 수 있다고 믿습니다. 대형 모델은 효율성을 향상하고 관련 AI 배포 비용을 줄이며 미세 조정을 더 쉽게 만드는 데 도움이 됩니다.
위 내용은 Google은 AI가 오류 수정 기능을 개선하는 데 도움이 되는 BIG-Bench Mistake 데이터 세트를 출시했습니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

Video Face Swap
완전히 무료인 AI 얼굴 교환 도구를 사용하여 모든 비디오의 얼굴을 쉽게 바꾸세요!

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)



 Agno 프레임 워크를 사용하여 멀티 모달 AI 에이전트를 구축하는 방법은 무엇입니까?
Apr 23, 2025 am 11:30 AM
Agno 프레임 워크를 사용하여 멀티 모달 AI 에이전트를 구축하는 방법은 무엇입니까?
Apr 23, 2025 am 11:30 AM
에이전트 AI에서 작업하는 동안 개발자는 종종 속도, 유연성 및 자원 효율성 사이의 상충 관계를 탐색하는 것을 발견합니다. 나는 에이전트 AI 프레임 워크를 탐구하고 Agno를 만났다 (이전에는 ph-이었다.
 SQL에서 열을 추가하는 방법? - 분석 Vidhya
Apr 17, 2025 am 11:43 AM
SQL에서 열을 추가하는 방법? - 분석 Vidhya
Apr 17, 2025 am 11:43 AM
SQL의 Alter Table 문 : 데이터베이스에 열을 동적으로 추가 데이터 관리에서 SQL의 적응성이 중요합니다. 데이터베이스 구조를 즉시 조정해야합니까? Alter Table 문은 솔루션입니다. 이 안내서는 Colu를 추가합니다
 Openai는 GPT-4.1로 초점을 이동하고 코딩 및 비용 효율성을 우선시합니다.
Apr 16, 2025 am 11:37 AM
Openai는 GPT-4.1로 초점을 이동하고 코딩 및 비용 효율성을 우선시합니다.
Apr 16, 2025 am 11:37 AM
릴리스에는 GPT-4.1, GPT-4.1 MINI 및 GPT-4.1 NANO의 세 가지 모델이 포함되어 있으며, 대형 언어 모델 환경 내에서 작업 별 최적화로 이동합니다. 이 모델은 사용자를 향한 인터페이스를 즉시 대체하지 않습니다
 Andrew Ng의 모델 임베딩에 대한 새로운 단기 과정
Apr 15, 2025 am 11:32 AM
Andrew Ng의 모델 임베딩에 대한 새로운 단기 과정
Apr 15, 2025 am 11:32 AM
임베딩 모델의 힘 잠금 해제 : Andrew Ng의 새로운 코스에 대한 깊은 다이빙 기계가 완벽한 정확도로 질문을 이해하고 응답하는 미래를 상상해보십시오. 이것은 공상 과학이 아닙니다. AI의 발전 덕분에 R이되었습니다
 Rocketpy -Analytics Vidhya를 사용한 로켓 런칭 시뮬레이션 및 분석
Apr 19, 2025 am 11:12 AM
Rocketpy -Analytics Vidhya를 사용한 로켓 런칭 시뮬레이션 및 분석
Apr 19, 2025 am 11:12 AM
Rocketpy : 포괄적 인 가이드로 로켓 발사 시뮬레이션 이 기사는 강력한 파이썬 라이브러리 인 Rocketpy를 사용하여 고출력 로켓 런칭을 시뮬레이션하는 것을 안내합니다. 로켓 구성 요소 정의에서 Simula 분석에 이르기까지 모든 것을 다룰 것입니다.
 Google은 다음 2025 년 클라우드에서 가장 포괄적 인 에이전트 전략을 공개합니다.
Apr 15, 2025 am 11:14 AM
Google은 다음 2025 년 클라우드에서 가장 포괄적 인 에이전트 전략을 공개합니다.
Apr 15, 2025 am 11:14 AM
Google의 AI 전략의 기초로서 Gemini Gemini는 Google의 AI 에이전트 전략의 초석으로 고급 멀티 모드 기능을 활용하여 텍스트, 이미지, 오디오, 비디오 및 코드에서 응답을 처리하고 생성합니다. Deepm에 의해 개발되었습니다
 직접 3D 인쇄 할 수있는 오픈 소스 휴머노이드 로봇 : Hugging Face Pollen Robotics
Apr 15, 2025 am 11:25 AM
직접 3D 인쇄 할 수있는 오픈 소스 휴머노이드 로봇 : Hugging Face Pollen Robotics
Apr 15, 2025 am 11:25 AM
Hugging Face는 X에서“우리가 오픈 소스 로봇을 전 세계에 가져 오기 위해 꽃가루 로봇 공학을 획득하고 있음을 발표하게되어 기쁩니다.
 DeepCoder-14B : O3-MINI 및 O1에 대한 오픈 소스 경쟁
Apr 26, 2025 am 09:07 AM
DeepCoder-14B : O3-MINI 및 O1에 대한 오픈 소스 경쟁
Apr 26, 2025 am 09:07 AM
AI 커뮤니티의 상당한 개발에서 Agentica와 AI는 DeepCoder-14B라는 오픈 소스 AI 코딩 모델을 발표했습니다. OpenAI와 같은 폐쇄 소스 경쟁 업체와 동등한 코드 생성 기능 제공
