

MySQL的表分区(转载)_MySQL

bitsCN.com
MySQL的表分区(转载)
一、什么是表分区 通俗地讲表分区是将一大表,根据条件分割成若干个小表。mysql5.1开始支持数据表分区了。 如:某用户表的记录超过了600万条,那么就可以根据入库日期将表分区,也可以根据所在地将表分区。当然也可根据其他的条件分区。
二、为什么要对表进行分区 为了改善大型表以及具有各种访问模式的表的可伸缩性,可管理性和提高数据库效率。
分区的一些优点包括: 1)、与单个磁盘或文件系统分区相比,可以存储更多的数据。 2)、对于那些已经失去保存意义的数据,通常可以通过删除与那些数据有关的分区,很容易地删除那些数据。相反地,在某些情况下,添加新数据的过程又可以通过为那些新数据专门增加一个新的分区,来很方便地实现。通常和分区有关的其他优点包括下面列出的这些。MySQL分区中的这些功能目前还没有实现,但是在我们的优先级列表中,具有高的优先级;我们希望在5.1的生产版本中,能包括这些功能。 3)、一些查询可以得到极大的优化,这主要是借助于满足一个给定WHERE语句的数据可以只保存在一个或多个分区内,这样在查找时就不用查找其他剩余的分区。因为分区可以在创建了分区表后进行修改,所以在第一次配置分区方案时还不曾这么做时,可以重新组织数据,来提高那些常用查询的效率。 4)、涉及到例如SUM()和COUNT()这样聚合函数的查询,可以很容易地进行并行处理。这种查询的一个简单例子如 “SELECT salesperson_id, COUNT (orders) as order_total FROM sales GROUP BY salesperson_id;”。通过“并行”,这意味着该查询可以在每个分区上同时进行,最终结果只需通过总计所有分区得到的结果。 5)、通过跨多个磁盘来分散数据查询,来获得更大的查询吞吐量。
三、分区类型
· RANGE分区:基于属于一个给定连续区间的列值,把多行分配给分区。 · LIST分区:类似于按RANGE分区,区别在于LIST分区是基于列值匹配一个离散值集合中的某个值来进行选择。 · HASH分区:基于用户定义的表达式的返回值来进行选择的分区,该表达式使用将要插入到表中的这些行的列值进行计算。这个函数可以包含MySQL 中有效的、产生非负整数值的任何表达式。 · KEY分区:类似于按HASH分区,区别在于KEY分区只支持计算一列或多列,且MySQL 服务器提供其自身的哈希函数。必须有一列或多列包含整数值。
- RANGE分区
基于属于一个给定连续区间的列值,把多行分配给分区。
这些区间要连续且不能相互重叠,使用VALUES LESS THAN操作符来进行定义。以下是实例。
Sql代码

- CREATE TABLE employees (
- id INT NOT NULL,
- fname VARCHAR(30),
- lname VARCHAR(30),
- hired DATE NOT NULL DEFAULT '1970-01-01',
- separated DATE NOT NULL DEFAULT '9999-12-31',
- job_code INT NOT NULL,
- store_id INT NOT NULL
- )
- partition BY RANGE (store_id) (
- partition p0 VALUES LESS THAN (6),
- partition p1 VALUES LESS THAN (11),
- partition p2 VALUES LESS THAN (16),
- partition p3 VALUES LESS THAN (21)
- );
按照这种分区方案,在商店1到5工作的雇员相对应的所有行被保存在分区P0中,商店6到10的雇员保存在P1中,依次类推。注意,每个分区都是按顺序进行定义,从最低到最高。这是PARTITION BY RANGE 语法的要求;在这点上,它类似于C或Java中的“switch ... case”语句。 对于包含数据(72, 'Michael', 'Widenius', '1998-06-25', NULL, 13)的一个新行,可以很容易地确定它将插入到p2分区中,但是如果增加了一个编号为第21的商店,将会发生什么呢?在这种方案下,由于没有规则把store_id大于20的商店包含在内,服务器将不知道把该行保存在何处,将会导致错误。 要避免这种错误,可以通过在CREATE TABLE语句中使用一个“catchall” VALUES LESS THAN子句,该子句提供给所有大于明确指定的最高值的值:
Sql代码- CREATE TABLE employees (
- id INT NOT NULL,
- fname VARCHAR(30),
- lname VARCHAR(30),
