

Underscore.js 1.3.3 중국어 주석 번역 지침_기본지식

// Underscore.js 1.3.3
// (c) 2009-2012 Jeremy Ashkenas, DocumentCloud Inc.
// Underscore는 MIT 라이센스에 따라 무료로 배포 가능합니다.
// Underscore의 일부는 Prototype에서 영감을 받거나 차용되었습니다.
// Oliver Steele의 Functional 및 John Resig의 Micro-Templating.
// 모든 세부 사항 및 문서는 다음을 참조하세요.
// http://documentcloud.github.com/underscore
(기능() {
// 브라우저에서는 창 객체로 표시되고 Node.js에서는 전역 객체로 표시되는 전역 객체를 생성합니다.
var 루트 = 이것;
//"_"(밑줄 변수)를 덮어쓰기 전의 값을 저장합니다.
// 이름 충돌이 있거나 사양을 고려하는 경우 _.noConstrict() 메서드를 사용하여 Underscore가 차지하기 전의 "_" 값을 복원하고 이름 변경을 위해 Underscore 개체를 반환할 수 있습니다.
var 이전Underscore = 루트._;
//내부 공유 및 사용을 위해 빈 객체 상수를 생성합니다.
var 차단기 = {};
//빠른 호출을 용이하게 하기 위해 내장 객체의 프로토타입 체인을 로컬 변수에 캐시합니다.
var ArrayProto = Array.prototype, //
ObjProto = Object.prototype, //
FuncProto = 함수.프로토타입;
//빠른 호출을 위해 지역 변수에 내장된 객체 프로토타입의 공통 메서드를 캐시합니다.
var 슬라이스 = ArrayProto.slice, //
unshift = ArrayProto.unshift, //
toString = ObjProto.toString, //
hasOwnProperty = ObjProto.hasOwnProperty;
// 이는 JavaScript 1.6에서 제공되는 몇 가지 새로운 메소드를 정의합니다.
// 호스트 환경이 이러한 메소드를 지원하는 경우 먼저 호출됩니다. 호스트 환경에서 이를 제공하지 않는 경우 Underscore에 의해 구현됩니다.
var NativeForEach = ArrayProto.forEach, //
NativeMap = ArrayProto.map, //
NativeReduce = ArrayProto.reduce, //
NativeReduceRight = ArrayProto.reduceRight, //
NativeFilter = ArrayProto.filter, //
NativeEvery = ArrayProto.every, //
NativeSome = ArrayProto.some, //
NativeIndexOf = ArrayProto.indexOf, //
NativeLastIndexOf = ArrayProto.lastIndexOf, //
NativeIsArray = Array.isArray, //
NativeKeys = Object.keys, //
NativeBind = FuncProto.bind;
// Underscore 래퍼를 반환하는 개체 스타일 호출 메서드를 만듭니다. 래퍼 개체의 프로토타입에는 Underscore의 모든 메서드가 포함되어 있습니다(DOM 개체를 jQuery 개체로 래핑하는 것과 유사).
var _ = 함수(obj) {
// 모든 Underscore 객체는 래퍼 객체를 통해 내부적으로 생성됩니다.
새로운 래퍼(obj)를 반환합니다.
};
// 다른 호스트 환경의 경우 Undersocre의 명명된 변수를 다른 개체에 저장합니다.
if( typeof imports !== 'undefine') {// Node.js 환경
if( 모듈 유형 !== '정의되지 않음' && module.exports) {
내보내기 = module.exports = _;
}
수출._ = _;
} else {//브라우저 환경에서 Underscore라는 이름의 변수가 window 객체에 걸려 있습니다.
루트['_'] = _;
}
// 버전 설명
_.VERSION = '1.3.3';
// 컬렉션 관련 메서드(데이터 및 객체에 대한 일반적인 처리 방법)
//-------
// 프로세서를 반복하고 컬렉션의 각 요소에 대해 프로세서 메서드를 실행합니다.
var 각각 = _.each = _.forEach = function(obj, iterator, context) {
//null 값을 처리하지 않음
if(obj == null)
반품;
if(nativeForEach && obj.forEach === NativeForEach) {
// 호스트 환경에서 지원하는 경우 JavaScript 1.6에서 제공하는 forEach 메서드가 먼저 호출됩니다.
obj.forEach(반복자, 컨텍스트);
} else if(obj.length === obj.length) {
//<array>의 각 요소에 대해 프로세서 메서드를 실행합니다.
for(var i = 0, l = obj.length; i < l; i ) {
if( i in obj && iterator.call(context, obj[i], i, obj) === 차단기)
반품;
}
} 또 다른 {
// <object>의 각 요소에 대해 프로세서 메서드를 실행합니다.
for(obj의 var 키) {
if(_.has(obj, key)) {
if(iterator.call(context, obj[key], key, obj) === 차단기)
반품;
}
}
}
};
// 반복 프로세서, 각 메소드와의 차이점은 맵이 각 반복의 반환 값을 저장하고 새 배열로 반환한다는 것입니다.
_.map = _.collect = function(obj, iterator, context) {
//반환값을 저장하는 데 사용되는 배열
var 결과 = [];
if(obj == null)
결과를 반환합니다.
// 호스트 환경에서 제공하는 맵 메소드 호출 우선순위를 지정합니다.
if(nativeMap && obj.map === 기본 맵)
return obj.map(반복자, 컨텍스트);
// 컬렉션의 요소를 반복합니다.
