

FAISS 벡터 공간을 시각화하고 RAG 매개변수를 조정하여 결과 정확도 향상

오픈소스 대규모 언어 모델의 성능이 지속적으로 향상됨에 따라 코드 작성 및 분석, 권장 사항, 텍스트 요약, QA(질의응답) 쌍 성능이 크게 향상되었습니다. 그러나 QA와 관련하여 LLM은 훈련되지 않은 데이터와 관련된 문제가 부족한 경우가 많으며 규정 준수, 영업 비밀 또는 개인 정보 보호를 보장하기 위해 많은 내부 문서가 회사 내에 보관됩니다. 이러한 문서를 쿼리하면 LLM은 환각을 느끼고 관련이 없거나 조작되었거나 일관성이 없는 콘텐츠를 생성할 수 있습니다.

이 문제를 처리할 수 있는 기술 중 하나는 검색 증강 생성(RAG)입니다. 여기에는 생성의 품질과 정확성을 향상시키기 위해 훈련 데이터 소스를 넘어 권위 있는 지식 기반을 참조하여 응답을 향상시키는 프로세스가 포함됩니다. RAG 시스템은 코퍼스에서 관련 문서 조각을 검색하는 검색 시스템과 검색된 조각을 컨텍스트로 활용하여 응답을 생성하는 LLM 모델로 구성됩니다. 따라서 코퍼스의 품질과 벡터 공간에 포함된 표현은 RAG 성능에 매우 중요합니다.
이 기사에서는 시각화 라이브러리 renumics-spotlight를 사용하여 FAISS 벡터 공간의 다차원 임베딩을 2D로 시각화하고 일부 주요 벡터화 매개변수를 변경하여 RAG 응답 정확도를 향상시킬 수 있는 가능성을 찾아보겠습니다. 우리가 선택한 LLM에는 Llama 2와 동일한 아키텍처를 갖춘 컴팩트 모델인 TinyLlama 1.1B Chat을 사용합니다. 정확도가 비례적으로 떨어지지 않으면서 리소스 공간이 더 작고 런타임이 더 빠르다는 장점이 있어 빠른 실험에 이상적입니다.
시스템 설계
QA 시스템에는 그림과 같이 두 개의 모듈이 있습니다.
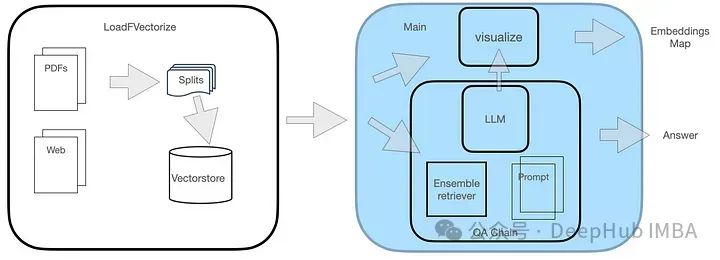
LoadFVectorize 모듈은 PDF 또는 웹 문서를 로드하고 예비 테스트 및 시각화를 수행하는 데 사용됩니다. 또 다른 모듈은 LLM을 로드하고 FAISS 검색기를 인스턴스화한 다음 LLM, 검색기 및 사용자 정의 쿼리 프롬프트를 포함한 검색 체인을 구축하는 일을 담당합니다. 마지막으로 벡터 공간을 시각화합니다.
코드 구현
1. 필요한 라이브러리 설치
renomics-spotlight 라이브러리는 주요 속성을 유지하면서 고차원 임베딩을 관리 가능한 2D 시각화로 줄이기 위해 Umap과 같은 시각화 방법을 채택합니다. 앞에서 Umap의 사용법을 간략하게 소개했지만 기본적인 기능만 소개했습니다. 이번에는 시스템 설계의 일부로 이를 실제 프로젝트에 통합했습니다. 먼저 필요한 라이브러리를 설치해야 합니다.
pip install langchain faiss-cpu sentence-transformers flask-sqlalchemy psutil unstructured pdf2image unstructured_inference pillow_heif opencv-python pikepdf pypdf pip install renumics-spotlight CMAKE_ARGS="-DLLAMA_METAL=on" FORCE_CMAKE=1 pip install --upgrade --force-reinstall llama-cpp-python --no-cache-dir
위의 마지막 줄은 Metal 지원이 포함된 llama-pcp-python 라이브러리를 설치하는 것입니다. 이 라이브러리는 M1 프로세서에서 하드웨어 가속 기능이 있는 TinyLlama를 로드하는 데 사용됩니다.