- hired DATE NOT NULL DEFAULT '1970-01-01',
- separated DATE NOT NULL DEFAULT '9999-12-31',
- job_code INT NOT NULL,
- store_id INT NOT NULL
- )
- PARTITION BY RANGE (store_id) (
- PARTITION p0 VALUES LESS THAN (6),
- PARTITION p1 VALUES LESS THAN (11),
- PARTITION p2 VALUES LESS THAN (16),
- PARTITION p3 VALUES LESS THAN MAXVALUE
- );
MAXVALUE 表示最大的可能的整数值。现在,store_id 列值大于或等于16(定义了的最高值)的所有行都将保存在分区p3中。在将来的某个时候,当商店数已经增长到25, 30, 或更多 ,可以使用ALTER TABLE语句为商店21-25, 26-30,等等增加新的分区。 在几乎一样的结构中,你还可以基于雇员的工作代码来分割表,也就是说,基于job_code 列值的连续区间。例如——假定2位数字的工作代码用来表示普通(店内的)工人,三个数字代码表示办公室和支持人员,四个数字代码表示管理层,你可以使用下面的语句创建该分区表:
Sql代码- CREATE TABLE employees (
- id INT NOT NULL,
- fname VARCHAR(30),
- lname VARCHAR(30),
- hired DATE NOT NULL DEFAULT '1970-01-01',
- separated DATE NOT NULL DEFAULT '9999-12-31',
- job_code INT NOT NULL,
- store_id INT NOT NULL
- )
- PARTITION BY RANGE (job_code) (
- PARTITION p0 VALUES LESS THAN (100),
- PARTITION p1 VALUES LESS THAN (1000),
- PARTITION p2 VALUES LESS THAN (10000)
- );
在这个例子中, 店内工人相关的所有行将保存在分区p0中,办公室和支持人员相关的所有行保存在分区p1中,管理层相关的所有行保存在分区p2中。 在VALUES LESS THAN 子句中使用一个表达式也是可能的。这里最值得注意的限制是MySQL 必须能够计算表达式的返回值作为LESS THAN (Sql代码
- CREATE TABLE employees (
- id INT NOT NULL,
- fname VARCHAR(30),
- lname VARCHAR(30),
- hired DATE NOT NULL DEFAULT '1970-01-01',
- separated DATE NOT NULL DEFAULT '9999-12-31',
- job_code INT,
- store_id INT
- )
- PARTITION BY RANGE (YEAR(separated)) (
- PARTITION p0 VALUES LESS THAN (1991),
- PARTITION p1 VALUES LESS THAN (1996),
- PARTITION p2 VALUES LESS THAN (2001),
- PARTITION p3 VALUES LESS THAN MAXVALUE
- );
在这个方案中,在1991年前雇佣的所有雇员的记录保存在分区p0中,1991年到1995年期间雇佣的所有雇员的记录保存在分区p1中, 1996年到2000年期间雇佣的所有雇员的记录保存在分区p2中,2000年后雇佣的所有工人的信息保存在p3中。
RANGE分区在如下场合特别有用: 1)、 当需要删除一个分区上的“旧的”数据时,只删除分区即可。如果你使用上面最近的那个例子给出的分区方案,你只需简单地使用 “ALTER TABLE employees DROP PARTITION p0;”来删除所有在1991年前就已经停止工作的雇员相对应的所有行。对于有大量行的表,这比运行一个如“DELETE FROM employees WHERE YEAR (separated)
注释:这种优化还没有在MySQL 5.1源程序中启用,但是,有关工作正在进行中。
- LIST分区
类似于按RANGE分区,区别在于LIST分区是基于列值匹配一个离散值集合中的某个值来进行选择。
