
최근 OpenAI의 영상 생성 모델인 Sora가 인기를 끌면서 생성 AI 모델의 멀티모달 기능이 다시 한번 폭넓은 관심을 끌었습니다.
실제 세계는 본질적으로 다중 모드이며 유기체는 시각, 언어, 소리 및 촉각을 포함한 다양한 채널을 통해 정보를 감지하고 교환합니다. 다중 모드 시스템 개발을 위한 한 가지 유망한 방향은 LLM의 다중 모드 인식 기능을 향상시키는 것입니다. 이는 주로 다중 모드 인코더와 언어 모델의 통합을 포함하여 다양한 양식에 걸쳐 정보를 처리하고 LLM의 텍스트 처리 기능을 활용하여 일관된 응답을 생성할 수 있도록 합니다.
그러나 이 전략은 텍스트 생성에만 적용되며 다중 모드 출력에는 적용되지 않습니다. 일부 선구적인 연구는 언어 모델의 다중 모드 이해 및 생성을 달성하는 데 상당한 진전을 이루었지만 이러한 모델은 이미지 또는 오디오와 같은 단일 비텍스트 형식으로 제한됩니다.
위 문제를 해결하기 위해 푸단대학교 Qiu Xipeng 팀은 Multimodal Art Projection(MAP) 및 Shanghai Artificial Intelligence Laboratory의 연구원과 함께 AnyGPT라는 다중 모드 언어 모델을 제안했습니다. 모드 조합은 다양한 양식의 내용을 이해하고 추론하는 데 사용됩니다. 특히 AnyGPT는 텍스트, 음성, 이미지, 음악 등과 같은 다양한 양식과 얽혀 있는 명령을 이해할 수 있으며 대응할 적절한 다중 모드 조합을 능숙하게 선택할 수 있습니다.
예를 들어 음성 프롬프트가 제공되면 AnyGPT는 음성, 이미지 및 음악 형식으로 포괄적인 응답을 생성할 수 있습니다.
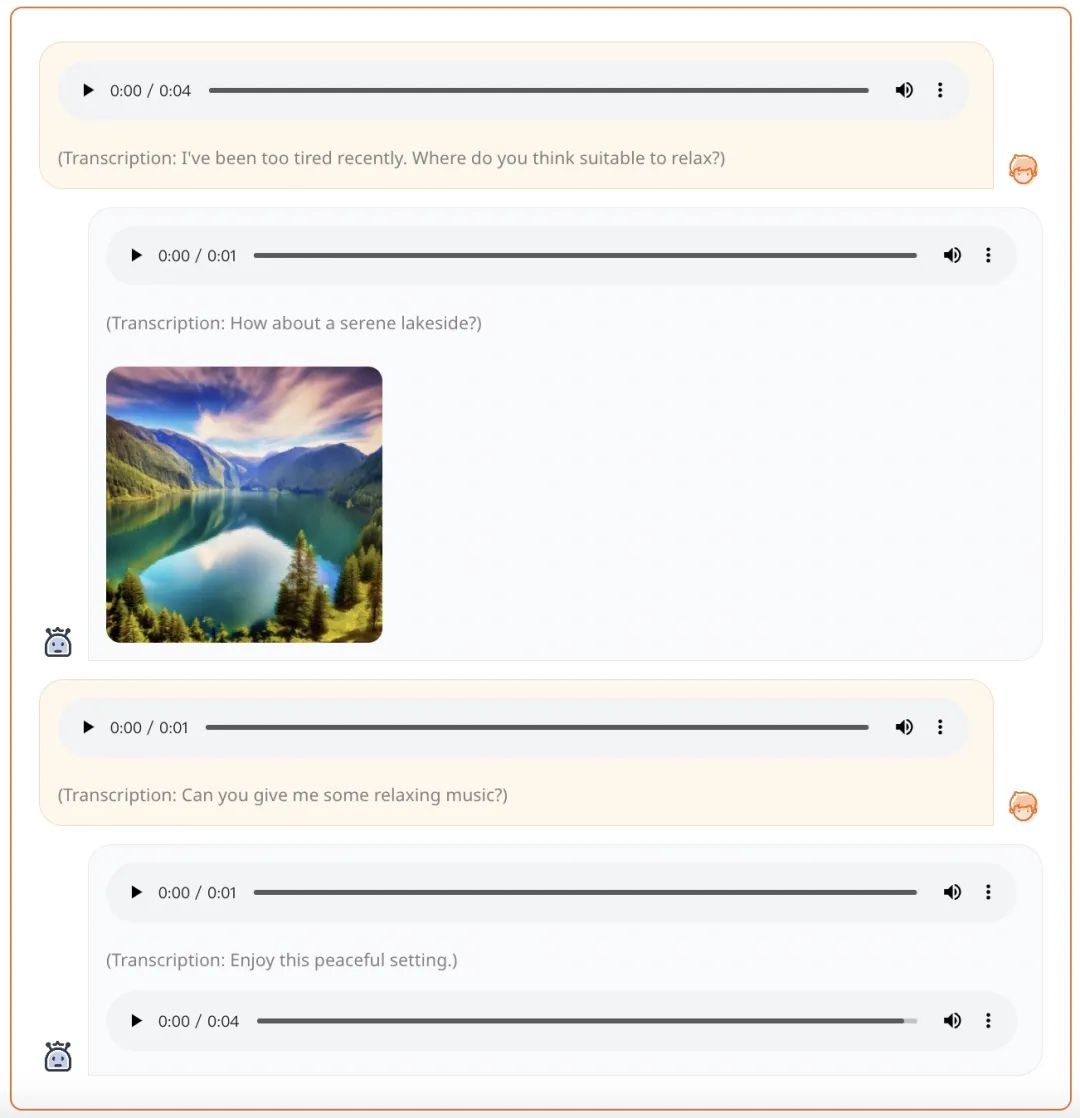
텍스트 + 이미지 형식의 프롬프트가 제공되면 AnyGPT는 다음을 생성할 수 있습니다. 프롬프트 요구 사항에 따른 음악:
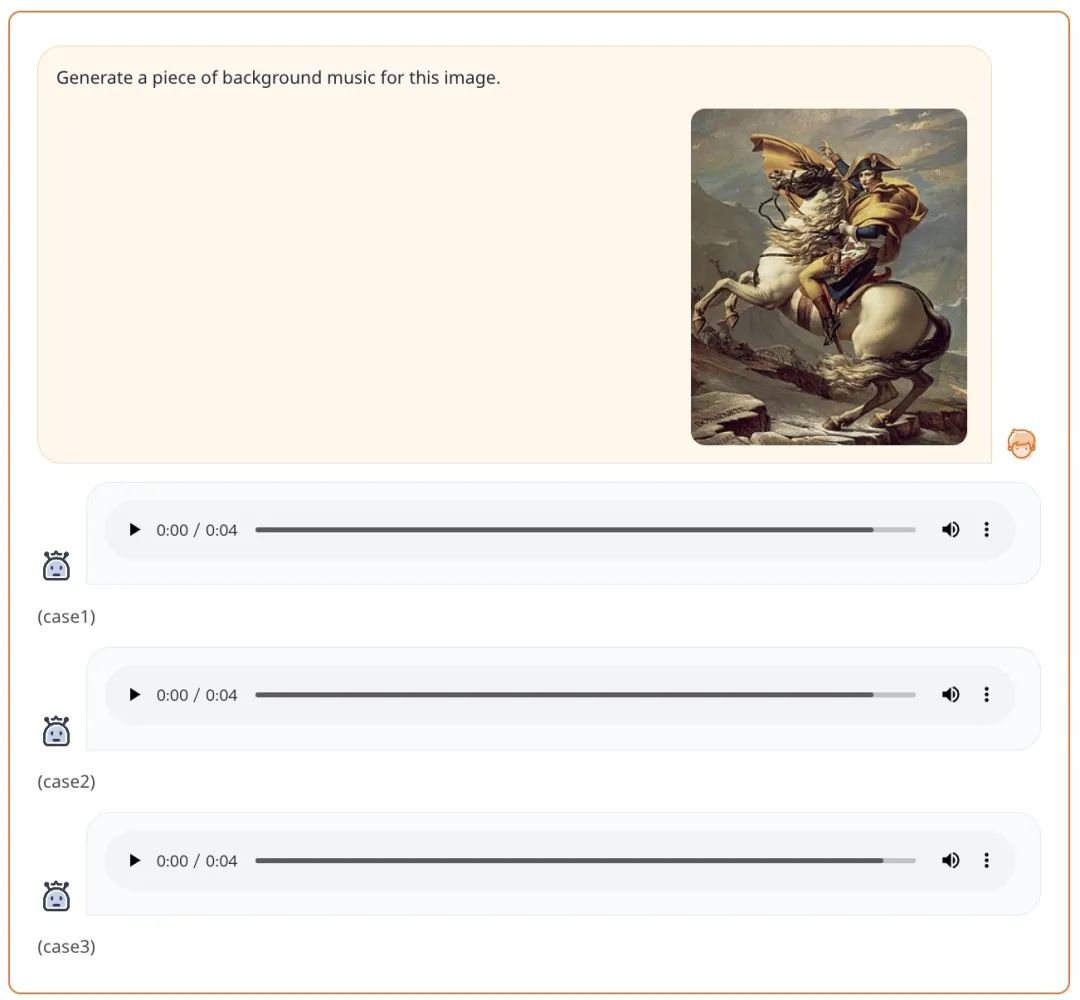

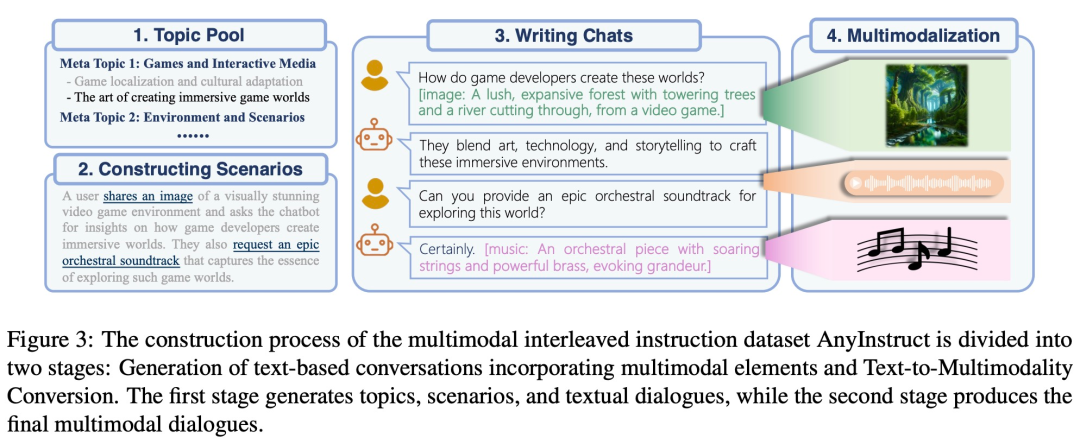
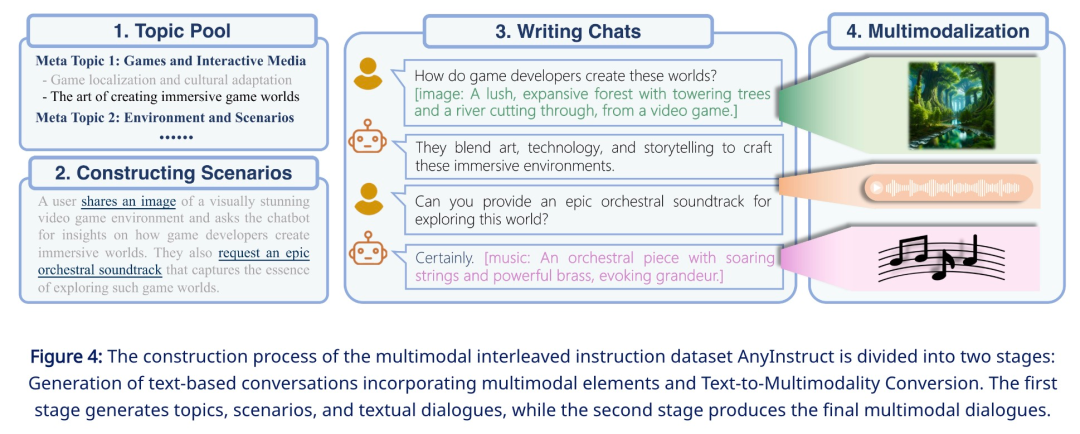
