

Gemini Pro를 따라잡고 추론 및 OCR 기능을 향상시키는 LLaVA-1.6은 너무 강력합니다.

지난해 4월 위스콘신대학교 매디슨캠퍼스, 마이크로소프트 리서치, 컬럼비아대학교 연구진이 공동으로 LLaVA(Large Language and Vision Assistant)를 출시했습니다. LLaVA는 작은 다중 모드 명령 데이터 세트로만 교육되었지만 일부 샘플에서는 GPT-4와 매우 유사한 추론 결과를 보여줍니다. 그런 다음 10월에 원래 LLaVA에 대한 간단한 수정을 통해 11개 벤치마크에서 SOTA를 업데이트한 LLaVA-1.5를 출시했습니다. 이 업그레이드의 결과는 매우 흥미롭고 다중 모드 AI 보조 분야에 새로운 혁신을 가져옵니다.
연구팀은 추론, OCR 및 세계 지식 분야에서 대폭적인 성능 향상을 이룬 LLaVA-1.6 버전의 출시를 발표했습니다. 이 LLaVA-1.6 버전은 여러 벤치마크에서 Gemini Pro보다 성능이 뛰어납니다.
- 데모 주소: https://llava.hliu.cc/
- 프로젝트 주소: https://github.com/haotian-liu/LLaVA
LLaVA-1.5와 비교하여 LLaVA-1.6에는 다음과 같은 개선 사항이 있습니다.
- 입력 이미지 해상도를 4배 높이고 최대 672x672, 336x1344, 1344x336 해상도의 세 가지 화면비를 지원합니다. 이를 통해 LLaVA-1.6은 더 많은 시각적 세부 정보를 캡처할 수 있습니다.
- LLaVA-1.6은 데이터 혼합을 조정하기 위한 향상된 시각적 지침을 통해 더 나은 시각적 추론 및 OCR 기능을 제공합니다.
- 더 나은 시각적 대화, 더 많은 장면, 다양한 응용 프로그램을 포괄합니다. LLaVA-1.6은 더 많은 세계 지식을 습득했으며 더 나은 논리적 추론 능력을 갖추고 있습니다.
- 효율적인 배포 및 추론을 위해 SGLang을 사용하세요.

이미지 출처: https://twitter.com/imhaotian/status/1752621754273472927
LLaVA-1.6은 LLaVA-1.5를 기반으로 미세 조정되고 최적화되었습니다. LLaVA-1.5의 단순한 디자인과 효율적인 데이터 처리 기능을 유지하며 100만 개 미만의 시각적 명령 튜닝 샘플을 계속 사용합니다. 32개의 A100 그래픽 카드를 사용하여 가장 큰 34B 모델을 약 하루만에 학습시켰습니다. 또한 LLaVA-1.6은 130만 개의 데이터 샘플을 활용하며 계산/훈련 데이터 비용은 다른 방법에 비해 100~1000배에 불과합니다. 이러한 개선으로 LLaVA-1.6은 더욱 효율적이고 비용 효율적인 버전이 되었습니다.