각각(obj, 함수(값, 인덱스, 목록)) {
// 각 반복의 반환 값을 결과 배열에 저장합니다.
results[results.length] = iterator.call(컨텍스트, 값, 인덱스, 목록);
});
//처리 결과를 반환합니다.
if(obj.길이 === obj.길이)
결과.길이 = obj.길이;
결과를 반환합니다.
};
// 컬렉션의 각 요소를 반복 프로세서에 넣고 이 반복의 반환 값을 "메모"로 다음 반복에 전달합니다. 일반적으로 결과를 누적하거나 데이터를 연결하는 데 사용됩니다.
_.reduce = _.foldl = _.inject = function(obj, iterator, 메모, 컨텍스트) {
// 매개변수 개수만큼 초기값이 있는지 확인
var 초기 = 인수.길이 >
if(obj == null)
obj = [];
// 호스트 환경에서 제공하는 축소 메소드 호출 우선순위를 지정합니다.
if(nativeReduce && obj.reduce === NativeReduce && false) {
if(컨텍스트)
iterator = _.bind(반복자, 컨텍스트);
초기 반환 ? obj.reduce(iterator, memo) : obj.reduce(iterator);
}
// 컬렉션의 요소를 반복합니다.
각각(obj, 함수(값, 인덱스, 목록)) {
if(!initial) {
// 초기값이 없으면 첫 번째 요소가 초기값으로 사용되며, 객체 컬렉션이 처리되면 기본값은 첫 번째 속성의 값입니다.
메모 = 값;
초기 = 사실;
} 또 다른 {
// 처리 결과를 기록하고 결과를 다음 반복으로 전달합니다.
memo = iterator.call(컨텍스트, 메모, 값, 인덱스, 목록);
}
});
if(!초기)
throw new TypeError('초기값이 없는 빈 배열 감소');
메모 반환;
};
// 감소와 유사하게 컬렉션의 요소를 반대 방향으로 반복합니다(즉, 마지막 요소에서 시작하여 첫 번째 요소까지).
_.reduceRight = _.foldr = function(obj, iterator, 메모, 컨텍스트) {
var 초기 = 인수.길이 >
if(obj == null)
obj = [];
// 호스트 환경에서 제공하는 ReduceRight 메소드 호출 우선순위를 지정합니다.
if(nativeReduceRight && obj.reduceRight === NativeReduceRight) {
if(컨텍스트)
iterator = _.bind(반복자, 컨텍스트);
초기 반환 ? obj.reduceRight(iterator, memo) : obj.reduceRight(iterator);
}
//컬렉션의 요소 순서를 반대로 바꿉니다.
var reversed = _.toArray(obj).reverse();
if(컨텍스트 && !초기)
iterator = _.bind(반복자, 컨텍스트);
//리듀스 메소드를 통해 데이터 처리
return 초기 ? _.reduce(reversed, iterator, memo, context) : _.reduce(reversed, iterator);
};
// 컬렉션의 요소를 순회하고 프로세서 확인을 통과할 수 있는 첫 번째 요소를 반환합니다.
_.find = _.Detect = function(obj, iterator, context) {
// 결과는 검증을 통과할 수 있는 첫 번째 요소를 저장합니다.
var 결과;
// any 메소드를 통해 데이터를 탐색하고 검증을 통과한 요소를 기록합니다.
// (iteration 중 프로세서 반환 상태를 확인하는 경우 여기서는 각각의 메소드를 사용하는 것이 더 적절할 것입니다)
모든(obj, 함수(값, 인덱스, 목록)) {
// 프로세서가 반환한 결과를 Boolean 타입으로 변환하여 값이 true이면 현재 요소를 기록하여 반환한다.
if(iterator.call(context, value, index, list)) {
결과 = 값;
사실을 반환;
}
});
결과 반환;
};
// find 메소드와 비슷하지만 filter 메소드는 컬렉션의 확인된 모든 요소를 기록합니다.
_.filter = _.select = function(obj, iterator, context) {
// 유효성 검사를 통과한 요소의 배열을 저장하는 데 사용됩니다.
var 결과 = [];
if(obj == null)
결과를 반환합니다.
// 호스트 환경에서 제공하는 필터 메소드를 우선적으로 호출합니다.
if(nativeFilter && obj.filter === NativeFilter)
return obj.filter(반복자, 컨텍스트);
// 컬렉션의 요소를 반복하고 프로세서에서 확인한 요소를 배열에 넣고 반환합니다.
각각(obj, 함수(값, 인덱스, 목록)) {
if(iterator.call(컨텍스트, 값, 인덱스, 목록))
결과[결과.길이] = 값;
});
결과를 반환합니다.
};
// 필터 메소드의 반대 효과, 즉 프로세서 검증을 통과하지 못한 요소 목록을 반환합니다.
_.reject = function(obj, iterator, context) {
var 결과 = [];
if(obj == null)
결과를 반환합니다.
각각(obj, 함수(값, 인덱스, 목록)) {
if(!iterator.call(컨텍스트, 값, 인덱스, 목록))
결과[결과.길이] = 값;
});
결과를 반환합니다.
};
//컬렉션의 모든 요소가 프로세서 확인을 통과할 수 있으면 true를 반환합니다.
_.every = _.all = function(obj, iterator, context) {
var 결과 = true;
if(obj == null)
결과 반환;
// 호스트 환경에서 제공하는 모든 메소드를 우선적으로 호출합니다.
if(nativeEvery && obj.every === NativeEvery)
return obj.every(반복자, 컨텍스트);
//컬렉션의 요소를 반복합니다.
