

OccNeRF: LiDAR 데이터 감독이 전혀 필요하지 않습니다.

위 작성 및 작성자 개인 요약
최근 몇 년간 자율주행 분야의 3차원 탑승 예측 작업은 그 특유의 장점으로 인해 학계와 산업계에서 폭넓은 주목을 받아왔습니다. 주변 환경의 3차원 구조를 재구성하여 자율주행 계획 및 네비게이션에 대한 세부 정보를 제공하는 작업입니다. 그러나 대부분의 현재 주류 방법은 LiDAR 포인트 클라우드를 기반으로 생성된 레이블을 사용하여 네트워크 훈련을 감독합니다. 최근 OccNeRF 연구에서 저자는 매개변수화된 점유 필드(Parameterized Occupancy Fields)라는 자체 감독 다중 카메라 점유 예측 방법을 제안했습니다. 이 방법은 야외 장면에서 경계가 없는 문제를 해결하고 샘플링 전략을 재구성합니다. 그런 다음 볼륨 렌더링(Volume Rendering) 기술을 통해 점유된 필드를 다중 카메라 깊이 맵으로 변환하고 다중 프레임 광도 일관성(Photometric Error)으로 감독합니다. 또한 이 방법은 사전 훈련된 개방형 어휘 의미론적 분할 모델을 활용하여 직업 분야에 의미론적 정보를 부여하기 위한 2D 의미론적 라벨을 생성합니다. 이 개방형 어휘 의미론적 분할 모델은 장면의 다양한 객체를 분할하고 각 객체에 의미론적 라벨을 할당할 수 있습니다. 이러한 의미 라벨을 점유 필드와 결합함으로써 모델은 환경을 더 잘 이해하고 더 정확한 예측을 할 수 있습니다. 요약하면, OccNeRF 방법은 매개변수화된 점유 필드, 볼륨 렌더링 및 다중 프레임 측광 일관성과 개방형 어휘 의미론적 분할 모델을 결합하여 자율 주행 시나리오에서 고정밀 점유 예측을 달성합니다. 이 방식은 자율주행 시스템에 더 많은 환경 정보를 제공하고, 자율주행의 안전성과 신뢰성을 향상시킬 것으로 기대된다.

- 문서 링크: https://arxiv.org/pdf/2312.09243.pdf
- 코드 링크: https://github.com/LinShan-Bin/OccNeRF
OccNeRF 문제 배경
최근 인공지능 기술의 급속한 발전과 함께 자율주행 분야에서도 큰 발전이 이루어졌습니다. 3D 인식은 자율주행의 기반이 되며, 이후의 계획과 의사결정에 필요한 정보를 제공합니다. 전통적인 방법에서 LiDAR는 정확한 3D 데이터를 직접 캡처할 수 있지만 센서의 높은 비용과 스캐닝 지점이 희박하여 실제 적용이 제한됩니다. 이에 반해 이미지 기반 3D 센싱 방식은 비용이 저렴하고 효과적이어서 점점 더 많은 주목을 받고 있습니다. 멀티 카메라 3D 물체 감지는 한동안 3D 장면 이해 작업의 주류였지만 현실 세계의 무제한 범주에 대처할 수 없고 데이터의 롱테일 배포에 어려움을 겪고 있습니다.
