

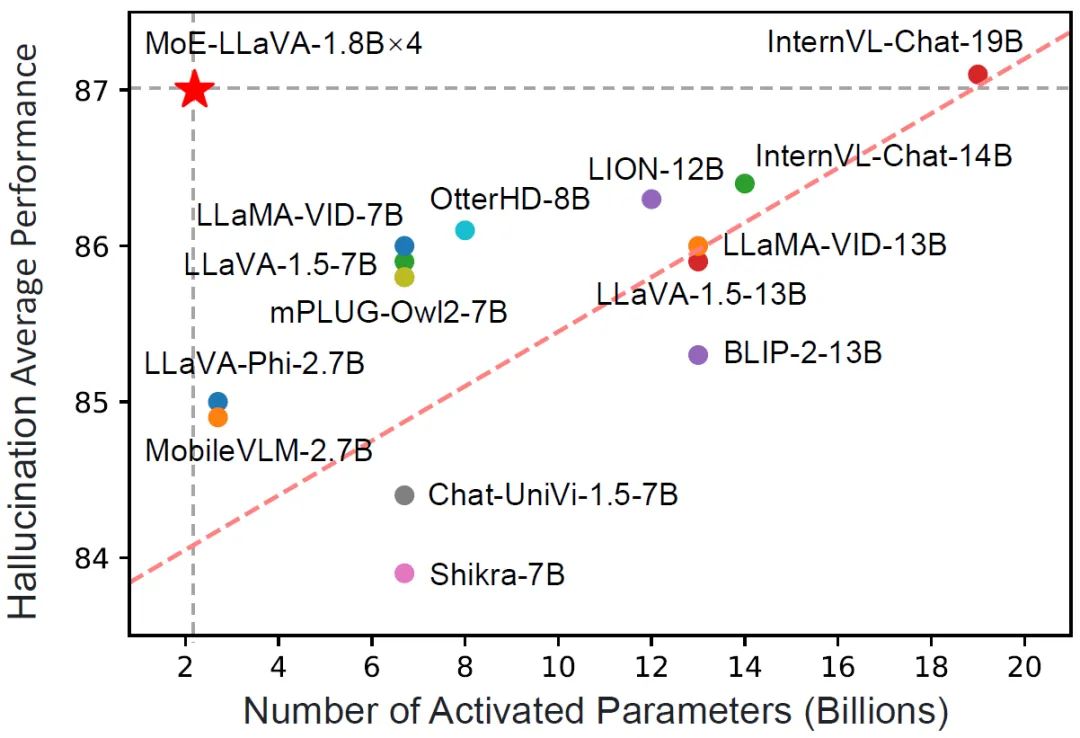
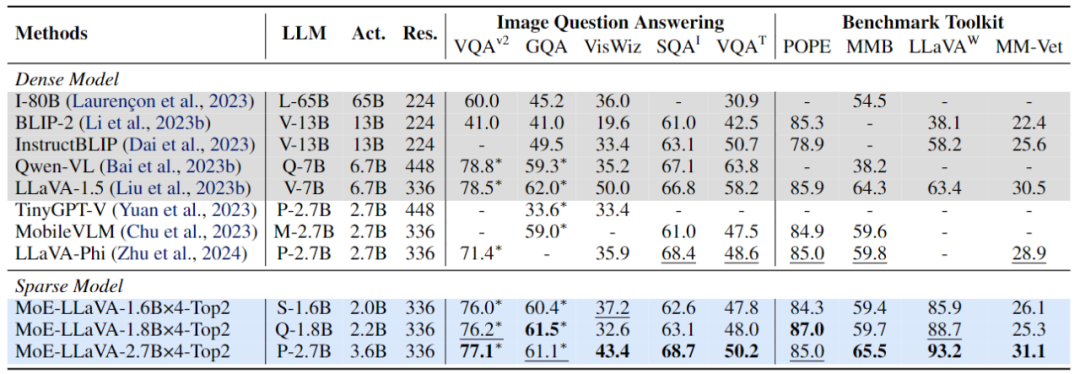
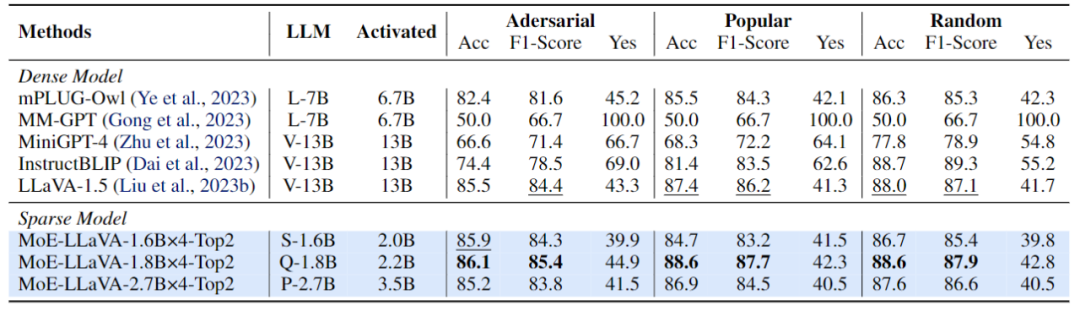
다중 모드 대형 모델이 희박하며 3B 모델 MoE-LLaVA는 LLaVA-1.5-7B와 유사합니다.

