
Random Forest 알고리즘은 다중 의사결정 트리와 부트스트랩 및 집계라는 기법을 사용하여 회귀 및 분류 작업을 수행할 수 있는 앙상블 기법입니다. 이에 대한 기본 아이디어는 단일 결정 트리에 의존하는 대신 여러 결정 트리를 결합하여 최종 출력을 결정하는 것입니다.
Random Forest는 수많은 분류 트리를 생성합니다. 포리스트의 각 트리 아래에 입력 벡터를 배치하여 입력 벡터를 기반으로 새 개체를 분류합니다. 각 트리에는 "투표"라고 부르는 클래스가 할당되며, 최종적으로 가장 많은 표를 얻은 클래스가 선택됩니다.
다음 단계는 랜덤 포레스트 알고리즘의 작동 방식을 이해하는 데 도움이 됩니다.
1단계: 먼저 데이터 세트에서 무작위 샘플을 선택합니다.
2단계: 각 샘플에 대해 알고리즘은 결정 트리를 생성합니다. 그러면 각 의사결정 트리의 예측 결과가 얻어집니다.
3단계: 이 단계에서 예상되는 각 결과가 투표됩니다.
4단계: 마지막으로 가장 많은 표를 얻은 예측 결과를 최종 예측 결과로 선택합니다.
Random Forest 알고리즘의 주요 특징은 다음과 같습니다.
랜덤 포레스트에는 기본 학습 모델로 여러 의사결정 트리가 있습니다. 데이터세트에서 행 샘플링과 특징 샘플링을 무작위로 수행하여 각 모델에 대한 샘플 데이터세트를 구성합니다. 이 부분을 부트스트랩이라고 합니다.
1단계: 필요한 라이브러리를 가져옵니다.
import numpy as np import matplotlib.pyplot as plt import pandas as pd
2단계: 데이터세트 가져오기 및 인쇄
ata=pd.read_csv('Salaries.csv') print(data)
3단계: 데이터세트에서 x까지 모든 행과 열 1을 선택하고 y
x=df.iloc[: ,:-1]로 모든 행과 열 2를 선택합니다. #":"는 모든 행을 선택한다는 뜻이고, ":-1"은 마지막 열을 무시한다는 의미입니다.
y=df.iloc[:,-1:]#":"는 모든 행을 선택한다는 뜻입니다. "- 1:"은 마지막 열을 제외한 모든 열을 무시한다는 의미입니다.
#"iloc()" 함수를 사용하면 데이터세트의 특정 셀을 선택할 수 있습니다. 즉, 데이터 프레임이나 데이터세트에서 특정 셀을 선택하는 데 도움이 됩니다. 값 집합에서 특정 행이나 열에 속하는 값을 선택합니다.
4단계: 데이터세트에 임의의 포리스트 회귀자를 맞추세요
from sklearn.ensemble import RandomForestRegressor regressor=RandomForestRegressor(n_estimators=100,random_state=0) regressor.fit(x,y)
5단계: 새로운 결과 예측
Y_pred=regressor.predict(np.array([6.5]).reshape(1,1))
6단계: 결과 시각화
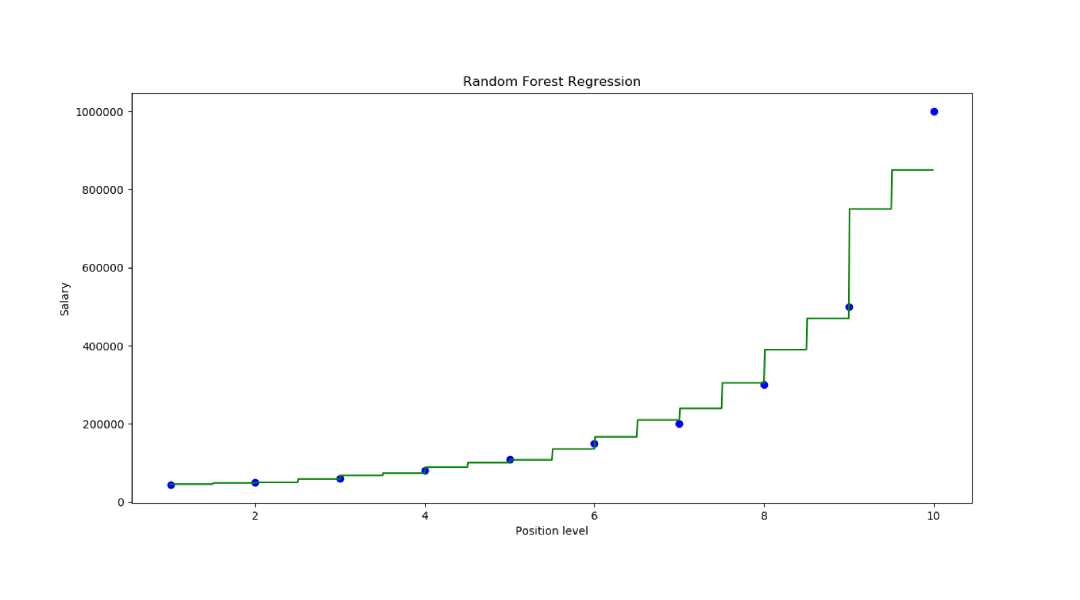
X_grid=np.arrange(min(x),max(x),0.01) X_grid=X_grid.reshape((len(X_grid),1)) plt.scatter(x,y,color='blue') plt.plot(X_grid,regressor.predict(X_grid), color='green') plt.title('Random Forest Regression') plt.xlabel('Position level') plt.ylabel('Salary') plt.show()
위 내용은 랜덤 포레스트 알고리즘 원리 및 실제 적용에 대한 Python 예제(완전한 코드 포함)의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



