

리눅스 그룹 스케줄링에 대한 간략한 분석

Linux 시스템은 다중 작업의 동시 실행을 지원하는 운영 체제로, 동시에 여러 프로세스를 실행할 수 있어 시스템 활용도와 효율성이 향상됩니다. 그러나 Linux 시스템이 최적의 성능을 얻기 위해서는 프로세스 스케줄링 방법을 이해하고 숙달하는 것이 필요합니다. 프로세스 스케줄링은 여러 작업을 동시에 실행하기 위해 특정 알고리즘과 전략을 기반으로 다양한 프로세스에 프로세서 리소스를 동적으로 할당하는 운영 체제의 기능을 나타냅니다. Linux 시스템에는 많은 프로세스 스케줄링 방법이 있으며 그 중 하나가 그룹 스케줄링입니다. 그룹 스케줄링은 서로 다른 프로세스 그룹이 일정 비율로 프로세서 리소스를 공유함으로써 공정성과 효율성 사이의 균형을 달성할 수 있도록 하는 그룹 기반 프로세스 스케줄링 방법입니다. 이 기사에서는 그룹 스케줄링의 원리, 구현, 구성, 장점 및 단점을 포함하여 Linux 그룹 스케줄링 방법을 간략하게 분석합니다.
c그룹 및 그룹 예약
Linux 커널은 그룹화 프로세스를 지원하고 다양한 리소스를 그룹별로 나눌 수 있는 제어 그룹 기능(cgroup, Linux 2.6.24부터)을 구현합니다. 예를 들어 그룹 1에는 CPU 30%와 디스크 IO 50%가 있고, 그룹 2에는 CPU 10%와 디스크 IO 20%가 있는 식입니다. 자세한 내용은 cgroup 관련 기사를 참조하세요.
cgroup은 다양한 유형의 리소스 분할을 지원하며, CPU 리소스도 그 중 하나이며 그룹 스케줄링으로 이어집니다.
Linux 커널에서 기존 스케줄러는 프로세스를 기반으로 예약됩니다. 사용자 A와 B가 주로 프로그램을 컴파일하는 데 사용되는 컴퓨터를 공유한다고 가정합니다. A와 B가 CPU 자원을 공평하게 공유할 수 있기를 바랄 수도 있지만, 사용자 A가 make -j8(8개 스레드 병렬 make)을 사용하고 사용자 B가 make를 직접 사용하는 경우(make 프로그램이 기본 우선순위를 사용한다고 가정할 때) 사용자 A의 make 프로그램은 사용자 B보다 8배 많은 프로세스 수를 생성하므로 사용자 B의 CPU를 (대략) 8배 차지합니다. 스케줄러는 프로세스 기반이기 때문에 사용자 A가 더 많은 프로세스를 보유할수록 스케줄링될 확률이 높아지고 CPU 대비 경쟁력이 높아집니다.
사용자 A와 B가 CPU를 공정하게 공유하도록 하려면 어떻게 해야 할까요? 그룹 예약이 가능합니다. 사용자 A와 B에 속한 프로세스는 각각 하나의 그룹으로 나누어집니다. 스케줄러는 먼저 두 그룹 중 하나의 그룹을 선택한 다음 선택한 그룹에서 실행할 프로세스를 선택합니다. 두 그룹이 선택될 확률이 동일하다면 사용자 A와 B는 각각 CPU의 약 50%를 차지하게 됩니다.