어떤 양식에서 어떤 양식으로든 생성 작업을 완료하기 위해 본 연구에서는 균일하게 훈련할 수 있는 포괄적인 프레임워크를 제안합니다. 아래 그림 1에 표시된 바와 같이, 프레임 워크는 다음을 포함한 세 가지 주요 구성 요소로 구성됩니다.
그중 토크나이저는 연속적인 비텍스트 형식을 개별 토큰으로 변환한 후 이를 다중 모드 인터리브 시퀀스로 배열합니다. 그런 다음 언어 모델은 다음 토큰 예측 훈련 대상을 사용하여 훈련됩니다. 추론 중에 다중 모드 토큰은 관련 토큰 해제 도구에 의해 원래 표현으로 다시 디코딩됩니다. 생성 품질을 향상시키기 위해 음성 복제 또는 이미지 초해상도와 같은 응용 프로그램을 포함하여 생성된 결과를 사후 처리하기 위해 다중 모드 향상 모듈을 배포할 수 있습니다.

이러한 데이터는 일반적으로 정확하게 표현하기 위해 많은 수의 비트가 필요하므로 긴 시퀀스가 발생합니다. 이는 시퀀스 길이에 따라 계산 복잡성이 기하급수적으로 증가하기 때문에 언어 모델에 특히 까다롭습니다. 