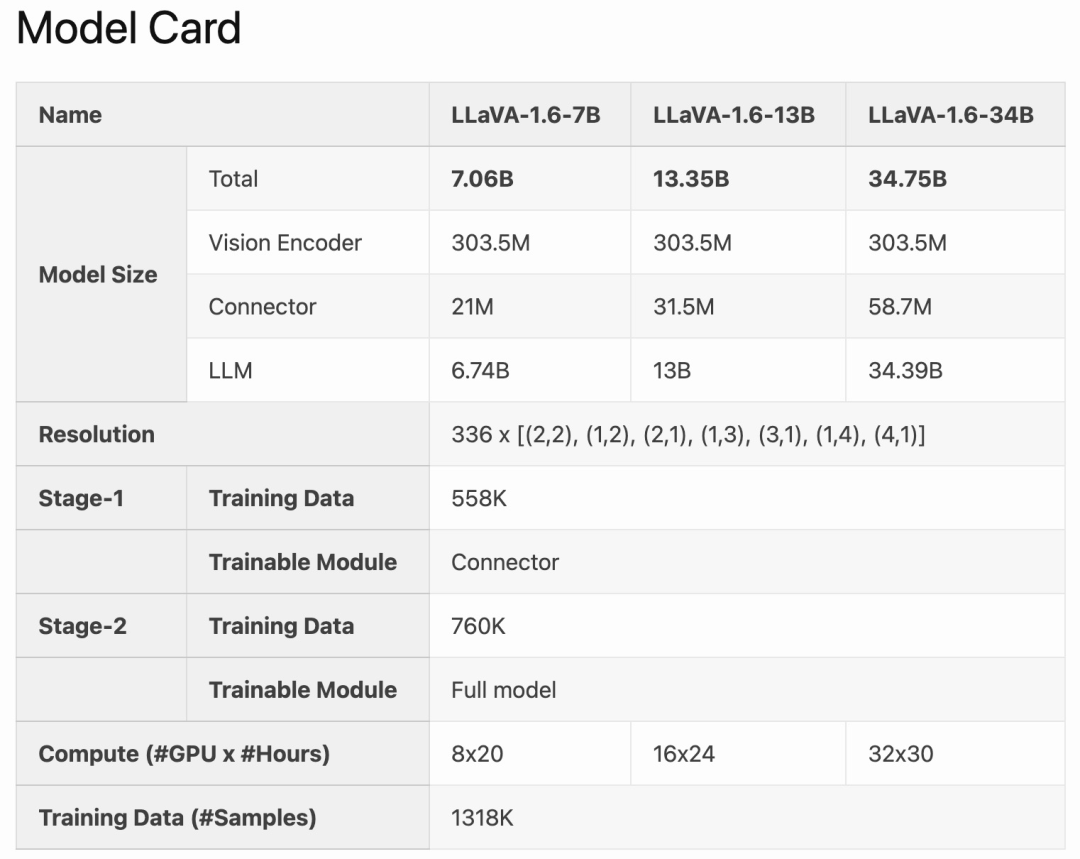
CogVLM 또는 Yi-VL과 같은 오픈 소스 LMM과 비교할 때 LLaVA-1.6은 SOTA 성능을 달성합니다. 상용 제품과 비교했을 때 LLaVA-1.6은 Gemini Pro와 비슷하며 일부 벤치마크에서는 Qwen-VL-Plus보다 우수합니다.
LLaVA-1.6은 강력한 제로샷 중국어 기능을 보여주고 멀티모달 벤치마크 MMBench-CN에서 SOTA 성능을 달성했다는 점을 언급할 가치가 있습니다.
방법 개선
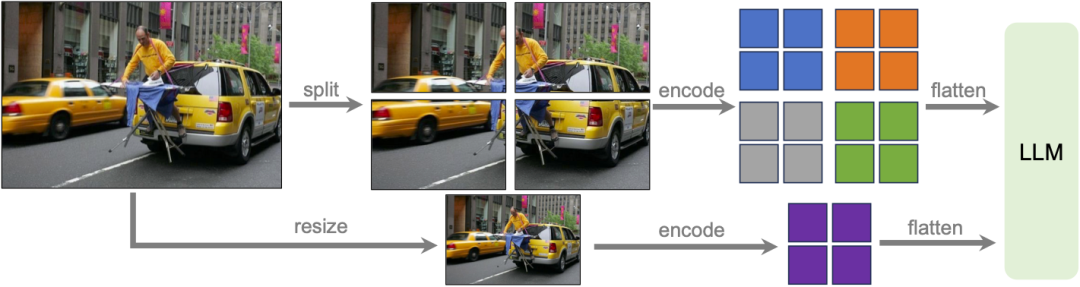
동적 고해상도
연구팀은 데이터 효율성을 유지하는 것을 목표로 LLaVA-1.6 모델을 고해상도로 설계했습니다. 고해상도 이미지와 세부 사항이 보존된 표현이 제공되면 이미지의 복잡한 세부 사항을 인식하는 모델의 능력이 크게 향상됩니다. 저해상도 이미지를 직면할 때, 즉 상상한 시각적 내용을 추측할 때 모델의 환각을 줄여줍니다.
