

解析MySQL数据库性能优化的六大技巧_MySQL

bitsCN.com
数据库表表面上存在索引和防错机制,然而一个简单的查询就会耗费很长时间。Web应用程序或许在开发环境中运行良好,但在产品环境中表现同样糟糕。如果你是个数据库管理员,你很有可能已经在某个阶段遇到上述情况。因此,本文将介绍对MySQL进行性能优化的技巧和窍门。
1.存储引擎的选择
如果数据表需要事务处理,应该考虑使用InnoDB,因为它完全符合ACID特性。如果不需要事务处理,使用默认存储引擎MyISAM是比较明智的。并且不要尝试同时使用这两个存储引擎。思考一下:在一个事务处理中,一些数据表使用InnoDB,而其余的使用MyISAM。结果呢?整个subject将被取消,只有那些在事务处理中的被带回到原始状态,其余的被提交的数据转存,这将导致整个数据库的冲突。然而存在一个简单的方法可以同时利用两个存储引擎的优势。目前大多数MySQL套件中包括InnoDB、编译器和链表,但如果你选择MyISAM,你仍然可以单独下载InnoDB,并把它作为一个插件。很简单的方法,不是吗?
2.计数问题
如果数据表采用的存储引擎支持事务处理(如InnoDB),你就不应使用COUNT(*)计算数据表中的行数。这是因为在产品类数据库使用COUNT(*),最多返回一个近似值,因为在某个特定时间,总有一些事务处理正在运行。如果使用COUNT(*)显然会产生bug,出现这种错误结果。
3.反复测试查询
查询最棘手的问题并不是无论怎样小心总会出现错误,并导致bug出现。恰恰相反,问题是在大多数情况下bug出现时,应用程序或数据库已经上线。的确不存在针对该问题切实可行的解决方法,除非将测试样本在应用程序或数据库上运行。任何数据库查询只有经过上千个记录的大量样本测试,才能被认可。
4.避免全表扫描
通常情况下,如果MySQL(或者其他关系数据库模型)需要在数据表中搜索或扫描任意特定记录时,就会用到全表扫描。此外,通常最简单的方法是使用索引表,以解决全表扫描引起的低效能问题。然而,正如我们在随后的问题中看到的,这存在错误部分。
5.使用”EXPLAIN”进行查询
当需要调试时,EXPLAIN是一个很好的命令,下面将对EXPLAIN进行深入探讨。
首先,创建一个简单的数据表:
CREATETABLE'awesome_pcq'(
'emp_id'INT(10)NOTNULL
DEFAULT'0',
'full_name'VARCHAR(100)NOTNULL,
'email_id'VARCHAR(100)NOTNULL,
'password'VARCHAR(50)NOTNULL,
'deleted'TINYINT(4)NOTNULL,
PRIMARYKEY('emp_id')
) COLLATE='utf8_general_ci'
ENGINE=InnoDB
ROW_FORMAT=DEFAULT
这个数据表一目了然,共有五列,最后一列“deleted”是一个Boolean类变量flag来检查帐号是活动的还是已被删除。接下来,您需要用样本记录填充这个表(比如,100个雇员记录)。正如你看到的,主键是“emp_id”。因此,使用电子邮件地址和密码字段,我们可以很容易地创建一个查询,以验证或拒绝登录请求,如下(实例一):
SELECTCOUNT(*)FROMawesome_pcqWHERE
email_id='blahblah'ANDpassword='blahblah'ANDdeleted=0
之前我们提到,要避免使用COUNT(*)。代码纠正如下(实例二):
SELECTemp_idFROMawesome_pcqWHERE
email_id='blahblah'ANDpassword='blahblah'ANDdeleted=0
现在回想一下,在实例一中,代码查询定位并返回“email_id”和“password”等于给定值的行数。在实例二中,进行了同样的查询,不同的是明确要求列出“emp_id”所有满足给定的标准的值。哪个查询更费时?