대규모 시각적 언어 모델(LVLM)은 모델을 확장하여 성능을 향상시킬 수 있습니다. 그러나 매개변수 크기를 늘리면 각 토큰의 계산이 모든 모델 매개변수를 활성화하므로 훈련 및 추론 비용이 증가합니다.
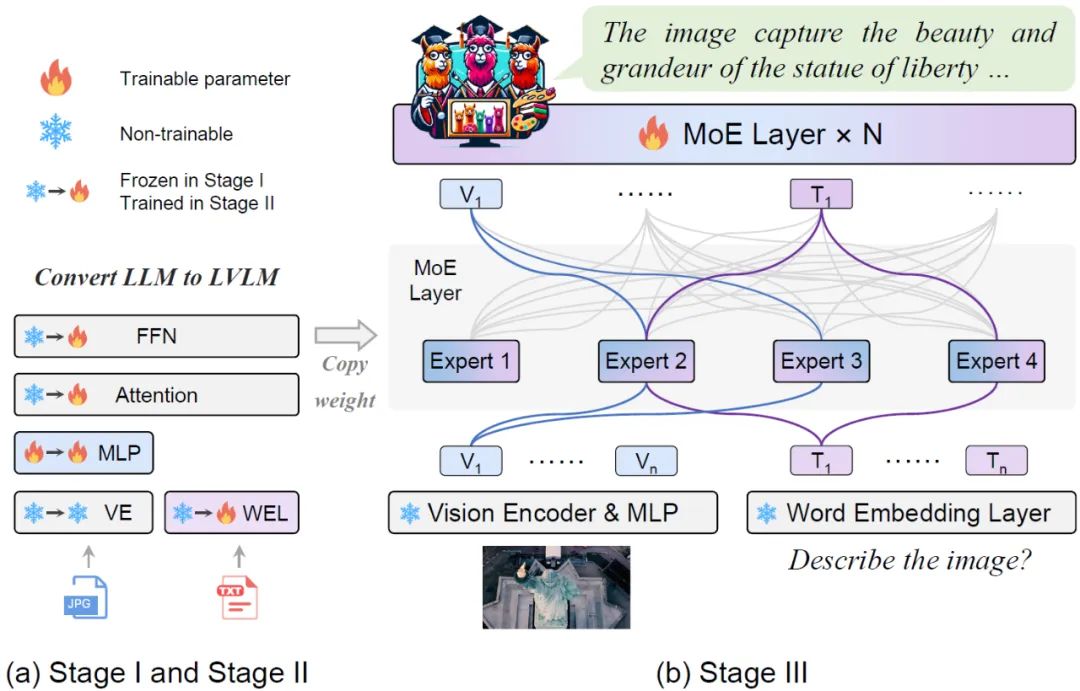
북경 대학교, 쑨원 대학교 및 기타 기관의 연구원들은 다중 모달 학습 및 모델 희소성과 관련된 성능 저하 문제를 해결하기 위해 MoE-Tuning이라는 새로운 훈련 전략을 공동으로 제안했습니다. MoE-Tuning은 놀라운 수의 매개변수를 사용하지만 일정한 계산 비용을 사용하여 희소 모델을 구축할 수 있습니다. 또한 연구원들은 MoE-LLaVA 프레임워크라고 불리는 MoE 기반의 새로운 희소 LVLM 아키텍처도 제안했습니다. 이 프레임워크에서는 라우팅 알고리즘을 통해 상위 k명의 전문가만 활성화되고 나머지 전문가는 비활성 상태로 유지됩니다. 이러한 방식으로 MoE-LLaVA 프레임워크는 배포 프로세스 중에 전문가 네트워크의 리소스를 보다 효율적으로 활용할 수 있습니다. 이러한 연구 결과는 LVLM 모델의 다중 모드 학습 및 모델 희소성 문제를 해결하기 위한 새로운 솔루션을 제공합니다.