데이터 혼합
고품질 사용자 지침 데이터. 데이터를 따르는 고품질 시각적 지침에 대한 연구의 정의는 두 가지 주요 기준에 따라 달라집니다. 첫째, 작업 지침의 다양성, 특히 작업 중에 실제 시나리오에서 접할 수 있는 광범위한 사용자 의도를 적절하게 표현하는 것입니다. 모델 배포 단계. 둘째, 호의적인 사용자 피드백을 유도하는 것을 목표로 응답의 우선순위를 정하는 것이 중요합니다.
따라서 이 연구에서는 두 가지 데이터 소스를 고려했습니다.
기존 GPT-V 데이터(LAION-GPT-V 및 ShareGPT-4V); 더 많은 시나리오에서 더 나은 시각적 대화를 더욱 촉진하기 위해 연구팀은 다양한 애플리케이션을 포괄하는 작은 15K 시각적 명령 튜닝 데이터 세트를 수집하고, 개인 정보 보호 문제가 있거나 해로울 수 있는 샘플을 신중하게 필터링하고, GPT-4V를 사용하여 응답을 생성했습니다. 다중 모드 문서/차트 데이터. (1) 연구팀은 TextCap이 TextVQA와 동일한 교육 이미지 세트를 사용한다는 것을 깨달았기 때문에 교육 데이터에서 TextCap을 제거합니다. 이를 통해 연구팀은 TextVQA를 평가할 때 모델의 제로샷 OCR 기능을 더 잘 이해할 수 있었습니다. 모델의 OCR 기능을 유지하고 더욱 향상시키기 위해 본 연구에서는 TextCap을 DocVQA 및 SynDog-EN으로 대체했습니다. (2) Qwen-VL-7B-Chat을 통해 이 연구에서는 플롯과 차트에 대한 더 나은 이해를 위해 ChartQA, DVQA 및 AI2D를 추가로 추가했습니다. 연구팀은 또한 Vicuna-1.5(7B 및 13B) 외에도 Mistral-7B 및 Nous-Hermes-2-Yi-34B를 포함한 더 많은 LLM 솔루션을 채택하여 LLaVA를 활성화하는 것을 고려하고 있다고 밝혔습니다. 더 넓은 범위의 사용자와 더 많은 장면을 지원합니다. 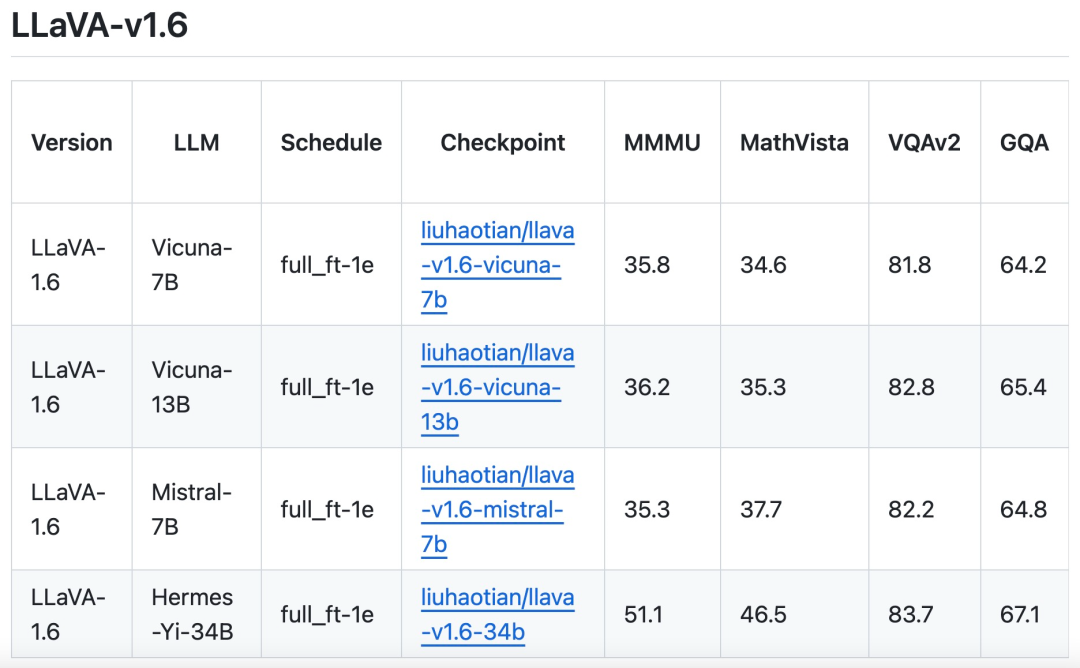
위 내용은 Gemini Pro를 따라잡고 추론 및 OCR 기능을 향상시키는 LLaVA-1.6은 너무 강력합니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

Video Face Swap
완전히 무료인 AI 얼굴 교환 도구를 사용하여 모든 비디오의 얼굴을 쉽게 바꾸세요!