관련 데이터 구조
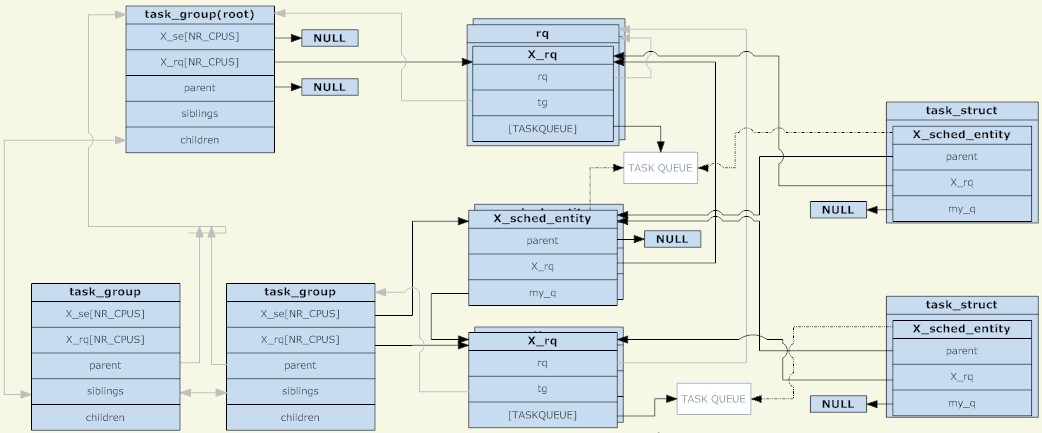
Linux 커널에서는 task_group 구조를 사용하여 그룹 예약을 위한 그룹을 관리합니다. 기존의 모든 task_group은 트리 구조를 형성합니다(cgroup의 디렉터리 구조에 해당).
task_group에는 모든 예약 범주(구체적으로 실시간 프로세스 및 일반 프로세스)가 있는 프로세스가 포함될 수 있으므로 task_group은 각 예약 전략에 대한 예약 구조 집합을 제공해야 합니다. 여기에 언급된 스케줄링 구조 세트는 주로 스케줄링 엔터티와 실행 큐(둘 다 CPU별로 공유됨)라는 두 부분으로 구성됩니다. task_group의 경우 스케줄링 엔터티는 상위 task_group의 실행 큐에 추가됩니다.
일정관리 주체라는 게 왜 있는 걸까요? 예약된 개체에는 task_group과 task라는 두 가지 유형이 있으므로 이를 표현하려면 추상 구조가 필요합니다. 스케줄링 엔터티가 task_group을 나타내는 경우 해당 my_q 필드는 이 스케줄링 그룹에 해당하는 실행 큐를 가리키고, 그렇지 않으면 my_q 필드는 NULL이고 스케줄링 엔터티는 작업을 나타냅니다. 스케줄링 엔터티에서 my_q의 반대는 상위 노드의 실행 큐이며, 이는 이 스케줄링 엔터티가 배치되어야 하는 실행 큐입니다.
따라서 스케줄링 엔터티와 실행 대기열은 또 다른 트리 구조를 형성합니다. 리프가 아닌 노드는 각각 task_group의 트리 구조에 해당하고 리프 노드는 특정 작업에 해당합니다. TASK_RUNNING 상태가 아닌 프로세스가 실행 큐에 들어가지 않는 것처럼, 그룹에 TASK_RUNNING 상태의 프로세스가 없으면 이 그룹(해당 스케줄링 엔터티)은 상위 수준 실행 큐에 들어가지 않습니다. 명확히 말하면, 스케줄링 그룹이 생성되는 한 해당 task_group은 task_group으로 구성된 트리 구조에 확실히 존재하며 해당 스케줄링 엔터티가 실행 큐로 구성된 트리 구조에 존재하는지 여부는 스케줄링 엔터티에 따라 달라집니다. 이 그룹에는 TASK_RUNNING 상태의 프로세스가 있습니다.
루트 노드인 task_group에는 스케줄링 엔터티가 없습니다. 스케줄러는 항상 실행 대기열에서 시작하여 다음 스케줄링 엔터티를 선택합니다(루트 노드는 첫 번째로 선택되어야 하며 다른 후보가 없으므로 루트 노드는 그렇지 않습니다). 예약 엔터티가 필요합니다). 루트 노드 task_group에 해당하는 실행 큐는 특정 실행 큐 외에도 일부 전역 통계 정보 및 기타 필드를 포함하는 rq 구조로 패키지됩니다.
일정이 발생하면 스케줄러는 루트 task_group의 실행 대기열에서 일정 엔터티를 선택합니다. 이 스케줄링 엔터티가 task_group을 나타내는 경우 스케줄러는 이 그룹에 해당하는 실행 큐에서 스케줄링 엔터티를 계속 선택해야 합니다. 이 재귀는 프로세스가 선택될 때까지 계속됩니다. 루트 task_group의 실행 큐가 비어 있지 않으면 반복을 통해 프로세스를 확실히 찾을 수 있습니다. task_group에 해당하는 실행 큐가 비어 있으면 해당 스케줄링 엔터티가 상위 노드에 해당하는 실행 큐에 추가되지 않기 때문입니다.