각각(obj, 함수(값, 인덱스, 목록)) {
// 이는 result = (result && iterator.call(context, value, index, list))로 이해됩니다.
// 프로세서의 결과가 Boolean 타입으로 변환된 후 참값인지 확인
if(!( 결과 = 결과 && iterator.call(컨텍스트, 값, 인덱스, 목록)))
복귀 차단기;
});
반환 !!결과;
};
// 컬렉션의 요소가 부울 유형으로 변환될 때 참값을 갖는지 확인합니까? 아니면 프로세서에서 처리된 후에 참값을 갖는지 확인합니까?
var any = _.some = _.any = function(obj, iterator, context) {
// 프로세서 매개변수가 지정되지 않은 경우 기본 프로세서 함수는 요소 자체를 반환하고 반복 중에 요소를 부울 유형으로 변환하여 참값인지 확인합니다.
반복자 || ( 반복자 = _.identity);
var 결과 = 거짓;
if(obj == null)
결과 반환;
// 호스트 환경에서 제공하는 일부 메소드 호출에 우선순위를 부여합니다.
if(nativeSome && obj.some === NativeSome)
return obj.some(반복자, 컨텍스트);
//컬렉션의 요소를 반복합니다.
각각(obj, 함수(값, 인덱스, 목록)) {
if(결과 || ( 결과 = iterator.call(컨텍스트, 값, 인덱스, 목록)))
복귀 차단기;
});
반환 !!결과;
};
// 컬렉션에 대상 매개변수와 정확히 일치하는 값이 있는지 확인합니다. (데이터 유형도 일치합니다.)
_.include = _.contains = function(obj, 대상) {
var 발견 = false;
if(obj == null)
반품을 찾았습니다.
// 호스트 환경에서 제공하는 Array.prototype.indexOf 메서드 호출 우선순위를 지정합니다.
if(nativeIndexOf && obj.indexOf === NativeIndexOf)
return obj.indexOf(target) != -1;
// any 메소드를 통해 컬렉션의 요소를 반복하고 요소의 값과 유형이 대상과 완전히 일치하는지 확인합니다.
발견 = 모든(obj, 함수(값)) {
반환 값 === 대상;
});
반품을 찾았습니다.
};
// 요소의 호출 메서드에 전달될 세 번째 매개변수부터 시작하여 컬렉션에 있는 모든 요소의 동일한 이름의 메서드를 순서대로 호출합니다.
// 모든 메소드의 처리 결과를 저장하는 배열을 반환
_.invoke = 함수(obj, 메서드) {
// 같은 이름의 메소드 호출 시 전달되는 매개변수 (3번째 매개변수부터 시작)
var args = Slice.call(인수, 2);
// 각 요소의 메소드를 차례로 호출하고 그 결과를 배열에 담아 반환한다.
return _.map(obj, function(value) {
return (_.isFunction(method) ? method || value : value[method]).apply(value, args);
});
};
// 객체 목록으로 구성된 배열을 탐색하고 각 객체의 지정된 속성에 대한 값 목록을 반환합니다.
_.pluck = function(obj, 키) {
// 객체에 속성이 존재하지 않는 경우, 정의되지 않음을 반환합니다.
return _.map(obj, function(value) {
반환값[키];
});
};
//컬렉션의 최대값을 반환하고, 비교할 수 있는 값이 없으면 정의되지 않은 값을 반환합니다.
_.max = 함수(obj, 반복자, 컨텍스트) {
// 컬렉션이 배열이고 프로세서가 사용되지 않는 경우 Math.max를 사용하여 최대값을 얻습니다.
// 일반적으로 일련의 숫자형 데이터가 배열로 저장됩니다.
if(!iterator && _.isArray(obj) && obj[0] === obj[0])
return Math.max.apply(Math, obj);
// null 값의 경우 음의 무한대를 직접 반환합니다.
if(!iterator && _.isEmpty(obj))
반환 -무한대;
// 임시 개체, 계산은 비교 프로세스 중 최대값을 저장하는 데 사용됩니다(임시).
변수 결과 = {
계산 : -무한대
};
//컬렉션의 요소를 반복합니다.
각각(obj, 함수(값, 인덱스, 목록)) {
// 프로세서 매개변수가 지정된 경우 비교 데이터는 프로세서가 반환한 값이고, 그렇지 않으면 각 순회 중 기본값이 직접 사용됩니다.
var 계산 = 반복자 ? iterator.call(컨텍스트, 값, 인덱스, 목록) : 값;
// 비교 값이 이전 값보다 크면 현재 값을 result.value에 넣습니다.
계산됨 >= 결과.계산됨 && ( 결과 = {
가치: 가치,
계산하다 : 계산하다
});
});
// 최대값을 반환합니다.
결과.값을 반환합니다.
};
//세트의 최소값을 반환합니다. 처리 프로세스는 max 메소드와 일치합니다.
_.min = 함수(obj, 반복자, 컨텍스트) {
if(!iterator && _.isArray(obj) && obj[0] === obj[0])
return Math.min.apply(Math, obj);
if(!iterator && _.isEmpty(obj))
무한대를 반환합니다.
변수 결과 = {
계산됨: 무한대
};
각각(obj, 함수(값, 인덱스, 목록)) {
var 계산 = 반복자 ? iterator.call(컨텍스트, 값, 인덱스, 목록) : 값;
계산된 < 결과.계산된 && ( 결과 = {
가치: 가치,
계산하다 : 계산하다
});
});
결과.값을 반환합니다.