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7698
7698
 15
1640
14
1393
52
1287
25
1229
29
15
1640
14
1393
52
1287
25
1229
29

 오픈 소스! ZoeDepth를 넘어! DepthFM: 빠르고 정확한 단안 깊이 추정!
Apr 03, 2024 pm 12:04 PM
오픈 소스! ZoeDepth를 넘어! DepthFM: 빠르고 정확한 단안 깊이 추정!
Apr 03, 2024 pm 12:04 PM
0. 이 글은 어떤 내용을 담고 있나요? 우리는 다재다능하고 빠른 최첨단 생성 단안 깊이 추정 모델인 DepthFM을 제안합니다. DepthFM은 전통적인 깊이 추정 작업 외에도 깊이 인페인팅과 같은 다운스트림 작업에서 최첨단 기능을 보여줍니다. DepthFM은 효율적이며 몇 가지 추론 단계 내에서 깊이 맵을 합성할 수 있습니다. 이 작품을 함께 읽어보아요~ 1. 논문 정보 제목: DepthFM: FastMoncularDepthEstimationwithFlowMatching 저자: MingGui, JohannesS.Fischer, UlrichPrestel, PingchuanMa, Dmytr
 세계에서 가장 강력한 오픈 소스 MoE 모델이 여기에 있습니다. 중국의 기능은 GPT-4와 비슷하며 가격은 GPT-4-Turbo의 거의 1%에 불과합니다.
May 07, 2024 pm 04:13 PM
세계에서 가장 강력한 오픈 소스 MoE 모델이 여기에 있습니다. 중국의 기능은 GPT-4와 비슷하며 가격은 GPT-4-Turbo의 거의 1%에 불과합니다.
May 07, 2024 pm 04:13 PM
기존 컴퓨팅을 능가할 뿐만 아니라 더 낮은 비용으로 더 효율적인 성능을 달성하는 인공 지능 모델을 상상해 보세요. 이것은 공상과학 소설이 아닙니다. DeepSeek-V2[1], 세계에서 가장 강력한 오픈 소스 MoE 모델이 여기에 있습니다. DeepSeek-V2는 경제적인 훈련과 효율적인 추론이라는 특징을 지닌 전문가(MoE) 언어 모델의 강력한 혼합입니다. 이는 236B 매개변수로 구성되며, 그 중 21B는 각 마커를 활성화하는 데 사용됩니다. DeepSeek67B와 비교하여 DeepSeek-V2는 더 강력한 성능을 제공하는 동시에 훈련 비용을 42.5% 절감하고 KV 캐시를 93.3% 줄이며 최대 생성 처리량을 5.76배로 늘립니다. DeepSeek은 일반 인공지능을 연구하는 회사입니다.