2. LoadFVectorize 모듈
모듈에는 3가지 기능이 포함되어 있습니다.
load_doc는 온라인 PDF 문서 로드를 처리하며, 각 블록은 512자로 나누어 100자로 겹쳐서 문서 목록을 반환합니다.
Vectorize는 위의 load_doc 함수를 호출하여 문서의 차단 목록을 가져오고 포함을 생성한 후 로컬 디렉터리 opdf_index에 저장하고 FAISS 인스턴스를 반환합니다.
load_db는 FAISS 라이브러리가 opdf_index 디렉토리의 디스크에 있는지 확인하고 이를 로드하려고 시도하며 결국 FAISS 객체를 반환합니다.
이 모듈 코드의 전체 코드는 다음과 같습니다.
# LoadFVectorize.py from langchain_community.embeddings import HuggingFaceEmbeddings from langchain_community.document_loaders import OnlinePDFLoader from langchain.text_splitter import RecursiveCharacterTextSplitter from langchain_community.vectorstores import FAISS # access an online pdf def load_doc() -> 'List[Document]':loader = OnlinePDFLoader("https://support.riverbed.com/bin/support/download?did=7q6behe7hotvnpqd9a03h1dji&versinotallow=9.15.0")documents = loader.load()text_splitter = RecursiveCharacterTextSplitter(chunk_size=512, chunk_overlap=100)docs = text_splitter.split_documents(documents)return docs # vectorize and commit to disk def vectorize(embeddings_model) -> 'FAISS':docs = load_doc()db = FAISS.from_documents(docs, embeddings_model)db.save_local("./opdf_index")return db # attempts to load vectorstore from disk def load_db() -> 'FAISS':embeddings_model = HuggingFaceEmbeddings()try:db = FAISS.load_local("./opdf_index", embeddings_model)except Exception as e:print(f'Exception: {e}\nNo index on disk, creating new...')db = vectorize(embeddings_model)return db3. 기본 모듈
기본 모듈은 처음에 다음 템플릿의 TinyLlama 프롬프트 템플릿을 정의합니다.
{context}{question}또한 TheBloke의 TinyLlama 양자화 버전을 사용하면 메모리를 크게 줄일 수 있습니다. 우리는 양자화 LLM을 GGUF 형식으로 로드하기로 결정했습니다.
그런 다음 LoadFVectorize 모듈에서 반환된 FAISS 개체를 사용하고, FAISS 검색기를 만들고, RetrievalQA를 인스턴스화하여 쿼리에 사용합니다.
# main.py from langchain.chains import RetrievalQA from langchain.prompts import PromptTemplate from langchain_community.llms import LlamaCpp from langchain_community.embeddings import HuggingFaceEmbeddings import LoadFVectorize from renumics import spotlight import pandas as pd import numpy as np # Prompt template qa_template = """ You are a friendly chatbot who always responds in a precise manner. If answer is unknown to you, you will politely say so. Use the following context to answer the question below: {context} {question} """ # Create a prompt instance QA_PROMPT = PromptTemplate.from_template(qa_template) # load LLM llm = LlamaCpp(model_path="./models/tinyllama_gguf/tinyllama-1.1b-chat-v1.0.Q5_K_M.gguf",temperature=0.01,max_tokens=2000,top_p=1,verbose=False,n_ctx=2048 ) # vectorize and create a retriever db = LoadFVectorize.load_db() faiss_retriever = db.as_retriever(search_type="mmr", search_kwargs={'fetch_k': 3}, max_tokens_limit=1000) # Define a QA chain qa_chain = RetrievalQA.from_chain_type(llm,retriever=faiss_retriever,chain_type_kwargs={"prompt": QA_PROMPT} ) query = 'What versions of TLS supported by Client Accelerator 6.3.0?' result = qa_chain({"query": query}) print(f'--------------\nQ: {query}\nA: {result["result"]}') visualize_distance(db,query,result["result"])벡터 공간 시각화 자체는 위 코드에서 visible_distance의 마지막 줄에 의해 처리됩니다.