이러한 문제를 해결하기 위해 본 연구에서는 의미 정보 모델링과 지각 정보 모델링을 포함한 2단계 고충실도 생성 프레임워크를 채택했습니다. 첫째, 언어 모델은 의미론적 수준에서 융합되고 정렬된 콘텐츠를 생성하는 작업을 담당합니다. 그런 다음 비자동회귀 모델은 다중 모드 의미 체계 토큰을 지각 수준에서 충실도가 높은 다중 모드 콘텐츠로 변환하여 성능과 효율성 사이의 균형을 유지합니다.
실험 결과에 따르면 AnyGPT는 모든 모드에서 모든 모드 간 대화 작업을 완료하는 동시에 모든 모드에서 전용 모델에 필적하는 성능을 달성하여 Discrete를 입증했습니다. 표현은 언어 모델의 여러 양식을 효과적이고 편리하게 통합할 수 있습니다.
이 연구에서는 모든 양식에 걸쳐 다중 모드 이해 및 생성 작업을 다루는 사전 훈련된 기본 AnyGPT의 기본 기능을 평가합니다. 이 평가는 사전 훈련 과정에서 다양한 양식 간의 일관성을 테스트하는 것을 목표로 합니다. 특히 각 양식의 텍스트-X 및 X-텍스트 작업을 테스트합니다. 여기서 X는 이미지, 음악 및 음성입니다.