很显然,这两个实例都是同样费时的数据库查询,因为无意间,两个实例查询都进行了全表扫描。为了更好地读懂指令,执行如下代码:
EXPLAINSELECTemp_idFROMawesome_pcqWHERE
email_id='blahblah'ANDpassword='blahblah'ANDdeleted=0
在输出时,集中在倒数第二列:“rows”。假设我们已经将表填充了100个记录,它会在第一行显示100,这是MySQL需要进行扫描用来计算查询的结果的行数。这说明了什么?这需要全表扫描。为了克服这个弊端,则需要添加索引。
6.添加索引
先从重要的说起:给每一个可能遇到的次要问题创建索引并不明智。过多的索引会导致效能减慢和资源占用。在进一步讨论之前,在实例中创建一个样本索引:
ALTERTABLE'awesome_pcq'ADDINDEX'LoginValidate'('email_id')
接下来,再次运行该查询:
EXPLAINSELECTemp_idFROMawesome_pcqWHERE
email_id='blahblah'ANDpassword='blahblah'ANDdeleted=0
请注意运行后的值。不是100,而是1。因此,为了给出查询结果,MySQL只扫描了1行,多亏先前创建的索引。你可能会注意到,索引只在电子邮件地址字段创建,而查询对其他字段同样进行了搜索。这表明MySQL先执行了一个cros-check,检查是否有在WHERE子句中的定义的值有索引指定,如果有这样的值就执行相应的操作。
但是,它不是每次重复将减少到一个。例如,如果不是唯一的索引字段(如employee names列可以有两行相同的值),即使创建索引,也将有多个记录留下。但它仍然比全表扫描好。并且,在WHERE子句中指定列的顺序没有在这个过程中发挥作用。例如,如果在上面的查询中,改变字段的顺序,使电子邮件地址出现在最后,MySQL仍将遍历索引列的基础上。那么,就要在索引上动脑筋,注意如何避免大量的全表扫描,并获得更好的结果。不过,这需要经历一个很长的过程。
bitsCN.com

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7319
7319
 9
1625
14
1349
46
1261
25
1209
29
9
1625
14
1349
46
1261
25
1209
29

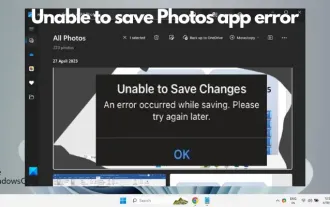 Windows 11에서 사진 앱 오류에 대한 변경 사항을 저장할 수 없습니다.
Mar 04, 2024 am 09:34 AM
Windows 11에서 사진 앱 오류에 대한 변경 사항을 저장할 수 없습니다.
Mar 04, 2024 am 09:34 AM
Windows 11에서 이미지 편집을 위해 사진 앱을 사용하는 동안 변경 내용을 저장할 수 없습니다. 오류가 발생하는 경우 이 문서에서 해결 방법을 제공합니다. 변경사항을 저장할 수 없습니다. 저장하는 동안 오류가 발생했습니다. 나중에 다시 시도해 주세요. 이 문제는 일반적으로 잘못된 권한 설정, 파일 손상 또는 시스템 오류로 인해 발생합니다. 그래서 우리는 이 문제를 해결하고 Windows 11 장치에서 Microsoft 사진 앱을 계속해서 원활하게 사용할 수 있도록 심층적인 연구를 수행하고 가장 효과적인 문제 해결 단계 중 일부를 정리했습니다. Windows 11에서 사진 앱 오류에 대한 변경 사항을 저장할 수 없는 문제 수정 많은 사용자가 다른 포럼에서 Microsoft 사진 앱 오류에 대해 이야기해 왔습니다.
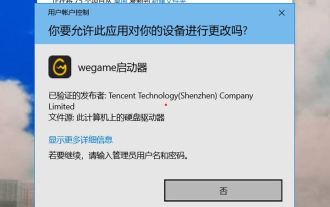 Windows 11에서 계속하려면 관리자 사용자 이름과 비밀번호를 입력하라는 메시지가 표시되는 문제를 해결하는 방법은 무엇입니까?
Apr 11, 2024 am 09:10 AM
Windows 11에서 계속하려면 관리자 사용자 이름과 비밀번호를 입력하라는 메시지가 표시되는 문제를 해결하는 방법은 무엇입니까?
