

Meta의 공식 Prompt 프로젝트 가이드: Llama 2는 이런 방식으로 사용하면 더 효율적입니다.

LLM(대형 언어 모델) 기술이 성숙해짐에 따라 신속한 엔지니어링이 점점 더 중요해지고 있습니다. Microsoft, OpenAI 등을 포함한 여러 연구 기관에서 LLM 프롬프트 엔지니어링 지침을 발표했습니다.
최근 Meta는 Llama 2 오픈 소스 모델을 위한 대화형 프롬프트 엔지니어링 가이드를 특별히 제공했습니다. 이 가이드에서는 Llama 2 사용에 대한 빠른 엔지니어링과 모범 사례를 다룹니다.
다음은 이 가이드의 핵심 내용입니다.
Llama 모델
2023년 Meta는 Llama와 Llama 2 모델을 출시했습니다. 더 작은 모델은 배포 및 실행 비용이 더 저렴하고, 더 큰 모델은 더 많은 기능을 제공합니다.
Llama 2 시리즈 모델 매개변수 척도는 다음과 같습니다.

Code Llama는 Llama 2를 기반으로 구축된 코드 중심 LLM이며, 다양한 매개변수 척도와 미세 조정 변형도 있습니다.

LLM 배포
LLM은 다음을 포함한 다양한 방법으로 배포 및 액세스할 수 있습니다.
셀프 호스팅: 로컬 하드웨어를 사용하여 추론 실행(예: llama.cpp 사용) Macbook Pro에서 실행되는 Llama 2에서. 장점: 개인 정보 보호/보안이 필요하거나 GPU가 충분한 경우 자체 호스팅이 가장 좋습니다.
클라우드 호스팅: 클라우드 제공업체에 의존하여 AWS, Azure, GCP 등과 같은 클라우드 제공업체를 통해 Llama 2를 실행하는 등 특정 모델을 호스팅하는 인스턴스를 배포합니다. 장점: 클라우드 호스팅은 모델과 해당 런타임을 맞춤설정하는 가장 좋은 방법입니다.
호스팅 API: API를 통해 직접 LLM을 호출합니다. AWS Bedrock, Replicate, Anyscale, Together 등을 포함하여 Llama 2 추론 API를 제공하는 많은 회사가 있습니다. 장점: 호스팅 API는 전체적으로 가장 쉬운 옵션입니다.
Hosted API
Hosted API에는 일반적으로 두 가지 주요 엔드포인트가 있습니다.
1 완료: 주어진 프롬프트에 대한 응답을 생성합니다.
2. chat_completion: 메시지 목록에서 다음 메시지를 생성하여 챗봇과 같은 사용 사례에 대한 보다 명확한 지침과 컨텍스트를 제공합니다.
token
LLM은 토큰이라는 블록 형태로 입력과 출력을 처리하며 각 모델에는 고유한 토큰화 방식이 있습니다. 예를 들어, 다음 문장은
우리의 운명은 별에 기록되어 있습니다.
Llama 2의 토큰화는 ["our", "dest", "iny", "is", "writing", "in", "별들"]. 토큰은 API 가격 책정 및 내부 동작(예: 하이퍼파라미터)을 고려할 때 특히 중요합니다. 각 모델에는 프롬프트가 초과할 수 없는 최대 컨텍스트 길이가 있으며 Llama 2는 4096개 토큰이고 Code Llama는 100,000개 토큰입니다.
노트북 설정
예를 들어 Replicate를 사용하여 Llama 2 채팅을 호출하고 LangChain을 사용하여 채팅 완료 API를 쉽게 설정합니다.
먼저 필수 구성 요소를 설치하세요.