실제 시나리오를 시뮬레이션하기 위해 모든 평가는 제로 샘플 모드에서 수행됩니다. 이는 AnyGPT가 평가 프로세스 중에 다운스트림 훈련 샘플을 미세 조정하거나 사전 훈련하지 않는다는 것을 의미합니다. 이 까다로운 평가 설정에서는 모델을 알 수 없는 테스트 분포로 일반화해야 합니다.
평가 결과 AnyGPT는 일반적인 다중 모드 언어 모델로서 다양한 다중 모드 이해 및 생성 작업에서 뛰어난 성능을 달성하는 것으로 나타났습니다.
Image
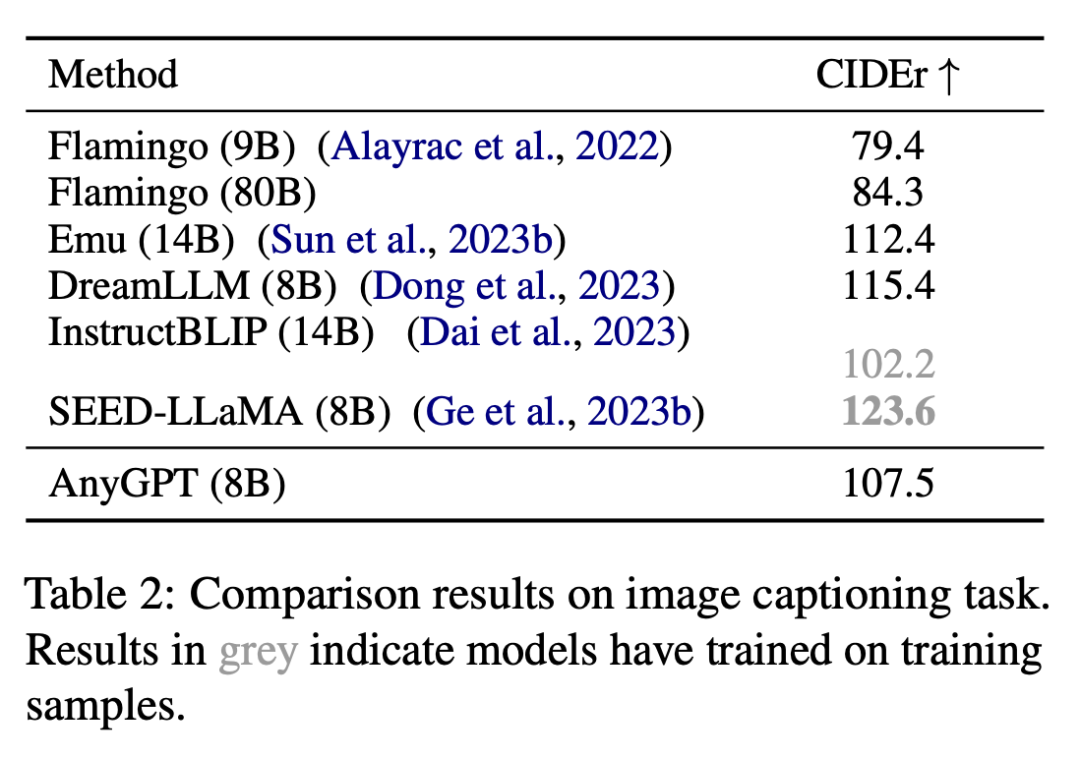
본 연구에서는 이미지 설명 작업에 대한 AnyGPT의 이미지 이해 능력을 평가하였으며, 그 결과는 Table 2와 같다.