마지막으로 task_group의 경우 해당 스케줄링 엔터티와 실행 큐는 CPU별로 공유되며, 스케줄링 엔터티(task_group에 해당)는 동일한 CPU에 해당하는 실행 큐에만 추가됩니다. 작업의 경우 스케줄링 엔터티의 복사본이 하나만 있습니다(CPU로 구분되지 않음). 스케줄러의 로드 밸런싱 기능은 다른 CPU에 해당하는 실행 대기열에서 스케줄링 엔터티(작업에 해당)를 이동할 수 있습니다.
그룹의 일정 계획 전략
그룹 스케줄링의 주요 데이터 구조가 명확해졌지만 여기에는 여전히 매우 중요한 문제가 있습니다. 작업에는 해당 우선순위(정적 우선순위 또는 동적 우선순위)가 있으며 스케줄러는 우선순위에 따라 실행 큐에서 프로세스를 선택한다는 것을 알고 있습니다. 그렇다면 task_group과 task는 모두 스케줄링 엔터티로 추상화되어 동일한 스케줄링을 허용하므로 task_group의 우선순위는 어떻게 정의해야 할까요? 이 질문은 구체적으로 스케줄링 범주(다른 스케줄링 범주에는 다른 우선순위 정의가 있음), 특히 rt(실시간 스케줄링) 및 cfs(완전히 공정한 스케줄링)에 의해 답변되어야 합니다.
실시간 프로세스의 그룹 예약
"Linux 프로세스 스케줄링에 대한 간략한 분석" 기사에서 볼 수 있듯이 실시간 프로세스는 CPU에 대한 실시간 요구 사항이 있는 프로세스이며 우선 순위는 특정 작업과 관련되어 있으며 사용자가 완전히 정의합니다. . 스케줄러는 항상 실행할 우선순위가 가장 높은 실시간 프로세스를 선택합니다.
그룹 스케줄링으로 발전한 그룹의 우선순위는 "그룹에서 가장 높은 우선순위 프로세스의 우선순위"로 정의됩니다. 예를 들어, 그룹에 우선순위가 10, 20, 30인 세 개의 프로세스가 있는 경우 그룹의 우선순위는 10입니다(값이 작을수록 우선순위가 높습니다).
그룹의 우선순위가 이렇게 정의되는데, 이는 흥미로운 현상으로 이어진다. 작업이 대기열에 추가되거나 대기열에서 제거되면 먼저 모든 상위 노드를 대기열에서 제거한 다음 아래에서 위로 다시 대기열에 넣어야 합니다. 그룹 노드의 우선순위는 하위 노드에 따라 달라지므로 작업을 대기열에 넣거나 대기열에서 빼면 각 상위 노드에 영향을 미칩니다.
그래서 스케줄러가 루트 노드의 task_group에서 스케줄링 엔터티를 선택하면 항상 올바른 경로를 따라 TASK_RUNNING 상태의 모든 실시간 프로세스 중에서 가장 높은 우선순위를 찾을 수 있습니다. 이러한 구현은 당연해 보이지만 잘 생각해 보면 실시간 프로세스를 이런 식으로 그룹화하는 것이 무슨 의미가 있을까요? 그룹화 여부에 관계없이 스케줄러가 해야 할 일은 "TASK_RUNNING 상태의 모든 실시간 프로세스 중 우선순위가 가장 높은 것을 선택"하는 것이다. 뭔가 빠진 것 같은데...
이제 Linux 시스템에 /proc/sys/kernel/sched_rt_기간_us 및 /proc/sys/kernel/sched_rt_runtime_us라는 두 개의 proc 파일을 도입해야 합니다. 이 두 파일은 sched_rt_ period_us를 기간으로 하는 기간 내에서 모든 실시간 프로세스의 실행 시간의 합이 sched_rt_runtime_us를 초과하지 않도록 규정하고 있습니다. 이 두 파일의 기본값은 1s와 0.95s이며, 이는 1초가 하나의 주기임을 의미하며, 이 주기에서 모든 실시간 프로세스의 총 실행 시간은 0.95초를 초과하지 않으며, 나머지는 최소 0.05초입니다. 초는 일반 프로세스용으로 예약됩니다. 즉, 실시간 프로세스가 CPU의 95% 이상을 차지하지 않습니다. 이 두 파일이 나타나기 전에는 실시간 프로세스의 실행 시간에 제한이 없었습니다. 항상 TASK_RUNNING 상태의 실시간 프로세스가 있었다면 일반 프로세스는 결코 실행될 수 없었습니다. sched_rt_runtime_us와 동등한 것은 sched_rt_ period_us와 같습니다.