논문 주소: https://arxiv.org/abs/2401.15947
프로젝트 주소: https://github.com/PKU-YuanGroup/MoE-LLaVA
데모 주소: https://huggingface.co/spaces/LanguageBind/MoE-LLaVA
논문 제목: MoE-LLaVA: Mixture of Experts for Large Vision-Language Models
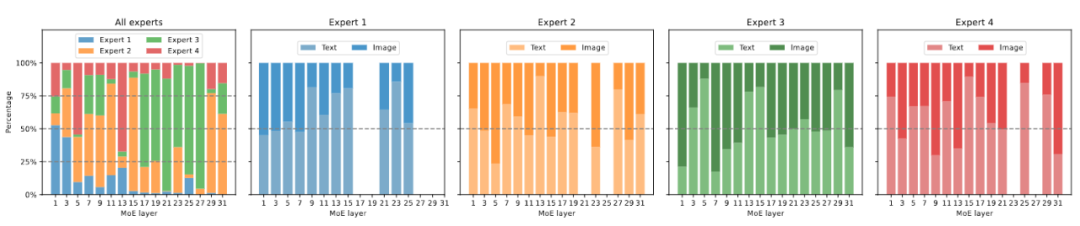
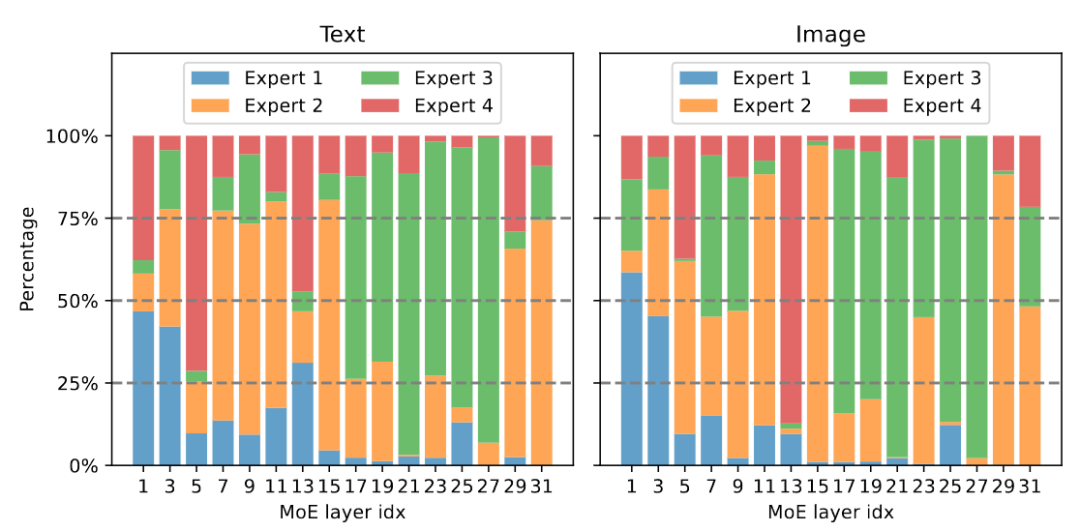
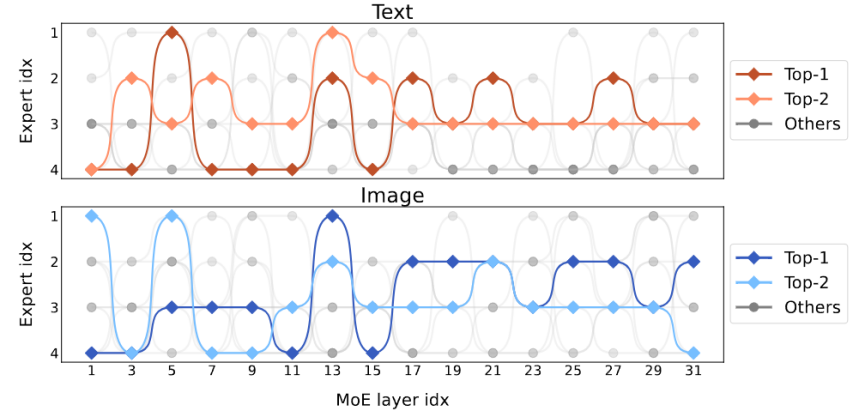
위 내용은 다중 모드 대형 모델이 희박하며 3B 모델 MoE-LLaVA는 LLaVA-1.5-7B와 유사합니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7530
7530
 15
1379
52
82
11
54
19
21
76
15
1379
52
82
11
54
19
21
76

 딥마인드 로봇이 탁구를 치는데 포핸드와 백핸드가 공중으로 미끄러져 인간 초보자를 완전히 제압했다.
Aug 09, 2024 pm 04:01 PM
딥마인드 로봇이 탁구를 치는데 포핸드와 백핸드가 공중으로 미끄러져 인간 초보자를 완전히 제압했다.
Aug 09, 2024 pm 04:01 PM
하지만 공원에 있는 노인을 이길 수는 없을까요? 파리올림픽이 본격화되면서 탁구가 많은 주목을 받고 있다. 동시에 로봇은 탁구 경기에서도 새로운 돌파구를 마련했습니다. 방금 DeepMind는 탁구 경기에서 인간 아마추어 선수 수준에 도달할 수 있는 최초의 학습 로봇 에이전트를 제안했습니다. 