3D 점유 예측은 멀티뷰 입력을 통해 주변 장면의 기하학적 구조를 직접 재구성함으로써 이러한 단점을 잘 보완할 수 있습니다. 대부분의 기존 방법은 이미지 기반 시스템에서는 사용할 수 없는 LiDAR 포인트 클라우드에서 생성된 레이블을 사용하여 네트워크 훈련을 감독하는 모델 설계 및 성능 최적화에 중점을 둡니다. 즉, 훈련 데이터를 수집하기 위해 여전히 값비싼 데이터 수집 수단을 사용해야 하며 LiDAR 포인트 클라우드 지원 주석 없이는 대량의 실제 데이터를 낭비해야 하므로 3D 점유 예측 개발이 어느 정도 제한됩니다. 따라서 자기주도형 3D 점유 예측을 탐구하는 것은 매우 귀중한 방향입니다.OccNeRF 알고리즘에 대한 자세한 설명
다음 그림은 OccNeRF 방식의 기본 과정을 보여줍니다. 모델은 다중 카메라 이미지
를 입력으로 사용하고 먼저 2D 백본을 사용하여 N 이미지의 특징을 추출한 다음 간단한 투영 및 이중선형 보간(매개변수화된 공간 아래)을 통해 직접 3D 특징을 얻고 마지막으로 3D를 통해 CNN 네트워크는 3D 기능을 최적화하고 예측을 출력합니다. 모델을 훈련하기 위해 OccNeRF 방법은 볼륨 렌더링을 통해 현재 프레임의 깊이 맵을 생성하고 이전 및 다음 프레임을 도입하여 광도 손실을 계산합니다. 더 많은 타이밍 정보를 제공하기 위해 OccNeRF는 점유 필드를 사용하여 다중 프레임 깊이 맵을 렌더링하고 손실 함수를 계산합니다. 동시에 OccNeRF는 2D 의미 지도를 동시에 렌더링하며 Open Lexicon 의미 체계 분할 모델에 의해 감독됩니다.
매개변수화된 Occupancy Fields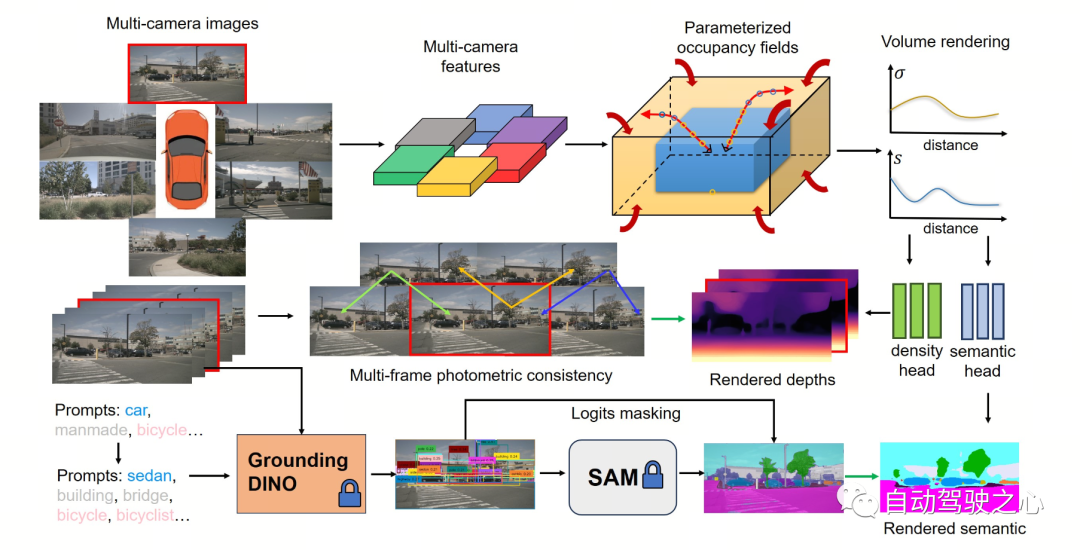
인식 범위 격차
문제를 해결하기 위해 제안되었습니다. 이론적으로 카메라는 무한한 거리에 있는 물체를 캡처할 수 있지만, 이전 점유 예측 모델은 더 가까운 공간(예: 40m 이내)만 고려합니다. 감독 방법에서 모델은 감독 신호를 기반으로 먼 물체를 무시하는 방법을 학습할 수 있습니다. 최적화 프로세스에 영향을 미칩니다. 이를 기반으로 OccNeRF는 매개변수화된 점유 필드(Parameterized Occupancy Fields)를 채택하여 무제한의 야외 장면을 모델링합니다.
OccNeRF의 매개변수화 공간은 내부와 외부로 구분됩니다. 내부 공간은 원래 좌표의 선형 매핑으로, 높은 해상도를 유지하는 반면 외부 공간은 무한한 범위를 나타냅니다. 특히 OccNeRF는 3D 공간에서 중간점의 좌표를 다음과 같이 변경합니다.