 AI가 수학적 연구를 전복시킨다! 필즈상 수상자이자 중국계 미국인 수학자, Terence Tao가 좋아하는 11개 논문 발표 |
Apr 09, 2024 am 11:52 AM
AI가 수학적 연구를 전복시킨다! 필즈상 수상자이자 중국계 미국인 수학자, Terence Tao가 좋아하는 11개 논문 발표 |
Apr 09, 2024 am 11:52 AM
AI는 실제로 수학을 변화시키고 있습니다. 최근 이 문제에 주목하고 있는 타오저쉬안(Tao Zhexuan)은 '미국수학회지(Bulletin of the American Mathematical Society)' 최신호를 게재했다. '기계가 수학을 바꿀 것인가?'라는 주제를 중심으로 많은 수학자들이 그들의 의견을 표현했습니다. 저자는 필즈상 수상자 Akshay Venkatesh, 중국 수학자 Zheng Lejun, 뉴욕대학교 컴퓨터 과학자 Ernest Davis 등 업계의 유명 학자들을 포함해 강력한 라인업을 보유하고 있습니다. AI의 세계는 극적으로 변했습니다. 이 기사 중 상당수는 1년 전에 제출되었습니다.
 안녕하세요, 일렉트릭 아틀라스입니다! 보스턴 다이나믹스 로봇 부활, 180도 이상한 움직임에 겁먹은 머스크
Apr 18, 2024 pm 07:58 PM
안녕하세요, 일렉트릭 아틀라스입니다! 보스턴 다이나믹스 로봇 부활, 180도 이상한 움직임에 겁먹은 머스크
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas가 공식적으로 전기 로봇 시대에 돌입했습니다! 어제 유압식 Atlas가 역사의 무대에서 "눈물을 흘리며" 물러났습니다. 오늘 Boston Dynamics는 전기식 Atlas가 작동 중이라고 발표했습니다. 상업용 휴머노이드 로봇 분야에서는 보스턴 다이내믹스가 테슬라와 경쟁하겠다는 각오를 다진 것으로 보인다. 새 영상은 공개된 지 10시간 만에 이미 100만 명이 넘는 조회수를 기록했다. 옛 사람들은 떠나고 새로운 역할이 등장하는 것은 역사적 필연이다. 올해가 휴머노이드 로봇의 폭발적인 해라는 것은 의심의 여지가 없습니다. 네티즌들은 “로봇의 발전으로 올해 개막식도 인간처럼 생겼고, 자유도도 인간보다 훨씬 크다. 그런데 정말 공포영화가 아닌가?”라는 반응을 보였다. 영상 시작 부분에서 아틀라스는 바닥에 등을 대고 가만히 누워 있는 모습입니다. 다음은 입이 떡 벌어지는 내용이다
 MLP를 대체하는 KAN은 오픈소스 프로젝트를 통해 컨볼루션으로 확장되었습니다.
Jun 01, 2024 pm 10:03 PM
MLP를 대체하는 KAN은 오픈소스 프로젝트를 통해 컨볼루션으로 확장되었습니다.
Jun 01, 2024 pm 10:03 PM
이달 초 MIT와 기타 기관의 연구자들은 MLP에 대한 매우 유망한 대안인 KAN을 제안했습니다. KAN은 정확성과 해석성 측면에서 MLP보다 뛰어납니다. 그리고 매우 적은 수의 매개변수로 더 많은 수의 매개변수를 사용하여 실행되는 MLP보다 성능이 뛰어날 수 있습니다. 예를 들어 저자는 KAN을 사용하여 더 작은 네트워크와 더 높은 수준의 자동화로 DeepMind의 결과를 재현했다고 밝혔습니다. 구체적으로 DeepMind의 MLP에는 약 300,000개의 매개변수가 있는 반면 KAN에는 약 200개의 매개변수만 있습니다. KAN은 MLP와 같이 강력한 수학적 기반을 가지고 있으며, KAN은 Kolmogorov-Arnold 표현 정리를 기반으로 합니다. 아래 그림과 같이 KAN은
 FisheyeDetNet: 어안 카메라를 기반으로 한 최초의 표적 탐지 알고리즘
Apr 26, 2024 am 11:37 AM
FisheyeDetNet: 어안 카메라를 기반으로 한 최초의 표적 탐지 알고리즘
Apr 26, 2024 am 11:37 AM
표적 탐지는 자율주행 시스템에서 상대적으로 성숙한 문제이며, 그 중 보행자 탐지는 가장 먼저 배포되는 알고리즘 중 하나입니다. 대부분의 논문에서 매우 포괄적인 연구가 수행되었습니다. 그러나 서라운드 뷰를 위한 어안 카메라를 사용한 거리 인식은 상대적으로 덜 연구되었습니다. 큰 방사형 왜곡으로 인해 표준 경계 상자 표현은 어안 카메라에서 구현하기 어렵습니다. 위의 설명을 완화하기 위해 확장된 경계 상자, 타원 및 일반 다각형 디자인을 극/각 표현으로 탐색하고 인스턴스 분할 mIOU 메트릭을 정의하여 이러한 표현을 분석합니다. 제안된 다각형 형태의 모델 fisheyeDetNet은 다른 모델보다 성능이 뛰어나며 동시에 자율 주행을 위한 Valeo fisheye 카메라 데이터 세트에서 49.5% mAP를 달성합니다.