};
// 배열을 정렬할 필요가 없도록 난수를 사용합니다.
_.shuffle = 함수(obj) {
// 섞인 변수는 처리 과정과 최종 결과 데이터를 저장합니다.
var shuffled = [], rand;
//컬렉션의 요소를 반복합니다.
각각(obj, 함수(값, 인덱스, 목록)) {
// 난수를 생성합니다. 난수는 <0-현재 처리된 숫자>
rand = Math.floor(Math.random() * (색인 1));
// 섞인 배열의 끝에 무작위로 얻은 요소를 넣습니다.
섞인[인덱스] = 섞인[랜드];
//이전에 얻은 난수 위치에 가장 최근의 값을 삽입
shuffled[rand] = 값;
});
// 무작위로 섞인 컬렉션 요소를 저장하는 배열을 반환합니다.
섞여서 돌아옴;
};
// 특정 필드나 값에 따라 컬렉션의 요소를 정렬합니다.
// Array.prototype.sort 메소드와 비교하여 sortBy 메소드는 객체 정렬을 지원합니다.
_.sortBy = function(obj, val, context) {
// val은 객체의 속성이거나 프로세서 함수여야 합니다. 프로세서인 경우 비교해야 하는 데이터를 반환해야 합니다.
var iterator = _.isFunction(val) ? val : function(obj) {
반환 객체[발];
};
// 호출 순서: _.pluck(_.map().sort());
// _.map() 메서드를 호출하여 컬렉션을 순회하고 컬렉션의 요소를 값 노드에 넣고 요소에서 비교해야 하는 데이터를 기준 속성에 넣습니다.
//criteria 속성의 데이터에 따라 컬렉션의 요소를 정렬하려면 sort() 메서드를 호출합니다.
// pluck을 호출하여 정렬된 객체 컬렉션을 얻고 반환합니다.
return _.pluck(_.map(obj, function(value, index, list)) {
반품 {
가치: 가치,
기준: iterator.call(컨텍스트, 값, 인덱스, 목록)
};
}).sort(함수(왼쪽, 오른쪽) {
var a = 왼쪽.기준, b = 오른쪽.기준;
만약(a ===
무효 0)
1을 반환합니다.
만약(b ===
무효 0)
-1을 반환합니다.
a <b ? -1:a >b ?
}), '값');
};
// 프로세서가 반환한 키에 따라 컬렉션의 요소를 여러 배열로 나눕니다.
_.groupBy = 함수(obj, val) {
var 결과 = {};
// val은 그룹화를 위해 프로세서 함수로 변환됩니다. val이 Function 유형 데이터가 아닌 경우 요소 필터링 시 키 값으로 사용됩니다.
var iterator = _.isFunction(val) ? val : function(obj) {
반환 객체[발];
};
//컬렉션의 요소를 반복합니다.
각각(obj, 함수(값, 인덱스)) {
// 프로세서의 반환 값을 키로 사용하고 동일한 키 요소를 새 배열에 넣습니다.
var key = iterator(값, 인덱스);
(결과[키] || (결과[키] = [])).push(값);
});
// 그룹화된 데이터를 반환합니다.
결과 반환;
};
_.sortedIndex = function(array, obj, iterator) {
반복자 || ( 반복자 = _.identity);
var low = 0, high = array.length;
while(낮음 < 높음) {
var mid = (낮음 높음) >> 1;
iterator(array[mid]) < iterator(obj) ? low = mid 1 : high = mid;
}
낮게 반환;
};
//컬렉션을 배열로 변환하고 반환
// 일반적으로 인수를 배열로 변환하거나, 정렬되지 않은 객체 컬렉션을 데이터 형태의 정렬된 컬렉션으로 변환하는 데 사용됩니다.
_.toArray = 함수(obj) {
만약(!obj)
반품 [];
if(_.isArray(obj))
return Slice.call(obj);
//인수를 배열로 변환
if(_.isArguments(obj))
return Slice.call(obj);
if(obj.toArray && _.isFunction(obj.toArray))
return obj.toArray();
//객체를 객체의 모든 속성(객체 프로토타입 체인의 속성 제외)의 값 목록이 포함된 배열로 변환합니다.
_.values(obj)를 반환합니다.
};
// 컬렉션의 요소 수를 계산합니다.
_.size = 함수(obj) {
// 컬렉션이 배열이면 배열 요소의 개수를 셉니다.
// 컬렉션이 객체인 경우 객체의 속성 수를 계산합니다(객체의 프로토타입 체인에 있는 속성 제외).
_.isArray(obj) ? obj.length : _.keys(obj).length;
};
// 배열 관련 메소드
// ---------------
// 지정된 배열의 첫 번째 또는 n 요소를 순서대로 반환합니다.
_.first = _.head = _.take = function(array, n, Guard) {
// 매개변수 n이 지정되지 않은 경우 첫 번째 요소를 반환합니다.
// n이 지정되면 지정된 수의 n 요소를 순서대로 포함하는 새 배열을 반환합니다.
//guard 매개변수는 첫 번째 요소만 반환되는지 확인하는 데 사용됩니다. Guard가 true인 경우 지정된 숫자 n은 유효하지 않습니다.
return (n != null) && !guard ? Slice.call(array, 0, n) : array[0];
};
//첫 번째 요소를 제외한 다른 요소를 포함하거나 마지막 요소부터 앞으로 지정된 n 요소를 제외하는 새 배열을 반환합니다.