visualize_distance는 FAISS 객체의 __dict__ 속성에 액세스하고, index_to_docstore_id 자체는 docstore 값에 대한 키 인덱스 사전입니다. -ids, 사용됨 벡터화된 총 문서 수는 인덱스 개체의 ntotal 속성으로 표시됩니다.
vs = db.__dict__.get("docstore")index_list = db.__dict__.get("index_to_docstore_id").values()doc_cnt = db.index.ntotal객체 인덱스 메소드 reconstruct_n을 호출하면 벡터 공간을 대략적으로 재구성할 수 있습니다.
embeddings_vec = db.index.reconstruct_n()
docstore-id 목록을 index_list로 사용하면 관련 문서 객체를 찾아 이를 사용하여 A를 생성할 수 있습니다. docstore-id, 문서 메타데이터, 문서 콘텐츠 및 모든 ID의 벡터 공간에 포함된 목록:
doc_list = list() for i,doc-id in enumerate(index_list):a_doc = vs.search(doc-id)doc_list.append([doc-id,a_doc.metadata.get("source"),a_doc.page_content,embeddings_vec[i]])그런 다음 목록을 사용하여 열 헤더가 포함된 DF를 만들고, 마지막으로 시각화를 위해 이 DF를 사용합니다.
df = pd.DataFrame(doc_list,columns=['id','metadata','document','embedding'])
在继续进行可视化之前,还需要将问题和答案结合起来,我们创建一个单独的问题以及答案的DF,然后与上面的df进行合并,这样能够显示问题和答案出现的地方,在可视化时我们可以高亮显示:
# add rows for question and answerembeddings_model = HuggingFaceEmbeddings()question_df = pd.DataFrame({"id": "question","question": question,"embedding": [embeddings_model.embed_query(question)],})answer_df = pd.DataFrame({"id": "answer","answer": answer,"embedding": [embeddings_model.embed_query(answer)],})df = pd.concat([question_df, answer_df, df])这里使用使用np.linalg.norm在文件和问题嵌入上的进行距离大小的计算:
question_embedding = embeddings_model.embed_query(question)# add column for vector distancedf["dist"] = df.apply( lambda row: np.linalg.norm(np.array(row["embedding"]) - question_embedding),axis=1,)
因为spotlight可以对df进行可视化,所有我们直接调用即可
spotlight.show(df)
이 단계에서는 브라우저 창에서 스포트라이트를 시작합니다. 、 테스트 실행 基 1. 기본 테스트
다음은 우리가 선택한 샘플 문제입니다.
Client Accelerator 6.3.0에서 지원하는 tls 버전은 무엇입니까? 예:
Client Accelerator 6.3.0에서는 어떤 버전을 지원합니까? TLS 1.1 또는 1.2.
다음 추가 정보가 응답에 포함될 수 있습니다.
클라이언트 가속기에서 다음 CLI 명령을 사용하여 이 기능을 활성화해야 합니다:(config) # 정책 id
그런 다음 위 질문에 대한 TinyLlama의 답변을 살펴보겠습니다.
Client Accelerator 6.3.0은 기본적으로 TLS 1.1 또는 1.2를 지원합니다. 클라이언트 가속기에서 지원되는 TLS 버전은 클라이언트 가속기에서 다음 CLI 명령을 사용하여 이 기능을 활성화해야 합니다.
