
프로세스 스케줄링은 운영 체제의 핵심 기능 중 하나입니다. 어떤 프로세스가 CPU 실행 시간을 얻을 수 있는지, 얼마나 많은 시간을 얻을 수 있는지 결정합니다. Linux 시스템에는 많은 프로세스 스케줄링 알고리즘이 있는데, 가장 중요하고 일반적으로 사용되는 알고리즘은 Linux 버전 2.6.23부터 도입된 CFS(Completely Fair Scheduling Algorithm)입니다. CFS의 목표는 각 프로세스가 자체 가중치와 필요에 따라 CPU 시간을 합리적이고 공정하게 할당하여 시스템의 전체 성능과 응답 속도를 향상시키는 것입니다. 이 기사에서는 CFS의 기본 원리, 데이터 구조, 구현 세부 사항, 장점과 단점을 소개하고 Linux 프로세스 스케줄링의 완전한 공정성을 깊이 이해하는 데 도움이 됩니다.
Linux 스케줄러의 간략한 역사
초기 Linux 스케줄러는 하이퍼스레딩은 물론이고 프로세서가 많은 대규모 아키텍처에 분명히 초점을 맞추지 않은 미니멀리스트 디자인을 사용했습니다. 1.2 Linux 스케줄러는 실행 가능한 작업 관리를 위해 링 큐를 사용하고 라운드 로빈 스케줄링 전략을 사용합니다. 이 스케줄러는 프로세스를 매우 효율적으로 추가 및 제거합니다(구조를 보호하는 잠금 기능 사용). 간단히 말해서 스케줄러는 복잡하지 않고 간단하고 빠릅니다.
Linux 버전 2.2에서는 클래스 예약 개념을 도입하여 실시간 작업, 비선점형 작업, 비실시간 작업에 대한 예약 전략을 허용했습니다. 2.2 스케줄러에는 SMP(Symmetric MultiProcessing) 지원도 포함되어 있습니다.
2.4 커널에는 O(N) 간격으로 실행되는 비교적 간단한 스케줄러가 포함되어 있습니다(스케줄링 이벤트 동안 각 작업을 반복합니다). 2.4 스케줄러는 시간을 에포크(epoch)로 나눕니다. 각 작업은 해당 시간 조각이 소진될 때까지 실행됩니다. 작업이 해당 시간 조각을 모두 사용하지 않는 경우 나머지 시간 조각의 절반이 새 시간 조각에 추가되어 다음 에포크에서 더 오래 실행될 수 있습니다. 스케줄러는 단순히 작업을 반복하고 적합성 함수(메트릭)를 적용하여 다음에 실행할 작업을 결정합니다. 이 방법은 비교적 간단하지만 상대적으로 비효율적이고 확장성이 부족하여 실시간 시스템에 사용하기에는 적합하지 않습니다. 또한 멀티 코어 프로세서와 같은 새로운 하드웨어 아키텍처를 활용하는 능력도 부족합니다.
O(1) 스케줄러라고 불리는 초기 2.6 스케줄러는 2.4 스케줄러의 문제를 해결하기 위해 설계되었습니다. 스케줄러는 예약할 다음 작업을 결정하기 위해 전체 작업 목록을 반복할 필요가 없었습니다(따라서 이름은 O( 1) 즉, 더 효율적이고 확장 가능하다는 의미입니다. O(1) 스케줄러는 실행 대기열에서 실행 가능한 작업을 추적합니다(실제로 각 우선순위 수준에 대해 두 개의 실행 대기열이 있습니다. 하나는 활성 작업용이고 다른 하나는 만료된 작업용). 이는 다음 작업을 실행할 작업을 결정하는 것을 의미합니다. 스케줄러는 단순히 우선순위에 따라 특정 활동의 실행 대기열에서 다음 작업을 가져옵니다. O(1) 스케줄러는 확장성이 뛰어나고 상호 작용성을 포함하여 작업이 I/O 바인딩인지 프로세서 바인딩인지 결정하기 위한 풍부한 통찰력을 제공합니다. 그러나 O(1) 스케줄러는 커널에서 어색합니다. 컴퓨팅 계시에는 많은 코드가 필요하고 관리가 어렵고 순수주의자들은 알고리즘의 본질을 포착하지 못합니다.