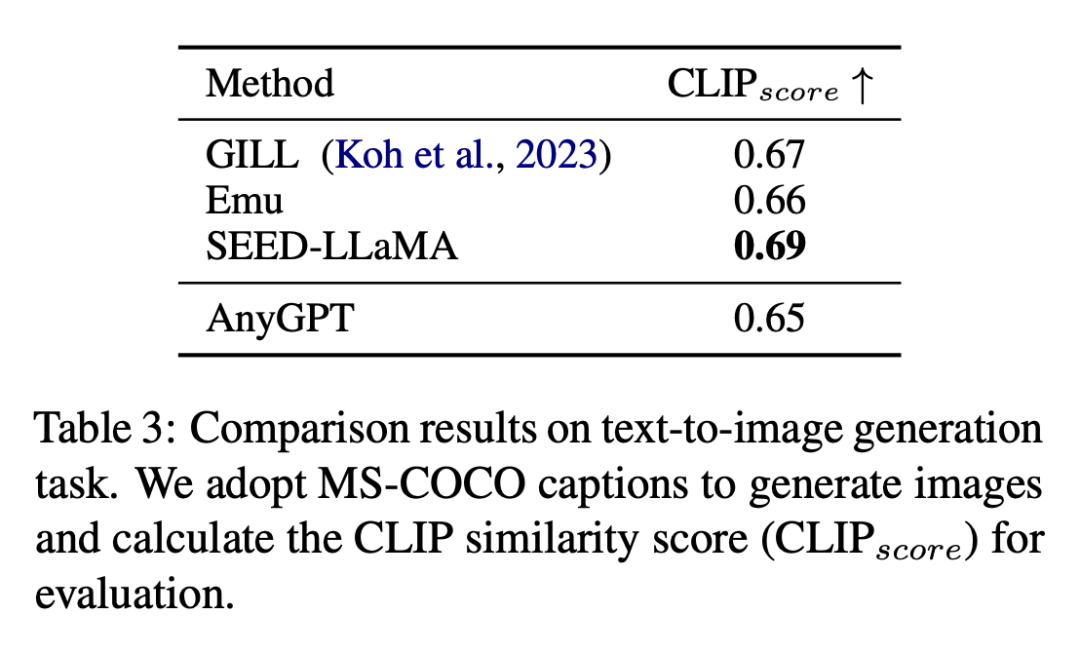
텍스트-이미지 생성 작업의 결과는 표 3과 같습니다.
 Speech
Speech
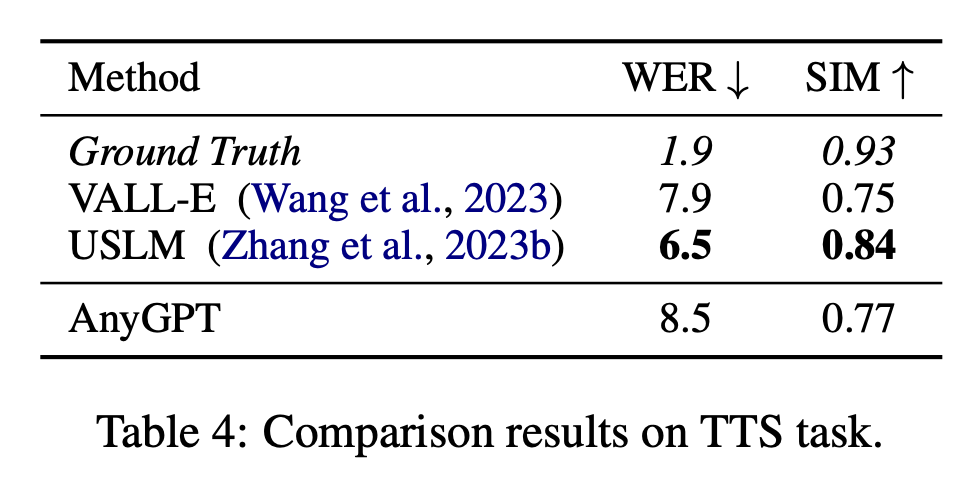
이 연구에서는 Wav2vec 2.0 및 Whisper를 사용하여 LibriSpeech 데이터세트의 테스트 하위 집합에서 단어 오류율(WER)을 계산하여 자동 음성 인식(ASR) 작업에 대한 AnyGPT의 성능을 평가합니다. 큰 V2를 기준으로 하고, 평가 결과를 표 5에 나타내었다.