sched_rt_runtime_us와 sched_rt_ period_us라는 변수가 두 개 있는 이유는 무엇인가요? CPU 사용률을 나타내는 변수를 직접 사용할 수는 없나요? 이는 많은 실시간 프로세스가 실제로 20ms마다 음성 패킷을 보내는 음성 프로그램, 40ms마다 프레임을 새로 고치는 비디오 프로그램 등과 같이 주기적으로 작업을 수행하기 때문이라고 생각합니다. 기간은 중요하며 매크로 CPU 점유율을 사용하는 것만으로는 실시간 프로세스 요구 사항을 정확하게 설명할 수 없습니다.
실시간 프로세스 그룹화는 sched_rt_runtime_us 및 sched_rt_기간_us의 개념을 확장합니다. 각 task_group에는 자체 sched_rt_runtime_us 및 sched_rt_기간_us가 있어 자체 그룹의 프로세스가 sched_rt_ period_us 기간 내에만 sched_rt_runtime_us를 실행할 수 있습니다. CPU 점유율은 sched_rt_runtime_us/sched_rt_기간_us입니다.
루트 노드의 task_group의 경우 해당 sched_rt_runtime_us 및 sched_rt_기간_us는 위 두 proc 파일의 값과 동일합니다. task_group 노드의 경우, TASK_RUNNING 상태에 n 개의 스케줄링 하위 그룹이 있고 m 개의 프로세스가 있고 CPU 점유율이 A이고 이 n 하위 그룹의 CPU 점유율이 B라고 가정하면 B는 A보다 작거나 같아야 합니다. , A-B의 남은 CPU 시간은 TASK_RUNNING 상태의 m개 프로세스에 할당됩니다. (여기서 논의하는 것은 CPU 점유율입니다. 각 스케줄링 그룹마다 주기 값이 다를 수 있기 때문입니다.)
sched_rt_runtime_us 및 sched_rt_ period_us의 논리를 구현하기 위해 커널이 프로세스의 실행 시간을 업데이트할 때(예: 주기적인 시계 인터럽트에 의해 트리거되는 시간 업데이트) 커널은 해당 런타임을 현재 프로세스의 스케줄링 엔터티에 추가합니다. 그리고 모든 조상 노드. 스케줄링 엔터티가 sched_rt_runtime_us에 의해 제한되는 시간에 도달하면 해당 실행 큐에서 제거되고 해당 rt_rq는 조절 상태로 설정됩니다. 이 상태에서는 이 rt_rq에 해당하는 스케줄링 엔터티가 다시 실행 큐에 들어가지 않습니다. 각 rt_rq는 sched_rt_period_us의 타이밍 주기로 주기적 타이머를 유지합니다. 타이머가 트리거될 때마다 해당 콜백 함수는 rt_rq의 런타임에서 sched_rt_period_us 단위 값을 뺀 다음(런타임을 0 이상으로 유지), 조절된 상태에서 rt_rq를 복원합니다.
또 다른 질문이 있습니다. 앞서 언급했듯이 기본적으로 시스템의 실시간 프로세스 실행 시간은 초당 0.95초를 초과하지 않습니다. 실시간 프로세스에 의한 실제 CPU 요구량이 0.95초 미만(0초 이상 0.95초 미만)인 경우 남은 시간은 일반 프로세스에 할당됩니다. 그리고 실시간 프로세스의 CPU 요구량이 0.95초보다 크면 0.95초 동안만 실행될 수 있으며 나머지 0.05초는 다른 일반 프로세스에 할당됩니다. 그런데 이 0.05초 동안 CPU를 사용할 필요가 있는 일반 프로세스가 없다면(TASK_RUNNING 상태가 없는 일반 프로세스) 어떻게 될까요? 이 경우 일반 프로세스는 CPU를 요구하지 않기 때문에 실시간 프로세스를 0.95초 이상 실행할 수 있을까? 할 수 없습니다. 나머지 0.05초 동안 커널은 실시간 프로세스가 CPU를 사용하도록 두기보다는 CPU를 유휴 상태로 유지합니다. sched_rt_runtime_us와 sched_rt_period_us는 매우 필수 항목임을 알 수 있습니다.