LIST分区通过使用“PARTITION BY LIST(expr)”来实现,其中“expr” 是某列值或一个基于某个列值、并返回一个整数值的表达式,然后通过“VALUES IN (value_list)”的方式来定义每个分区,其中“value_list”是一个通过逗号分隔的整数列表。 注释:在MySQL 5.1中,当使用LIST分区时,有可能只能匹配整数列表。
Sql代码- CREATE TABLE employees (
- id INT NOT NULL,
- fname VARCHAR(30),
- lname VARCHAR(30),
- hired DATE NOT NULL DEFAULT '1970-01-01',
- separated DATE NOT NULL DEFAULT '9999-12-31',
- job_code INT,
- store_id INT
- );
假定有20个音像店,分布在4个有经销权的地区,如下表所示:
==================== 地区 商店ID 号
------------------------------------
北区 3, 5, 6, 9, 17 东区 1, 2, 10, 11, 19, 20 西区 4, 12, 13, 14, 18 中心区 7, 8, 15, 16
==================== 要按照属于同一个地区商店的行保存在同一个分区中的方式来分割表,可以使用下面的“CREATE TABLE”语句:
Sql代码- CREATE TABLE employees (
- id INT NOT NULL,
- fname VARCHAR(30),
- lname VARCHAR(30),
- hired DATE NOT NULL DEFAULT '1970-01-01',
- separated DATE NOT NULL DEFAULT '9999-12-31',
- job_code INT,
- store_id INT
- )
- PARTITION BY LIST(store_id)
- PARTITION pNorth VALUES IN (3,5,6,9,17),
- PARTITION pEast VALUES IN (1,2,10,11,19,20),
- PARTITION pWest VALUES IN (4,12,13,14,18),
- PARTITION pCentral VALUES IN (7,8,15,16)
- );
这使得在表中增加或删除指定地区的雇员记录变得容易起来。例如,假定西区的所有音像店都卖给了其他公司。那么与在西区音像店工作雇员相关的所有记录(行)可以使用查询“ALTER TABLE employees DROP PARTITION pWest;”来进行删除,它与具有同样作用的DELETE (删除)查询“DELETE query DELETE FROM employees WHERE store_id IN (4,12,13,14,18);”比起来,要有效得多。 【要点】:如果试图插入列值(或分区表达式的返回值)不在分区值列表中的一行时,那么“INSERT”查询将失败并报错。例如,假定LIST分区的采用上面的方案,下面的查询将失败:
Sql代码- INSERT INTO employees VALUES(224, 'Linus', 'Torvalds', '2002-05-01', '2004-10-12', 42, 21);
这是因为“store_id”列值21不能在用于定义分区pNorth, pEast, pWest,或pCentral的值列表中找到。要重点注意的是,LIST分区没有类似如“VALUES LESS THAN MAXVALUE”这样的包含其他值在内的定义。将要匹配的任何值都必须在值列表中找到。
LIST分区除了能和RANGE分区结合起来生成一个复合的子分区,与HASH和KEY分区结合起来生成复合的子分区也是可能的。
- HASH分区
基于用户定义的表达式的返回值来进行选择的分区,该表达式使用将要插入到表中的这些行的列值进行计算。这个函数可以包含MySQL 中有效的、产生非负整数值的任何表达式。
要使用HASH分区来分割一个表,要在CREATE TABLE 语句上添加一个“PARTITION BY HASH (expr)”子句,其中“expr”是一个返回一个整数的表达式。它可以仅仅是字段类型为MySQL 整型的一列的名字。此外,你很可能需要在后面再添加一个“PARTITIONS num”子句,其中num 是一个非负的整数,它表示表将要被分割成分区的数量。
Sql代码- CREATE TABLE employees (
- id INT NOT NULL,
- fname VARCHAR(30),
- lname VARCHAR(30),
- hired DATE NOT NULL DEFAULT '1970-01-01',
- separated DATE NOT NULL DEFAULT '9999-12-31',
