

자가 게임 미세 조정 훈련을 위한 SPIN 기술을 활용한 LLM 최적화

2024년은 LLM(대형 언어 모델)이 급속히 발전하는 해입니다. LLM 훈련에서 정렬 방법은 인간의 선호도에 의존하는 지도형 미세 조정(SFT) 및 인간 피드백을 통한 강화 학습(RLHF)을 포함하는 중요한 기술적 수단입니다. 이러한 방법은 LLM 개발에 중요한 역할을 해왔지만 정렬 방법에는 수동으로 주석을 단 대량의 데이터가 필요합니다. 이러한 과제에 직면하여 미세 조정은 활발한 연구 분야가 되었으며, 연구자들은 인간 데이터를 효과적으로 활용할 수 있는 방법을 개발하기 위해 적극적으로 노력하고 있습니다. 따라서 정렬 방법의 개발은 LLM 기술의 획기적인 발전을 촉진할 것입니다.
캘리포니아 대학에서는 최근 연구를 진행하여 SPIN(Self Play fine tunNing)이라는 새로운 기술을 도입했습니다. SPIN은 AlphaGo Zero 및 AlphaZero와 같은 게임의 성공적인 셀프 플레이 메커니즘을 활용하여 LLM(언어 학습 모델)이 셀프 플레이에 참여할 수 있도록 합니다. 이 기술을 사용하면 인간이든 고급 모델(예: GPT-4)이든 전문적인 주석자가 필요하지 않습니다. SPIN의 훈련 과정에는 새로운 언어 모델을 훈련하고 일련의 반복을 통해 자체 생성된 응답과 인간이 생성한 응답을 구별하는 작업이 포함됩니다. 궁극적인 목표는 인간의 반응과 구별할 수 없는 반응을 생성하는 언어 모델을 개발하는 것입니다. 본 연구의 목적은 언어 모델의 자가 학습 능력을 더욱 향상시켜 인간의 표현과 사고에 더욱 가깝게 만드는 것입니다. 이번 연구 결과는 자연어 처리 기술 발전에 새로운 돌파구를 가져올 것으로 기대된다.
자기 게임
자기 게임은 자신의 복사본과 대결하여 학습 환경의 도전과 복잡성을 높이는 학습 기술입니다. 이 접근 방식을 사용하면 에이전트가 다른 버전의 에이전트와 상호 작용할 수 있으므로 성능이 향상됩니다. AlphaGo Zero는 셀프 게임의 성공적인 사례입니다.

셀프 게임은 MARL(다중 에이전트 강화 학습)에서 효과적인 방법임이 입증되었습니다. 그러나 이를 대규모 언어 모델(LLM)의 확장에 적용하는 것은 새로운 접근 방식입니다. 대규모 언어 모델에 자체 게임을 적용하면 보다 일관되고 정보가 풍부한 텍스트를 생성하는 능력이 더욱 향상될 수 있습니다. 이 방법은 언어 모델의 추가 개발과 개선을 촉진할 것으로 예상됩니다.
셀프 플레이는 경쟁적이거나 협력적인 환경에서 적용될 수 있습니다. 경쟁에서는 알고리즘의 복사본이 서로 경쟁하여 목표를 달성합니다. 협력에서는 복사본이 공동의 목표를 달성하기 위해 함께 작동합니다. 지도 학습, 강화 학습 및 기타 기술과 결합하여 성능을 향상시킬 수 있습니다.
SPIN
SPIN은 2인용 게임과 같습니다. 이 게임에서:
마스터 모델(새로운 LLM)의 역할은 언어 모델(LLM)에서 생성된 응답과 인간이 생성한 응답을 구별하는 방법을 배우는 것입니다. 각 반복에서 마스터 모델은 LLM을 적극적으로 교육하여 응답을 인식하고 구별하는 능력을 향상시킵니다.
적대 모델(이전 LLM)은 인간이 생성하는 것과 유사한 반응을 생성하는 임무를 맡습니다. 이는 과거 지식을 기반으로 출력을 생성하는 자체 게임 메커니즘을 사용하여 이전 반복의 LLM을 통해 생성됩니다. 적대적 모델의 목표는 새로운 LLM이 그것이 기계에서 생성되었는지 확신할 수 없을 정도로 현실적인 응답을 생성하는 것입니다.