마지막으로 여러 CPU 문제가 있습니다. 앞서 언급했듯이 각 task_group에 대해 해당 스케줄링 엔터티와 실행 대기열이 CPU별로 유지됩니다. sched_rt_runtime_us와 sched_rt_ period_us는 스케줄링 엔터티에 작용하므로 시스템에 N개의 CPU가 있는 경우 실시간 프로세스가 차지하는 실제 CPU의 상한은 N*sched_rt_runtime_us/sched_rt_기간_us입니다. 즉, 기본 제한인 1초에도 불구하고 실시간 프로세스는 0.95초 동안만 실행될 수 있습니다. 그러나 실시간 프로세스의 경우 CPU에 코어가 2개 있으면 여전히 CPU의 100%를 점유하려는 요구(예: 무한 루프 실행)를 충족할 수 있습니다. 그러면 이 실시간 프로세스가 차지하는 CPU의 100%가 두 부분으로 구성되어야 하는 것이 합리적입니다(각 CPU는 부분을 차지하지만 95%를 초과할 수 없음). 그러나 실제로 CPU 간의 프로세스 마이그레이션으로 인해 발생하는 컨텍스트 전환 및 캐시 무효화와 같은 일련의 문제를 피하기 위해 한 CPU의 스케줄링 엔터티는 다른 CPU의 해당 스케줄링 엔터티에서 시간을 빌릴 수 있습니다. 그 결과 거시적으로 sched_rt_runtime_us의 제한 사항을 충족할 뿐만 아니라 프로세스 마이그레이션도 방지합니다.
일반 프로세스의 그룹 스케줄링
글 시작 부분에서 두 사용자 A와 B는 프로세스 수가 달라도 CPU 요구 사항을 균등하게 공유할 수 있다고 언급했습니다. 그러나 위의 실시간 프로세스에 대한 그룹 스케줄링 전략은 관련이 없는 것 같습니다. 실제로 이는 그룹 스케줄러가 수행해야 하는 작업입니다.
실시간 프로세스에 비해 일반 프로세스의 그룹 스케줄링은 그다지 특별하지 않습니다. 그룹은 프로세스와 거의 동일한 엔터티로 처리되며 고유한 정적 우선 순위를 가지며 스케줄러는 우선 순위를 동적으로 조정합니다. 그룹의 경우 그룹 내 프로세스의 우선순위는 그룹의 우선순위에 영향을 주지 않습니다. 이러한 프로세스의 우선순위는 스케줄러가 그룹을 선택한 경우에만 고려됩니다.
그룹의 우선순위를 설정하기 위해 각 task_group에는 share 매개변수가 있습니다(앞에서 언급한 sched_rt_runtime_us 및 sched_rt_기간_us 두 매개변수와 병행). 공유는 우선순위가 아니라 스케줄링 엔터티의 가중치입니다(이것이 CFS 스케줄러의 작동 방식입니다). 이 가중치와 우선순위는 일대일로 대응됩니다. 일반 프로세스의 우선순위는 해당 스케줄링 개체의 가중치로 변환되므로 공유가 우선순위를 나타낸다고 할 수 있습니다.
공유의 기본값은 일반 프로세스의 기본 우선순위에 해당하는 가중치와 동일합니다. 따라서 기본적으로 그룹과 프로세스는 CPU를 동일하게 공유합니다.
예
(환경: ubuntu 10.04, 커널 2.6.32, Intel Core2 듀얼 코어)
CPU 리소스만 나누는 cgroup을 마운트하고 두 개의 하위 그룹 grp_a 및 grp_b를 생성합니다.