논문 주소: https://arxiv.org/pdf/2408.03906 DeepMind 로봇은 탁구를 얼마나 잘 치나요? 아마도 인간 아마추어 선수들과 동등할 것입니다: 포핸드와 백핸드 모두: 상대는 다양한 플레이 스타일을 사용하고 로봇도 견딜 수 있습니다: 다양한 스핀으로 서브를 받습니다. 그러나 게임의 강도는 그만큼 강렬하지 않은 것 같습니다. 공원에 있는 노인. 로봇용, 탁구용
 최초의 기계식 발톱! Yuanluobao는 2024년 세계 로봇 회의에 등장하여 집에 들어갈 수 있는 최초의 체스 로봇을 출시했습니다.
Aug 21, 2024 pm 07:33 PM
최초의 기계식 발톱! Yuanluobao는 2024년 세계 로봇 회의에 등장하여 집에 들어갈 수 있는 최초의 체스 로봇을 출시했습니다.
Aug 21, 2024 pm 07:33 PM
8월 21일, 2024년 세계로봇대회가 베이징에서 성대하게 개최되었습니다. SenseTime의 홈 로봇 브랜드 "Yuanluobot SenseRobot"은 전체 제품군을 공개했으며, 최근에는 Yuanluobot AI 체스 두는 로봇인 체스 프로페셔널 에디션(이하 "Yuanluobot SenseRobot")을 출시하여 세계 최초의 A 체스 로봇이 되었습니다. 집. Yuanluobo의 세 번째 체스 게임 로봇 제품인 새로운 Guoxiang 로봇은 AI 및 엔지니어링 기계 분야에서 수많은 특별한 기술 업그레이드와 혁신을 거쳤으며 처음으로 3차원 체스 말을 집는 능력을 실현했습니다. 가정용 로봇의 기계 발톱을 통해 체스 게임, 모두 체스 게임, 기보 복습 등과 같은 인간-기계 기능을 수행합니다.