 초지능의 생명력이 깨어난다! 하지만 자동 업데이트 AI가 등장하면서 엄마들은 더 이상 데이터 병목 현상을 걱정할 필요가 없습니다.
Apr 29, 2024 pm 06:55 PM
초지능의 생명력이 깨어난다! 하지만 자동 업데이트 AI가 등장하면서 엄마들은 더 이상 데이터 병목 현상을 걱정할 필요가 없습니다.
Apr 29, 2024 pm 06:55 PM
세상은 미친 듯이 큰 모델을 만들고 있습니다. 인터넷의 데이터만으로는 충분하지 않습니다. 훈련 모델은 '헝거게임'처럼 생겼고, 전 세계 AI 연구자들은 이러한 데이터를 탐식하는 사람들에게 어떻게 먹이를 줄지 고민하고 있습니다. 이 문제는 다중 모드 작업에서 특히 두드러집니다. 아무것도 할 수 없던 시기에, 중국 인민대학교 학과의 스타트업 팀은 자체 새로운 모델을 사용하여 중국 최초로 '모델 생성 데이터 피드 자체'를 현실화했습니다. 또한 이해 측면과 생성 측면의 두 가지 접근 방식으로 양측 모두 고품질의 다중 모드 새로운 데이터를 생성하고 모델 자체에 데이터 피드백을 제공할 수 있습니다. 모델이란 무엇입니까? Awaker 1.0은 중관촌 포럼에 최근 등장한 대형 멀티모달 모델입니다. 팀은 누구입니까? 소폰 엔진. 런민대학교 힐하우스 인공지능대학원 박사과정 학생인 Gao Yizhao가 설립했습니다.
 공장에서 일하는 테슬라 로봇, 머스크 : 올해 손의 자유도가 22도에 달할 것!
May 06, 2024 pm 04:13 PM
공장에서 일하는 테슬라 로봇, 머스크 : 올해 손의 자유도가 22도에 달할 것!
May 06, 2024 pm 04:13 PM
테슬라의 로봇 옵티머스(Optimus)의 최신 영상이 공개됐는데, 이미 공장에서 작동이 가능한 상태다. 정상 속도에서는 배터리(테슬라의 4680 배터리)를 다음과 같이 분류합니다. 공식은 또한 20배 속도로 보이는 모습을 공개했습니다. 작은 "워크스테이션"에서 따고 따고 따고 : 이번에 출시됩니다. 영상에는 옵티머스가 공장에서 이 작업을 전 과정에 걸쳐 사람의 개입 없이 완전히 자율적으로 완료하는 모습이 담겨 있습니다. 그리고 Optimus의 관점에서 보면 자동 오류 수정에 중점을 두고 구부러진 배터리를 집어 넣을 수도 있습니다. NVIDIA 과학자 Jim Fan은 Optimus의 손에 대해 높은 평가를 했습니다. Optimus의 손은 세계의 다섯 손가락 로봇 중 하나입니다. 가장 능숙합니다. 손은 촉각적일 뿐만 아니라