// 첫 번째 방법과의 차이점은 배열 이전에 필요한 요소의 위치를 먼저 결정하고, 초기화는 배열 끝에서 제외된 요소의 위치를 결정한다는 점입니다.
_.initial = 함수(배열, n, 가드) {
// 매개변수 n이 전달되지 않으면 마지막 요소를 제외한 다른 요소가 기본적으로 반환됩니다.
// 매개변수 n이 전달되면 마지막 요소부터 n개 요소를 제외한 다른 요소가 반환됩니다.
// Guard는 하나의 요소만 반환되도록 하는 데 사용됩니다. Guard가 true인 경우 지정된 숫자 n은 유효하지 않습니다.
return Slice.call(array, 0, array.length - ((n == null) || Guard ? 1 : n));
};
//배열의 마지막 n개 요소 또는 지정된 n개 요소를 역순으로 반환합니다.
_.last = 함수(배열, n, 가드) {
if((n != null) && !guard) {
// 구한 요소 위치 n을 배열 끝까지 계산하여 지정하고, 새로운 배열로 반환
return Slice.call(array, Math.max(array.length - n, 0));
} 또 다른 {
// 숫자가 지정되지 않거나 Guard가 true인 경우 마지막 요소만 반환됩니다.
반환 배열[array.length - 1];
}
};
// 첫 번째 또는 지정된 처음 n개 요소를 제외한 다른 요소를 가져옵니다.
_.rest = _.tail = function(배열, 인덱스, 가드) {
// 배열의 끝까지 슬라이스의 두 번째 위치 매개변수를 계산합니다.
// 인덱스가 지정되지 않거나 가드 값이 true인 경우 첫 번째 요소를 제외한 다른 요소를 반환합니다.
// (index == null) 값이 true일 경우, 슬라이스 함수에 전달된 매개변수는 자동으로 1로 변환됩니다.
return Slice.call(array, (index == null) || Guard ? 1 : index);
};
// 값이 true로 변환될 수 있는 배열의 모든 요소를 반환하고 새 배열을 반환합니다.
// 변환할 수 없는 값에는 false, 0, '', null, undefine, NaN 등이 있으며, 이러한 값은 false로 변환됩니다.
_.compact = 함수(배열) {
return _.filter(배열, 함수(값) {
반환!!값;
});
};
// 다차원 숫자를 1차원 배열로 결합하여 심층 병합을 지원합니다.
//shallow 매개변수는 병합 깊이를 제어하는 데 사용됩니다.shallow가 true인 경우 첫 번째 레이어만 병합되며 기본적으로 깊은 병합이 수행됩니다.
_.Flatten = 함수(배열, 얕은) {
// 배열의 각 요소를 반복하고 반환 값을 데모로 다음 반복에 전달합니다.
return _.reduce(array, function(memo, value) {
// 요소가 여전히 배열인 경우 다음과 같이 판단합니다.
// - Deep Merge가 수행되지 않는 경우 Array.prototype.concat을 사용하여 현재 배열과 이전 데이터를 연결합니다.
// - 깊은 병합이 지원되는 경우 기본 요소가 더 이상 배열 유형이 아닐 때까지 flatten 메서드가 반복적으로 호출됩니다.
if(_.isArray(값))
return memo.concat(shallow ? value : _.Flatten(value));
// 데이터(값)가 이미 맨 아래에 있어서 더 이상 배열 형태가 아닌 경우, 해당 데이터를 메모에 병합하고 반환합니다.
메모[memo.length] = 값;
메모 반환;
}, []);
};
// 현재 배열에서 지정된 데이터와 동일하지 않은 차이 데이터를 필터링하여 반환합니다. (차이 방법 설명 참조)
_.without = 함수(배열) {
return _.difference(array, Slice.call(arguments, 1));
};
// 배열의 데이터 중복 제거(비교를 위해 === 사용)
// isSorted 매개변수가 false가 아닌 경우 배열의 요소에 대해 순차적으로 include 메소드를 호출하여 반환 값(배열)에 동일한 요소가 추가되었는지 확인합니다.
// 호출하기 전에 배열의 데이터가 순서대로 정렬되었는지 확인하면 isSorted를 true로 설정할 수 있습니다. isSorted를 사용하면 마지막 요소와 비교하여 동일한 값이 제외됩니다. .
// uniq 메소드는 기본적으로 배열의 데이터를 비교합니다. 반복기 프로세서가 선언된 경우 비교 배열은 프로세서를 기반으로 생성되지만 비교 중에 배열의 데이터만 반환됩니다. end는 여전히 원래 배열입니다.
_.uniq = _.unique = function(array, isSorted, iterator) {
// 반복자 프로세서를 사용하는 경우 현재 배열의 데이터가 반복자에 의해 먼저 처리되고 처리된 새 배열이 반환됩니다.
// 새 배열은 비교의 기초로 사용됩니다.
var 초기 = 반복자 ? _.map(array, iterator) : 배열;
// 처리 결과를 기록하는 데 사용되는 임시 배열
var 결과 = [];
// 배열에 값이 2개만 있는 경우 비교를 위해 include 메서드를 사용할 필요가 없습니다. isSorted를 true로 설정하면 작업 효율성이 향상됩니다.
if(array.length < 3)
isSorted = 사실;
// 처리 결과를 반복하고 누적하기 위해 축소 메소드를 사용합니다.
//초기 변수는 비교해야 하는 기준 데이터입니다. 원본 배열이거나 프로세서의 결과 집합일 수 있습니다(반복자가 설정된 경우).