pip install langchain replicate
from typing import Dict, Listfrom langchain.llms import Replicatefrom langchain.memory import ChatMessageHistoryfrom langchain.schema.messages import get_buffer_stringimport os# Get a free API key from https://replicate.com/account/api-tokensos.environ ["REPLICATE_API_TOKEN"] = "YOUR_KEY_HERE"LLAMA2_70B_CHAT = "meta/llama-2-70b-chat:2d19859030ff705a87c746f7e96eea03aefb71f166725aee39692f1476566d48"LLAMA2_13B_CHAT = "meta/llama-2-13b-chat:f4e2de70d66816a838a89eeeb621910adffb0dd0baba3976c96980970978018d"# We'll default to the smaller 13B model for speed; change to LLAMA2_70B_CHAT for more advanced (but slower) generationsDEFAULT_MODEL = LLAMA2_13B_CHATdef completion (prompt: str,model: str = DEFAULT_MODEL,temperature: float = 0.6,top_p: float = 0.9,) -> str:llm = Replicate (model=model,model_kwargs={"temperature": temperature,"top_p": top_p, "max_new_tokens": 1000})return llm (prompt)def chat_completion (messages: List [Dict],model = DEFAULT_MODEL,temperature: float = 0.6,top_p: float = 0.9,) -> str:history = ChatMessageHistory ()for message in messages:if message ["role"] == "user":history.add_user_message (message ["content"])elif message ["role"] == "assistant":history.add_ai_message (message ["content"])else:raise Exception ("Unknown role")return completion (get_buffer_string (history.messages,human_prefix="USER",ai_prefix="ASSISTANT",),model,temperature,top_p,)def assistant (content: str):return { "role": "assistant", "content": content }def user (content: str):return { "role": "user", "content": content }def complete_and_print (prompt: str, model: str = DEFAULT_MODEL):print (f'==============\n {prompt}\n==============')response = completion (prompt, model)print (response, end='\n\n')Completion API
complete_and_print ("The typical color of the sky is:")complete_and_print ("which model version are you?")Chat Completion 모델은 LLM과 상호 작용하기 위한 추가 구조를 제공하여 단일 텍스트 대신 구조화된 메시지 개체 배열을 LLM에 보냅니다. 이 메시지 목록은 계속 진행해야 할 일부 "배경" 또는 "역사적" 정보를 LLM에 제공합니다.
일반적으로 각 메시지에는 역할과 콘텐츠가 포함됩니다.
시스템 역할이 포함된 메시지는 개발자가 LLM에 핵심 지침을 제공하는 데 사용됩니다.
사용자 역할이 포함된 메시지는 일반적으로 사람이 제공한 메시지입니다.
보조 역할이 포함된 메시지는 일반적으로 LLM에서 생성됩니다.
response = chat_completion (messages=[user ("My favorite color is blue."),assistant ("That's great to hear!"),user ("What is my favorite color?"),])print (response)# "Sure, I can help you with that! Your favorite color is blue."LLM 하이퍼파라미터
LLM API 通常会采用影响输出的创造性和确定性的参数。在每一步中,LLM 都会生成 token 及其概率的列表。可能性最小的 token 会从列表中「剪切」(基于 top_p),然后从剩余候选者中随机(温度参数 temperature)选择一个 token。换句话说:top_p 控制生成中词汇的广度,温度控制词汇的随机性,温度参数 temperature 为 0 会产生几乎确定的结果。
def print_tuned_completion (temperature: float, top_p: float):response = completion ("Write a haiku about llamas", temperature=temperature, top_p=top_p)print (f'[temperature: {temperature} | top_p: {top_p}]\n {response.strip ()}\n')print_tuned_completion (0.01, 0.01)print_tuned_completion (0.01, 0.01)# These two generations are highly likely to be the sameprint_tuned_completion (1.0, 1.0)print_tuned_completion (1.0, 1.0)# These two generations are highly likely to be differentprompt 技巧
详细、明确的指令会比开放式 prompt 产生更好的结果:
complete_and_print (prompt="Describe quantum physics in one short sentence of no more than 12 words")# Returns a succinct explanation of quantum physics that mentions particles and states existing simultaneously.
