

값비싼 EUV 리소그래피의 사용을 줄일 수 있다고 독일 머크는 DSA 자기조립 기술이 10년 안에 상용화될 것이라고 밝혔다.

2월 5일 본 사이트의 소식에 따르면, 독일 머크의 아난드 남비어(Anand Nambier) 수석부사장은 최근 기자간담회에서 DSA 자가조립 기술이 향후 10년 안에 상용화될 것이라고 말했는데, 이는 값비싼 EUV 패터닝 은 기존 포토리소그래피 기술에 중요한 추가 요소가 됩니다.
이 사이트의 참고 사항: DSA는 Directed self-assemble의 약자로 블록 공중합체의 표면 특성을 이용하여 주기적인 패턴의 자동 구성을 구현하고 이를 기반으로 최종적으로 제어 가능한 방향으로 원하는 패턴을 형성하도록 유도합니다. 일반적으로 DSA는 독립형 패터닝 기술로 사용하기에 적합하지 않으며 오히려 다른 패터닝 기술(예: 기존 포토리소그래피)과 결합하여 고정밀 반도체를 생산하는 것으로 알려져 있습니다.

. EUV에서 DSA의 주요 응용 분야는 EUV의 무작위 오류를 보상하는 것입니다. 무작위 오류는 EUV 공정 전체 패터닝 오류의 50%를 차지합니다.
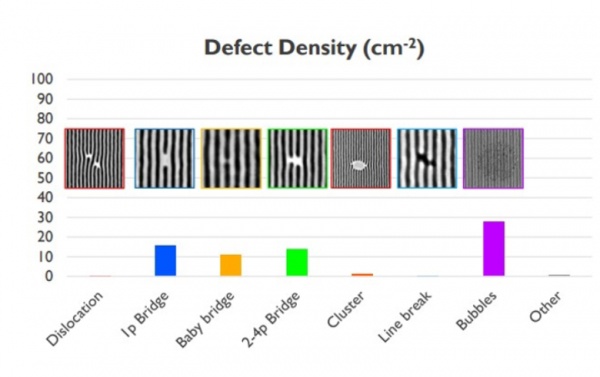
DSA를 상업적으로 대규모로 적용하려면 패턴 생성 중에 발생하는 기포, 브리지, 클러스터와 같은 결함을 줄이는 등 몇 가지 문제를 해결해야 합니다. 그 중 교량 결함은 가장 흔한 문제 중 하나입니다.
위 내용은 값비싼 EUV 리소그래피의 사용을 줄일 수 있다고 독일 머크는 DSA 자기조립 기술이 10년 안에 상용화될 것이라고 밝혔다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

Video Face Swap
완전히 무료인 AI 얼굴 교환 도구를 사용하여 모든 비디오의 얼굴을 쉽게 바꾸세요!

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7675
7675
 15
1393
52
1207
24
91
11
73
19
15
1393
52
1207
24
91
11
73
19