_.reduce(초기, 함수(메모, 값, 인덱스) {
// isSorted 매개변수가 true인 경우 ===를 직접 사용하여 레코드의 마지막 데이터를 비교합니다.
// isSorted 매개변수가 false인 경우, include 메소드를 사용하여 컬렉션의 각 데이터와 비교합니다.
if( isSorted ? _.last(memo) !== value || !memo.length : !_.include(memo, value)) {
//메모는 비교된 중복되지 않은 데이터를 기록합니다.
// iterator 매개변수의 상태에 따라 메모에 기록되는 데이터는 원본 데이터일 수도 있고, 프로세서에서 처리된 데이터일 수도 있음
memo.push(값);
// 처리 결과 배열에 저장된 데이터는 항상 원래 배열의 데이터입니다.
results.push(배열[색인]);
}
메모 반환;
}, []);
//배열에 중복되지 않은 데이터만 포함된 처리 결과를 반환합니다.
결과를 반환합니다.
};
// Union 메소드는 uniq 메소드와 동일한 효과를 갖습니다. 차이점은 Union을 사용하면 여러 배열을 매개변수로 전달할 수 있다는 점입니다.
_.union = 함수() {
// Union은 매개변수의 여러 배열을 배열 객체로 얕게 병합하고 처리를 위해 uniq 메서드에 전달합니다.
return _.uniq(_.platten(arguments, true));
};
// 현재 배열과 하나 이상의 다른 배열의 교차 요소를 가져옵니다.
//두 번째 매개변수부터 시작하여 비교해야 하는 하나 이상의 배열입니다.
_.intersection = _.intersect = 함수(배열) {
// 나머지 변수는 비교해야 하는 다른 배열 객체를 기록합니다.
var 나머지 = Slice.call(인수, 1);
// 반복 계산을 피하기 위해 uniq 메소드를 사용하여 현재 배열에서 중복 데이터를 제거합니다.
// 프로세서를 통해 현재 배열의 데이터를 필터링하고 조건에 맞는 데이터를 반환합니다(동일 요소 비교).
return _.filter(_.uniq(array), function(item) {
// Every 메소드를 사용하여 각 배열에 비교해야 하는 데이터가 포함되어 있는지 확인합니다.
// 모든 배열에 비교 데이터가 포함되어 있으면 모두 true를 반환하고, 배열에 해당 요소가 없으면 false를 반환합니다.
return _.every(rest, function(other) {
// 다른 매개변수는 비교해야 하는 각 배열을 저장합니다.
// 항목은 현재 배열에서 비교해야 하는 데이터를 저장합니다.
// indexOf 메소드를 사용하여 배열에 해당 요소가 존재하는지 검색합니다. (indexOf 메소드 설명 참조)
return _.indexOf(기타, 항목) >= 0;
});
});
};
// 현재 배열에서 지정된 데이터와 동일하지 않은 차이 데이터를 필터링하고 반환합니다.
// 이 함수는 일반적으로 배열에서 지정된 데이터를 삭제하고 삭제 후 새 배열을 가져오는 데 사용됩니다.
// 이 메소드의 기능은 Without와 동일합니다. Without 메소드 매개변수는 데이터가 배열에 포함되는 것을 허용하지 않는 반면, Difference 메소드 매개변수는 배열을 권장합니다(without과 동일한 매개변수를 사용할 수도 있습니다).
_.차이 = 함수(배열) {
// 두 번째 매개변수부터 모든 매개변수를 배열로 병합합니다. (1단계만 병합하고, 깊은 병합은 하지 않습니다.)
// 나머지 변수에는 원본 데이터와 비교하기 위해 이 메서드에서 사용되는 검증 데이터가 저장됩니다.
var 나머지 = _.platten(slice.call(arguments, 1), true);
// 병합된 배열 데이터를 필터링합니다. 필터 조건은 현재 배열에 매개변수에 지정된 검증 데이터가 포함되어 있지 않다는 것입니다.
// 필터 조건에 맞는 데이터를 새로운 배열로 결합하여 반환
return _.filter(배열, 함수(값) {
return !_.include(나머지, 값);
});
};
//각 배열의 동일한 위치에 있는 데이터를 새로운 2차원 배열로 반환합니다. 반환되는 배열의 길이는 전달된 매개변수의 최대 배열 길이를 기준으로 합니다. 다른 배열의 공백 위치는 정의되지 않은 상태로 채워집니다.
// zip 메소드에는 여러 매개변수가 포함되어야 하며 각 매개변수는 배열이어야 합니다.
_.zip = 함수() {
//매개변수를 배열로 변환합니다. 이때 args는 2차원 배열입니다.
var args = Slice.call(인수);
// 각 배열의 길이를 계산하고 최대 길이 값을 반환합니다.
var 길이 = _.max(_.pluck(args, '길이'));
//처리 결과를 저장하는 데 사용되는 최대 길이 값에 따라 새로운 빈 배열을 생성합니다.
var 결과 = new Array(length);
//루프의 최대 길이, 각 루프에서 각 배열의 동일한 위치(0부터 순서대로 마지막 위치까지)의 데이터를 얻기 위해 pluck 메소드가 호출됩니다.
// 얻은 데이터를 새 배열에 저장하고 결과에 넣고 반환합니다.
for(var i = 0; i 
핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7381
7381
 15
1628
14
1357
52
1267
25
1216
29
15
1628
14
1357
52
1267
25
1216
29

 Edge 브라우저와 함께 제공되는 번역 웹 페이지가 누락된 경우 어떻게 해야 합니까?