이 프로세스는 GAN과 매우 유사하지 않지만 여전히 동일하지는 않습니다
SPIN의 역학은 입력(x)과 출력(y)으로 구성된 감독 미세 조정(SFT) 데이터 세트의 사용과 관련됩니다. ) 쌍. 이러한 예는 인간이 주석을 달고 인간과 유사한 반응을 인식하도록 기본 모델을 훈련하기 위한 기초 역할을 합니다. 일부 공개 SFT 데이터 세트에는 Dolly15K, Baize, Ultrachat 등이 포함됩니다.
주 모델 훈련
주 모델을 훈련하여 언어 모델(LLM)과 인간 반응을 구별하기 위해 SPIN은 목적 함수를 사용합니다. 이 함수는 실제 데이터와 적대적 모델에 의해 생성된 응답 간의 기대값 차이를 측정합니다. 주요 모델의 목표는 이러한 기대 가치 격차를 최대화하는 것입니다. 여기에는 실제 데이터의 응답과 쌍을 이루는 단서에 높은 값을 할당하고, 적대 모델에서 생성된 응답 쌍에 낮은 값을 할당하는 작업이 포함됩니다. 이 목적 함수는 최소화 문제로 공식화됩니다.
마스터 모델의 임무는 손실 함수를 최소화하는 것인데, 이는 실제 데이터의 쌍별 할당 값과 상대 모델 응답의 쌍별 할당 값의 차이를 측정합니다. 학습 프로세스 전반에 걸쳐 마스터 모델은 매개변수를 조정하여 이 손실 함수를 최소화합니다. 이 반복 프로세스는 마스터 모델이 LLM 응답과 인간 응답을 효과적으로 구별하는 데 능숙해질 때까지 계속됩니다.
적대 모델 업데이트
적대 모델 업데이트에는 학습 중에 실제 데이터와 언어 모델 응답을 구별하는 방법을 학습한 마스터 모델의 능력이 향상됩니다. 마스터 모델이 향상되고 특정 기능 클래스에 대한 이해가 향상됨에 따라 적대 모델과 같은 매개변수도 업데이트해야 합니다. 마스터 플레이어는 동일한 프롬프트에 직면하면 학습된 식별을 사용하여 가치를 평가합니다.
상대 모델 플레이어의 목표는 언어 모델을 향상하여 해당 응답이 마스터 플레이어의 실제 데이터와 구별되지 않도록 하는 것입니다. 이를 위해서는 언어 모델의 매개변수를 조정하는 프로세스를 설정해야 합니다. 목표는 안정성을 유지하면서 언어 모델의 응답에 대한 마스터 모델의 평가를 최대화하는 것입니다. 여기에는 개선 사항이 원래 언어 모델에서 너무 멀리 벗어나지 않도록 균형을 맞추는 작업이 포함됩니다.
좀 혼란스러울 것 같지만 간단히 요약하자면:
훈련 중에는 모델이 하나만 있지만 모델은 이전 라운드 모델(기존 LLM/상대 모델)과 기본 모델(훈련 중인)로 구분됩니다. 사용 훈련 중인 모델의 출력을 이전 모델 라운드의 출력과 비교하여 현재 모델의 훈련을 최적화합니다. 하지만 여기서는 상대 모델로 훈련된 모델이 필요하므로 SPIN 알고리즘은 훈련 결과를 미세 조정하는 데에만 적합합니다.
SPIN 알고리즘
SPIN은 사전 훈련된 모델에서 합성 데이터를 생성합니다. 그런 다음 이 합성 데이터는 새로운 작업에 대한 모델을 미세 조정하는 데 사용됩니다.

위는 원본 논문에 있는 Spin 알고리즘의 의사 코드입니다. 작동 방식을 더 잘 설명하기 위해 Python으로 재현했습니다.
1. 초기화 매개변수 및 SFT 데이터 세트
원고에서는 Zephyr-7B-SFT-Full을 기본 모델로 사용했습니다. 데이터 세트의 경우 OpenAI의 Turbo API를 사용하여 생성된 약 140만 개의 대화로 구성된 더 큰 Ultrachat200k 코퍼스의 하위 세트를 사용했습니다. 그들은 50,000개의 큐를 무작위로 샘플링하고 기본 모델을 사용하여 합성 응답을 생성했습니다.