(config) # 정책 ID```
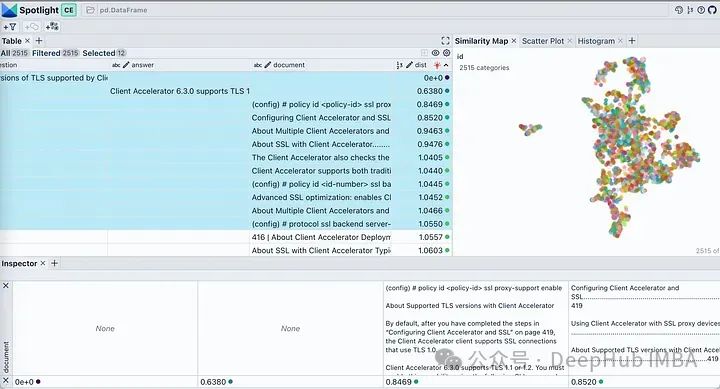
스포트라이트에 보이는 버튼을 사용하여 표시된 열을 제어하세요. 질문, 답변 및 가장 관련성이 높은 문서 조각을 상단에 표시하려면 표를 "dist"로 정렬하세요. 문서 임베딩을 살펴보면 문서의 거의 모든 청크를 단일 클러스터로 설명합니다. 원본 PDF는 특정 제품에 대한 배포 가이드이므로 클러스터로 간주되는 데 문제가 없기 때문에 이는 합리적입니다.```이 명령은 TLS 1.1 또는 TLS 1.2에만 적용됩니다. 이전 TLS 버전을 지원해야 하는 경우 client-tlss1.0과 함께 ssl 백엔드 명령을 사용할 수 있습니다. 또는 client-tlss1.1 option 대신. 실제 답변과 매우 유사해 보이지만 이러한 TLS 버전은 기본값이 아니기 때문에 완전히 정확하지는 않습니다. 그럼 그가 어떤 구절에서 답을 찾았는지 볼까요?
유사성 맵 탭에서 필터 아이콘을 클릭하면 아래 이미지와 같이 선택한 문서 목록만 촘촘하게 클러스터되어 강조 표시되고 나머지는 회색으로 표시됩니다.
리트리버는 RAG 성능에 영향을 미치는 핵심 요소이므로 임베딩 공간에 영향을 미치는 여러 매개변수를 살펴보겠습니다. TextSplitter의 청크 크기(1000, 2000) 및/또는 중첩(100, 200) 매개 변수는 문서 분할 중에 다릅니다.
왼쪽에서 오른쪽으로 보면 블록 크기가 증가함에 따라 벡터 공간이 희박해지고 블록이 작아지는 것을 관찰할 수 있습니다. 아래에서 위로 갈수록 벡터 공간 특성의 큰 변화 없이 중첩이 점차 증가합니다. 이러한 모든 매핑에서 전체 세트는 여전히 거의 단일 클러스터로 나타나며 몇 가지 이상값만 존재합니다. 이는 생성된 응답이 모두 매우 유사하기 때문에 생성된 응답에서 볼 수 있습니다.
如果查询位于簇中心等位置时由于最近邻可能不同,在这些参数发生变化时响应很可能会发生显著变化。如果RAG应用程序无法提供预期答案给某些问题,则可以通过生成类似上述可视化图表并结合这些问题进行分析,可能找到最佳划分语料库以提高整体性能方面优化方法。
为了进一步说明,我们将两个来自不相关领域(Grammy Awards和JWST telescope)的维基百科文档的向量空间进行可视化展示。
def load_doc():loader = WebBaseLoader(['https://en.wikipedia.org/wiki/66th_Annual_Grammy_Awards','https://en.wikipedia.org/wiki/James_Webb_Space_Telescope'])documents = loader.load()...