我们可以给定使用规则和限制,以给出明确的指令。
- 风格化,例如:
- 向我解释一下这一点,就像儿童教育网络节目中教授小学生一样;
- 我是一名软件工程师,使用大型语言模型进行摘要。用 250 字概括以下文字;
- 像私家侦探一样一步步追查案件,给出你的答案。
- 格式化
使用要点;
以 JSON 对象形式返回;
使用较少的技术术语并用于工作交流中。
- 限制
- 仅使用学术论文;
- 切勿提供 2020 年之前的来源;
- 如果你不知道答案,就说你不知道。
以下是给出明确指令的例子:
complete_and_print ("Explain the latest advances in large language models to me.")# More likely to cite sources from 2017complete_and_print ("Explain the latest advances in large language models to me. Always cite your sources. Never cite sources older than 2020.")# Gives more specific advances and only cites sources from 2020零样本 prompting
一些大型语言模型(例如 Llama 2)能够遵循指令并产生响应,而无需事先看过任务示例。没有示例的 prompting 称为「零样本 prompting(zero-shot prompting)」。例如:
complete_and_print ("Text: This was the best movie I've ever seen! \n The sentiment of the text is:")# Returns positive sentimentcomplete_and_print ("Text: The director was trying too hard. \n The sentiment of the text is:")# Returns negative sentiment少样本 prompting
添加所需输出的具体示例通常会产生更加准确、一致的输出。这种方法称为「少样本 prompting(few-shot prompting)」。例如:
def sentiment (text):response = chat_completion (messages=[user ("You are a sentiment classifier. For each message, give the percentage of positive/netural/negative."),user ("I liked it"),assistant ("70% positive 30% neutral 0% negative"),user ("It could be better"),assistant ("0% positive 50% neutral 50% negative"),user ("It's fine"),assistant ("25% positive 50% neutral 25% negative"),user (text),])return responsedef print_sentiment (text):print (f'INPUT: {text}')print (sentiment (text))print_sentiment ("I thought it was okay")# More likely to return a balanced mix of positive, neutral, and negativeprint_sentiment ("I loved it!")# More likely to return 100% positiveprint_sentiment ("Terrible service 0/10")# More likely to return 100% negativeRole Prompting
Llama 2 在指定角色时通常会给出更一致的响应,角色为 LLM 提供了所需答案类型的背景信息。
例如,让 Llama 2 对使用 PyTorch 的利弊问题创建更有针对性的技术回答:
complete_and_print ("Explain the pros and cons of using PyTorch.")# More likely to explain the pros and cons of PyTorch covers general areas like documentation, the PyTorch community, and mentions a steep learning curvecomplete_and_print ("Your role is a machine learning expert who gives highly technical advice to senior engineers who work with complicated datasets. Explain the pros and cons of using PyTorch.")# Often results in more technical benefits and drawbacks that provide more technical details on how model layers思维链