여기서 는 좌표이고, 는 내부 공간의 해당 경계 값을 나타내는 조정 가능한 매개변수입니다. 또한 조정 가능합니다. 조정된 매개변수는 점유된 내부 공간의 비율을 나타냅니다. 매개변수화된 점유 필드를 생성할 때 OccNeRF는 먼저 매개변수화된 공간에서 샘플링하고 역변환을 통해 원래 좌표를 얻은 다음 원래 좌표를 이미지 평면에 투영하고 마지막으로 샘플링과 3차원 컨볼루션을 통해 점유 필드를 얻습니다.
다중 프레임 깊이 추정
점유 네트워크를 훈련하기 위해 OccNeRF는 볼륨 렌더링을 사용하여 점유를 깊이 맵으로 변환하고 광도 손실 함수를 통해 감독하기로 선택했습니다. 샘플링 전략은 깊이 맵을 렌더링할 때 중요합니다. 매개변수화된 공간에서 깊이나 시차를 기준으로 균일하게 직접 샘플링하면 샘플링 지점이 내부 또는 외부 공간에 고르지 않게 분포되어 최적화 프로세스에 영향을 미칩니다. 따라서 OccNeRF는 카메라 중심이 원점에 가깝다는 전제 하에 매개변수화된 공간에서 균일하게 직접 샘플링하는 것을 제안합니다. 또한 OccNeRF는 훈련 중에 다중 프레임 깊이 맵을 렌더링하고 감독합니다.
아래 그림은 파라메트릭 공간 표현 사용의 장점을 시각적으로 보여줍니다. (세 번째 줄은 매개변수화된 공간을 사용하고 두 번째 줄은 사용하지 않습니다.)

Semantic Label Generation
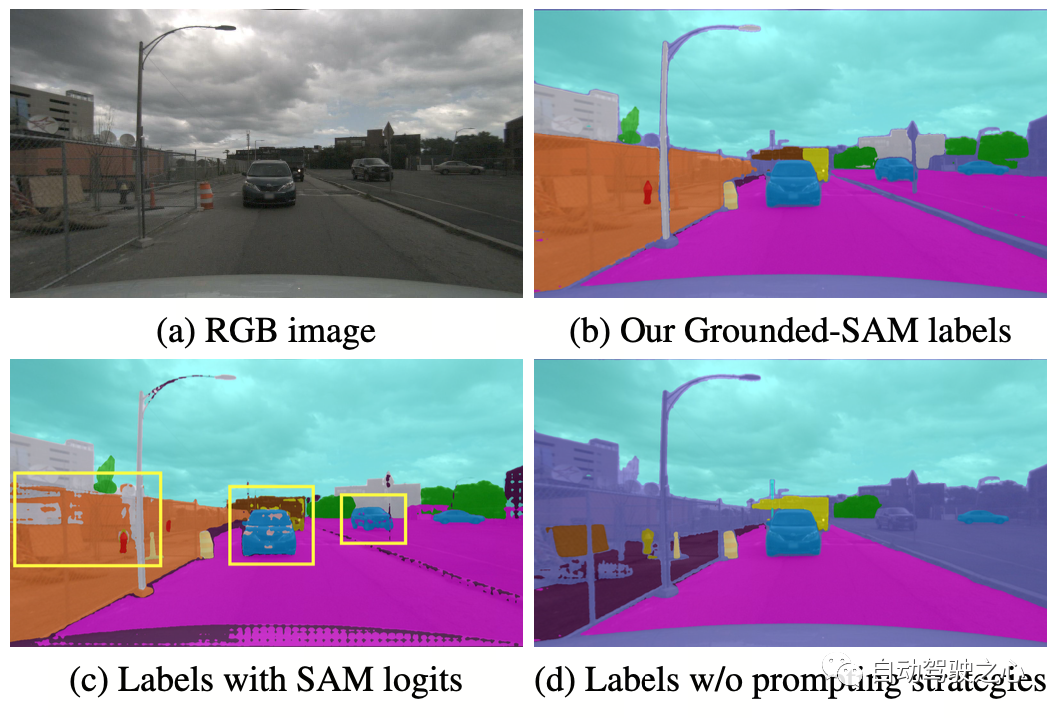
OccNeRF는 사전 훈련된 GroundedSAM(Grounding DINO + SAM)을 사용하여 2D 의미 체계 라벨을 생성합니다. OccNeRF는 고품질 라벨을 생성하기 위해 두 가지 전략을 채택합니다. 