 클로드도 게으르게 됐어요! 네티즌 : 휴가를 보내는 법을 배우십시오
Sep 02, 2024 pm 01:56 PM
클로드도 게으르게 됐어요! 네티즌 : 휴가를 보내는 법을 배우십시오
Sep 02, 2024 pm 01:56 PM
개학이 코앞으로 다가왔습니다. 새 학기를 앞둔 학생들뿐만 아니라 대형 AI 모델도 스스로 관리해야 합니다. 얼마 전 레딧에는 클로드가 게으르다고 불평하는 네티즌들이 붐볐습니다. "레벨이 많이 떨어졌고, 자주 멈췄고, 심지어 출력도 매우 짧아졌습니다. 출시 첫 주에는 4페이지 전체 문서를 한 번에 번역할 수 있었지만 지금은 반 페이지도 출력하지 못합니다. !" https://www.reddit.com/r/ClaudeAI/comments/1by8rw8/something_just_feels_wrong_with_claude_in_the/ "클로드에게 완전히 실망했습니다"라는 제목의 게시물에
 세계로봇컨퍼런스에서 '미래 노인돌봄의 희망'을 담은 국산 로봇이 포위됐다.
Aug 22, 2024 pm 10:35 PM
세계로봇컨퍼런스에서 '미래 노인돌봄의 희망'을 담은 국산 로봇이 포위됐다.
Aug 22, 2024 pm 10:35 PM
베이징에서 열린 세계로봇컨퍼런스에서는 휴머노이드 로봇의 전시가 현장의 절대 화두가 됐다. 스타더스트 인텔리전트 부스에서는 AI 로봇 어시스턴트 S1이 덜시머, 무술, 서예 3대 퍼포먼스를 선보였다. 문학과 무술을 모두 갖춘 하나의 전시 공간은 수많은 전문 관객과 미디어를 끌어 모았습니다. 탄력 있는 현의 우아한 연주를 통해 S1은 정밀한 작동과 속도, 힘, 정밀성을 갖춘 절대적인 제어력을 보여줍니다. CCTV 뉴스는 '서예'의 모방 학습 및 지능형 제어에 대한 특별 보도를 진행했습니다. 회사 설립자 Lai Jie는 부드러운 움직임 뒤에 하드웨어 측면이 최고의 힘 제어와 가장 인간과 유사한 신체 지표(속도, 하중)를 추구한다고 설명했습니다. 등)이지만 AI측에서는 사람의 실제 움직임 데이터를 수집해 로봇이 강한 상황에 직면했을 때 더욱 강해지고 빠르게 진화하는 방법을 학습할 수 있다. 그리고 민첩하다
 ACL 2024 시상식 발표: HuaTech의 Oracle 해독에 관한 최고의 논문 중 하나, GloVe Time Test Award
Aug 15, 2024 pm 04:37 PM
ACL 2024 시상식 발표: HuaTech의 Oracle 해독에 관한 최고의 논문 중 하나, GloVe Time Test Award
Aug 15, 2024 pm 04:37 PM
참가자들은 이번 ACL 컨퍼런스에서 많은 것을 얻었습니다. ACL2024는 6일간 태국 방콕에서 개최됩니다. ACL은 전산언어학 및 자연어 처리 분야 최고의 국제학술대회로 국제전산언어학회(International Association for Computational Linguistics)가 주최하고 매년 개최된다. ACL은 NLP 분야에서 학술 영향력 1위를 항상 차지하고 있으며, CCF-A 추천 컨퍼런스이기도 합니다. 올해로 62회째를 맞이하는 ACL 컨퍼런스에는 NLP 분야의 최신 저서가 400편 이상 접수됐다. 어제 오후 컨퍼런스에서는 최우수 논문과 기타 상을 발표했습니다. 이번에 최우수논문상 7개(미출판 2개), 우수주제상 1개, 우수논문상 35개가 있다. 이 컨퍼런스에서는 또한 3개의 리소스 논문상(ResourceAward)과 사회적 영향상(Social Impact Award)을 수상했습니다.