Apr 11, 2024 am 09:10 AM
Win11 시스템을 사용할 때 관리자 사용자 이름과 비밀번호를 입력하라는 메시지가 표시되는 경우가 있습니다. 이 문서에서는 이 상황을 처리하는 방법에 대해 설명합니다. 방법 1: 1. [Windows 로고]를 클릭한 다음 [Shift+다시 시작]을 눌러 안전 모드로 들어가거나 이 방법으로 안전 모드로 들어갑니다. 시작 메뉴를 클릭하고 설정을 선택합니다. "업데이트 및 보안"을 선택하고 "복구"에서 "지금 다시 시작"을 선택한 후 옵션을 입력하고 - 문제 해결 - 고급 옵션 - 시작 설정 -&mdash를 선택하세요.
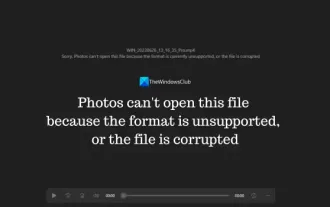 형식이 지원되지 않거나 파일이 손상되었기 때문에 포토에서 이 파일을 열 수 없습니다.
Feb 22, 2024 am 09:49 AM
형식이 지원되지 않거나 파일이 손상되었기 때문에 포토에서 이 파일을 열 수 없습니다.
Feb 22, 2024 am 09:49 AM
Windows에서 사진 앱은 사진과 비디오를 보고 관리하는 편리한 방법입니다. 이 애플리케이션을 통해 사용자는 추가 소프트웨어를 설치하지 않고도 멀티미디어 파일에 쉽게 액세스할 수 있습니다. 그러나 때때로 사용자는 사진 앱을 사용할 때 "지원되지 않는 형식이므로 이 파일을 열 수 없습니다."라는 오류 메시지가 표시되거나 사진이나 비디오를 열려고 할 때 파일이 손상되는 등 몇 가지 문제가 발생할 수 있습니다. 이러한 상황은 사용자에게 혼란스럽고 불편할 수 있으므로 문제를 해결하려면 몇 가지 조사와 수정이 필요합니다. 사용자가 사진 앱에서 사진이나 비디오를 열려고 하면 다음 오류가 표시됩니다. 죄송합니다. 해당 형식이 현재 지원되지 않거나 파일이 아니기 때문에 포토에서 이 파일을 열 수 없습니다.
 응용 프로그램 시작 오류 0xc000012d 문제를 해결하는 방법
Jan 02, 2024 pm 12:53 PM
응용 프로그램 시작 오류 0xc000012d 문제를 해결하는 방법
Jan 02, 2024 pm 12:53 PM
친구의 컴퓨터에 특정 파일이 누락된 경우 오류 코드 0xc000012d가 발생하며 애플리케이션이 정상적으로 시작되지 않습니다. 실제로 해당 파일을 다시 다운로드하여 설치하면 쉽게 해결할 수 있습니다. 응용 프로그램을 정상적으로 시작할 수 없습니다. 0xc000012d: 1. 먼저 사용자는 ".netframework"를 다운로드해야 합니다. 2. 그런 다음 다운로드 주소를 찾아 컴퓨터에 다운로드합니다. 3. 그런 다음 바탕 화면을 두 번 클릭하여 실행을 시작합니다. 4. 설치가 완료되면 잘못된 프로그램 위치로 돌아가 프로그램을 다시 실행해 보세요.
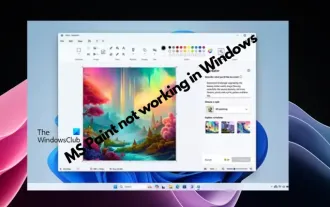 MS 그림판이 Windows 11에서 제대로 작동하지 않습니다.
Mar 09, 2024 am 09:52 AM
MS 그림판이 Windows 11에서 제대로 작동하지 않습니다.