O(1) 스케줄러가 직면한 문제를 해결하고 기타 외부 압력을 처리하려면 무언가를 변경해야 합니다. 이 변경 사항은 계단 스케줄러에 대한 그의 초기 작업을 통합한 RSDL(Rotating Staircase Deadline Scheduler)을 포함하는 Con Kolivas의 커널 패치에서 비롯되었습니다. 이 작업의 결과는 공정성과 제한된 대기 시간을 통합한 간단하게 설계된 스케줄러입니다. Kolivas의 스케줄러가 많은 관심을 끌고 있기 때문에(많은 사람들이 이를 현재 2.6.21 주류 커널에 포함시킬 것을 요구하고 있음) 스케줄러 변경이 다가오고 있다는 것은 분명합니다. O(1) 스케줄러의 창시자인 Ingo Molnar는 Kolivas의 아이디어 중 일부를 중심으로 CFS 기반 스케줄러를 개발했습니다. CFS를 분석하고 높은 수준에서 어떻게 작동하는지 살펴보겠습니다.
———————————————————————————————————————
CFS의 기본 아이디어는 작업에 프로세서 시간을 제공하는 측면에서 균형(공정성)을 유지하는 것입니다. 이는 프로세스에 상당한 수의 프로세서가 할당되어야 함을 의미합니다. 작업에 할당된 시간의 균형이 맞지 않는 경우(즉, 하나 이상의 작업에 다른 작업에 비해 상당한 시간이 주어지지 않음을 의미) 균형이 맞지 않는 작업에 실행 시간을 주어야 합니다.
균형을 유지하기 위해 CFS는 가상 런타임이라는 작업에 제공되는 시간을 유지합니다. 작업의 가상 런타임이 작을수록 작업이 서버에 액세스할 수 있는 시간이 짧아지고 프로세서에 대한 수요가 높아집니다. CFS에는 현재 실행되고 있지 않은 작업(예: I/O 대기)이 결국 필요할 때 프로세서를 공정하게 공유하도록 보장하는 절전 공정성 개념도 포함되어 있습니다.
그러나 실행 대기열에서 작업을 유지하지 않았던 이전 Linux 스케줄러와 달리 CFS는 시간 순서에 따른 레드-블랙 트리를 유지했습니다(그림 1 참조). 레드-블랙 트리는 흥미롭고 유용한 많은 특성을 가진 트리입니다. 첫째, 이는 자체 균형을 유지합니다. 즉, 트리의 어떤 경로도 다른 경로보다 두 배 이상 길지 않습니다. 둘째, 트리에서의 실행은 O(log n) 시간(여기서 n은 트리의 노드 수)에 발생합니다. 즉, 작업을 빠르고 효율적으로 삽입하거나 삭제할 수 있습니다.
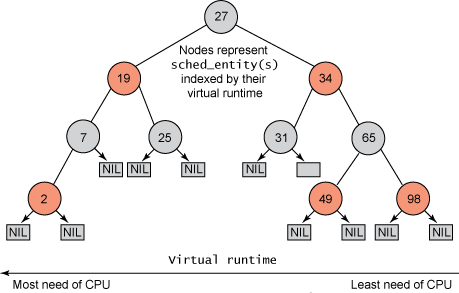
작업은 시간 순서로 정렬된 빨강-검정 트리(sched_entity 개체로 표시)에 저장되며, 프로세서를 가장 많이 요구하는 작업(가장 낮은 가상 런타임)은 트리 왼쪽에 저장되고, 프로세서를 가장 적게 요구하는 작업( 가장 높은 가상 런타임) 런타임)은 트리의 오른쪽에 저장됩니다. 공정성을 위해 스케줄러는 공정성을 유지하기 위해 다음에 예약할 레드-블랙 트리의 가장 왼쪽 노드를 선택합니다. 작업은 실행 시간을 가상 런타임에 추가한 다음 실행 가능한 경우 트리에 다시 삽입하여 CPU 시간을 설명합니다. 이렇게 하면 트리 왼쪽에 있는 작업에 실행할 시간이 주어지며, 트리의 내용은 오른쪽에서 왼쪽으로 이동되어 공정성이 유지됩니다. 따라서 실행 가능한 각 작업은 다른 작업을 따라잡아 전체 실행 가능한 작업 집합에서 실행 균형을 유지합니다.