# Import necessary libraries from datasets import load_dataset import pandas as pd # Load the Ultrachat 200k dataset ultrachat_dataset = load_dataset("HuggingFaceH4/ultrachat_200k") # Initialize an empty DataFrame combined_df = pd.DataFrame() # Loop through all the keys in the Ultrachat dataset for key in ultrachat_dataset.keys():# Convert each dataset key to a pandas DataFrame and concatenate it with the existing DataFramecombined_df = pd.concat([combined_df, pd.DataFrame(ultrachat_dataset[key])]) # Shuffle the combined DataFrame and reset the index combined_df = combined_df.sample(frac=1, random_state=123).reset_index(drop=True) # Select the first 50,000 rows from the shuffled DataFrame ultrachat_50k_sample = combined_df.head(50000)저자의 프롬프트 템플릿 "### Instruction: {prompt}nn### Response:"
# for storing each template in a list templates_data = [] for index, row in ultrachat_50k_sample.iterrows():messages = row['messages'] # Check if there are at least two messages (user and assistant)if len(messages) >= 2:user_message = messages[0]['content']assistant_message = messages[1]['content'] # Create the templateinstruction_response_template = f"### Instruction: {user_message}\n\n### Response: {assistant_message}" # Append the template to the listtemplates_data.append({'Template': instruction_response_template}) # Create a new DataFrame with the generated templates (ground truth) ground_truth_df = pd.DataFrame(templates_data)그런 다음 다음과 유사한 데이터를 얻었습니다.
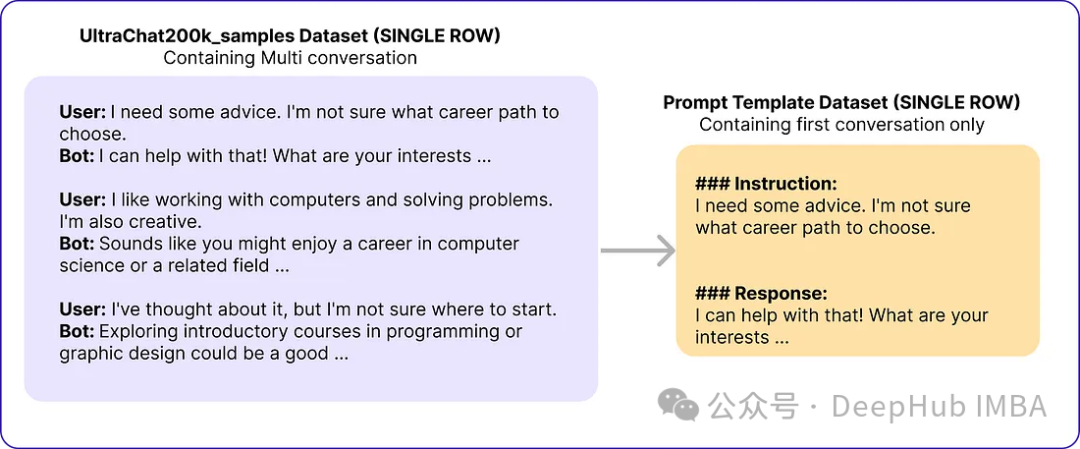
SPIN 알고리즘은 언어 모델(LLM)을 다음과 같이 업데이트합니다. 실측 응답과 일관성을 유지하기 위한 반복 매개변수입니다. 이 프로세스는 생성된 응답을 실제와 구별하기 어려울 때까지 계속되어 높은 수준의 유사성을 달성합니다(손실 감소).