只修改了上面代码其余的代码保持不变。运行修改后的代码,我们得到下图所示的向量空间可视化。
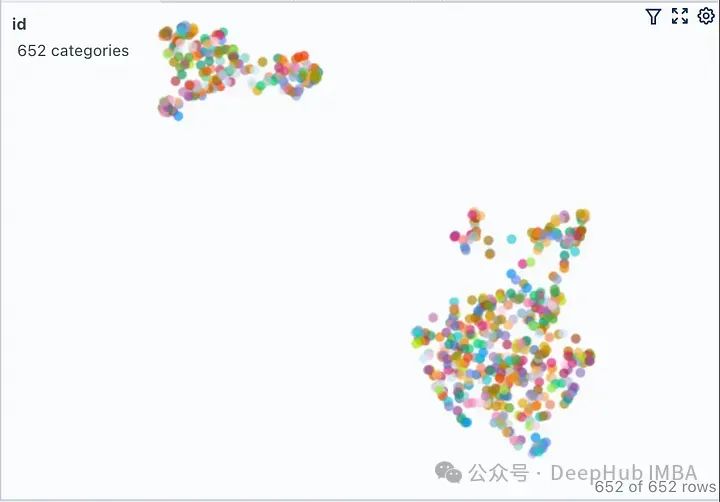
这里有两个不同的不重叠的簇。如果我们要在任何一个簇之外提出一个问题,那么从检索器获得上下文不仅不会对LLM有帮助,而且还很可能是有害的。提出之前提出的同样的问题,看看我们LLM产生什么样的“幻觉”
Client Accelerator 6.3.0 supports the following versions of Transport Layer Security (TLS):
- TLS 1.2\2. TLS 1.3\3. TLS 1.2 with Extended Validation (EV) certificates\4. TLS 1.3 with EV certificates\5. TLS 1.3 with SHA-256 and SHA-384 hash algorithms
这里我们使用FAISS用于向量存储。如果你正在使用ChromaDB并想知道如何执行类似的可视化,renumics-spotlight也是支持的。
总结
检索增强生成(RAG)允许我们利用大型语言模型的能力,即使LLM没有对内部文档进行训练也能得到很好的结果。RAG涉及从矢量库中检索许多相关文档块,然后LLM将其用作生成的上下文。因此嵌入的质量将在RAG性能中发挥重要作用。
在本文中,我们演示并可视化了几个关键矢量化参数对LLM整体性能的影响。并使用renumics-spotlight,展示了如何表示整个FAISS向量空间,然后将嵌入可视化。Spotlight直观的用户界面可以帮助我们根据问题探索向量空间,从而更好地理解LLM的反应。通过调整某些矢量化参数,我们能够影响其生成行为以提高精度。
위 내용은 FAISS 벡터 공간을 시각화하고 RAG 매개변수를 조정하여 결과 정확도 향상의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7518
7518
 15
1378
52
81
11
53
19
21
68
15
1378
52
81
11
53
19
21
68

 Chrome 브라우저가 충돌하는 이유는 무엇입니까? Chrome이 열리자마자 충돌하는 문제를 해결하는 방법은 무엇입니까?
Mar 13, 2024 pm 07:28 PM
Chrome 브라우저가 충돌하는 이유는 무엇입니까? Chrome이 열리자마자 충돌하는 문제를 해결하는 방법은 무엇입니까?
Mar 13, 2024 pm 07:28 PM
Google 크롬은 높은 보안성과 강력한 안정성을 갖추고 있어 대다수 사용자에게 사랑받고 있습니다. 그러나 일부 사용자는 Chrome을 열자마자 충돌이 발생하는 것을 발견합니다. 무슨 일입니까? 탭이 너무 많이 열려 있거나 브라우저 버전이 너무 오래되었기 때문일 수 있습니다. 아래에서 자세한 해결 방법을 살펴보겠습니다. Google 크롬의 충돌 문제를 해결하는 방법은 무엇입니까? 1. 불필요한 탭 닫기 열려 있는 탭이 너무 많은 경우 불필요한 탭을 닫아보세요. 이렇게 하면 Google 크롬의 리소스 압박을 효과적으로 완화하고 충돌 가능성을 줄일 수 있습니다. 2. Chrome 업데이트 Google Chrome의 버전이 너무 오래된 경우에는 충돌 및 기타 오류가 발생할 수도 있으므로 Chrome을 최신 버전으로 업데이트하는 것이 좋습니다. 오른쪽 상단의 [사용자 정의 및 제어]-[설정]을 클릭합니다.