으아아아각각 3개의 쉘을 열고 첫 번째 쉘에 grp_a를 추가하고 마지막 두 쉘에 grp_b를 추가합니다.
kouu@kouu-one:~/test/rtproc$ cat ttt.sh echo $1 > /dev/cgroup/cpu/$2/tasks
(为什么要用ttt.sh来写cgroup下的tasks文件呢?因为写这个文件需要root权限,当前shell没有root权限,而sudo只能赋予被它执行的程序的root权限。其实sudo sh,然后再在新开的shell里面执行echo操作也是可以的。) kouu@kouu-one:~/test1$ echo $$ 6740 kouu@kouu-one:~/test1$ sudo sh ttt.sh $$ grp_a kouu@kouu-one:~/test2$ echo $$ 9410 kouu@kouu-one:~/test2$ sudo sh ttt.sh $$ grp_b kouu@kouu-one:~/test3$ echo $$ 9425 kouu@kouu-one:~/test3$ sudo sh ttt.sh $$ grp_b
回到cgroup目录下,确认这几个shell都被加进去了:
kouu@kouu-one:/dev/cgroup/cpu$ cat grp_a/tasks 6740 kouu@kouu-one:/dev/cgroup/cpu$ cat grp_b/tasks 9410 9425
现在准备在这三个shell下同时执行一个死循环的程序(a.out),为了避免多CPU带来的影响,将进程绑定到第二个核上:
#define _GNU_SOURCE
\#include
int main()
{
cpu_set_t set;
CPU_ZERO(&set);
CPU_SET(1, &set);
sched_setaffinity(0, sizeof(cpu_set_t), &set);
while(1);
return 0;
}
编译生成a.out,然后在前面的三个shell中分别运行。三个shell分别会fork出一个子进程来执行a.out,这些子进程都会继承其父进程的cgroup分组信息。然后top一下,可以观察到属于grp_a的a.out占了50%的CPU,而属于grp_b的两个a.out各占25%的CPU(加起来也是50%):
kouu@kouu-one:/dev/cgroup/cpu$ top -c ...... PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 19854 kouu 20 0 1616 328 272 R 50 0.0 0:11.69 ./a.out 19857 kouu 20 0 1616 332 272 R 25 0.0 0:05.73 ./a.out 19860 kouu 20 0 1616 332 272 R 25 0.0 0:04.68 ./a.out ......
接下来再试试实时进程,把a.out程序改造如下:
#define _GNU_SOURCE
\#include
int main()
{
int prio = 50;
sched_setscheduler(0, SCHED_FIFO, (struct sched_param*)&prio);
while(1);
return 0;
}
然后设置grp_a的rt_runtime值:
kouu@kouu-one:/dev/cgroup/cpu$ sudo sh \# echo 300000 > grp_a/cpu.rt_runtime_us \# exit kouu@kouu-one:/dev/cgroup/cpu$ cat grp_a/cpu.rt_* 1000000 300000
现在的配置是每秒为一个周期,属于grp_a的实时进程每秒种只能执行300毫秒。运行a.out(设置实时进程需要root权限),然后top看看:
kouu@kouu-one:/dev/cgroup/cpu$ top -c ...... Cpu(s): 31.4%us, 0.7%sy, 0.0%ni, 68.0%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st ...... PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 28324 root -51 0 1620 332 272 R 60 0.0 0:06.49 ./a.out ......
可以看到,CPU虽然闲着,但是却不分给a.out程序使用。由于双核的原因,a.out实际的CPU占用是60%而不是30%。
其他
前段时间,有一篇“200+行Kernel补丁显著改善Linux桌面性能”的新闻比较火。这个内核补丁能让高负载条件下的桌面程序响应延迟得到大幅度降低。其实现原理是,自动创建基于TTY的task_group,所有进程都会被放置在它所关联的TTY组中。通过这样的自动分组,就将桌面程序(Xwindow会占用一个TTY)和其他终端或伪终端(各自占用一个TTY)划分开了。终端上运行的高负载程序(比如make -j64)对桌面程序的影响将大大减少。(根据前面描述的普通进程的组调度的实现可以知道,如果一个任务给系统带来了很高的负载,只会影响到与它同组的进程。这个任务包含一个或是一万个TASK_RUNNING状态的进程,对于其他组的进程来说是没有影响的。)
本文浅析了linux组调度的方法,包括组调度的原理、实现、配置和优缺点等方面。通过了解和掌握这些知识,我们可以深入理解Linux进程调度的高级知识,从而更好地使用和优化Linux系统。
위 내용은 리눅스 그룹 스케줄링에 대한 간략한 분석의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7484
7484
 15
1377
52
77
11
51
19
19
37
15
1377
52
77
11
51
19
19
37

 C 언어로 멀티 스레딩을 구현하는 4 가지 방법
Apr 03, 2025 pm 03:00 PM
C 언어로 멀티 스레딩을 구현하는 4 가지 방법
Apr 03, 2025 pm 03:00 PM
언어의 멀티 스레딩은 프로그램 효율성을 크게 향상시킬 수 있습니다. C 언어에서 멀티 스레딩을 구현하는 4 가지 주요 방법이 있습니다. 독립 프로세스 생성 : 여러 독립적으로 실행되는 프로세스 생성, 각 프로세스에는 자체 메모리 공간이 있습니다. 의사-다일리트 레딩 : 동일한 메모리 공간을 공유하고 교대로 실행하는 프로세스에서 여러 실행 스트림을 만듭니다. 멀티 스레드 라이브러리 : PTHREADS와 같은 멀티 스레드 라이브러리를 사용하여 스레드를 만들고 관리하여 풍부한 스레드 작동 기능을 제공합니다. COROUTINE : 작업을 작은 하위 작업으로 나누고 차례로 실행하는 가벼운 다중 스레드 구현.