- job_code INT,
- store_id INT
- )
- PARTITION BY HASH(store_id)
- PARTITIONS 4;
如果没有包括一个PARTITIONS子句,那么分区的数量将默认为1。 例外: 对于NDB Cluster(簇)表,默认的分区数量将与簇数据节点的数量相同,
这种修正可能是考虑任何MAX_ROWS 设置,以便确保所有的行都能合适地插入到分区中。
- LINER HASH
MySQL还支持线性哈希功能,它与常规哈希的区别在于,线性哈希功能使用的一个线性的2的幂(powers-of-two)运算法则,而常规 哈希使用的是求哈希函数值的模数。 线性哈希分区和常规哈希分区在语法上的唯一区别在于,在“PARTITION BY” 子句中添加“LINEAR”关键字。
Sql代码- CREATE TABLE employees (
- id INT NOT NULL,
- fname VARCHAR(30),
- lname VARCHAR(30),
- hired DATE NOT NULL DEFAULT '1970-01-01',
- separated DATE NOT NULL DEFAULT '9999-12-31',
- job_code INT,
- store_id INT
- )
- PARTITION BY LINEAR HASH(YEAR(hired))
- PARTITIONS 4;
假设一个表达式expr, 当使用线性哈希功能时,记录将要保存到的分区是num 个分区中的分区N,其中N是根据下面的算法得到: 1. 找到下一个大于num.的、2的幂,我们把这个值称为V ,它可以通过下面的公式得到: 2. V = POWER(2, CEILING(LOG(2, num))) (例如,假定num是13。那么LOG(2,13)就是3.7004397181411。 CEILING(3.7004397181411)就是4,则V = POWER(2,4), 即等于16)。 3. 设置 N = F(column_list) & (V - 1). 4. 当 N >= num: · 设置 V = CEIL(V / 2) · 设置 N = N & (V - 1) 例如,假设表t1,使用线性哈希分区且有4个分区,是通过下面的语句创建的: CREATE TABLE t1 (col1 INT, col2 CHAR(5), col3 DATE) PARTITION BY LINEAR HASH( YEAR(col3) ) PARTITIONS 6; 现在假设要插入两行记录到表t1中,其中一条记录col3列值为'2003-04-14',另一条记录col3列值为'1998-10-19'。第一条记录将要保存到的分区确定如下: V = POWER(2, CEILING(LOG(2,7))) = 8 N = YEAR('2003-04-14') & (8 - 1) = 2003 & 7 = 3 (3 >= 6 为假(FALSE): 记录将被保存到#3号分区中) 第二条记录将要保存到的分区序号计算如下: V = 8 N = YEAR('1998-10-19') & (8-1) = 1998 & 7 = 6 (6 >= 4 为真(TRUE): 还需要附加的步骤) N = 6 & CEILING(5 / 2) = 6 & 3 = 2 (2 >= 4 为假(FALSE): 记录将被保存到#2分区中) 按照线性哈希分区的优点在于增加、删除、合并和拆分分区将变得更加快捷,有利于处理含有极其大量(1000吉)数据的表。它的缺点在于,与使用
常规HASH分区得到的数据分布相比,各个分区间数据的分布不大可能均衡。
- KSY分区
类似于按HASH分区,区别在于KEY分区只支持计算一列或多列,且MySQL 服务器提供其自身的哈希函数。必须有一列或多列包含整数值。
Sql代码- CREATE TABLE tk (
- col1 INT NOT NULL,
- col2 CHAR(5),
- col3 DATE
- )
- PARTITION BY LINEAR KEY (col1)
- PARTITIONS 3;
在KEY分区中使用关键字LINEAR和在HASH分区中使用具有同样的作用,分区的编号是通过2的幂(powers-of-two)算法得到,而不是通过模数算法。
bitsCN.com
핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7531
7531
 15
1379
52
82
11
55
19
21
77
15
1379
52
82
11
55
19
21
77

 Xiaohongshu 계정을 사용하여 사용자를 찾는 방법은 무엇입니까? 내 휴대폰 번호를 찾을 수 있나요?