하나는 nuScene의 모호한 카테고리를 정확한 설명으로 대체하는 프롬프트 단어 최적화입니다. OccNeRF에서는 프롬프트 단어를 최적화하기 위해 세 가지 전략이 사용됩니다: 모호한 단어 대체(자동차가 세단으로 대체됨), 단어 대 단어 다중 단어(인공이 건물, 광고판 및 교량으로 대체됨), 추가 정보 도입(자전거가 자전거로 대체됨) 자전거로 대체(자전거 이용자). 두 번째는 SAM에서 제공하는 픽셀별 신뢰도 대신 Grounding DINO의 감지 프레임 신뢰도를 기반으로 카테고리를 결정하는 것입니다. OccNeRF가 생성한 의미 라벨 효과는 다음과 같습니다.
OccNeRF는 nuScenes에 대한 실험을 수행했으며 주로 다중 뷰 자기 지도 깊이 추정 및 3D 점유 예측 작업을 완료했습니다.
다중 시점 자기주도 깊이 추정
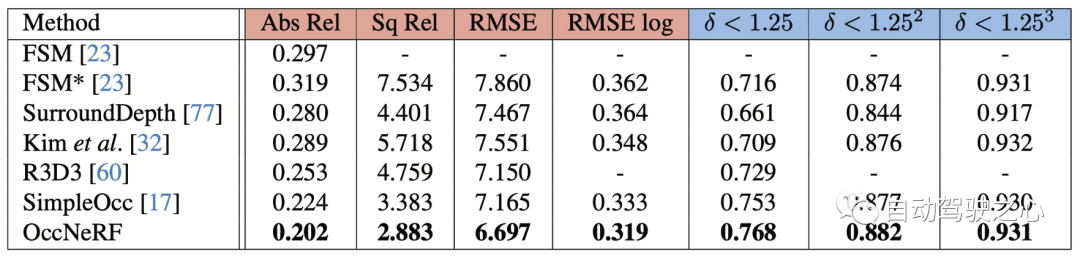
OccNeRF의 NuScene에 대한 다중 시점 자기주도 깊이 추정 성능은 아래 표와 같습니다. 3D 모델링을 기반으로 한 OccNeRF는 2D 방식을 훨씬 능가하고 SimpleOcc도 능가한다는 것을 알 수 있는데, 이는 주로 야외 장면에 대해 OccNeRF가 모델링하는 무제한 공간 범위 때문입니다.
 논문에 나온 일부 시각화는 다음과 같습니다.
논문에 나온 일부 시각화는 다음과 같습니다.
 3D 점유 예측
3D 점유 예측
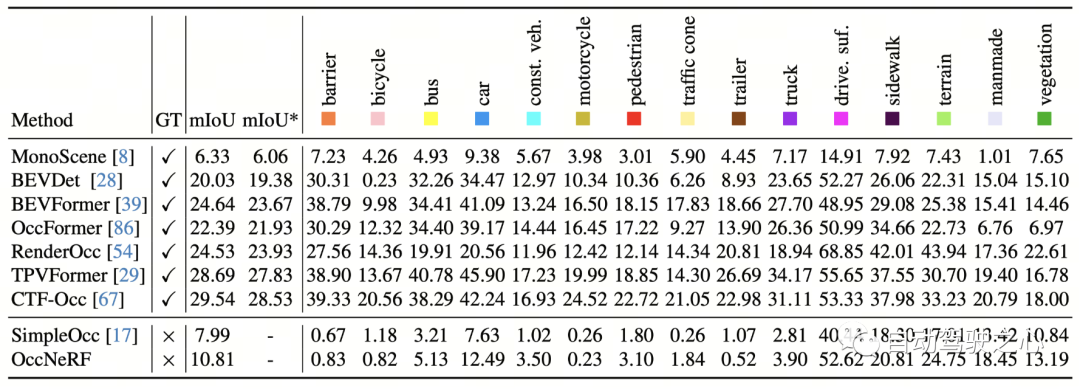
nuScenes에서 OccNeRF의 3D 점유 예측 성능은 아래 표에 나와 있습니다. OccNeRF는 주석이 달린 데이터를 전혀 사용하지 않기 때문에 성능은 여전히 감독 방법에 비해 뒤떨어집니다. 그러나 운전 가능한 표면 및 인공과 같은 일부 범주는 감독 방법과 비슷한 성능을 달성했습니다.
