

Linux에서 du와 ls로 계산한 파일 크기가 10배 다르다고요?

事情是这样的,昨天开发让我给他倒个日志,由于历史原因吧,没有日志系统,直接上服务器看了下他要的日志大小
[root@xxxxx apps]# du -hs smartorder.log 9.0G smartorder.log
看了下,不小,我问开发,要整个日志吗,还是可以按日期给他切一下,他说要整个,我想着日志文件,通常压缩完也没多少,就压缩了一下,压缩完确实也不是太大
[root@xxxxx apps]# du -hs smartorder.log.tar.gz 744M smartorder.log.tar.gz
没多想,我就给他down下来发过去了
晚上回家,哥们找到我了

我说不可能啊,怎么可能100G,吓到我了,他还给我发了个截图
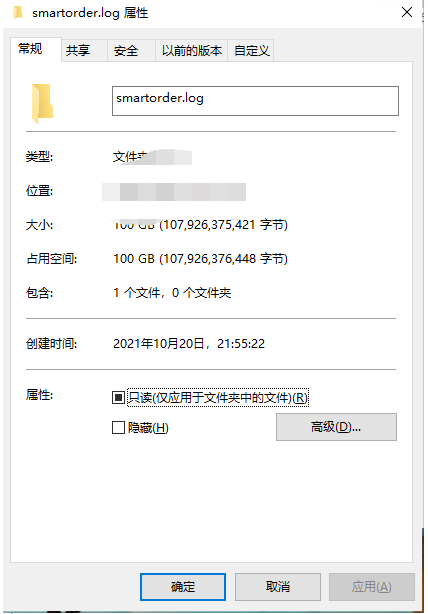
确实是100G,没办法,开电脑上服务器查看,通过ls指定–block-size查看大小
[root@xxxxx apps]# ls -l --block-size=G smartorder.log -rw-r--r-- 1 root root 103G Oct 21 09:00 smartorder.log
这。。。。。
后来想起来,du查找的时候是按照block大小计算的,计算的是实际占用磁盘空间的大小,但即便这样,按道理,和ls命令查出来的大小不会差太多,但是凡事有例外
linux中有一种文件叫做sparse file,它可以延迟分配磁盘空间,类似于我们用的虚拟机,在创建虚拟机的时候,可以分配20G的磁盘空间,但是你创建完后,去查看宿主机磁盘占用,确实际没有占用那么多
Sparse File专业名称叫稀疏文件,这是Unix类和NTFS等文件系统的一个特性
开始时,一个sparse file不包含数据,也没有分配到用来存储用户数据的磁盘空间。当数据被写入sparse file时,NTFS逐渐为其分配磁盘空间。
Sparse File以64KB为单位增量增长,所以磁盘上sparse file的大小总是64KB的倍数
Sparse File就是在文件中留有很多空余空间,留备将来插入数据使用。如果这些空余空间被ASCII码的NULL字符占据,并且这些空间相当大,那么,这个文件就被称为稀疏文件,而且,并不分配相应的磁盘块。
很显然,我上面遇到的就是一个Sparse File,那么这么大的一个sparse file,怎么处理?
其实cp命令有一个针对sparse文件拷贝优化的参数–spare=WHEN,WHEN的值为auto、always、never,默认为auto,如果设置为never则会自动填数据
同样支持sparse的命令还有tar、cpio、rsync,下面通过tar试下
[root@bibang-server apps]# tar cSf smartorder.log.tar smartorder.log [root@bibang-server apps]# ls -l --block-size=G smartorder.log.tar -rw-r--r-- 1 root root 10G Oct 21 09:57 smartorder.log.tar
如何查找系统上的sparse file,或确认文件是否是sparse file?
[root@xxxxx apps]# find ./smartorder.log -type f -printf "%S\t%p\n" 0.0886597 ./smartorder.log
如上,通过find命令,find命令通过%S输出的结果中,最左边一列显示的值是(BLOCK-SIZE*st_blocks/st_size),sparse file的大小通常是小于1.0的
如果要查找文件系统上所有稀疏文件,可以通过以下find命令
find / -type f -printf "%S\t%p\n" | gawk '$1
ok,今天的内容就到这里了,欢迎转发、在看、关注!
위 내용은 Linux에서 du와 ls로 계산한 파일 크기가 10배 다르다고요?의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7471
7471
 15
1377
52
77
11
48
19
19
30
15
1377
52
77
11
48
19
19
30