SPIN 알고리즘에는 두 개의 루프가 있습니다. 내부 루프는 우리가 사용한 샘플 수를 기준으로 실행되었으며, 외부 루프는 총 3번의 반복 동안 실행되었으며, 저자는 이 이후에도 모델의 성능이 변하지 않는다는 것을 발견했습니다. Alignment Handbook 라이브러리는 미세 조정 방법의 코드 기반으로 사용되며 DeepSpeed 모듈과 결합되어 훈련 비용이 절감됩니다. 그들은 일반적으로 LLM을 미세 조정하는 데 사용되는 것처럼 모든 반복에 대한 가중치 감소 없이 RMSProp 최적화 프로그램을 사용하여 Zephyr-7B-SFT-Full을 교육했습니다. 전역 배치 크기는 bfloat16 정밀도를 사용하여 64로 설정됩니다. 반복 0과 1의 최고 학습률은 5e-7로 설정되고, 반복 2와 3의 최고 학습률은 루프가 자체 재생 미세 조정의 끝에 접근함에 따라 1e-7로 감소합니다. 마지막으로 β = 0.1이 선택되고 최대 시퀀스 길이는 2048 토큰으로 설정됩니다. 다음은 이러한 매개변수입니다
# Importing the PyTorch library import torch # Importing the neural network module from PyTorch import torch.nn as nn # Importing the DeepSpeed library for distributed training import deepspeed # Importing the AutoTokenizer and AutoModelForCausalLM classes from the transformers library from transformers import AutoTokenizer, AutoModelForCausalLM # Loading the zephyr-7b-sft-full model from HuggingFace tokenizer = AutoTokenizer.from_pretrained("alignment-handbook/zephyr-7b-sft-full") model = AutoModelForCausalLM.from_pretrained("alignment-handbook/zephyr-7b-sft-full") # Initializing DeepSpeed Zero with specific configuration settings deepspeed_config = deepspeed.config.Config(train_batch_size=64, train_micro_batch_size_per_gpu=4) model, optimizer, _, _ = deepspeed.initialize(model=model, config=deepspeed_config, model_parameters=model.parameters()) # Defining the optimizer and setting the learning rate using RMSprop optimizer = deepspeed.optim.RMSprop(optimizer, lr=5e-7) # Setting up a learning rate scheduler using LambdaLR from PyTorch scheduler = torch.optim.lr_scheduler.LambdaLR(optimizer, lambda epoch: 0.2 ** epoch) # Setting hyperparameters for training num_epochs = 3 max_seq_length = 2048 beta = 0.12. 합성 데이터 생성(SPIN 알고리즘 내부 루프)
이 내부 루프는 훈련 배치의 코드인 실제 데이터와 일치해야 하는 응답을 생성하는 역할을 담당합니다. 실제 값과 모델 출력의 힌트 예입니다.
 기본 모델 Zephyr-7B-SFT-Full에서 생성된 힌트와 해당 출력을 포함하는 새로운 df zephyr_sft_output.
기본 모델 Zephyr-7B-SFT-Full에서 생성된 힌트와 해당 출력을 포함하는 새로운 df zephyr_sft_output.
3. 규칙 업데이트
최소화 문제를 인코딩하기 전에 llm에서 생성된 출력의 조건부 확률 분포를 계산하는 방법을 이해하는 것이 중요합니다. 원본 논문에서는 조건부 확률 분포 pθ(y|x)가 분해를 통해 다음과 같이 표현될 수 있는 Markov 프로세스를 사용합니다.
 이 분해는 입력 시퀀스가 주어졌을 때 출력 시퀀스의 확률이 다음과 같이 나누어 표현될 수 있음을 의미합니다. 주어진 입력 시퀀스 의 각 출력 토큰은 이전 출력 토큰의 확률을 곱하여 계산됩니다. 예를 들어, 출력 시퀀스는 "나는 책 읽기를 즐긴다"이고 입력 시퀀스는 "나는 즐긴다"입니다. 입력 시퀀스가 주어지면 출력 시퀀스의 조건부 확률은 다음과 같이 계산할 수 있습니다.
이 분해는 입력 시퀀스가 주어졌을 때 출력 시퀀스의 확률이 다음과 같이 나누어 표현될 수 있음을 의미합니다. 주어진 입력 시퀀스 의 각 출력 토큰은 이전 출력 토큰의 확률을 곱하여 계산됩니다. 예를 들어, 출력 시퀀스는 "나는 책 읽기를 즐긴다"이고 입력 시퀀스는 "나는 즐긴다"입니다. 입력 시퀀스가 주어지면 출력 시퀀스의 조건부 확률은 다음과 같이 계산할 수 있습니다.
 마르코프 프로세스 조건부 확률 정답을 계산하는 데 사용되는 확률 분포와 Zephyr LLM 응답은 손실 함수를 계산하는 데 사용됩니다. 하지만 먼저 조건부 확률 함수를 인코딩해야 합니다.
마르코프 프로세스 조건부 확률 정답을 계산하는 데 사용되는 확률 분포와 Zephyr LLM 응답은 손실 함수를 계산하는 데 사용됩니다. 하지만 먼저 조건부 확률 함수를 인코딩해야 합니다.