Mar 09, 2024 am 09:52 AM
Microsoft Paint가 Windows 11/10에서 작동하지 않습니까? 글쎄, 이것은 일반적인 문제인 것 같으며 우리는 이를 해결할 수 있는 몇 가지 훌륭한 솔루션을 가지고 있습니다. 사용자들은 MSPaint를 사용하려고 할 때 작동하지 않거나 열리지 않는다고 불평해 왔습니다. 앱의 스크롤바가 작동하지 않고, 붙여넣기 아이콘이 표시되지 않고, 충돌이 발생하는 등의 현상이 발생합니다. 다행히 Microsoft 그림판 앱 관련 문제를 해결하는 데 도움이 되는 가장 효과적인 문제 해결 방법 중 일부를 수집했습니다. Microsoft 그림판이 작동하지 않는 이유는 무엇입니까? MSPaint가 Windows 11/10 PC에서 작동하지 않는 몇 가지 이유는 다음과 같습니다. 보안 식별자가 손상되었습니다. 정지 시스템
 Apple Vision Pro를 PC에 연결하는 방법
Apr 08, 2024 pm 09:01 PM
Apple Vision Pro를 PC에 연결하는 방법
Apr 08, 2024 pm 09:01 PM
Apple Vision Pro 헤드셋은 기본적으로 컴퓨터와 호환되지 않으므로 Windows 컴퓨터에 연결되도록 구성해야 합니다. Apple Vision Pro는 출시 이후 큰 인기를 끌었으며, 최첨단 기능과 광범위한 조작성을 통해 그 이유를 쉽게 알 수 있습니다. PC에 맞게 일부 조정할 수 있지만 기능은 AppleOS에 크게 의존하므로 기능이 제한됩니다. AppleVisionPro를 내 컴퓨터에 어떻게 연결합니까? 1. 시스템 요구 사항 확인 최신 버전의 Windows 11이 필요합니다. (Custom PC 및 Surface 장치는 지원되지 않습니다.) 64비트 2GHZ 이상 빠른 프로세서 지원 고성능 GPU, 대부분
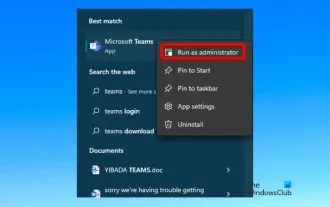 caa90019 Microsoft Teams 오류 수정
Feb 19, 2024 pm 02:30 PM
caa90019 Microsoft Teams 오류 수정
Feb 19, 2024 pm 02:30 PM
많은 사용자들이 Microsoft Teams를 사용하여 로그인을 시도할 때마다 오류 코드 caa90019가 발생한다고 불평해 왔습니다. 편리한 커뮤니케이션 앱임에도 이런 실수는 매우 흔합니다. Microsoft Teams 오류 수정: caa90019 이 경우 시스템에 표시되는 오류 메시지는 "죄송합니다. 현재 문제가 발생했습니다." Microsoft Teams 오류 caa90019를 해결하는 데 도움이 되는 궁극적인 솔루션 목록을 준비했습니다. 예비 단계 관리자로 실행 Microsoft Teams 애플리케이션 캐시 지우기 settings.json 파일 삭제 Credential Manager에서 Microsoft 지우기
 Win11 관리자가 이 응용 프로그램을 실행하지 못하도록 차단합니다.
Jan 30, 2024 pm 05:18 PM
Win11 관리자가 이 응용 프로그램을 실행하지 못하도록 차단합니다.
Jan 30, 2024 pm 05:18 PM
Win11 시스템 관리자가 이 애플리케이션을 실행하는 것을 차단했습니다. Windows 11 운영 체제를 사용할 때 시스템 관리자가 애플리케이션 실행을 차단하는 일반적인 문제가 발생할 수 있습니다. 작업을 완료하거나 엔터테인먼트를 즐기기 위해 이 애플리케이션을 실행해야 할 수도 있으므로 이는 혼란스럽고 실망스러울 수 있습니다. 그러나 걱정하지 마십시오. 일반적으로 이 문제에 대한 해결책이 있습니다. 먼저, 왜 이런 문제가 발생하는지 이해해야 합니다. Windows 11 운영 체제는 맬웨어나 바이러스의 실행을 방지하기 위해 더 높은 수준의 보안 및 개인 정보 보호 조치를 갖추고 있으며, 시스템 관리자는 특정 응용 프로그램의 실행 권한을 제한할 수 있습니다. 이는 귀하의 컴퓨터와 개인정보의 보안을 보호하기 위한 것입니다. 그러나 때로는 시스템 관리자가