 MySQL에 루트로 로그인 할 수 없습니다
Apr 08, 2025 pm 04:54 PM
MySQL에 루트로 로그인 할 수 없습니다
Apr 08, 2025 pm 04:54 PM
Root로 MySQL에 로그인 할 수없는 주된 이유는 권한 문제, 구성 파일 오류, 암호 일관성이 없음, 소켓 파일 문제 또는 방화벽 차단입니다. 솔루션에는 다음이 포함됩니다. 구성 파일의 BAND-ADDRESS 매개 변수가 올바르게 구성되어 있는지 확인하십시오. 루트 사용자 권한이 수정 또는 삭제되어 재설정되었는지 확인하십시오. 케이스 및 특수 문자를 포함하여 비밀번호가 정확한지 확인하십시오. 소켓 파일 권한 설정 및 경로를 확인하십시오. 방화벽이 MySQL 서버에 연결되는지 확인하십시오.
 libv는 두입니다
Apr 03, 2025 pm 08:03 PM
libv는 두입니다
Apr 03, 2025 pm 08:03 PM
Lua-Libuv라는 프로젝트를 개발했으며 내 경험을 공유하게되어 기쁩니다. 이 프로젝트의 원래 의도는 Libuv (C로 작성된 비동기 I/O 라이브러리)를 사용하여 C 언어를 심층적으로 배울 필요없이 간단한 HTTP 서버를 구축하는 방법을 탐색하는 것입니다. Chatgpt의 도움으로 Http.c의 기본 코드를 완료했습니다. 지속적인 연결을 다룰 때 적절한 시간에 연결을 닫고 리소스를 자유롭게하는 것을 성공적으로 구현했습니다. 처음에는 연결을 닫아 기본 프로그램을 종료 한 간단한 서버를 만들려고했지만 문제가있었습니다. 스트리밍을 사용하여 데이터 블록을 전송하려고 시도했지만 작동하는 동안 메인 스레드가 차단됩니다. 결국, 나는 내 목표가 C 언어를 깊이 배우는 것이 아니기 때문에이 접근법을 포기하기로 결정했습니다. 마지막으로, 나는
 C 언어 조건부 편집 : 초보자가 실제 응용 프로그램에 대한 자세한 안내서
Apr 04, 2025 am 10:48 AM
C 언어 조건부 편집 : 초보자가 실제 응용 프로그램에 대한 자세한 안내서
Apr 04, 2025 am 10:48 AM
C 언어 조건부 컴파일은 컴파일 시간 조건을 기반으로 코드 블록을 선택적으로 컴파일하는 메커니즘입니다. 입문 방법에는 다음이 포함됩니다. #IF 및 #ELSE 지시문을 사용하여 조건에 따라 코드 블록을 선택합니다. 일반적으로 사용되는 조건부 표현에는 STDC, _WIN32 및 LINUX가 포함됩니다. 실제 사례 : 운영 체제에 따라 다른 메시지를 인쇄합니다. 시스템의 숫자 수에 따라 다른 데이터 유형을 사용하십시오. 컴파일러에 따라 다른 헤더 파일이 지원됩니다. 조건부 컴파일은 코드의 휴대 성과 유연성을 향상시켜 컴파일러, 운영 체제 및 CPU 아키텍처 변경에 적응할 수 있도록합니다.