 Linux 터미널에서 Python (Version 명령)을 사용할 때 권한 문제를 해결하는 방법은 무엇입니까?
Apr 02, 2025 am 06:36 AM
Linux 터미널에서 Python (Version 명령)을 사용할 때 권한 문제를 해결하는 방법은 무엇입니까?
Apr 02, 2025 am 06:36 AM
Linux 터미널에서 Python 사용 ...
 C 언어로 멀티 스레딩을 구현하는 4 가지 방법
Apr 03, 2025 pm 03:00 PM
C 언어로 멀티 스레딩을 구현하는 4 가지 방법
Apr 03, 2025 pm 03:00 PM
언어의 멀티 스레딩은 프로그램 효율성을 크게 향상시킬 수 있습니다. C 언어에서 멀티 스레딩을 구현하는 4 가지 주요 방법이 있습니다. 독립 프로세스 생성 : 여러 독립적으로 실행되는 프로세스 생성, 각 프로세스에는 자체 메모리 공간이 있습니다. 의사-다일리트 레딩 : 동일한 메모리 공간을 공유하고 교대로 실행하는 프로세스에서 여러 실행 스트림을 만듭니다. 멀티 스레드 라이브러리 : PTHREADS와 같은 멀티 스레드 라이브러리를 사용하여 스레드를 만들고 관리하여 풍부한 스레드 작동 기능을 제공합니다. COROUTINE : 작업을 작은 하위 작업으로 나누고 차례로 실행하는 가벼운 다중 스레드 구현.
 Web.xml을 열는 방법
Apr 03, 2025 am 06:51 AM
Web.xml을 열는 방법
Apr 03, 2025 am 06:51 AM
Web.xml 파일을 열려면 다음 방법을 사용할 수 있습니다. 텍스트 편집기 (예 : 메모장 또는 문자 메시지)를 사용하여 통합 개발 환경 (예 : Eclipse 또는 NetBeans)을 사용하여 명령을 편집하십시오 (Windows : Notepad Web.xml; Mac/Linux : Open -A Texted web.xml).
 Linux 시스템에서 Python 통역사를 삭제할 수 있습니까?
Apr 02, 2025 am 07:00 AM
Linux 시스템에서 Python 통역사를 삭제할 수 있습니까?
Apr 02, 2025 am 07:00 AM
Linux 시스템과 함께 제공되는 Python 통역사를 제거하는 문제와 관련하여 많은 Linux 배포판이 설치 될 때 Python 통역사를 사전 설치하고 패키지 관리자를 사용하지 않습니다 ...
 가장 잘 사용되는 Linux는 무엇입니까?
Apr 03, 2025 am 12:11 AM
가장 잘 사용되는 Linux는 무엇입니까?
Apr 03, 2025 am 12:11 AM
Linux는 서버 관리, 임베디드 시스템 및 데스크탑 환경으로 사용되는 것이 가장 좋습니다. 1) 서버 관리에서 Linux는 웹 사이트, 데이터베이스 및 응용 프로그램을 호스팅하는 데 사용되어 안정성과 안정성을 제공합니다. 2) 임베디드 시스템에서 Linux는 유연성과 안정성으로 인해 스마트 홈 및 자동차 전자 시스템에서 널리 사용됩니다. 3) 데스크탑 환경에서 Linux는 풍부한 응용 프로그램과 효율적인 성능을 제공합니다.
 데비안 하프 (Debian Hadoop)의 호환성은 어떻습니까?
Apr 02, 2025 am 08:42 AM
데비안 하프 (Debian Hadoop)의 호환성은 어떻습니까?
Apr 02, 2025 am 08:42 AM
Debianlinux는 안정성과 보안으로 유명하며 서버, 개발 및 데스크탑 환경에서 널리 사용됩니다. 현재 Debian 및 Hadoop과 직접 호환성에 대한 공식 지침이 부족하지만이 기사에서는 Debian 시스템에 Hadoop를 배포하는 방법을 안내합니다. 데비안 시스템 요구 사항 : Hadoop 구성을 시작하기 전에 Debian 시스템이 Hadoop의 최소 작동 요구 사항을 충족하는지 확인하십시오. 여기에는 필요한 JAVA 런타임 환경 (JRE) 및 Hadoop 패키지 설치가 포함됩니다. Hadoop 배포 단계 : 다운로드 및 unzip hadoop : 공식 Apachehadoop 웹 사이트에서 필요한 Hadoop 버전을 다운로드하여 해결하십시오.
 GO를 사용하여 Oracle 데이터베이스에 연결할 때 Oracle 클라이언트를 설치해야합니까?
Apr 02, 2025 pm 03:48 PM
GO를 사용하여 Oracle 데이터베이스에 연결할 때 Oracle 클라이언트를 설치해야합니까?
Apr 02, 2025 pm 03:48 PM
GO를 사용하여 Oracle 데이터베이스에 연결할 때 Oracle 클라이언트를 설치해야합니까? GO에서 개발할 때 Oracle 데이터베이스에 연결하는 것이 일반적인 요구 사항입니다 ...
 데비안 문자열은 여러 브라우저와 호환됩니다
Apr 02, 2025 am 08:30 AM
데비안 문자열은 여러 브라우저와 호환됩니다
Apr 02, 2025 am 08:30 AM
"Debiantrings"는 표준 용어가 아니며 구체적인 의미는 여전히 불분명합니다. 이 기사는 브라우저 호환성에 직접 언급 할 수 없습니다. 그러나 "Debiantrings"가 Debian 시스템에서 실행되는 웹 응용 프로그램을 지칭하는 경우 브라우저 호환성은 응용 프로그램 자체의 기술 아키텍처에 따라 다릅니다. 대부분의 최신 웹 응용 프로그램은 크로스 브라우저 호환성에 전념합니다. 이는 웹 표준에 따라 웹 표준과 잘 호환 가능한 프론트 엔드 기술 (예 : HTML, CSS, JavaScript) 및 백엔드 기술 (PHP, Python, Node.js 등)을 사용하는 데 의존합니다. 응용 프로그램이 여러 브라우저와 호환되도록 개발자는 종종 브라우저 크로스 테스트를 수행하고 응답 성을 사용해야합니다.
