

동적 측정, 이러한 데이터는 주로 시계열 데이터와 이벤트 데이터의 두 가지 범주로 나뉩니다. 시계열 데이터는 CPU 사용량 등의 실제 값 시계열(일반적으로 고정된 시간 간격)을 나타내고, 이벤트 데이터는 메모리 오버플로 이벤트와 같은 특정 이벤트의 발생을 기록하는 시퀀스를 나타냅니다. 제품 서비스 품질을 보장하고, 서비스 중단 시간을 줄이고, 더 큰 경제적 손실을 방지하려면 주요 서비스 이벤트에 대한 진단이 특히 중요합니다. 실제 운영 및 유지보수 업무에서 서비스 이벤트 진단 시, 운영 및 유지보수 담당자는 서비스 이벤트와 관련된 시계열 데이터를 분석하여 이벤트의 원인을 분석할 수 있다. 비록 이 상관관계가 실제 원인과 결과 관계를 완벽하게 정확하게 반영할 수는 없지만 여전히 진단을 위한 좋은 단서와 계시를 제공할 수 있습니다.
그럼 문제는 이벤트와 시계열 데이터 간의 관계를 자동으로 파악하는 방법은 무엇입니까?
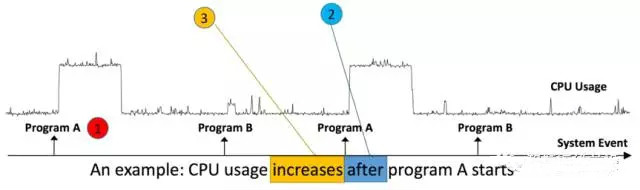
질문이 글에서 저자는 이벤트(E)와 시계열(S) 데이터 상관 문제를 2-샘플 문제로 변환하고 최근접 이웃 방법을 사용하여 관련 여부를 확인합니다. 주로 세 가지 질문에 답변했습니다:A. E와 S 사이에 상관관계가 있나요? 비. 상관관계가 있다면 E와 S의 연대순은 어떻게 되나요? E가 먼저 발생합니까, 아니면 S가 먼저 발생합니까? C. E와 S 사이의 단조로운 관계. S(또는 E)가 먼저 발생한다고 가정하면 S의 증가 또는 감소로 인해 E가 발생합니까? 그림과 같이 이벤트는 프로그램 A, B의 실행이고, 타이밍 데이터는 CPU 사용량입니다. 이벤트(프로그램 A의 실행)와 타이밍 데이터(CPU 사용량) 사이에는 상관관계가 있음을 알 수 있는데, 이는 프로그램 A가 실행된 후 증가하는 CPU 사용량의 변화이다.
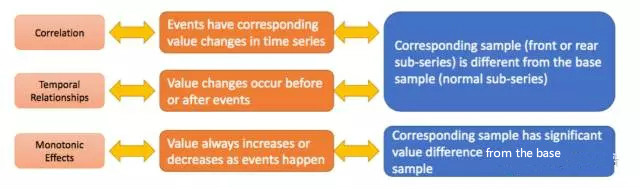
이 기사의 알고리즘 아키텍처는 상관관계, 시간 순서 및 단조성의 세 가지 문제를 각각 해결하기 위해 주로 세 부분으로 나뉩니다. 이 세 부분은 다음에 자세히 소개하겠습니다.
이 기사에서는 상관 관계 판단을 2-표본 문제로 변환합니다. 2-표본 가설 검정의 핵심은 두 표본이 동일한 분포에서 나온 것인지 확인하는 것입니다. 먼저 A1으로 표시되는 이벤트 이전(또는 이후)에 해당하는 길이 k를 갖는 시계열 샘플 데이터의 N 세그먼트를 선택합니다. 샘플 그룹 A2는 시계열에서 길이가 k인 일련의 샘플 데이터를 무작위로 선택합니다. 샘플 세트는 A1이고 A2까지 올라갑니다. E와 S가 관련되어 있는 경우 A1과 A2의 분포는 다르며 그렇지 않은 경우 분포는 동일합니다. A1과 A2의 분포가 동일한지 어떻게 확인합니까? 다음 예를 살펴보겠습니다.
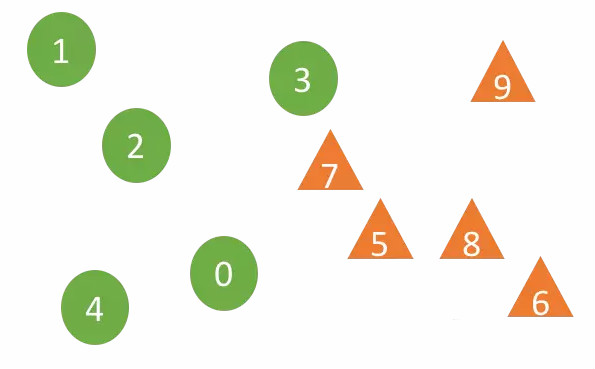
위 그림에서 샘플 0-4는 샘플 그룹 A1에 속하고 5-9는 샘플 그룹 A2에 속합니다. DTW 알고리즘은 두 샘플 사이의 거리를 계산하는 데 사용됩니다(DTW 알고리즘은 확장에 잘 적응할 수 있습니다). 및 시퀀스 데이터의 변위). 샘플 그룹 Ai(i=1 또는 2)에 속하는 샘플 X의 경우, E와 S의 최근접 이웃 샘플 r개에 대해 더 많은 관련이 있습니다. 예를 들어, 이웃 개수가 r=2인 경우 샘플 7의 최근접 이웃 2개는 서로 다른 두 샘플 그룹의 3과 5이지만, 샘플 5의 최근접 이웃 2개는 동일한 샘플 그룹 A2의 7과 8입니다. 이 기사에서는 "가설 검정 H1"의 신뢰성을 판단하기 위해 신뢰 계수(신뢰 계수)를 사용합니다(두 분포가 동일하지 않음, 즉 E와 S가 관련됨). 믿을 수 있는 H1입니다. 알고리즘에는 가장 가까운 이웃 수 r과 시계열 길이 k라는 두 가지 주요 매개변수가 있습니다. 이웃 수는 샘플 수의 자연 로그입니다. 시계열 데이터의 자기상관 함수 곡선의 첫 번째 피크는 다음과 같습니다. 시퀀스 길이.