# zephyr-sft-dataframe (that contains output that will be improved while training) zephyr_sft_output = pd.DataFrame(columns=['prompt', 'generated_output']) # Looping through each row in the 'ultrachat_50k_sample' dataframe for index, row in ultrachat_50k_sample.iterrows():# Extracting the 'prompt' column value from the current rowprompt = row['prompt'] # Generating output for the current prompt using the Zephyr modelinput_ids = tokenizer(prompt, return_tensors="pt").input_idsoutput = model.generate(input_ids, max_length=200, num_beams=5, no_repeat_ngram_size=2, top_k=50, top_p=0.95) # Decoding the generated output to human-readable textgenerated_text = tokenizer.decode(output[0], skip_special_tokens=True) # Appending the current prompt and its generated output to the new dataframe 'zephyr_sft_output'zephyr_sft_output = zephyr_sft_output.append({'prompt': prompt, 'generated_output': generated_text}, ignore_index=True)손실 함수 4가지 중요한 조건부 확률 변수가 포함되어 있습니다. 이러한 각 변수는 기본 실제 데이터 또는 이전에 생성된 합성 데이터에 따라 달라집니다.
而lambda是一个正则化参数,用于控制偏差。在KL正则化项中使用它来惩罚对手模型的分布与目标数据分布之间的差异。论文中没有明确提到lambda的具体值,因为它可能会根据所使用的特定任务和数据集进行调优。
def LSPIN_loss(model, updated_model, tokenizer, input_text, lambda_val=0.01):# Initialize conditional probability using the original model and input textcp = compute_conditional_probability(tokenizer, model, input_text) # Update conditional probability using the updated model and input textcp_updated = compute_conditional_probability(tokenizer, updated_model, input_text) # Calculate conditional probabilities for ground truth datap_theta_ground_truth = cp(tokenizer, model, input_text)p_theta_t_ground_truth = cp(tokenizer, model, input_text) # Calculate conditional probabilities for synthetic datap_theta_synthetic = cp_updated(tokenizer, updated_model, input_text)p_theta_t_synthetic = cp_updated(tokenizer, updated_model, input_text) # Calculate likelihood ratioslr_ground_truth = p_theta_ground_truth / p_theta_t_ground_truthlr_synthetic = p_theta_synthetic / p_theta_t_synthetic # Compute the LSPIN lossloss = lambda_val * torch.log(lr_ground_truth) - lambda_val * torch.log(lr_synthetic) return loss
如果你有一个大的数据集,可以使用一个较小的lambda值,或者如果你有一个小的数据集,则可能需要使用一个较大的lambda值来防止过拟合。由于我们数据集大小为50k,所以可以使用0.01作为lambda的值。
4、训练(SPIN算法外循环)
这就是Pytorch训练的一个基本流程,就不详细解释了:
# Training loop for epoch in range(num_epochs): # Model with initial parametersinitial_model = AutoModelForCausalLM.from_pretrained("alignment-handbook/zephyr-7b-sft-full") # Update the learning ratescheduler.step() # Initialize total loss for the epochtotal_loss = 0.0 # Generating Synthetic Data (Inner loop)for index, row in ultrachat_50k_sample.iterrows(): # Rest of the code ... # Output == prompt response dataframezephyr_sft_output # Computing loss using LSPIN functionfor (index1, row1), (index2, row2) in zip(ultrachat_50k_sample.iterrows(), zephyr_sft_output.iterrows()):# Assuming 'prompt' and 'generated_output' are the relevant columns in zephyr_sft_outputprompt = row1['prompt']generated_output = row2['generated_output'] # Compute LSPIN lossupdated_model = model # It will be replacing with updated modelloss = LSPIN_loss(initial_model, updated_model, tokenizer, prompt) # Accumulate the losstotal_loss += loss.item() # Backward passloss.backward() # Update the parametersoptimizer.step() # Update the value of betaif epoch == 2:beta = 5.0我们运行3个epoch,它将进行训练并生成最终的Zephyr SFT LLM版本。官方实现还没有在GitHub上开源,这个版本将能够在某种程度上产生类似于人类反应的输出。我们看看他的运行流程
表现及结果
SPIN可以显著提高LLM在各种基准测试中的性能,甚至超过通过直接偏好优化(DPO)补充额外的GPT-4偏好数据训练的模型。
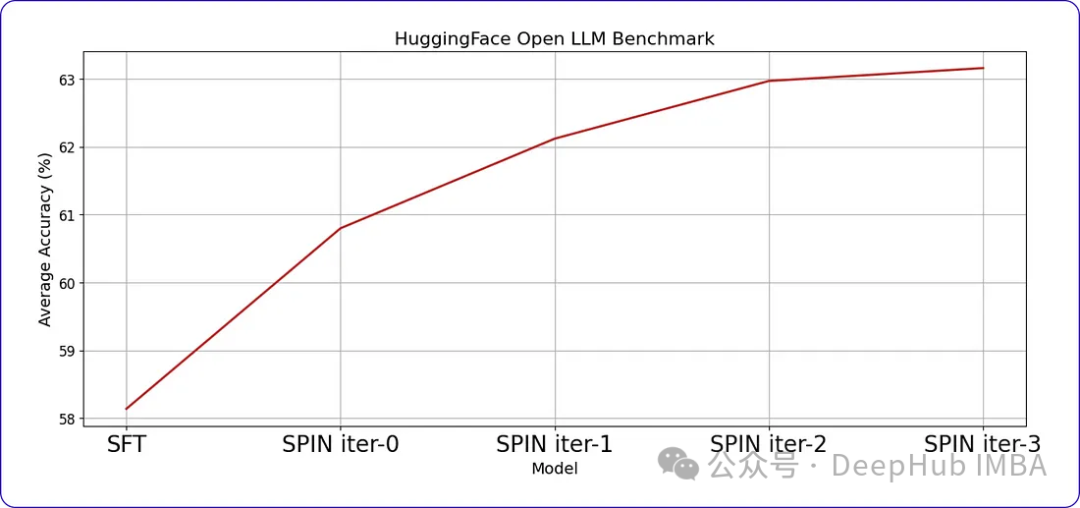
当我们继续训练时,随着时间的推移,进步会变得越来越小。这表明模型达到了一个阈值,进一步的迭代不会带来显著的收益。这是我们训练数据中样本提示符每次迭代后的响应。

위 내용은 자가 게임 미세 조정 훈련을 위한 SPIN 기술을 활용한 LLM 최적화의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7439
7439
 15
1369
52
76
11
32
19
15
1369
52
76
11
32
19

 Bytedance Cutting, SVIP 슈퍼 멤버십 출시: 연간 연속 구독료 499위안, 다양한 AI 기능 제공
Jun 28, 2024 am 03:51 AM
Bytedance Cutting, SVIP 슈퍼 멤버십 출시: 연간 연속 구독료 499위안, 다양한 AI 기능 제공
Jun 28, 2024 am 03:51 AM
이 사이트는 6월 27일에 Jianying이 ByteDance의 자회사인 FaceMeng Technology에서 개발한 비디오 편집 소프트웨어라고 보도했습니다. 이 소프트웨어는 Douyin 플랫폼을 기반으로 하며 기본적으로 플랫폼 사용자를 위한 짧은 비디오 콘텐츠를 제작합니다. Windows, MacOS 및 기타 운영 체제. Jianying은 멤버십 시스템 업그레이드를 공식 발표하고 지능형 번역, 지능형 하이라이트, 지능형 패키징, 디지털 인간 합성 등 다양한 AI 블랙 기술을 포함하는 새로운 SVIP를 출시했습니다. 가격면에서 SVIP 클리핑 월 요금은 79위안, 연간 요금은 599위안(본 사이트 참고: 월 49.9위안에 해당), 월간 연속 구독료는 월 59위안, 연간 연속 구독료는 59위안입니다. 연간 499위안(월 41.6위안)입니다. 또한, 컷 관계자는 "사용자 경험 향상을 위해 기존 VIP에 가입하신 분들도
 Rag 및 Sem-Rag를 사용한 상황 증강 AI 코딩 도우미
Jun 10, 2024 am 11:08 AM
Rag 및 Sem-Rag를 사용한 상황 증강 AI 코딩 도우미
Jun 10, 2024 am 11:08 AM
검색 강화 생성 및 의미론적 메모리를 AI 코딩 도우미에 통합하여 개발자 생산성, 효율성 및 정확성을 향상시킵니다. EnhancingAICodingAssistantswithContextUsingRAGandSEM-RAG에서 번역됨, 저자 JanakiramMSV. 기본 AI 프로그래밍 도우미는 자연스럽게 도움이 되지만, 소프트웨어 언어에 대한 일반적인 이해와 소프트웨어 작성의 가장 일반적인 패턴에 의존하기 때문에 가장 관련성이 높고 정확한 코드 제안을 제공하지 못하는 경우가 많습니다. 이러한 코딩 도우미가 생성한 코드는 자신이 해결해야 할 문제를 해결하는 데 적합하지만 개별 팀의 코딩 표준, 규칙 및 스타일을 따르지 않는 경우가 많습니다. 이로 인해 코드가 애플리케이션에 승인되기 위해 수정되거나 개선되어야 하는 제안이 나타나는 경우가 많습니다.