———————————————————————————————————————
Linux 내의 모든 작업은 task_struct의 작업 구조 표현입니다. 이 구조(및 기타 관련 콘텐츠)는 작업을 완벽하게 설명하며 작업의 현재 상태, 해당 스택, 프로세스 ID, 우선 순위(정적 및 동적) 등을 포함합니다. ./linux/include/linux/sched.h에서 이러한 구조와 관련 구조를 찾을 수 있습니다. 그러나 모든 작업을 실행할 수 있는 것은 아니기 때문에 Menlo, monospace;color: #10f5d6c">task_struct에서는 CFS 관련 필드를 찾을 수 없습니다. 대신 일정 정보를 추적하기 위해 task_struct 的任务结构表示。该结构(以及其他相关内容)完整地描述了任务并包括了任务的当前状态、其堆栈、进程标识、优先级(静态和动态)等等。您可以在 ./linux/include/linux/sched.h 中找到这些内容以及相关结构。 但是因为不是所有任务都是可运行的,您在 task_struct 中不会发现任何与 CFS 相关的字段。 相反,会创建一个名为 sched_entity라는 새로운 구조가 생성됩니다(그림 2 참조).
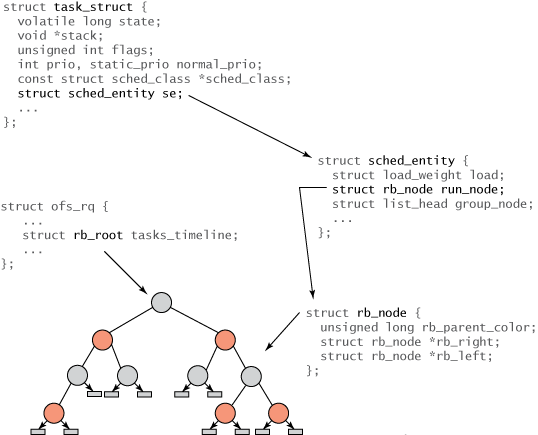
다양한 구조 간의 관계는 그림 2에 나와 있습니다. 트리의 루트는 rb_root 元素通过 cfs_rq 结构(在 ./kernel/sched.c 中)引用。红黑树的叶子不包含信息,但是内部节点代表一个或多个可运行的任务。红黑树的每个节点都由 rb_node 表示,它只包含子引用和父对象的颜色。 rb_node 包含在sched_entity 结构中,该结构包含 rb_node 引用、负载权重以及各种统计数据。最重要的是, sched_entity 包含 vruntime(64 位字段),它表示任务运行的时间量,并作为红黑树的索引。 最后,task_struct 位于顶端,它完整地描述任务并包含 sched_entity 구조를 통과합니다.
CFS 부분에 관한 한 스케줄링 기능은 매우 간단합니다. ./kernel/sched.c에서 일반적인 schedule() 函数,它会先抢占当前运行任务(除非它通过yield() 代码先抢占自己)。注意 CFS 没有真正的时间切片概念用于抢占,因为抢占时间是可变的。 当前运行任务(现在被抢占的任务)通过对 put_prev_task 调用(通过调度类)返回到红黑树。 当 schedule 函数开始确定下一个要调度的任务时,它会调用 pick_next_task函数。此函数也是通用的(在 ./kernel/sched.c 中),但它会通过调度器类调用 CFS 调度器。 CFS 中的 pick_next_task 函数可以在 ./kernel/sched_fair.c(称为 pick_next_task_fair())中找到。 此函数只是从红黑树中获取最左端的任务并返回相关 sched_entity。通过此引用,一个简单的 task_of() 调用确定返回的 task_struct 참조를 볼 수 있습니다. 범용 스케줄러는 최종적으로 이 작업을 위한 프로세서를 제공합니다.
———————————————————————————————————————
CFS는 우선 순위를 직접 사용하지 않지만 작업 실행이 허용되는 시간에 대한 감쇠 요소로 사용합니다. 우선순위가 낮은 작업은 붕괴 계수가 더 높고, 우선 순위가 높은 작업은 붕괴 계수가 낮습니다. 즉, 작업 실행에 허용되는 시간은 우선 순위가 높은 작업보다 우선 순위가 낮은 작업에 더 빨리 소모됩니다. 이는 우선순위에 따라 예약된 실행 큐를 유지하는 것을 방지하는 깔끔한 솔루션입니다.