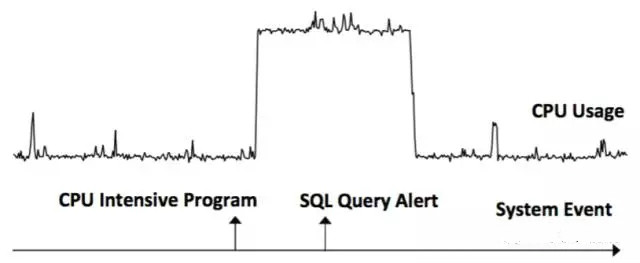
이벤트 전후의 시퀀스와 무작위로 선택된 시계열을 선택하여 상관 관계를 계산합니다. Dr이 True이고 Df가 False인 경우 S가 발생하기 전에 E가 발생한다는 의미입니다(E -> S). Dr가 False이고 Df가 True이거나 Dr가 True이고 Df가 True인 경우 E가 발생하기 전에 S가 발생한다는 의미입니다(S -> E). 아래 예와 같이 이벤트 CPU 집중 프로그램 -> 시계열 데이터 CPU 사용량, 시계열 데이터 CPU 사용량 -> 이벤트 SQL 쿼리 경고.
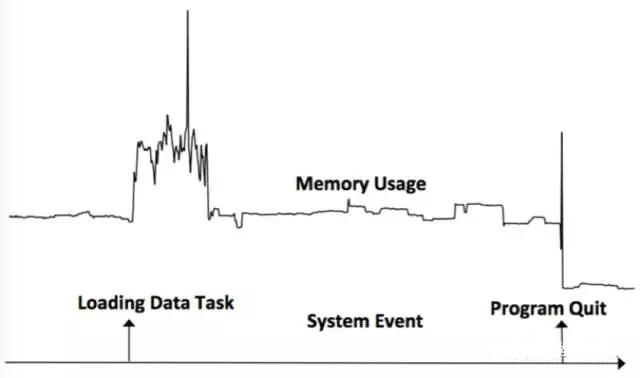
단조성은 이벤트 발생 전후 시계열의 변화로 판단합니다. 이벤트 발생 후 시계열이 이전 시퀀스의 값보다 크면 단조성이 증가하고, 그렇지 않으면 감소합니다. 아래 그림과 같이 Data Task를 로딩하는 이벤트로 인해 메모리 사용량이 증가하였고, 프로그램 종료 이벤트로 인해 메모리 사용량이 감소했습니다.
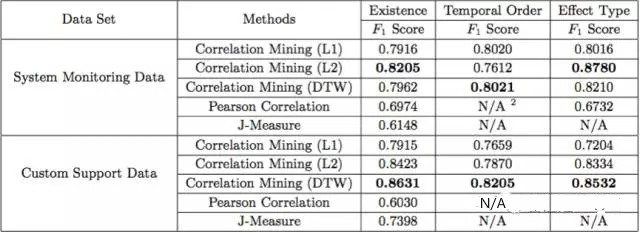
이 기사에서는 Microsoft의 시스템 모니터링 데이터와 고객 서비스 팀의 데이터를 사용하여 알고리즘 성능을 검증합니다. 데이터는 24S(메모리, CPU 및 DISK 데이터)와 52E(특정 작업 실행), 7S(HTTP 상태 코드)입니다. ) 및 57 E(서비스 주제)의 평가 기준은 F점수입니다. 결과는 DTW 거리가 다른 거리(L1 및 L2)보다 전반적으로 더 나은 성능을 발휘하고 알고리즘이 전체적으로 두 가지 기본 알고리즘(Pearson 상관 관계 및 J-Measure)보다 더 나은 성능을 발휘한다는 것을 보여줍니다.
이 기사에서는 세 가지 질문에 답하면서 사건과 시계열 데이터 간의 관계를 연구하는 새로운 비지도 방법을 소개합니다. E와 S가 관련되어 있습니까? E와 S는 어떤 순서로 발생했나요? 그리고 단조로운 관계란 무엇입니까? 사건 간의 상관관계와 시계열 데이터 간의 상관관계에 주로 초점을 맞춘 현재의 많은 상관관계 연구와 비교하여, 이 글은 사건과 시간 사이의 위 세 가지 질문에 답하는 첫 번째 글입니다. 시리즈 데이터 문제.
이벤트 진단은 운영 및 유지 관리 분야에서 항상 매우 중요한 작업이었습니다. 이벤트와 시계열 데이터 간의 상관 관계는 이벤트 진단에 좋은 영감을 제공할 뿐만 아니라 근본 원인 분석에 대한 좋은 단서를 제공할 수도 있습니다. 저자는 Microsoft의 내부 데이터 세트에서 알고리즘을 검증하고 좋은 결과를 얻었으며 이는 학계와 산업계 모두에게 높은 가치가 있습니다.
위 내용은 마이크로소프트의 AIOps 작업 세부 사항 공개의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