Mar 22, 2024 am 08:40 AM
Xiaohongshu 계정을 사용하여 사용자를 찾는 방법은 무엇입니까? 내 휴대폰 번호를 찾을 수 있나요?
Mar 22, 2024 am 08:40 AM
소셜 미디어의 급속한 발전으로 Xiaohongshu는 가장 인기 있는 소셜 플랫폼 중 하나가 되었습니다. 사용자는 Xiaohongshu 계정을 만들어 자신의 개인 신원을 표시하고 다른 사용자와 소통하고 상호 작용할 수 있습니다. 사용자의 Xiaohongshu 번호를 찾으려면 다음의 간단한 단계를 따르세요. 1. Xiaohongshu 계정을 사용하여 사용자를 찾는 방법은 무엇입니까? 1. Xiaohongshu 앱을 열고 오른쪽 하단에 있는 "검색" 버튼을 클릭한 다음 "메모" 옵션을 선택합니다. 2. 노트 목록에서 찾고자 하는 사용자가 게시한 노트를 찾아보세요. 클릭하시면 메모 세부정보 페이지로 이동합니다. 3. 노트 상세페이지에서 해당 사용자의 아바타 아래 '팔로우' 버튼을 클릭하여 해당 사용자의 개인 홈페이지로 진입합니다. 4. 이용자 개인 홈페이지 우측 상단의 점 3개 버튼 클릭 후 '개인정보' 선택
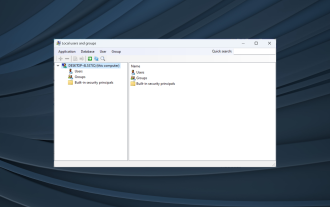 Windows 11에 로컬 사용자 및 그룹이 없습니다: 추가하는 방법
Sep 22, 2023 am 08:41 AM
Windows 11에 로컬 사용자 및 그룹이 없습니다: 추가하는 방법
Sep 22, 2023 am 08:41 AM
로컬 사용자 및 그룹 유틸리티는 컴퓨터 관리에 내장되어 있으며 콘솔에서 또는 독립적으로 액세스할 수 있습니다. 그러나 일부 사용자는 Windows 11에 로컬 사용자 및 그룹이 누락되어 있음을 발견합니다. 액세스 권한이 있는 일부 사용자에게는 이 스냅인이 이 버전의 Windows 10에서 작동하지 않을 수 있다는 메시지가 표시됩니다. 이 컴퓨터의 사용자 계정을 관리하려면 제어판의 사용자 계정 도구를 사용하십시오. 이 문제는 Windows 10의 이전 버전에서 보고되었으며 일반적으로 사용자 측의 문제 또는 감독으로 인해 발생합니다. Windows 11에서 로컬 사용자 및 그룹이 누락되는 이유는 무엇입니까? Windows Home 버전을 실행 중이며 Professional 버전 이상에서는 로컬 사용자 및 그룹을 사용할 수 있습니다. 활동
 슈퍼유저로 Ubuntu에 로그인
Mar 20, 2024 am 10:55 AM
슈퍼유저로 Ubuntu에 로그인
Mar 20, 2024 am 10:55 AM
Ubuntu 시스템에서는 루트 사용자가 일반적으로 비활성화되어 있습니다. 루트 사용자를 활성화하려면 passwd 명령을 사용하여 비밀번호를 설정한 다음 su- 명령을 사용하여 루트로 로그인할 수 있습니다. 루트 사용자는 무제한 시스템 관리 권한을 가진 사용자입니다. 그는 파일, 사용자 관리, 소프트웨어 설치 및 제거, 시스템 구성 변경에 액세스하고 수정할 수 있는 권한을 가지고 있습니다. 루트 사용자와 일반 사용자 사이에는 분명한 차이가 있습니다. 루트 사용자는 시스템에서 가장 높은 권한과 더 넓은 제어 권한을 갖습니다. 루트 사용자는 일반 사용자가 할 수 없는 중요한 시스템 명령을 실행하고 시스템 파일을 편집할 수 있습니다. 이 가이드에서는 Ubuntu 루트 사용자, 루트로 로그인하는 방법, 일반 사용자와 어떻게 다른지 살펴보겠습니다. 알아채다
 핀둬둬에서 구매한 내역은 어디서 확인할 수 있나요? 구매한 내역은 어떻게 확인하나요?