简单地添加一个「鼓励逐步思考」的短语可以显著提高大型语言模型执行复杂推理的能力(Wei et al. (2022)),这种方法称为 CoT 或思维链 prompting:
complete_and_print ("Who lived longer Elvis Presley or Mozart?")# Often gives incorrect answer of "Mozart"complete_and_print ("Who lived longer Elvis Presley or Mozart? Let's think through this carefully, step by step.")# Gives the correct answer "Elvis"自洽性(Self-Consistency)
LLM 是概率性的,因此即使使用思维链,一次生成也可能会产生不正确的结果。自洽性通过从多次生成中选择最常见的答案来提高准确性(以更高的计算成本为代价):
import refrom statistics import modedef gen_answer ():response = completion ("John found that the average of 15 numbers is 40.""If 10 is added to each number then the mean of the numbers is?""Report the answer surrounded by three backticks, for example:```123```",model = LLAMA2_70B_CHAT)match = re.search (r'```(\d+)```', response)if match is None:return Nonereturn match.group (1)answers = [gen_answer () for i in range (5)]print (f"Answers: {answers}\n",f"Final answer: {mode (answers)}",)# Sample runs of Llama-2-70B (all correct):# [50, 50, 750, 50, 50]-> 50# [130, 10, 750, 50, 50] -> 50# [50, None, 10, 50, 50] -> 50检索增强生成
有时我们可能希望在应用程序中使用事实知识,那么可以从开箱即用(即仅使用模型权重)的大模型中提取常见事实:
complete_and_print ("What is the capital of the California?", model = LLAMA2_70B_CHAT)# Gives the correct answer "Sacramento"然而,LLM 往往无法可靠地检索更具体的事实或私人信息。模型要么声明它不知道,要么幻想出一个错误的答案:
complete_and_print ("What was the temperature in Menlo Park on December 12th, 2023?")# "I'm just an AI, I don't have access to real-time weather data or historical weather records."complete_and_print ("What time is my dinner reservation on Saturday and what should I wear?")# "I'm not able to access your personal information [..] I can provide some general guidance"检索增强生成(RAG)是指在 prompt 中包含从外部数据库检索的信息(Lewis et al. (2020))。RAG 是将事实纳入 LLM 应用的有效方法,并且比微调更经济实惠,微调可能成本高昂并对基础模型的功能产生负面影响。
MENLO_PARK_TEMPS = {"2023-12-11": "52 degrees Fahrenheit","2023-12-12": "51 degrees Fahrenheit","2023-12-13": "51 degrees Fahrenheit",}def prompt_with_rag (retrived_info, question):complete_and_print (f"Given the following information: '{retrived_info}', respond to: '{question}'")def ask_for_temperature (day):temp_on_day = MENLO_PARK_TEMPS.get (day) or "unknown temperature"prompt_with_rag (f"The temperature in Menlo Park was {temp_on_day} on {day}'",# Retrieved factf"What is the temperature in Menlo Park on {day}?",# User question)ask_for_temperature ("2023-12-12")# "Sure! The temperature in Menlo Park on 2023-12-12 was 51 degrees Fahrenheit."ask_for_temperature ("2023-07-18")# "I'm not able to provide the temperature in Menlo Park on 2023-07-18 as the information provided states that the temperature was unknown."程序辅助语言模型