Music
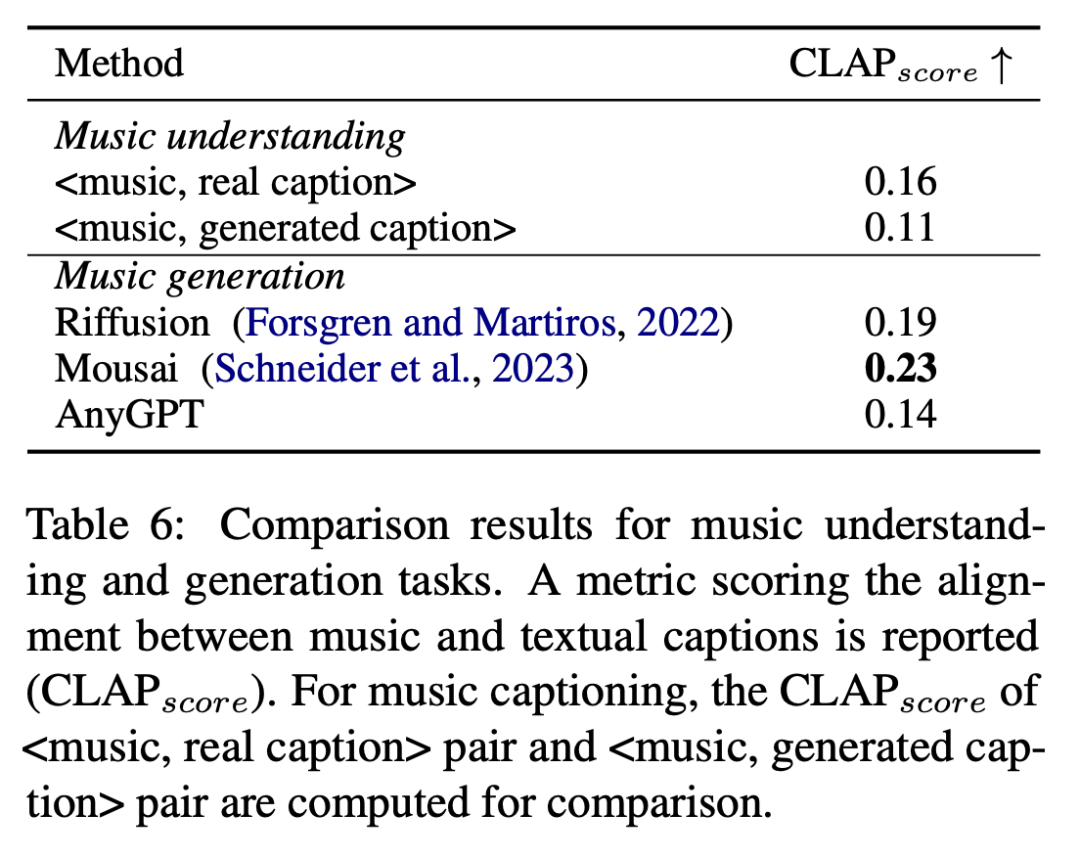
이 연구는 생성된 음악을 측정하기 위한 객관적인 지표로 CLAP_score 점수를 사용하여 MusicCaps 벤치마크에서 음악 이해 및 생성 작업에 대한 AnyGPT의 성능을 평가했습니다. 텍스트 설명 간의 유사성, 평가 결과는 표 6에 나와 있습니다.
관심 있는 독자는 논문 원문을 읽고 연구 내용에 대해 자세히 알아볼 수 있습니다.
위 내용은 Fudan University 등은 이미지, 음악, 텍스트 및 음성을 포함한 모든 모달 입력 및 출력인 AnyGPT를 출시했습니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