CFS의 또 다른 흥미로운 측면은 그룹 스케줄링 개념(2.6.24 커널에서 도입됨)입니다. 그룹 예약은 특히 다른 많은 작업을 생성하는 작업을 처리할 때 일정을 공정하게 만드는 또 다른 방법입니다. 많은 작업을 생성하는 서버가 들어오는 연결을 병렬화하려고 한다고 가정합니다(HTTP 서버의 일반적인 아키텍처). 모든 작업이 균일하고 공정하게 처리되는 것은 아니며 CFS는 이러한 동작을 처리하기 위해 그룹을 도입합니다. 작업을 생성하는 서버 프로세스는 그룹 전체(계층 구조)에서 가상 런타임을 공유하는 반면, 개별 작업은 자체적으로 독립적인 가상 런타임을 유지합니다. 이런 방식으로 개별 작업은 그룹과 거의 동일한 일정 시간을 받습니다. /proc 인터페이스가 프로세스 계층 구조를 관리하는 데 사용되어 그룹이 형성되는 방식을 완벽하게 제어할 수 있다는 것을 알게 될 것입니다. 이 구성을 사용하면 사용자, 프로세스 또는 변형 전체에 공정성을 배포할 수 있습니다.
CFS와 함께 도입된 것은 수업 예약 개념입니다(그림 2를 기억하세요). 각 작업은 작업 예약 방법을 결정하는 예약 클래스에 속합니다. 스케줄링 클래스는 sched_class),函数集定义调度器的行为。例如,每个调度器提供一种方式, 添加要调度的任务、调出要运行的下一个任务、提供给调度器等等。每个调度器类都在一对一连接的列表中彼此相连,使类可以迭代(例如, 要启用给定处理器的禁用)。一般结构如图 3 所示。注意,将任务函数加入队列或脱离队列只需从特定调度结构中加入或移除任务。 函数 pick_next_task를 통해 실행될 다음 작업을 선택하는 일반적인 기능 세트를 정의합니다(스케줄링 클래스의 특정 전략에 따라 다름).

하지만 예약 클래스가 작업 구조 자체의 일부라는 점을 잊지 마세요(그림 2 참조). 이는 예약 클래스에 관계없이 작업 운영을 단순화합니다. 예를 들어, 다음 함수는 ./kernel/sched.c의 새 작업으로 현재 실행 중인 작업(curr 定义了当前运行任务, rq 代表 CFS 红黑树而 p이 예약될 다음 작업)을 선점합니다.
이 작업이 공정 일정 수업을 사용하는 경우 check_preempt_curr() 将解析为 check_preempt_wakeup(). ./kernel/sched_rt.c, ./kernel/sched_fair.c 및 ./kernel/sched_idle.c에서 이러한 관계를 볼 수 있습니다.
예약 클래스는 예약이 변경되는 또 다른 흥미로운 장소이지만 예약 도메인이 증가함에 따라 기능도 증가합니다. 이러한 도메인을 사용하면 부하 분산 및 격리 목적으로 하나 이상의 프로세서를 계층적으로 그룹화할 수 있습니다. 하나 이상의 프로세서가 스케줄링 정책을 공유하거나(및 프로세서 간의 로드 밸런싱을 유지) 독립적인 스케줄링 정책을 구현하여 의도적으로 작업을 격리할 수 있습니다.
스케줄링을 계속 연구하면 성능과 확장성의 한계를 뛰어넘는 개발 중인 스케줄러를 발견하게 될 것입니다. Con Kolivas는 자신의 Linux 경험에 굴하지 않고 BFS라는 또 다른 Linux 스케줄러를 개발했습니다. 스케줄러는 NUMA 시스템과 모바일 기기에서 더 나은 성능을 발휘한다고 하며 안드로이드 운영체제의 파생 버전에 도입됐다.
이 기사를 통해 CFS는 Linux 시스템에서 가장 진보되고 효율적인 프로세스 스케줄링 알고리즘 중 하나입니다. CFS는 실행 가능한 프로세스 대기열을 저장하고 가상 실행 시간을 계산합니다. 프로세스의 공정성 확보를 위해 Wake-up 선점 기능을 구현하여 Interactive 프로세스의 응답 속도를 향상시켜 프로세스 스케줄링의 완전한 공정성을 달성합니다. 물론 CFS는 완벽하지 않습니다. 활성 절전 프로세스에 대한 과도한 보상, 실시간 프로세스에 대한 지원 부족, 멀티 코어 프로세서의 활용도 부족 등 몇 가지 잠재적인 문제와 한계가 있습니다. 향후 버전을 개선하고 최적화하세요. 간단히 말해서, CFS는 Linux 시스템에서 없어서는 안 될 구성 요소이며 심층적인 연구와 숙달이 필요한 가치가 있습니다.
위 내용은 Linux CFS: 프로세스 스케줄링에서 완전한 공정성을 달성하는 방법의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