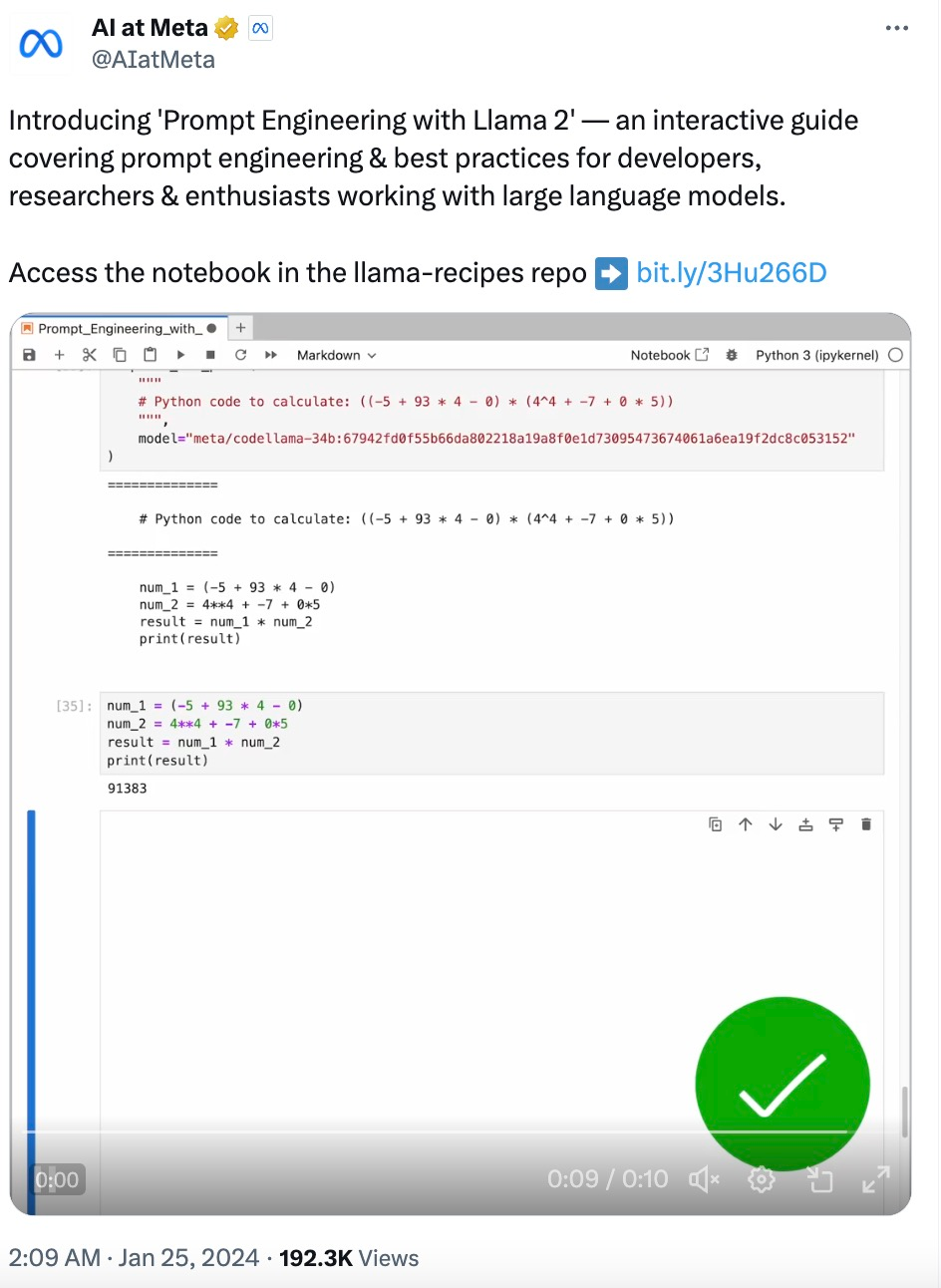
LLM 本质上不擅长执行计算,例如:
complete_and_print ("""Calculate the answer to the following math problem:((-5 + 93 * 4 - 0) * (4^4 + -7 + 0 * 5))""")# Gives incorrect answers like 92448, 92648, 95463Gao et al. (2022) 提出「程序辅助语言模型(Program-aided Language Models,PAL)」的概念。虽然 LLM 不擅长算术,但它们非常擅长代码生成。PAL 通过指示 LLM 编写代码来解决计算任务。
complete_and_print ("""# Python code to calculate: ((-5 + 93 * 4 - 0) * (4^4 + -7 + 0 * 5))""",model="meta/codellama-34b:67942fd0f55b66da802218a19a8f0e1d73095473674061a6ea19f2dc8c053152")# The following code was generated by Code Llama 34B:num1 = (-5 + 93 * 4 - 0)num2 = (4**4 + -7 + 0 * 5)answer = num1 * num2print (answer)
위 내용은 Meta의 공식 Prompt 프로젝트 가이드: Llama 2는 이런 방식으로 사용하면 더 효율적입니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

Video Face Swap
완전히 무료인 AI 얼굴 교환 도구를 사용하여 모든 비디오의 얼굴을 쉽게 바꾸세요!

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7686
7686
 15
1639
14
1393
52
1287
25
1229
29
15
1639
14
1393
52
1287
25
1229
29

 오픈 소스! ZoeDepth를 넘어! DepthFM: 빠르고 정확한 단안 깊이 추정!
Apr 03, 2024 pm 12:04 PM
오픈 소스! ZoeDepth를 넘어! DepthFM: 빠르고 정확한 단안 깊이 추정!
Apr 03, 2024 pm 12:04 PM
0. 이 글은 어떤 내용을 담고 있나요? 우리는 다재다능하고 빠른 최첨단 생성 단안 깊이 추정 모델인 DepthFM을 제안합니다. DepthFM은 전통적인 깊이 추정 작업 외에도 깊이 인페인팅과 같은 다운스트림 작업에서 최첨단 기능을 보여줍니다. DepthFM은 효율적이며 몇 가지 추론 단계 내에서 깊이 맵을 합성할 수 있습니다. 이 작품을 함께 읽어보아요~ 1. 논문 정보 제목: DepthFM: FastMoncularDepthEstimationwithFlowMatching 저자: MingGui, JohannesS.Fischer, UlrichPrestel, PingchuanMa, Dmytr
 세계에서 가장 강력한 오픈 소스 MoE 모델이 여기에 있습니다. 중국의 기능은 GPT-4와 비슷하며 가격은 GPT-4-Turbo의 거의 1%에 불과합니다.
May 07, 2024 pm 04:13 PM
세계에서 가장 강력한 오픈 소스 MoE 모델이 여기에 있습니다. 중국의 기능은 GPT-4와 비슷하며 가격은 GPT-4-Turbo의 거의 1%에 불과합니다.
May 07, 2024 pm 04:13 PM
기존 컴퓨팅을 능가할 뿐만 아니라 더 낮은 비용으로 더 효율적인 성능을 달성하는 인공 지능 모델을 상상해 보세요. 이것은 공상과학 소설이 아닙니다. DeepSeek-V2[1], 세계에서 가장 강력한 오픈 소스 MoE 모델이 여기에 있습니다. DeepSeek-V2는 경제적인 훈련과 효율적인 추론이라는 특징을 지닌 전문가(MoE) 언어 모델의 강력한 혼합입니다. 이는 236B 매개변수로 구성되며, 그 중 21B는 각 마커를 활성화하는 데 사용됩니다. DeepSeek67B와 비교하여 DeepSeek-V2는 더 강력한 성능을 제공하는 동시에 훈련 비용을 42.5% 절감하고 KV 캐시를 93.3% 줄이며 최대 생성 처리량을 5.76배로 늘립니다. DeepSeek은 일반 인공지능을 연구하는 회사입니다.