 기사에 포함된 시각화 중 일부는 다음과 같습니다.
기사에 포함된 시각화 중 일부는 다음과 같습니다.

많은 자동차 제조업체가 LiDAR 센서를 제거하려고 하는 이때, 라벨이 지정되지 않은 수천 개의 이미지를 효과적으로 활용하는 방법 데이터는 중요한 이슈 주제입니다. 그리고 OccNeRF는 우리에게 귀중한 시도를 가져왔습니다.
 원본 링크: https://mp.weixin.qq.com/s/UiYEeauAGVtT0c5SB2tHEA
원본 링크: https://mp.weixin.qq.com/s/UiYEeauAGVtT0c5SB2tHEA
위 내용은 OccNeRF: LiDAR 데이터 감독이 전혀 필요하지 않습니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7486
7486
 15
1377
52
77
11
51
19
19
38
15
1377
52
77
11
51
19
19
38

 자율주행 분야에서 Gaussian Splatting이 인기를 끌면서 NeRF가 폐기되기 시작한 이유는 무엇입니까?
Jan 17, 2024 pm 02:57 PM
자율주행 분야에서 Gaussian Splatting이 인기를 끌면서 NeRF가 폐기되기 시작한 이유는 무엇입니까?
Jan 17, 2024 pm 02:57 PM
위에 작성됨 및 저자의 개인적인 이해 3DGS(3차원 가우스플래팅)는 최근 몇 년간 명시적 방사선장 및 컴퓨터 그래픽 분야에서 등장한 혁신적인 기술입니다. 이 혁신적인 방법은 수백만 개의 3D 가우스를 사용하는 것이 특징이며, 이는 주로 암시적 좌표 기반 모델을 사용하여 공간 좌표를 픽셀 값에 매핑하는 NeRF(Neural Radiation Field) 방법과 매우 다릅니다. 명시적인 장면 표현과 미분 가능한 렌더링 알고리즘을 갖춘 3DGS는 실시간 렌더링 기능을 보장할 뿐만 아니라 전례 없는 수준의 제어 및 장면 편집 기능을 제공합니다. 이는 3DGS를 차세대 3D 재구성 및 표현을 위한 잠재적인 게임 체인저로 자리매김합니다. 이를 위해 우리는 처음으로 3DGS 분야의 최신 개발 및 관심사에 대한 체계적인 개요를 제공합니다.
 자율주행 시나리오에서 롱테일 문제를 해결하는 방법은 무엇입니까?
Jun 02, 2024 pm 02:44 PM
자율주행 시나리오에서 롱테일 문제를 해결하는 방법은 무엇입니까?
