
이전 사례에서는 모델 융합이 널리 사용되었으며, 특히 판별 모델에서는 꾸준히 성능을 향상시킬 수 있는 방법으로 간주됩니다. 그러나 생성 언어 모델의 경우 작동 방식은 관련 디코딩 프로세스로 인해 판별 모델만큼 간단하지 않습니다.
또한 대형 모델의 매개변수 개수 증가로 인해 매개변수 규모가 더 큰 시나리오에서는 단순 앙상블 학습으로 고려할 수 있는 방법이 클래식 스태킹, 부스팅 및 기타 방법은 스택 모델의 매개변수 문제를 쉽게 확장할 수 없기 때문입니다. 따라서 대형 모델의 앙상블 학습에는 세심한 고려가 필요합니다.
아래에서는 모델 통합, 확률적 통합, 접목 학습, 크라우드소싱 투표, MOE 등 5가지 기본 통합 방법을 설명합니다.
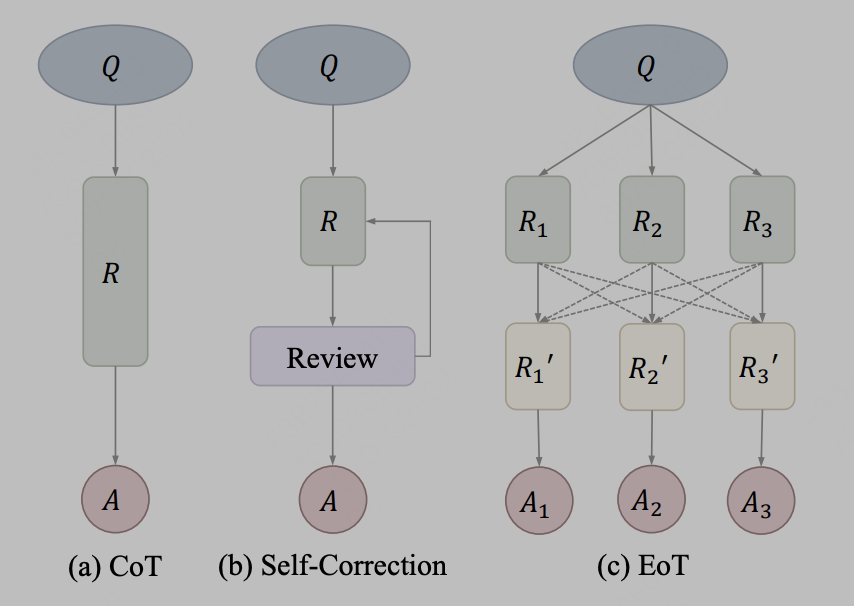
모델 통합은 비교적 간단합니다. 즉, 큰 모델은 출력 텍스트 수준에서 통합됩니다. 예를 들어, 세 가지 다른 LLama 모델의 출력 결과를 사용하여 네 번째 모델에 대한 프롬프트로 입력하면 됩니다. 참조. 실제로 통신 방법으로는 텍스트를 통한 정보 전달이 활용될 수 있는데, 대표적인 방법이 EoT인데, 이는 '생각의 교환: 모델 간 통신을 통한 대규모 언어 모델 역량 강화'라는 글에서 유래한 것입니다. 생각 교환(Exchange-of-Thought)으로 알려진 생각 교환 프레임워크는 문제 해결 과정에서 집단적 이해를 향상시키기 위해 모델 간의 교차 의사소통을 촉진하도록 설계되었습니다. 이 프레임워크를 통해 모델은 다른 모델의 추론을 흡수하여 자체 솔루션을 더 잘 조정하고 개선할 수 있습니다. 논문의 다이어그램으로 표현:
 Picture
Picture
저자는 CoT와 자기 수정 방법을 동일한 개념으로 취급한 후 EoT는 여러 모델 간에 계층적 메시지 전달이 가능한 새로운 방법을 제공합니다. 모델 간 의사소통을 통해 모델은 서로의 추론과 사고 과정을 활용하여 문제를 보다 효과적으로 해결하는 데 도움을 줄 수 있습니다. 이 접근 방식은 모델 성능과 정확성을 향상시킬 것으로 예상됩니다.
확률적 앙상블은 기존 기계 학습 방법과 유사합니다. 예를 들어, 모델이 예측한 로짓 결과를 평균하여 앙상블 방법을 구성할 수 있습니다. 대형 모델에서는 변형 모델의 어휘 출력 확률 수준에서 확률적 앙상블을 융합할 수 있습니다. 이 작업을 수행하려면 융합된 여러 원본 모델의 어휘 목록이 일관되어야 한다는 점에 유의하는 것이 중요합니다. 이러한 통합 방법은 모델의 성능과 견고성을 향상시켜 실제 적용 시나리오에 더 적합하게 만듭니다.
아래에서는 간단한 의사코드 구현을 제공합니다.