 1c나노 세대 메모리 경쟁: 삼성은 EUV 활용 확대 계획, 마이크론은 몰리브덴·루테늄 소재 선보일 예정
Feb 04, 2024 am 09:40 AM
1c나노 세대 메모리 경쟁: 삼성은 EUV 활용 확대 계획, 마이크론은 몰리브덴·루테늄 소재 선보일 예정
Feb 04, 2024 am 09:40 AM
국내 언론 더일렉은 삼성전자와 마이크론이 차세대 D램 메모리인 1cnm 공정에서 더 많은 신기술을 선보일 것이라고 보도했다. 이번 조치로 메모리 성능과 에너지 효율성이 더욱 향상될 것으로 기대된다. 글로벌 DRAM 시장의 선두주자로서 삼성전자와 마이크론의 기술 혁신은 전체 산업 발전을 촉진할 것입니다. 이는 또한 미래의 메모리 제품이 더욱 효율적이고 강력해질 것임을 의미합니다. 이 사이트의 참고 사항: 1cnm 세대는 6번째 10+nm 세대이며 Micron은 이를 1γnm 프로세스라고도 부릅니다. 현재 가장 발전된 메모리는 1bnm 세대인데, 삼성에서는 1bnm을 12nm 수준의 공정이라고 부릅니다. 분석업체 테크인사이트 최정동 전무는 최근 세미나에서 마이크론이 1cnm 페스티벌에 참가할 것이라고 밝혔다.
 NVIDIA만이 수혜자가 아닙니다. AI 교육도 메모리 칩 제조업체에 이익이 됩니다.
May 31, 2023 pm 05:16 PM
NVIDIA만이 수혜자가 아닙니다. AI 교육도 메모리 칩 제조업체에 이익이 됩니다.
May 31, 2023 pm 05:16 PM
30일 뉴스에 따르면 메모리반도체 시장이 부진한 가운데 인공지능(AI) 수요가 많아 삼성, SK하이닉스 등 기업에 수혜가 예상된다. 5월 24일, 엔비디아는 재무 보고서를 발표했고, 회사의 시장 가치는 이틀 만에 2,070억 달러나 급증했습니다. 이전까지 반도체 산업은 불황을 겪었는데, 이번 재무보고 예측은 사람들에게 큰 자신감과 희망을 주었습니다. 인공지능 분야가 본격화되면 마이크로소프트 같은 전통 기술 대기업과 오픈AI 같은 스타트업은 삼성, SK하이닉스 같은 기업에 도움을 구할 것이다. 기계 학습에는 대량의 데이터를 처리하고 비디오, 오디오 및 텍스트를 분석하고 인간의 창의성을 시뮬레이션하려면 메모리 칩이 필요합니다. 실제로 AI 기업은 그 어느 때보다 더 많은 DRAM 칩을 구매하고 있을 수 있습니다. 메모리 칩 수요
 1nm 칩은 중국산인가요, 미국산인가요?
Nov 06, 2023 pm 01:30 PM
1nm 칩은 중국산인가요, 미국산인가요?
Nov 06, 2023 pm 01:30 PM
1nm 칩을 누가 만들었는지는 확실하지 않습니다. 연구 개발 관점에서 보면 1nm 칩은 대만, 중국, 미국이 공동 개발한 것입니다. 양산 관점에서 볼 때 이 기술은 아직 완전히 구현되지 않았습니다. 이번 연구의 주요 책임자는 중국 과학자인 MIT의 Zhu Jiadi 박사이다. Zhu Jiadi 박사는 연구가 아직 초기 단계이며 대량 생산과는 거리가 멀다고 말했습니다.
 중국 최초: Changxin 메모리, LPDDR5 DRAM 메모리 칩 출시
Nov 28, 2023 pm 09:29 PM
중국 최초: Changxin 메모리, LPDDR5 DRAM 메모리 칩 출시
Nov 28, 2023 pm 09:29 PM
11월 28일 이 사이트의 소식. 창신 메모리 공식 홈페이지에 따르면 창신 메모리는 최신 LPDDR5DRAM 메모리 칩을 출시했다. 자체 개발 및 생산한 LPDDR5 제품을 출시한 최초의 국내 브랜드다. 모바일 단말기 시장에서 Changxin Storage의 제품 레이아웃은 더욱 다양해졌습니다. 이 웹사이트에서는 Changxin Memory LPDDR5 시리즈 제품에 12Gb LPDDR5 입자, POP 패키지 12GBLPDDR5 칩 및 DSC 패키지 6GBLPDDR5 칩이 포함되어 있음을 확인했습니다. 12GBLPDDR5 칩은 샤오미, 트랜션 등 국내 주류 휴대폰 제조사 모델에서 검증됐다. LPDDR5는 창신메모리가 중·고급 모바일 기기 시장을 겨냥해 출시한 제품이다.
 삼성전자, 이르면 2024년 말까지 첫 ASML High-NA EUV 리소그래피 장비 설치 시작할 것으로 밝혀져
Aug 16, 2024 am 11:11 AM
삼성전자, 이르면 2024년 말까지 첫 ASML High-NA EUV 리소그래피 장비 설치 시작할 것으로 밝혀져
Aug 16, 2024 am 11:11 AM