Mar 12, 2024 pm 07:20 PM
핀둬둬에서 구매한 내역은 어디서 확인할 수 있나요? 구매한 내역은 어떻게 확인하나요?
Mar 12, 2024 pm 07:20 PM
Pinduoduo 소프트웨어는 좋은 제품을 많이 제공하고 언제 어디서나 구입할 수 있으며 각 제품의 품질은 엄격하게 통제되고 모든 제품은 정품이며 우대 쇼핑 할인이 많아 누구나 온라인 쇼핑을 할 수 있습니다. 온라인으로 로그인하려면 휴대폰 번호를 입력하고, 온라인으로 여러 배송 주소와 연락처 정보를 추가하고, 다양한 카테고리의 제품 섹션을 언제든지 확인하고 구매하고 주문하세요. 집을 떠나지 않고도 편리함을 경험할 수 있습니다. 온라인 쇼핑 서비스를 이용하면 구매한 상품을 포함한 모든 구매 기록을 볼 수 있으며, 수십 개의 쇼핑 빨간 봉투와 쿠폰을 무료로 받을 수 있습니다. 이제 편집자가 자세한 온라인 정보를 제공합니다. Pinduoduo 사용자는 구매한 제품 기록을 볼 수 있습니다. 1. 휴대폰을 열고 핀둬둬 아이콘을 클릭하세요.
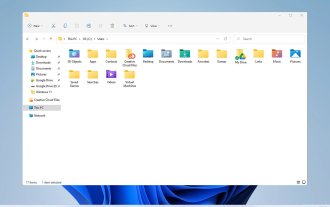 Windows 11 가이드 살펴보기: 기존 하드 드라이브의 사용자 폴더에 액세스하는 방법
Sep 27, 2023 am 10:17 AM
Windows 11 가이드 살펴보기: 기존 하드 드라이브의 사용자 폴더에 액세스하는 방법
Sep 27, 2023 am 10:17 AM
권한으로 인해 특정 폴더에 항상 액세스할 수 있는 것은 아닙니다. 오늘 가이드에서는 Windows 11의 기존 하드 드라이브에 있는 사용자 폴더에 액세스하는 방법을 보여 드리겠습니다. 프로세스는 간단하지만 드라이브 크기에 따라 시간이 걸릴 수 있으며 때로는 몇 시간이 걸릴 수도 있으므로 인내심을 갖고 이 가이드의 지침을 자세히 따르십시오. 기존 하드 드라이브에 있는 사용자 폴더에 액세스할 수 없는 이유는 무엇입니까? 사용자 폴더는 다른 컴퓨터의 소유이므로 수정할 수 없습니다. 이 폴더에 대한 소유권 외에는 어떤 권한도 없습니다. 오래된 하드 드라이브에서 사용자 파일을 여는 방법은 무엇입니까? 1. 폴더 소유권을 가져오고 권한을 변경합니다. 이전 사용자 디렉터리를 찾아 마우스 오른쪽 버튼으로 클릭하고 속성을 선택합니다. "안"으로 이동
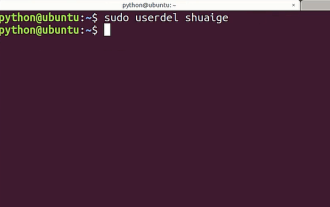 튜토리얼: Ubuntu 시스템에서 일반 사용자 계정을 삭제하는 방법은 무엇입니까?