Jun 02, 2024 pm 02:44 PM
어제 인터뷰 도중 롱테일 관련 질문을 해본 적이 있느냐는 질문을 받아서 간략하게 요약해볼까 생각했습니다. 자율주행의 롱테일 문제는 자율주행차의 엣지 케이스, 즉 발생 확률이 낮은 가능한 시나리오를 말한다. 인지된 롱테일 문제는 현재 단일 차량 지능형 자율주행차의 운영 설계 영역을 제한하는 주요 이유 중 하나입니다. 자율주행의 기본 아키텍처와 대부분의 기술적인 문제는 해결되었으며, 나머지 5%의 롱테일 문제는 점차 자율주행 발전을 제한하는 핵심이 되었습니다. 이러한 문제에는 다양한 단편적인 시나리오, 극단적인 상황, 예측할 수 없는 인간 행동이 포함됩니다. 자율 주행에서 엣지 시나리오의 "롱테일"은 자율주행차(AV)의 엣지 케이스를 의미하며 발생 확률이 낮은 가능한 시나리오입니다. 이런 희귀한 사건
 카메라 또는 LiDAR를 선택하시겠습니까? 강력한 3D 객체 감지 달성에 대한 최근 검토
Jan 26, 2024 am 11:18 AM
카메라 또는 LiDAR를 선택하시겠습니까? 강력한 3D 객체 감지 달성에 대한 최근 검토
Jan 26, 2024 am 11:18 AM
0. 전면 작성&& 자율주행 시스템은 다양한 센서(예: 카메라, 라이더, 레이더 등)를 사용하여 주변 환경을 인식하고 알고리즘과 모델을 사용하는 고급 인식, 의사결정 및 제어 기술에 의존한다는 개인적인 이해 실시간 분석과 의사결정을 위해 이를 통해 차량은 도로 표지판을 인식하고, 다른 차량을 감지 및 추적하며, 보행자 행동을 예측하는 등 복잡한 교통 환경에 안전하게 작동하고 적응할 수 있게 되므로 현재 널리 주목받고 있으며 미래 교통의 중요한 발전 분야로 간주됩니다. . 하나. 하지만 자율주행을 어렵게 만드는 것은 자동차가 주변에서 일어나는 일을 어떻게 이해할 수 있는지 알아내는 것입니다. 이를 위해서는 자율주행 시스템의 3차원 객체 감지 알고리즘이 주변 환경의 객체의 위치를 포함하여 정확하게 인지하고 묘사할 수 있어야 하며,
 CLIP-BEVFormer: BEVFormer 구조를 명시적으로 감독하여 롱테일 감지 성능을 향상시킵니다.
Mar 26, 2024 pm 12:41 PM
CLIP-BEVFormer: BEVFormer 구조를 명시적으로 감독하여 롱테일 감지 성능을 향상시킵니다.
Mar 26, 2024 pm 12:41 PM
위에 작성 및 저자의 개인적인 이해: 현재 전체 자율주행 시스템에서 인식 모듈은 중요한 역할을 합니다. 자율주행 시스템의 제어 모듈은 적시에 올바른 판단과 행동 결정을 내립니다. 현재 자율주행 기능을 갖춘 자동차에는 일반적으로 서라운드 뷰 카메라 센서, 라이더 센서, 밀리미터파 레이더 센서 등 다양한 데이터 정보 센서가 장착되어 다양한 방식으로 정보를 수집하여 정확한 인식 작업을 수행합니다. 순수 비전을 기반으로 한 BEV 인식 알고리즘은 하드웨어 비용이 저렴하고 배포가 용이하며, 출력 결과를 다양한 다운스트림 작업에 쉽게 적용할 수 있어 업계에서 선호됩니다.
 자율주행과 궤도예측에 관한 글은 이 글이면 충분합니다!
Feb 28, 2024 pm 07:20 PM
자율주행과 궤도예측에 관한 글은 이 글이면 충분합니다!
Feb 28, 2024 pm 07:20 PM
자율주행 궤적 예측은 차량의 주행 과정에서 발생하는 다양한 데이터를 분석하여 차량의 향후 주행 궤적을 예측하는 것을 의미합니다. 자율주행의 핵심 모듈인 궤도 예측의 품질은 후속 계획 제어에 매우 중요합니다. 궤적 예측 작업은 풍부한 기술 스택을 보유하고 있으며 자율 주행 동적/정적 인식, 고정밀 지도, 차선, 신경망 아키텍처(CNN&GNN&Transformer) 기술 등에 대한 익숙함이 필요합니다. 시작하기가 매우 어렵습니다! 많은 팬들은 가능한 한 빨리 궤도 예측을 시작하여 함정을 피하기를 희망합니다. 오늘은 궤도 예측을 위한 몇 가지 일반적인 문제와 입문 학습 방법을 살펴보겠습니다. 관련 지식 입문 1. 미리보기 논문이 순서대로 되어 있나요? A: 먼저 설문조사를 보세요, p
 nuScenes의 최신 SOTA | SparseAD: Sparse 쿼리는 효율적인 엔드투엔드 자율주행을 지원합니다!