 미세 조정을 통해 LLM이 실제로 새로운 것을 배울 수 있습니까? 새로운 지식을 도입하면 모델이 더 많은 환각을 생성할 수 있습니다.
Jun 11, 2024 pm 03:57 PM
미세 조정을 통해 LLM이 실제로 새로운 것을 배울 수 있습니까? 새로운 지식을 도입하면 모델이 더 많은 환각을 생성할 수 있습니다.
Jun 11, 2024 pm 03:57 PM
LLM(대형 언어 모델)은 대규모 텍스트 데이터베이스에서 훈련되어 대량의 실제 지식을 습득합니다. 이 지식은 매개변수에 내장되어 필요할 때 사용할 수 있습니다. 이러한 모델에 대한 지식은 훈련이 끝나면 "구체화"됩니다. 사전 훈련이 끝나면 모델은 실제로 학습을 중단합니다. 모델을 정렬하거나 미세 조정하여 이 지식을 활용하고 사용자 질문에 보다 자연스럽게 응답하는 방법을 알아보세요. 그러나 때로는 모델 지식만으로는 충분하지 않을 때도 있으며, 모델이 RAG를 통해 외부 콘텐츠에 접근할 수 있더라도 미세 조정을 통해 모델을 새로운 도메인에 적응시키는 것이 유익한 것으로 간주됩니다. 이러한 미세 조정은 인간 주석 작성자 또는 기타 LLM 생성자의 입력을 사용하여 수행됩니다. 여기서 모델은 추가적인 실제 지식을 접하고 이를 통합합니다.
 7가지 멋진 GenAI 및 LLM 기술 인터뷰 질문
Jun 07, 2024 am 10:06 AM
7가지 멋진 GenAI 및 LLM 기술 인터뷰 질문
Jun 07, 2024 am 10:06 AM
AIGC에 대해 자세히 알아보려면 다음을 방문하세요. 51CTOAI.x 커뮤니티 https://www.51cto.com/aigc/Translator|Jingyan Reviewer|Chonglou는 인터넷 어디에서나 볼 수 있는 전통적인 문제 은행과 다릅니다. 고정관념에서 벗어나 생각해야 합니다. LLM(대형 언어 모델)은 데이터 과학, 생성 인공 지능(GenAI) 및 인공 지능 분야에서 점점 더 중요해지고 있습니다. 이러한 복잡한 알고리즘은 인간의 기술을 향상시키고 많은 산업 분야에서 효율성과 혁신을 촉진하여 기업이 경쟁력을 유지하는 데 핵심이 됩니다. LLM은 자연어 처리, 텍스트 생성, 음성 인식 및 추천 시스템과 같은 분야에서 광범위하게 사용될 수 있습니다. LLM은 대량의 데이터로부터 학습하여 텍스트를 생성할 수 있습니다.
 대형 모델에 대한 새로운 과학적이고 복잡한 질문 답변 벤치마크 및 평가 시스템을 제공하기 위해 UNSW, Argonne, University of Chicago 및 기타 기관이 공동으로 SciQAG 프레임워크를 출시했습니다.
Jul 25, 2024 am 06:42 AM
대형 모델에 대한 새로운 과학적이고 복잡한 질문 답변 벤치마크 및 평가 시스템을 제공하기 위해 UNSW, Argonne, University of Chicago 및 기타 기관이 공동으로 SciQAG 프레임워크를 출시했습니다.
