

MySQL如何使用临时表_MySQL

bitsCN.com MySQL如何使用临时表 【临时表存储】MySQL临时表分为“内存临时表”和“磁盘临时表”,其中内存临时表使用MySQL的MEMORY存储引擎,磁盘临时表使用MySQL的MyISAM存储引擎;一般情况下,MySQL会先创建内存临时表,但内存临时表超过配置指定的值后,MySQL会将内存临时表导出到磁盘临时表。 【使用临时表的场景】1)ORDER BY子句和GROUP BY子句不同,例如:ORDERY BY price GROUP BY name; 2)在JOIN查询中,ORDER BY或者GROUP BY使用了不是第一个表的列例如:SELECT * from TableA, TableB ORDER BY TableA.price GROUP by TableB.name 3)ORDER BY中使用了DISTINCT关键字ORDERY BY DISTINCT(price) 4)SELECT语句中指定了SQL_SMALL_RESULT关键字SQL_SMALL_RESULT的意思就是告诉MySQL,结果会很小,请直接使用内存临时表,不需要使用索引排序SQL_SMALL_RESULT必须和GROUP BY、DISTINCT或DISTINCTROW一起使用一般情况下,我们没有必要使用这个选项,让MySQL服务器选择即可。 【直接使用磁盘临时表的场景】1)表包含TEXT或者BLOB列;2)GROUP BY 或者 DISTINCT 子句中包含长度大于512字节的列;3)使用UNION或者UNION ALL时,SELECT子句中包含大于512字节的列; 【临时表相关配置】tmp_table_size:指定系统创建的内存临时表最大大小;http://dev.mysql.com/doc/refman/5.1/en/server-system-variables.html#sysvar_tmp_table_size max_heap_table_size: 指定用户创建的内存表的最大大小;http://dev.mysql.com/doc/refman/5.1/en/server-system-variables.html#sysvar_max_heap_table_size 注意:最终的系统创建的内存临时表大小是取上述两个配置值的最小值。 【表的设计原则】使用临时表一般都意味着性能比较低,特别是使用磁盘临时表,性能更慢,因此我们在实际应用中应该尽量避免临时表的使用。如果实在无法避免,也应该尽量避免使用磁盘临时表。 常见的方法有:1)创建索引:在ORDER BY或者GROUP BY的列上创建索引,这样可以避免使用临时表;2)分拆很长的列,可以避免使用磁盘临时表:一般情况下,TEXT、BLOB,大于512字节的字符串,基本上都是为了显示信息,而不会用于查询条件,因此表设计的时候,应该将这些列独立到另外一张表。 【如何判断使用了临时表】使用explain查看执行计划,Extra列看到Using temporary就意味着使用了临时表。 MySQL官方手册:http://dev.mysql.com/doc/refman/5.1/en/internal-temporary-tables.html 摘自 追梦人-技术博客 bitsCN.com

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7393
7393
 15
1630
14
1358
52
1268
25
1217
29
15
1630
14
1358
52
1268
25
1217
29

 화웨이는 내년에 혁신적인 MED 스토리지 제품을 출시할 예정입니다. 랙 용량은 10PB를 초과하고 전력 소비량은 2kW 미만입니다.
Mar 07, 2024 pm 10:43 PM
화웨이는 내년에 혁신적인 MED 스토리지 제품을 출시할 예정입니다. 랙 용량은 10PB를 초과하고 전력 소비량은 2kW 미만입니다.