Jan 02, 2024 pm 12:34 PM
튜토리얼: Ubuntu 시스템에서 일반 사용자 계정을 삭제하는 방법은 무엇입니까?
Jan 02, 2024 pm 12:34 PM
Ubuntu 시스템에 많은 사용자가 추가되었습니다. 더 이상 사용하지 않는 사용자를 삭제하고 싶습니다. 아래의 자세한 튜토리얼을 살펴보겠습니다. 1. 터미널 명령줄을 열고 userdel 명령을 사용하여 지정된 사용자를 삭제합니다. 2. 삭제 시 반드시 일반 사용자 디렉터리에 있어야 합니다. 아래 그림과 같이 이 권한이 없습니다. 3. 삭제 명령을 실행한 후 실제로 삭제되었는지 어떻게 판단할 수 있나요? 다음으로 아래 그림과 같이 cat 명령을 사용하여 passwd 파일을 엽니다. 4. 삭제된 사용자 정보가 더 이상 passwd 파일에 없는 것을 볼 수 있으며 이는 아래 그림과 같이 사용자가 삭제되었음을 증명합니다. 5. 그런 다음 홈 파일을 입력합니다.
 sudo란 무엇이며 왜 중요한가요?
Feb 21, 2024 pm 07:01 PM
sudo란 무엇이며 왜 중요한가요?
Feb 21, 2024 pm 07:01 PM
sudo(수퍼유저 실행)는 일반 사용자가 루트 권한으로 특정 명령을 실행할 수 있도록 하는 Linux 및 Unix 시스템의 핵심 명령입니다. sudo의 기능은 주로 다음 측면에 반영됩니다. 권한 제어 제공: sudo는 사용자에게 일시적으로 수퍼유저 권한을 얻을 수 있는 권한을 부여하여 시스템 리소스와 민감한 작업을 엄격하게 제어합니다. 일반 사용자는 필요할 때만 sudo를 통해 임시 권한을 얻을 수 있으며, 항상 슈퍼유저로 로그인할 필요는 없습니다. 향상된 보안: sudo를 사용하면 일상적인 작업 중에 루트 계정을 사용하지 않아도 됩니다. 모든 작업에 루트 계정을 사용하면 올바르지 않거나 부주의한 작업에는 전체 권한이 부여되므로 예기치 않은 시스템 손상이 발생할 수 있습니다. 그리고
 Windows 11 KB5031455 설치에 실패하여 일부 사용자에게 다른 문제 발생
Nov 01, 2023 am 08:17 AM
Windows 11 KB5031455 설치에 실패하여 일부 사용자에게 다른 문제 발생
Nov 01, 2023 am 08:17 AM
Microsoft는 Windows 503145511H22 이상에 대한 선택적 업데이트로 KB2를 대중에게 출시하기 시작했습니다. 이는 지원되는 영역의 Windows Copilot, 시작 메뉴 항목에 대한 미리 보기 지원, 작업 표시줄 그룹 해제 등을 포함하여 Windows 11 Moment 4 기능을 기본적으로 활성화하는 첫 번째 업데이트입니다. 또한 메모리 누수를 일으키는 잠재적인 성능 문제를 포함하여 여러 Windows 11 버그를 수정합니다. 하지만 아이러니하게도 2023년 9월의 선택적 업데이트는 업데이트를 설치하려는 사용자에게, 심지어 이미 설치한 사용자에게도 재앙이 될 것입니다. 많은 사용자가 이 Wi-Fi를 설치하지 않을 것입니다.