 AI가 수학적 연구를 전복시킨다! 필즈상 수상자이자 중국계 미국인 수학자, Terence Tao가 좋아하는 11개 논문 발표 |
Apr 09, 2024 am 11:52 AM
AI가 수학적 연구를 전복시킨다! 필즈상 수상자이자 중국계 미국인 수학자, Terence Tao가 좋아하는 11개 논문 발표 |
Apr 09, 2024 am 11:52 AM
AI는 실제로 수학을 변화시키고 있습니다. 최근 이 문제에 주목하고 있는 타오저쉬안(Tao Zhexuan)은 '미국수학회지(Bulletin of the American Mathematical Society)' 최신호를 게재했다. '기계가 수학을 바꿀 것인가?'라는 주제를 중심으로 많은 수학자들이 그들의 의견을 표현했습니다. 저자는 필즈상 수상자 Akshay Venkatesh, 중국 수학자 Zheng Lejun, 뉴욕대학교 컴퓨터 과학자 Ernest Davis 등 업계의 유명 학자들을 포함해 강력한 라인업을 보유하고 있습니다. AI의 세계는 극적으로 변했습니다. 이 기사 중 상당수는 1년 전에 제출되었습니다.
 안녕하세요, 일렉트릭 아틀라스입니다! 보스턴 다이나믹스 로봇 부활, 180도 이상한 움직임에 겁먹은 머스크
Apr 18, 2024 pm 07:58 PM
안녕하세요, 일렉트릭 아틀라스입니다! 보스턴 다이나믹스 로봇 부활, 180도 이상한 움직임에 겁먹은 머스크
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas가 공식적으로 전기 로봇 시대에 돌입했습니다! 어제 유압식 Atlas가 역사의 무대에서 "눈물을 흘리며" 물러났습니다. 오늘 Boston Dynamics는 전기식 Atlas가 작동 중이라고 발표했습니다. 상업용 휴머노이드 로봇 분야에서는 보스턴 다이내믹스가 테슬라와 경쟁하겠다는 각오를 다진 것으로 보인다. 새 영상은 공개된 지 10시간 만에 이미 100만 명이 넘는 조회수를 기록했다. 옛 사람들은 떠나고 새로운 역할이 등장하는 것은 역사적 필연이다. 올해가 휴머노이드 로봇의 폭발적인 해라는 것은 의심의 여지가 없습니다. 네티즌들은 “로봇의 발전으로 올해 개막식도 인간처럼 생겼고, 자유도도 인간보다 훨씬 크다. 그런데 정말 공포영화가 아닌가?”라는 반응을 보였다. 영상 시작 부분에서 아틀라스는 바닥에 등을 대고 가만히 누워 있는 모습입니다. 다음은 입이 떡 벌어지는 내용이다
 MLP를 대체하는 KAN은 오픈소스 프로젝트를 통해 컨볼루션으로 확장되었습니다.
Jun 01, 2024 pm 10:03 PM
MLP를 대체하는 KAN은 오픈소스 프로젝트를 통해 컨볼루션으로 확장되었습니다.
Jun 01, 2024 pm 10:03 PM
이달 초 MIT와 기타 기관의 연구자들은 MLP에 대한 매우 유망한 대안인 KAN을 제안했습니다. KAN은 정확성과 해석성 측면에서 MLP보다 뛰어납니다. 그리고 매우 적은 수의 매개변수로 더 많은 수의 매개변수를 사용하여 실행되는 MLP보다 성능이 뛰어날 수 있습니다. 예를 들어 저자는 KAN을 사용하여 더 작은 네트워크와 더 높은 수준의 자동화로 DeepMind의 결과를 재현했다고 밝혔습니다. 구체적으로 DeepMind의 MLP에는 약 300,000개의 매개변수가 있는 반면 KAN에는 약 200개의 매개변수만 있습니다. KAN은 MLP와 같이 강력한 수학적 기반을 가지고 있으며, KAN은 Kolmogorov-Arnold 표현 정리를 기반으로 합니다. 아래 그림과 같이 KAN은
 FisheyeDetNet: 어안 카메라를 기반으로 한 최초의 표적 탐지 알고리즘
Apr 26, 2024 am 11:37 AM
FisheyeDetNet: 어안 카메라를 기반으로 한 최초의 표적 탐지 알고리즘
Apr 26, 2024 am 11:37 AM
표적 탐지는 자율주행 시스템에서 상대적으로 성숙한 문제이며, 그 중 보행자 탐지는 가장 먼저 배포되는 알고리즘 중 하나입니다. 대부분의 논문에서 매우 포괄적인 연구가 수행되었습니다. 그러나 서라운드 뷰를 위한 어안 카메라를 사용한 거리 인식은 상대적으로 덜 연구되었습니다. 큰 방사형 왜곡으로 인해 표준 경계 상자 표현은 어안 카메라에서 구현하기 어렵습니다. 위의 설명을 완화하기 위해 확장된 경계 상자, 타원 및 일반 다각형 디자인을 극/각 표현으로 탐색하고 인스턴스 분할 mIOU 메트릭을 정의하여 이러한 표현을 분석합니다. 제안된 다각형 형태의 모델 fisheyeDetNet은 다른 모델보다 성능이 뛰어나며 동시에 자율 주행을 위한 Valeo fisheye 카메라 데이터 세트에서 49.5% mAP를 달성합니다.