Apr 17, 2024 pm 06:22 PM
nuScenes의 최신 SOTA | SparseAD: Sparse 쿼리는 효율적인 엔드투엔드 자율주행을 지원합니다!
Apr 17, 2024 pm 06:22 PM
전면 및 시작점 작성 엔드 투 엔드 패러다임은 통합 프레임워크를 사용하여 자율 주행 시스템에서 멀티 태스킹을 달성합니다. 이 패러다임의 단순성과 명확성에도 불구하고 하위 작업에 대한 엔드투엔드 자율 주행 방법의 성능은 여전히 단일 작업 방법보다 훨씬 뒤떨어져 있습니다. 동시에 이전 엔드투엔드 방법에서 널리 사용된 조밀한 조감도(BEV) 기능으로 인해 더 많은 양식이나 작업으로 확장하기가 어렵습니다. 여기서는 희소 검색 중심의 엔드 투 엔드 자율 주행 패러다임(SparseAD)이 제안됩니다. 여기서 희소 검색은 밀집된 BEV 표현 없이 공간, 시간 및 작업을 포함한 전체 운전 시나리오를 완전히 나타냅니다. 특히 통합 스파스 아키텍처는 탐지, 추적, 온라인 매핑을 포함한 작업 인식을 위해 설계되었습니다. 게다가 무겁다.
 SIMPL: 자율 주행을 위한 간단하고 효율적인 다중 에이전트 동작 예측 벤치마크
Feb 20, 2024 am 11:48 AM
SIMPL: 자율 주행을 위한 간단하고 효율적인 다중 에이전트 동작 예측 벤치마크
Feb 20, 2024 am 11:48 AM
원제목: SIMPL: ASimpleandEfficientMulti-agentMotionPredictionBaselineforAutonomousDriving 논문 링크: https://arxiv.org/pdf/2402.02519.pdf 코드 링크: https://github.com/HKUST-Aerial-Robotics/SIMPL 저자 단위: Hong Kong University of Science 및 기술 DJI 논문 아이디어: 이 논문은 자율주행차를 위한 간단하고 효율적인 모션 예측 기준선(SIMPL)을 제안합니다. 기존 에이전트 센트와 비교
 엔드투엔드(End-to-End)와 차세대 자율주행 시스템, 그리고 엔드투엔드 자율주행에 대한 몇 가지 오해에 대해 이야기해볼까요?
Apr 15, 2024 pm 04:13 PM
엔드투엔드(End-to-End)와 차세대 자율주행 시스템, 그리고 엔드투엔드 자율주행에 대한 몇 가지 오해에 대해 이야기해볼까요?
Apr 15, 2024 pm 04:13 PM
지난 달에는 몇 가지 잘 알려진 이유로 업계의 다양한 교사 및 급우들과 매우 집중적인 교류를 가졌습니다. 교환에서 피할 수 없는 주제는 자연스럽게 엔드투엔드와 인기 있는 Tesla FSDV12입니다. 저는 이 기회를 빌어 여러분의 참고와 토론을 위해 지금 이 순간 제 생각과 의견을 정리하고 싶습니다. End-to-End 자율주행 시스템을 어떻게 정의하고, End-to-End 해결을 위해 어떤 문제가 예상되나요? 가장 전통적인 정의에 따르면, 엔드 투 엔드 시스템은 센서로부터 원시 정보를 입력하고 작업과 관련된 변수를 직접 출력하는 시스템을 의미합니다. 예를 들어 이미지 인식에서 CNN은 기존의 특징 추출 + 분류기 방식에 비해 end-to-end 방식으로 호출할 수 있습니다. 자율주행 작업에서는 다양한 센서(카메라/LiDAR)로부터 데이터를 입력받아