Mar 07, 2024 pm 10:43 PM
이 웹사이트는 3월 7일 화웨이의 데이터 스토리지 제품 라인 사장인 Zhou Yuefeng 박사가 최근 MWC2024 컨퍼런스에 참석하여 웜 데이터(WarmData)와 콜드 데이터(ColdData)용으로 설계된 차세대 OceanStorArctic 자전 스토리지 솔루션을 구체적으로 시연했다고 보도했습니다. Huawei의 데이터 스토리지 제품 라인 사장 Zhou Yuefeng은 일련의 혁신적인 솔루션을 출시했습니다. 이미지 출처: 이 사이트에 첨부된 Huawei의 공식 보도 자료는 다음과 같습니다. 이 솔루션의 가격은 자기 테이프보다 20% 저렴하며, 전력 소비는 하드 디스크보다 90% 낮습니다. 해외 기술 매체인 blockandfiles에 따르면, Huawei 대변인은 자기전기 저장 솔루션에 대한 정보도 공개했습니다. Huawei의 자기전자 디스크(MED)는 자기 저장 매체의 주요 혁신입니다. 1세대 ME
 Vue3+TS+Vite 개발 기술: 데이터 암호화 및 저장 방법
Sep 10, 2023 pm 04:51 PM
Vue3+TS+Vite 개발 기술: 데이터 암호화 및 저장 방법
Sep 10, 2023 pm 04:51 PM
Vue3+TS+Vite 개발 팁: 데이터를 암호화하고 저장하는 방법 인터넷 기술의 급속한 발전으로 인해 데이터 보안 및 개인 정보 보호가 점점 더 중요해지고 있습니다. Vue3+TS+Vite 개발 환경에서 데이터를 암호화하고 저장하는 방법은 모든 개발자가 직면해야 하는 문제입니다. 이 기사에서는 개발자가 애플리케이션 보안 및 사용자 경험을 개선하는 데 도움이 되는 몇 가지 일반적인 데이터 암호화 및 저장 기술을 소개합니다. 1. 데이터 암호화 프런트엔드 데이터 암호화 프런트엔드 암호화는 데이터 보안을 보호하는 중요한 부분입니다. 일반적으로 사용되는
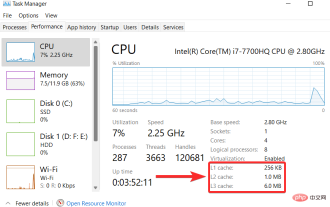 Windows 11에서 캐시를 지우는 방법: 사진이 포함된 자세한 튜토리얼
Apr 24, 2023 pm 09:37 PM
Windows 11에서 캐시를 지우는 방법: 사진이 포함된 자세한 튜토리얼
Apr 24, 2023 pm 09:37 PM
캐시란 무엇입니까? 캐시(ka·shay로 발음)는 자주 요청되는 데이터 및 지침을 저장하는 데 사용되는 특수 고속 하드웨어 또는 소프트웨어 구성 요소로, 웹 사이트, 애플리케이션, 서비스 및 기타 시스템 측면을 더 빠르게 로드하는 데 사용할 수 있습니다. . 캐싱을 사용하면 가장 자주 액세스하는 데이터를 쉽게 사용할 수 있습니다. 캐시 파일은 캐시 메모리와 동일하지 않습니다. 캐시 파일은 여러 프로그램에서 필요할 수 있는 PNG, 아이콘, 로고, 셰이더 등과 같이 자주 필요한 파일을 의미합니다. 이러한 파일은 일반적으로 숨겨져 있는 실제 드라이브 공간에 저장됩니다. 반면에 캐시 메모리는 주 메모리 및/또는 RAM보다 빠른 메모리 유형입니다. CPU에 더 가깝고 RAM에 비해 빠르기 때문에 데이터 액세스 시간을 크게 줄입니다.
 우분투에서의 Git 설치 과정
Mar 20, 2024 pm 04:51 PM
우분투에서의 Git 설치 과정
Mar 20, 2024 pm 04:51 PM
Git은 빠르고 안정적이며 적응력이 뛰어난 분산 버전 제어 시스템입니다. 분산된 비선형 워크플로를 지원하도록 설계되어 모든 규모의 소프트웨어 개발 팀에 이상적입니다. 각 Git 작업 디렉터리는 모든 변경 사항에 대한 전체 기록을 보유하고 네트워크 액세스나 중앙 서버 없이도 버전을 추적할 수 있는 독립적인 저장소입니다. GitHub는 분산 개정 제어의 모든 기능을 제공하는 클라우드에 호스팅되는 Git 저장소입니다. GitHub는 클라우드에서 호스팅되는 Git 저장소입니다. CLI 도구인 Git과 달리 GitHub에는 웹 기반 그래픽 사용자 인터페이스가 있습니다. 이는 다른 개발자와 협력하고 스크립트 변경 사항을 추적하는 버전 제어에 사용됩니다.