 초지능의 생명력이 깨어난다! 하지만 자동 업데이트 AI가 등장하면서 엄마들은 더 이상 데이터 병목 현상을 걱정할 필요가 없습니다.
Apr 29, 2024 pm 06:55 PM
초지능의 생명력이 깨어난다! 하지만 자동 업데이트 AI가 등장하면서 엄마들은 더 이상 데이터 병목 현상을 걱정할 필요가 없습니다.
Apr 29, 2024 pm 06:55 PM
세상은 미친 듯이 큰 모델을 만들고 있습니다. 인터넷의 데이터만으로는 충분하지 않습니다. 훈련 모델은 '헝거게임'처럼 생겼고, 전 세계 AI 연구자들은 이러한 데이터를 탐식하는 사람들에게 어떻게 먹이를 줄지 고민하고 있습니다. 이 문제는 다중 모드 작업에서 특히 두드러집니다. 아무것도 할 수 없던 시기에, 중국 인민대학교 학과의 스타트업 팀은 자체 새로운 모델을 사용하여 중국 최초로 '모델 생성 데이터 피드 자체'를 현실화했습니다. 또한 이해 측면과 생성 측면의 두 가지 접근 방식으로 양측 모두 고품질의 다중 모드 새로운 데이터를 생성하고 모델 자체에 데이터 피드백을 제공할 수 있습니다. 모델이란 무엇입니까? Awaker 1.0은 중관촌 포럼에 최근 등장한 대형 멀티모달 모델입니다. 팀은 누구입니까? 소폰 엔진. 런민대학교 힐하우스 인공지능대학원 박사과정 학생인 Gao Yizhao가 설립했습니다.
 Sora 'Ke Ling'의 Kuaishou 버전이 테스트용으로 공개되었습니다. 120초가 넘는 비디오를 생성하고 물리학을 더 잘 이해하며 복잡한 움직임을 정확하게 모델링할 수 있습니다.
Jun 11, 2024 am 09:51 AM
Sora 'Ke Ling'의 Kuaishou 버전이 테스트용으로 공개되었습니다. 120초가 넘는 비디오를 생성하고 물리학을 더 잘 이해하며 복잡한 움직임을 정확하게 모델링할 수 있습니다.
Jun 11, 2024 am 09:51 AM
무엇? 주토피아는 국내 AI로 현실이 되는 걸까? 영상과 함께 노출된 것은 '켈링'이라는 국산 대형 영상세대 신형 모델이다. Sora는 유사한 기술 경로를 사용하고 자체 개발한 여러 기술 혁신을 결합하여 크고 합리적인 움직임뿐만 아니라 물리적 세계의 특성을 시뮬레이션하고 강력한 개념적 결합 능력과 상상력을 갖춘 비디오를 제작합니다. 데이터에 따르면 Keling은 최대 1080p의 해상도로 30fps에서 최대 2분의 초장 영상 생성을 지원하며 다양한 화면비를 지원합니다. 또 다른 중요한 점은 Keling이 실험실에서 공개한 데모나 비디오 결과 시연이 아니라 단편 비디오 분야의 선두주자인 Kuaishou가 출시한 제품 수준 애플리케이션이라는 점입니다. 더욱이 백지 작성이 아닌 실용성에 중점을 두고, 출시되자마자 온라인에 진출하는 데 중점을 두고 있다. 콰이잉에서는 커링의 대형 모델이 출시됐다.