 【녹슬 셀프 스터디】 소개
Apr 04, 2025 am 08:03 AM
【녹슬 셀프 스터디】 소개
Apr 04, 2025 am 08:03 AM
1.0.1 서문이 프로젝트 (코드 및 댓글 포함)는 내 스스로 가르침 녹에서 기록되었습니다. 부정확하거나 불분명 한 진술이있을 수 있습니다. 사과하십시오. 당신이 그것으로부터 혜택을받는다면, 그것은 더 좋습니다. 1.0.2 Rustrust가 신뢰할 수 있고 효율적인 이유는 무엇입니까? Rust는 C 및 C를 유사한 성능으로 대체 할 수 있지만 보안이 높을 수 있으며 C 및 C와 같은 오류를 확인하기 위해 빈번한 재 컴파일이 필요하지 않습니다. 주요 장점에는 메모리 보안 (널 포인터가 해석, 매달려있는 포인터 및 데이터 경합 방지)이 포함됩니다. 스레드-안전 (실행하기 전에 다중 스레드 코드가 안전한지 확인하십시오). 정의되지 않은 동작을 피하십시오 (예 : 경계 밖으로 배열, 발기 국가화되지 않은 변수 또는 자유 메모리에 대한 액세스). Rust는 제네릭과 같은 현대 언어 기능을 제공합니다
 MySQL을 해결하는 방법을 시작할 수 없습니다
Apr 08, 2025 pm 02:21 PM
MySQL을 해결하는 방법을 시작할 수 없습니다
Apr 08, 2025 pm 02:21 PM
MySQL 시작이 실패하는 데는 여러 가지 이유가 있으며 오류 로그를 확인하여 진단 할 수 있습니다. 일반적인 원인에는 포트 충돌 (포트 점유 체크 및 구성 수정), 권한 문제 (서비스 실행 사용자 권한 실행), 구성 파일 오류 (파라미터 설정 확인), 데이터 디렉토리 손상 (데이터 복원 또는 테이블 공간 재건), IBDATA 테이블 공간 문제 (IBDATA1 파일 확인), 플러그로드 (확인 오류 로그)가 포함됩니다. 문제를 해결할 때 오류 로그를 기반으로 문제를 분석하고 문제의 근본 원인을 찾고 문제를 방지하고 해결하기 위해 정기적으로 데이터를 백업하는 습관을 개발해야합니다.
 C 언어 기능 라이브러리는 어디에 있습니까? C 언어 기능 라이브러리를 추가하는 방법?
Apr 03, 2025 pm 11:39 PM
C 언어 기능 라이브러리는 어디에 있습니까? C 언어 기능 라이브러리를 추가하는 방법?
Apr 03, 2025 pm 11:39 PM
C Language Function Library는 다양한 기능을 포함하는 도구 상자이며, 다른 라이브러리 파일로 구성됩니다. 라이브러리를 추가하려면 컴파일러의 명령 줄 옵션을 통해이를 지정해야합니다. 예를 들어 GCC 컴파일러는 -L 옵션을 사용한 다음 라이브러리 이름의 약어를 사용합니다. 라이브러리 파일이 기본 검색 경로에 있지 않은 경우 -L 옵션을 사용하여 라이브러리 파일 경로를 지정해야합니다. 라이브러리는 정적 라이브러리 및 동적 라이브러리로 나눌 수 있습니다. 정적 라이브러리는 컴파일 타임에 프로그램에 직접 연결되며 동적 라이브러리는 런타임에로드됩니다.
 Linux의 5 가지 기본 구성 요소는 무엇입니까?
Apr 06, 2025 am 12:05 AM
Linux의 5 가지 기본 구성 요소는 무엇입니까?
Apr 06, 2025 am 12:05 AM
Linux의 5 가지 기본 구성 요소는 다음과 같습니다. 1. 커널, 하드웨어 리소스 관리; 2. 기능과 서비스를 제공하는 시스템 라이브러리; 3. 쉘, 사용자가 시스템과 상호 작용할 수있는 인터페이스; 4. 파일 시스템, 데이터 저장 및 구성; 5. 시스템 리소스를 사용하여 기능을 구현합니다.