Mar 14, 2024 pm 08:50 PM
Edge 브라우저와 함께 제공되는 번역 웹 페이지가 누락된 경우 어떻게 해야 합니까?
Mar 14, 2024 pm 08:50 PM
엣지 브라우저에는 언제 어디서나 번역할 수 있는 번역 기능이 있어 사용자에게 큰 편리함을 제공합니다. 그러나 많은 사용자들은 내장된 번역 웹 페이지가 누락되었다고 말합니다. 그러면 엣지 브라우저가 자동으로 어떻게 해야 합니까? 내가 가져온 번역 페이지가 없어졌나요? Edge 브라우저와 함께 제공되는 번역된 웹 페이지가 누락된 경우 이를 복원하는 방법을 이 사이트에서 소개하겠습니다. Edge 브라우저에 포함된 번역 웹페이지가 누락되어 복원하는 방법 1. 번역 기능이 활성화되어 있는지 확인하십시오. Edge 브라우저에서 오른쪽 상단에 있는 세 개의 점 아이콘을 클릭한 후 "설정" 옵션을 선택하십시오. 설정 페이지 왼쪽에서 언어 옵션을 선택하세요. '번역'을 확인하세요.
 자막 없이 영화를 본다고 걱정하지 마세요! Xiaomi는 일본어 및 한국어 번역을 위한 Xiaoai 번역 실시간 자막 출시를 발표했습니다.
Jul 22, 2024 pm 02:11 PM
자막 없이 영화를 본다고 걱정하지 마세요! Xiaomi는 일본어 및 한국어 번역을 위한 Xiaoai 번역 실시간 자막 출시를 발표했습니다.
Jul 22, 2024 pm 02:11 PM
7월 22일 소식에 따르면, 오늘 샤오미 더페이퍼 OS 공식 웨이보에서는 샤오아이 번역이 업그레이드됐다고 발표했다. 일본어와 한국어 번역에 실시간 자막이 추가됐고, 자막 없는 영상과 라이브 회의도 전사 및 번역이 가능해졌다. 실시간. 대면동시통역은 중국어, 영어, 일본어, 한국어, 러시아어, 포르투갈어, 스페인어, 이탈리아어, 프랑스어, 독일어, 인도네시아어, 힌디어 등 12개 언어 번역을 지원합니다. 위 기능은 현재 다음 세 가지 새로운 휴대폰만 지원합니다. Xiaomi MIX Fold 4 Xiaomi MIX Flip Redmi K70 Extreme Edition 2021년에는 Xiao Ai의 AI 자막이 일본어 및 한국어 번역에 추가될 예정인 것으로 알려졌습니다. AI 자막은 샤오미가 자체 개발한 동시통역 기술을 사용해 더 빠르고 안정적이며 정확한 자막 읽기 경험을 제공합니다. 1. 공식 성명에 따르면 Xiaoai 번역기는 오디오 및 비디오 장소에서만 사용할 수 있는 것이 아닙니다.
 Sogou 브라우저를 번역하는 방법
Feb 01, 2024 am 11:09 AM
Sogou 브라우저를 번역하는 방법
Feb 01, 2024 am 11:09 AM
Sogou 브라우저는 어떻게 번역하나요? 우리가 일반적으로 정보를 확인하기 위해 Sogou 브라우저를 사용할 때 영어로 된 일부 웹사이트를 보게 됩니다. 왜냐하면 웹사이트를 탐색하는 것이 매우 어렵기 때문입니다. 이런 상황이 발생합니다! Sogou 브라우저에는 번역 버튼이 내장되어 있습니다. 단 한 번의 클릭만으로 Sogou 브라우저가 자동으로 전체 웹페이지를 번역해 줍니다. 작동 방법을 모르신다면 편집자가 Sogou 브라우저에서 번역하는 방법에 대한 구체적인 단계를 정리했습니다. 방법을 모르신다면 저를 따라가서 읽어보세요! Sogou 브라우저 번역 방법 1. Sogou 브라우저를 열고 오른쪽 상단의 번역 아이콘을 클릭합니다. 2. 번역 텍스트 유형을 선택한 다음 번역해야 하는 텍스트를 입력합니다. 3. Sogou 브라우저가 자동으로 텍스트를 번역합니다. 이로써 위의 Sogou Browsing 작업이 모두 완료되었습니다.
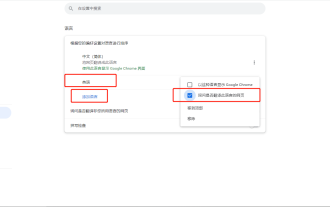 Google 크롬 내장 번역이 실패하는 문제를 해결하는 방법은 무엇입니까?
Mar 13, 2024 pm 08:46 PM
Google 크롬 내장 번역이 실패하는 문제를 해결하는 방법은 무엇입니까?