 홍멍 스마트 트래블 S9과 풀시나리오 신제품 출시 컨퍼런스, 다수의 블록버스터 신제품이 함께 출시됐다
Aug 08, 2024 am 07:02 AM
홍멍 스마트 트래블 S9과 풀시나리오 신제품 출시 컨퍼런스, 다수의 블록버스터 신제품이 함께 출시됐다
Aug 08, 2024 am 07:02 AM
오늘 오후 Hongmeng Zhixing은 공식적으로 새로운 브랜드와 신차를 환영했습니다. 8월 6일, Huawei는 Hongmeng Smart Xingxing S9 및 Huawei 전체 시나리오 신제품 출시 컨퍼런스를 개최하여 파노라마식 스마트 플래그십 세단 Xiangjie S9, 새로운 M7Pro 및 Huawei novaFlip, MatePad Pro 12.2인치, 새로운 MatePad Air, Huawei Bisheng을 선보였습니다. 레이저 프린터 X1 시리즈, FreeBuds6i, WATCHFIT3 및 스마트 스크린 S5Pro를 포함한 다양한 새로운 올-시나리오 스마트 제품, 스마트 여행, 스마트 오피스, 스마트 웨어에 이르기까지 화웨이는 풀 시나리오 스마트 생태계를 지속적으로 구축하여 소비자에게 스마트한 경험을 제공합니다. 만물인터넷. Hongmeng Zhixing: 스마트 자동차 산업의 업그레이드를 촉진하기 위한 심층적인 권한 부여 화웨이는 중국 자동차 산업 파트너와 손을 잡고
 Li Feifei 팀은 로봇에 공간 지능을 제공하고 GPT-4o를 통합하기 위해 ReKep을 제안했습니다.
Sep 03, 2024 pm 05:18 PM
Li Feifei 팀은 로봇에 공간 지능을 제공하고 GPT-4o를 통합하기 위해 ReKep을 제안했습니다.
Sep 03, 2024 pm 05:18 PM
비전과 로봇 학습의 긴밀한 통합. 최근 화제를 모으고 있는 1X 휴머노이드 로봇 네오(NEO)와 두 개의 로봇 손이 원활하게 협력해 옷 개기, 차 따르기, 신발 싸기 등을 하는 모습을 보면 마치 로봇 시대로 접어들고 있다는 느낌을 받을 수 있다. 실제로 이러한 부드러운 움직임은 첨단 로봇 기술 + 정교한 프레임 디자인 + 다중 모드 대형 모델의 산물입니다. 우리는 유용한 로봇이 종종 환경과 복잡하고 절묘한 상호작용을 요구한다는 것을 알고 있으며, 환경은 공간적, 시간적 영역에서 제약으로 표현될 수 있습니다. 예를 들어, 로봇이 차를 따르도록 하려면 먼저 로봇이 찻주전자 손잡이를 잡고 차를 흘리지 않고 똑바로 세운 다음, 주전자 입구와 컵 입구가 일치할 때까지 부드럽게 움직여야 합니다. 을 누른 다음 주전자를 특정 각도로 기울입니다. 이것
 분산 인공지능 컨퍼런스 DAI 2024 Call for Papers: Agent Day, 강화학습의 아버지 Richard Sutton이 참석합니다! Yan Shuicheng, Sergey Levine 및 DeepMind 과학자들이 기조 연설을 할 예정입니다.
Aug 22, 2024 pm 08:02 PM
분산 인공지능 컨퍼런스 DAI 2024 Call for Papers: Agent Day, 강화학습의 아버지 Richard Sutton이 참석합니다! Yan Shuicheng, Sergey Levine 및 DeepMind 과학자들이 기조 연설을 할 예정입니다.
Aug 22, 2024 pm 08:02 PM
컨퍼런스 소개 과학기술의 급속한 발전과 함께 인공지능은 사회 발전을 촉진하는 중요한 힘이 되었습니다. 이 시대에 우리는 분산인공지능(DAI)의 혁신과 적용을 목격하고 참여할 수 있어 행운입니다. 분산 인공지능(Distributed Artificial Intelligence)은 인공지능 분야의 중요한 한 분야로, 최근 몇 년간 점점 더 많은 주목을 받고 있습니다. 대규모 언어 모델(LLM) 기반 에이전트가 갑자기 등장했습니다. 대규모 모델의 강력한 언어 이해와 생성 기능을 결합하여 자연어 상호 작용, 지식 추론, 작업 계획 등에 큰 잠재력을 보여주었습니다. AIAgent는 빅 언어 모델을 이어받아 현재 AI계에서 화제가 되고 있습니다. 오