 Windows on Ollama: LLM(대형 언어 모델)을 로컬에서 실행하기 위한 새로운 도구
Feb 28, 2024 pm 02:43 PM
Windows on Ollama: LLM(대형 언어 모델)을 로컬에서 실행하기 위한 새로운 도구
Feb 28, 2024 pm 02:43 PM
최근 OpenAITranslator와 NextChat은 모두 Ollama에서 로컬로 실행되는 대규모 언어 모델을 지원하기 시작했으며, 이는 "초보자" 매니아에게 새로운 플레이 방식을 제공합니다. 게다가 Windows(미리보기 버전)에서 Ollama의 출시는 Windows 장치의 AI 개발 방식을 완전히 뒤바꾸었습니다. 이는 AI 분야의 탐험가와 일반 "수질 테스트 플레이어"에게 명확한 길을 안내했습니다. 올라마란 무엇인가요? Ollama는 AI 모델의 개발 및 사용을 크게 단순화하는 획기적인 인공 지능(AI) 및 기계 학습(ML) 도구 플랫폼입니다. 기술 커뮤니티에서는 AI 모델의 하드웨어 구성과 환경 구축이 항상 까다로운 문제였습니다.
 pycharm 충돌을 해결하는 방법
Apr 25, 2024 am 05:09 AM
pycharm 충돌을 해결하는 방법
Apr 25, 2024 am 05:09 AM
PyCharm 충돌에 대한 해결 방법은 다음과 같습니다. 메모리 사용량 확인 및 PyCharm의 메모리 제한 증가, 플러그인 확인 및 불필요한 플러그인 제거, PyCharm 지원 담당자에게 문의 도와주기 위해.
 대규모 언어 모델이 SwiGLU를 활성화 기능으로 사용하는 이유는 무엇입니까?
Apr 08, 2024 pm 09:31 PM
대규모 언어 모델이 SwiGLU를 활성화 기능으로 사용하는 이유는 무엇입니까?
Apr 08, 2024 pm 09:31 PM
대규모 언어 모델의 아키텍처에 관심을 가져왔다면 최신 모델과 연구 논문에서 "SwiGLU"라는 용어를 본 적이 있을 것입니다. SwiGLU는 대규모 언어 모델에서 가장 일반적으로 사용되는 활성화 함수라고 할 수 있습니다. 이 기사에서는 이에 대해 자세히 소개하겠습니다. SwiGLU는 실제로 Google이 2020년에 제안한 활성화 기능으로 SWISH와 GLU의 특성을 결합한 것입니다. SwiGLU의 전체 중국어 이름은 "양방향 게이트 선형 장치"입니다. SWISH와 GLU라는 두 가지 활성화 기능을 최적화하고 결합하여 모델의 비선형 표현 능력을 향상시킵니다. SWISH는 대규모 언어 모델에서 널리 사용되는 매우 일반적인 활성화 함수인 반면, GLU는 자연어 처리 작업에서 좋은 성능을 보였습니다.