Mar 13, 2024 pm 08:46 PM
브라우저에는 일반적으로 번역 기능이 내장되어 있으므로 외국어 웹사이트를 탐색할 때 이해하지 못할까 봐 걱정할 필요가 없습니다! Chrome도 예외는 아니지만 일부 사용자는 Google Chrome의 번역 기능을 열 때 응답이 없거나 실패하는 것을 발견합니다. 내가 찾은 최신 솔루션을 사용해 볼 수 있습니다. 작업 튜토리얼: 오른쪽 상단 모서리에 있는 세 개의 점을 클릭하고 설정을 클릭합니다. 언어 추가를 클릭하고, 영어와 중국어를 추가한 후, 영어 설정은 해당 언어로 웹페이지를 번역할지 묻습니다. 중국어 설정은 웹페이지를 해당 언어로 표시하며, 그 전에 중국어를 맨 위로 이동해야 합니다. 기본 언어로 설정할 수 있습니다. 웹 페이지를 열었는데 번역 옵션이 팝업되지 않으면 마우스 오른쪽 버튼을 클릭하고 중국어 번역, 확인을 선택하세요.
 JavaScript 기반 실시간 번역 도구 구축
Aug 09, 2023 pm 07:22 PM
JavaScript 기반 실시간 번역 도구 구축
Aug 09, 2023 pm 07:22 PM
JavaScript 기반의 실시간 번역 도구 구축 서문 세계화에 대한 요구가 증가하고 국경 간 교류 및 교환이 빈번하게 발생함에 따라 실시간 번역 도구는 매우 중요한 응용 프로그램이 되었습니다. JavaScript와 일부 기존 API를 활용하여 간단하지만 유용한 실시간 번역 도구를 구축할 수 있습니다. 이 기사에서는 JavaScript를 기반으로 이 기능을 구현하는 방법을 코드 예제와 함께 소개합니다. 구현 단계 1단계: HTML 구조 생성 먼저 간단한 HTML을 생성해야 합니다.
 Google 크롬이 중국어를 번역할 수 없는 이유는 무엇인가요?
Mar 11, 2024 pm 04:04 PM
Google 크롬이 중국어를 번역할 수 없는 이유는 무엇인가요?
Mar 11, 2024 pm 04:04 PM
Google 크롬이 중국어를 번역할 수 없는 이유는 무엇입니까? 우리 모두 알고 있듯이 Google 크롬은 번역 기능이 내장된 브라우저 중 하나입니다. 이 브라우저에서 다른 나라에서 작성된 페이지를 탐색하면 브라우저가 자동으로 해당 페이지를 중국어로 번역한다고 합니다. 현재로서는 설정에서 수정해야 합니다. 다음으로, 편집자는 Google 크롬이 중국어로 번역할 수 없는 문제에 대한 해결책을 제시할 것입니다. 관심 있는 친구들은 와서 살펴볼 수 있습니다. Google 크롬은 중국어 솔루션을 번역할 수 없습니다. 1. 로컬 호스트 파일을 수정합니다. 호스트는 확장자가 없는 시스템 파일입니다. 주요 기능은 IP 주소와 호스트 이름 간의 매핑 관계를 정의하는 것입니다. 매핑 IP 주소입니다.
 Sogou Browser가 웹 페이지를 번역할 수 없는 문제를 해결하는 방법
Jan 29, 2024 pm 09:18 PM
Sogou Browser가 웹 페이지를 번역할 수 없는 문제를 해결하는 방법
Jan 29, 2024 pm 09:18 PM
Sogou Browser가 이 웹페이지를 번역할 수 없으면 어떻게 해야 합니까? Sogou 브라우저는 매우 사용하기 쉬운 다기능 브라우저입니다. 웹 페이지 번역 기능은 매우 강력하며 공부와 업무에서 대부분의 문제를 해결하는 데 도움이 됩니다. 그러나 일부 친구들은 Sogou 브라우저에 이 웹 페이지를 번역할 수 없는 문제가 있다고 보고했습니다. 이는 잘못된 작동으로 인해 발생할 수 있습니다. 아래에서는 Sogou 브라우저가 번역할 수 없는 문제를 알려드리겠습니다. 번역하세요. 이 페이지 솔루션을 번역하세요. Sogou 브라우저는 이 웹페이지를 번역할 수 없습니다. 해결 방법 1: 1. Sogou 브라우저를 다운로드하여 설치합니다. 2. Sogou 브라우저를 엽니다. 3. 영어 웹사이트를 엽니다. 4. 웹사이트가 열린 후 오른쪽 상단에 있는 번역 아이콘을 클릭합니다. 5. 번역을 선택합니다. 텍스트를 입력하고 현재 웹페이지 번역을 클릭하세요. 6
 iOS 17.2: iPhone의 작업 버튼을 사용하여 음성을 번역하는 방법
Dec 15, 2023 pm 11:21 PM
iOS 17.2: iPhone의 작업 버튼을 사용하여 음성을 번역하는 방법
Dec 15, 2023 pm 11:21 PM
iOS 17.2에서는 iPhone 작업 버튼에 대한 새로운 사용자 정의 번역 옵션으로 의사소통 장벽을 극복합니다. 사용 방법을 알아보려면 계속 읽어보세요. iPhone 15 Pro와 같이 작업 버튼이 있는 iPhone을 사용하는 경우 Apple의 iOS 17.2 소프트웨어 업데이트는 버튼에 새로운 번역 옵션을 제공하여 실시간 대화를 여러 언어로 번역할 수 있게 해줍니다. Apple에 따르면 번역은 정확할 뿐만 아니라 상황을 인식하여 뉘앙스와 음성 언어가 효과적으로 포착되도록 보장합니다. 이 기능은 여행자, 학생, 언어를 배우는 모든 사람에게 도움이 될 것입니다. 번역 기능을 사용하기 전에 번역하려는 언어를 선택하세요. Apple에 내장된 번역 앱을 통해 이 작업을 수행할 수 있습니다.