16일 본 사이트 소식에 따르면 서울경제는 어제(15일) 삼성전자가 2024년 4분기부터 2025년 1분기 사이에 ASML로부터 첫 번째 High-NAEUV 노광기를 설치할 예정이라고 보도했다. 2025년 중반 상용화 예정. 보도에 따르면 삼성은 화성 캠퍼스에 최초의 ASMLTwinscanEXE:5000High-NA 리소그래피 기계를 설치할 예정이며, 이는 주로 로직 및 DRAM용 차세대 제조 기술을 개발하기 위한 연구 개발 목적으로 사용될 것입니다. 삼성전자는 High-NAEUV 기술을 중심으로 강력한 생태계를 구축할 계획이다. 삼성전자는 High-NAEUV 노광장비 확보에 더해 일본 Lasertec과 협력해 High-NAEUV 노광장비 전용 고-NAEUV 노광장비 개발도 진행 중이다.
 TSMC의 첨단 패키징 고객들이 주문량을 크게 쫓고 있는 것으로 알려졌으며, 내년 월간 생산능력은 120% 증가할 계획이다.
Nov 13, 2023 pm 12:29 PM
TSMC의 첨단 패키징 고객들이 주문량을 크게 쫓고 있는 것으로 알려졌으며, 내년 월간 생산능력은 120% 증가할 계획이다.
Nov 13, 2023 pm 12:29 PM
이 홈페이지는 11월 13일 대만경제일보에 따르면 TSMC의 CoWoS 고급 패키징 수요가 10월 주문 확대를 확정한 엔비디아 외에도 애플, AMD, 브로드컴, 마벨 등 대형 고객사들이 폭발할 것이라고 보도했다. 최근에는 수주를 대폭 추진하기도 했습니다. 보도에 따르면 TSMC는 위에서 언급한 5개 주요 고객의 요구를 충족하기 위해 CoWoS 첨단 패키징 생산 능력 확장을 가속화하기 위해 열심히 노력하고 있습니다. 내년 월 생산능력은 당초 목표보다 약 20% 증가한 3만5000개로 예상된다. TSMC의 주요 5개 고객사가 대량 주문을 했다는 것은 인공지능 애플리케이션이 널리 대중화되고 주요 제조사들이 관심을 갖고 있음을 의미한다고 분석했다. 인공지능 칩에 대한 수요가 크게 증가했습니다. 본 사이트에 대한 문의에 따르면 현재 CoWoS 고급 패키징 기술은 주로 CoWos-S의 세 가지 유형으로 구분됩니다.
 Realtek 5GbE 유선 네트워크 카드 칩 RTL8126-CG에 안정성 문제가 있어 내년으로 연기될 것으로 알려졌습니다.
Aug 25, 2023 am 11:53 AM
Realtek 5GbE 유선 네트워크 카드 칩 RTL8126-CG에 안정성 문제가 있어 내년으로 연기될 것으로 알려졌습니다.
Aug 25, 2023 am 11:53 AM
8월 24일 이 웹사이트의 뉴스에 따르면 대부분의 기술 제조업체는 Gamescom에서 몇 가지 신제품을 선보였습니다. 예를 들어, ASRock은 Z790 마더보드의 "반세대" 업데이트 버전을 선보였습니다. 이 새로운 마더보드는 RTL8125-BG 칩을 사용합니다. 6월 Computex 쇼에서 프로토타입에 사용된 RTL8126-CG 대신에 사용되었습니다. 네덜란드 언론 Tweakers에 따르면 Gamescom에 참가하는 여러 마더보드 제조업체는 Realtek의 5GbE 유선 네트워크 카드 칩 RTL8126-CG가 더 저렴하지만 안정성 문제로 인해 올 가을 출시되는 마더보드에는 설치되지 않을 것이라고 밝혔습니다. 문제가 있지만 올 가을에 새 마더보드가 나오기 전에는 문제를 해결할 수 없습니다.
 소식통에 따르면 Nvidia는 AI 칩 HGX H20, L20 PCle 및 L2 PCle의 중국 전용 버전을 개발하고 있습니다.
Nov 09, 2023 pm 03:33 PM
소식통에 따르면 Nvidia는 AI 칩 HGX H20, L20 PCle 및 L2 PCle의 중국 전용 버전을 개발하고 있습니다.
Nov 09, 2023 pm 03:33 PM
최신 뉴스에 따르면 Science and Technology Innovation Board Daily와 Blue Whale Finance의 보고서에 따르면 업계 체인 소식통에 따르면 Nvidia가 HGXH20, L20PCle 및 L2PCle을 포함하여 중국 시장에 적합한 최신 버전의 AI 칩을 개발했다고 합니다. 현재 NVIDIA는 이에 대해 언급하지 않았습니다. 이 문제에 정통한 사람들은 이 세 가지 칩이 모두 NVIDIA H100의 개선 사항을 기반으로 한다고 말했습니다. NVIDIA는 이르면 11월 16일에 이를 발표할 예정이며, 국내 제조업체는 빠르면 샘플을 받게 될 것입니다. 날. 공개 정보를 확인한 후 NVIDIAH100TensorCoreGPU가 TSMC N4 프로세스를 기반으로 하고 800억 개의 트랜지스터를 통합하는 새로운 Hopper 아키텍처를 채택한다는 사실을 알게 되었습니다. 이전 세대 제품 대비 다중 전문가(MoE) 제공 가능