 Groq Llama 3 70B를 로컬에서 사용하기 위한 단계별 가이드
Jun 10, 2024 am 09:16 AM
Groq Llama 3 70B를 로컬에서 사용하기 위한 단계별 가이드
Jun 10, 2024 am 09:16 AM
번역기 | Bugatti 리뷰 | Chonglou 이 문서에서는 GroqLPU 추론 엔진을 사용하여 JanAI 및 VSCode에서 초고속 응답을 생성하는 방법을 설명합니다. 모두가 AI의 인프라 측면에 초점을 맞춘 Groq와 같은 더 나은 대규모 언어 모델(LLM)을 구축하기 위해 노력하고 있습니다. 이러한 대형 모델의 빠른 응답은 이러한 대형 모델이 더 빠르게 응답하도록 보장하는 핵심입니다. 이 튜토리얼에서는 GroqLPU 구문 분석 엔진과 API 및 JanAI를 사용하여 노트북에서 로컬로 액세스하는 방법을 소개합니다. 이 기사에서는 코드 생성, 코드 리팩터링, 문서 입력 및 테스트 단위 생성을 돕기 위해 이를 VSCode에 통합합니다. 이 기사에서는 우리만의 인공 지능 프로그래밍 도우미를 무료로 만들 것입니다. GroqLPU 추론 엔진 Groq 소개
 비교적 원활한 Android 에뮬레이터에 대한 권장 사항(사용할 Android 에뮬레이터 선택)
Apr 21, 2024 pm 06:01 PM
비교적 원활한 Android 에뮬레이터에 대한 권장 사항(사용할 Android 에뮬레이터 선택)
Apr 21, 2024 pm 06:01 PM
Android 에뮬레이터는 컴퓨터에서 Android 시스템의 실행을 시뮬레이션할 수 있는 소프트웨어입니다. 시중에는 다양한 종류의 Android 에뮬레이터가 있으며 품질도 다양합니다. 독자가 자신에게 가장 적합한 에뮬레이터를 선택할 수 있도록 돕기 위해 이 기사에서는 부드럽고 사용하기 쉬운 Android 에뮬레이터에 중점을 둘 것입니다. 1. BlueStacks: 빠른 실행 속도 뛰어난 실행 속도와 원활한 사용자 경험을 갖춘 BlueStacks는 인기 있는 Android 에뮬레이터입니다. 사용자가 다양한 모바일 게임과 애플리케이션을 플레이할 수 있도록 하여 매우 높은 성능으로 컴퓨터에서 Android 시스템을 에뮬레이트할 수 있습니다. 2. NoxPlayer: 다중 열기를 지원하여 여러 에뮬레이터에서 동시에 다양한 게임을 실행할 수 있습니다.
 GPU 하드웨어 가속을 활성화해야 합니까?
Feb 26, 2024 pm 08:45 PM
GPU 하드웨어 가속을 활성화해야 합니까?
Feb 26, 2024 pm 08:45 PM
하드웨어 가속 GPU를 활성화해야 합니까? 지속적인 기술의 발전과 진보에 따라 컴퓨터 그래픽 처리의 핵심 구성요소인 GPU(Graphics Processor Unit)는 중요한 역할을 하고 있습니다. 그러나 일부 사용자는 하드웨어 가속을 켜야 하는지 여부에 대해 질문할 수 있습니다. 이 기사에서는 GPU에 대한 하드웨어 가속의 필요성과 하드웨어 가속을 켤 때 컴퓨터 성능과 사용자 경험에 미치는 영향에 대해 설명합니다. 먼저, 하드웨어 가속 GPU가 어떻게 작동하는지 이해해야 합니다. GPU는 특화된
 WPS 양식이 느리게 응답하는 경우 어떻게 해야 합니까? WPS 양식이 멈추고 응답이 느린 이유는 무엇입니까?
Mar 14, 2024 pm 02:43 PM
WPS 양식이 느리게 응답하는 경우 어떻게 해야 합니까? WPS 양식이 멈추고 응답이 느린 이유는 무엇입니까?
Mar 14, 2024 pm 02:43 PM
WPS 양식이 매우 느리게 응답하는 경우 어떻게 해야 합니까? 사용자는 다른 프로그램을 닫거나 소프트웨어를 업데이트하여 작업을 수행할 수 있습니다. 이 사이트에서 WPS 양식의 응답 속도가 느린 이유를 사용자에게 주의 깊게 소개하십시오. WPS 테이블의 응답 속도가 느린 이유는 무엇입니까? 1. 다른 프로그램 닫기: 실행 중인 다른 프로그램, 특히 시스템 리소스를 많이 차지하는 프로그램을 닫습니다. 이를 통해 WPS Office에 더 많은 컴퓨팅 리소스를 제공하고 지연 및 지연을 줄일 수 있습니다. 2. WPSOffice 업데이트: 최신 버전의 WPSOffice를 사용하고 있는지 확인하세요. 공식 WPSOffice 웹사이트에서 최신 버전을 다운로드하여 설치하면 일부 알려진 성능 문제를 해결할 수 있습니다. 3. 파일 크기 줄이기