 민감한 데이터를 보호하기 위해 sessionStorage를 올바르게 사용하는 방법
Jan 13, 2024 am 11:54 AM
민감한 데이터를 보호하기 위해 sessionStorage를 올바르게 사용하는 방법
Jan 13, 2024 am 11:54 AM
sessionStorage를 올바르게 사용하여 민감한 정보를 저장하려면 특정 코드 예제가 필요합니다. 웹 개발이든 모바일 애플리케이션 개발이든 사용자 로그인 자격 증명, ID 번호 등과 같은 민감한 정보를 저장하고 처리해야 하는 경우가 많습니다. 프런트엔드 개발에서는 sessionStorage를 사용하는 것이 일반적인 스토리지 솔루션입니다. 그러나 sessionStorage는 브라우저 기반 스토리지이기 때문에 저장된 민감한 정보가 악의적으로 접근 및 사용되지 않도록 몇 가지 보안 문제에 주의가 필요합니다.
 PHP와 Swoole은 어떻게 효율적인 데이터 캐싱 및 저장을 달성합니까?
Jul 23, 2023 pm 04:03 PM
PHP와 Swoole은 어떻게 효율적인 데이터 캐싱 및 저장을 달성합니까?
Jul 23, 2023 pm 04:03 PM
PHP와 Swoole은 어떻게 효율적인 데이터 캐싱 및 저장을 달성합니까? 개요: 웹 애플리케이션 개발에서 데이터 캐싱 및 저장은 매우 중요한 부분입니다. PHP와 Swoole은 데이터를 캐시하고 저장하는 효율적인 방법을 제공합니다. 이 기사에서는 PHP와 Swoole을 사용하여 효율적인 데이터 캐싱 및 저장을 달성하는 방법을 소개하고 해당 코드 예제를 제공합니다. 1. swoole 소개: swoole은 PHP 언어용으로 개발된 고성능 비동기 네트워크 통신 엔진입니다.
 한 글로 인공지능 테이블 이해하기: MindsDB로 시작하기
Apr 12, 2023 pm 12:04 PM
한 글로 인공지능 테이블 이해하기: MindsDB로 시작하기
Apr 12, 2023 pm 12:04 PM
이 기사는 WeChat 공개 계정 "정보 시대에 살기"에서 재인쇄되었습니다. 저자는 정보 시대에 살고 있습니다. 이 기사를 재인쇄하려면 Living in the Information Age 공개 계정에 문의하세요. 데이터베이스 작업에 익숙한 학생들에게는 멋진 SQL 문을 작성하고 데이터베이스에서 필요한 데이터를 찾는 방법을 찾는 것이 일상적인 작업입니다. 머신러닝에 익숙한 학생들에게는 데이터를 얻고, 데이터를 전처리하고, 모델을 구축하고, 훈련 세트와 테스트 세트를 결정하고, 훈련된 모델을 사용하여 미래에 대한 일련의 예측을 하는 것도 일상적인 작업입니다. 그렇다면 두 기술을 결합할 수 있을까요? 데이터는 데이터베이스에 저장되어 있으며 예측은 과거 데이터를 기반으로 해야 한다는 것을 알 수 있습니다. 데이터베이스에 존재하는 데이터를 통해 미래의 데이터를 쿼리하면,
 PHP 배열을 사용한 데이터 캐싱 및 저장 방법 및 기술
Jul 16, 2023 pm 02:33 PM
PHP 배열을 사용한 데이터 캐싱 및 저장 방법 및 기술
Jul 16, 2023 pm 02:33 PM
PHP 배열을 사용하여 데이터 캐싱 및 저장을 구현하는 방법 및 기술 인터넷의 발전과 데이터 양의 급속한 증가로 인해 데이터 캐싱 및 저장은 개발 과정에서 고려해야 할 문제 중 하나가 되었습니다. 널리 사용되는 프로그래밍 언어인 PHP는 데이터 캐싱 및 저장을 구현하는 다양한 방법과 기술도 제공합니다. 그중에서도 데이터 캐싱과 저장을 위해 PHP 배열을 사용하는 것은 간단하고 효율적인 방법입니다. 1. 데이터 캐싱 데이터 캐싱의 목적은 데이터베이스나 기타 외부 데이터 소스에 대한 액세스 횟수를 줄여서