Jul 25, 2024 am 06:42 AM
편집자 |ScienceAI 질문 응답(QA) 데이터 세트는 자연어 처리(NLP) 연구를 촉진하는 데 중요한 역할을 합니다. 고품질 QA 데이터 세트는 모델을 미세 조정하는 데 사용될 수 있을 뿐만 아니라 LLM(대형 언어 모델)의 기능, 특히 과학적 지식을 이해하고 추론하는 능력을 효과적으로 평가하는 데에도 사용할 수 있습니다. 현재 의학, 화학, 생물학 및 기타 분야를 포괄하는 과학적인 QA 데이터 세트가 많이 있지만 이러한 데이터 세트에는 여전히 몇 가지 단점이 있습니다. 첫째, 데이터 형식이 비교적 단순하고 대부분이 객관식 질문이므로 평가하기 쉽지만 모델의 답변 선택 범위가 제한되고 모델의 과학적 질문 답변 능력을 완전히 테스트할 수 없습니다. 이에 비해 개방형 Q&A는
 당신이 모르는 머신러닝의 5가지 학교
Jun 05, 2024 pm 08:51 PM
당신이 모르는 머신러닝의 5가지 학교
Jun 05, 2024 pm 08:51 PM
머신 러닝은 명시적으로 프로그래밍하지 않고도 컴퓨터가 데이터로부터 학습하고 능력을 향상시킬 수 있는 능력을 제공하는 인공 지능의 중요한 분야입니다. 머신러닝은 이미지 인식, 자연어 처리, 추천 시스템, 사기 탐지 등 다양한 분야에서 폭넓게 활용되며 우리의 삶의 방식을 변화시키고 있습니다. 기계 학습 분야에는 다양한 방법과 이론이 있으며, 그 중 가장 영향력 있는 5가지 방법을 "기계 학습의 5개 학교"라고 합니다. 5개 주요 학파는 상징학파, 연결주의 학파, 진화학파, 베이지안 학파, 유추학파이다. 1. 상징주의라고도 알려진 상징주의는 논리적 추론과 지식 표현을 위해 상징을 사용하는 것을 강조합니다. 이 사고 학교는 학습이 기존을 통한 역연역 과정이라고 믿습니다.
 SOTA 성능, 샤먼 다중 모드 단백질-리간드 친화성 예측 AI 방법, 최초로 분자 표면 정보 결합
Jul 17, 2024 pm 06:37 PM
SOTA 성능, 샤먼 다중 모드 단백질-리간드 친화성 예측 AI 방법, 최초로 분자 표면 정보 결합
Jul 17, 2024 pm 06:37 PM
Editor | KX 약물 연구 및 개발 분야에서 단백질과 리간드의 결합 친화도를 정확하고 효과적으로 예측하는 것은 약물 스크리닝 및 최적화에 매우 중요합니다. 그러나 현재 연구에서는 단백질-리간드 상호작용에서 분자 표면 정보의 중요한 역할을 고려하지 않습니다. 이를 기반으로 Xiamen University의 연구자들은 처음으로 단백질 표면, 3D 구조 및 서열에 대한 정보를 결합하고 교차 주의 메커니즘을 사용하여 다양한 양식 특징을 비교하는 새로운 다중 모드 특징 추출(MFE) 프레임워크를 제안했습니다. 조정. 실험 결과는 이 방법이 단백질-리간드 결합 친화도를 예측하는 데 있어 최첨단 성능을 달성한다는 것을 보여줍니다. 또한 절제 연구는 이 프레임워크 내에서 단백질 표면 정보와 다중 모드 기능 정렬의 효율성과 필요성을 보여줍니다. 관련 연구는 "S"로 시작된다
 AI와 같은 시장을 개척하는 GlobalFoundries는 Tagore Technology의 질화 갈륨 기술 및 관련 팀을 인수합니다.
Jul 15, 2024 pm 12:21 PM
AI와 같은 시장을 개척하는 GlobalFoundries는 Tagore Technology의 질화 갈륨 기술 및 관련 팀을 인수합니다.
Jul 15, 2024 pm 12:21 PM
7월 5일 이 웹사이트의 소식에 따르면 글로벌파운드리는 올해 7월 1일 보도자료를 통해 타고르 테크놀로지(Tagore Technology)의 전력질화갈륨(GaN) 기술 및 지적재산권 포트폴리오 인수를 발표하고 자동차와 인터넷 시장 점유율 확대를 희망하고 있다고 밝혔다. 더 높은 효율성과 더 나은 성능을 탐구하기 위한 사물 및 인공 지능 데이터 센터 응용 분야입니다. 생성 AI와 같은 기술이 디지털 세계에서 계속 발전함에 따라 질화갈륨(GaN)은 특히 데이터 센터에서 지속 가능하고 효율적인 전력 관리를 위한 핵심 솔루션이 되었습니다. 이 웹사이트는 이번 인수 기간 동안 Tagore Technology의 엔지니어링 팀이 GLOBALFOUNDRIES에 합류하여 질화갈륨 기술을 더욱 개발할 것이라는 공식 발표를 인용했습니다. G