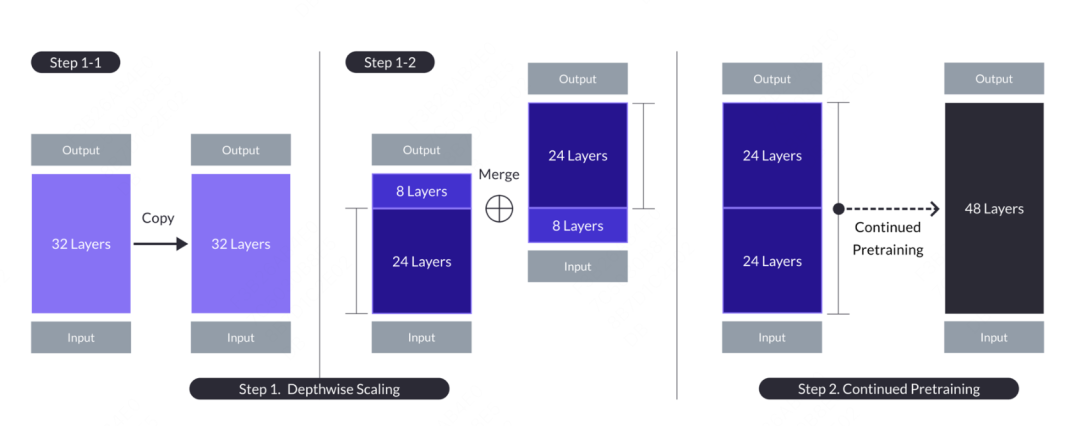
접목 학습의 개념은 데이터 마이닝 대회에서 유래한 국내 캐글 그랜드마스터의 Plantgo에서 유래되었습니다. 본질적으로 일종의 전이학습(transfer learning)으로, 원래 한 트리 모델의 출력을 다른 트리 모델의 입력으로 사용하는 방법을 설명하는 데 사용되었습니다. 이 방법은 나무 번식의 접목과 유사하므로 이름이 붙여졌습니다. 대형 모델에는 접목 학습의 적용도 있습니다. 모델 이름은 "SOLAR 10.7B: Scaling Large Language Models with Simple but Effective Depth Up-Scaling"에서 나온 것입니다. 모델 접목. 머신러닝의 접목 학습과 달리, 대형 모델은 다른 모델의 확률 결과를 직접 융합하지 않고, 융합 모델에 구조와 가중치의 일부를 접목하여 일정한 사전 학습 과정을 거칩니다. 모델 매개변수를 새 모델에 맞게 조정할 수 있습니다. 구체적인 작업은 후속 수정을 위해 n개의 레이어가 포함된 기본 모델을 복사하는 것입니다. 그런 다음 마지막 m개의 레이어가 원본 모델에서 제거되고 처음 m개의 레이어가 복사본에서 제거되어 두 개의 서로 다른 n-m 레이어 모델이 생성됩니다. 마지막으로 두 모델을 연결하여 2*(n-m) 레이어의 확장 모델을 형성합니다.
48레이어 대상 모델을 구축해야 하는 경우 두 개의 32레이어 모델에서 처음 24레이어와 마지막 24레이어를 가져와 연결하여 새로운 48레이어 모델을 형성하는 것을 고려할 수 있습니다. 그런 다음 결합된 모델은 추가로 사전 학습됩니다. 일반적으로 사전 훈련을 계속하려면 처음부터 훈련하는 것보다 데이터 양과 컴퓨팅 리소스가 덜 필요합니다.
 Pictures
Pictures
사전 훈련을 계속한 후에는 지시 미세 조정과 DPO라는 두 가지 프로세스가 포함된 정렬 작업도 필요합니다. 명령어 미세 조정은 오픈 소스 명령어 데이터를 사용하고 이를 수학 관련 명령어 데이터로 변환하여 모델의 수학적 기능을 향상시킵니다. DPO는 결국 SOLAR 채팅 버전이 된 기존 RLHF를 대체합니다.
크라우드소싱 투표는 올해 WSDM CUP 1위 계획에 사용되었으며, 이전 국내 세대 대회에서도 시행되었습니다. 핵심 아이디어는 모델에 의해 생성된 문장이 모든 모델의 결과와 가장 유사한 경우 이 문장을 모든 모델의 평균으로 간주할 수 있다는 것입니다. 이렇게 확률적 의미의 평균이 토큰 생성 결과의 평균이 됩니다. 주어진 테스트 샘플에 집계해야 할 후보 답변이 있다고 가정합니다. 각 후보에 대해 )와 () 사이의 상관 점수를 계산하고 이를 ()의 품질 점수로 합산합니다. 소스는 레이어 코사인 유사성(em_a_s로 표시됨), 단어 수준 ROUGE-L(word_a_f로 표시됨) 및 문자 수준 ROUGE-L(char_a_f로 표시됨)을 포함할 수 있습니다. 다음은 리터럴을 포함하여 인위적으로 구성된 유사성 표시기입니다.
코드 주소: https://github.com/zhangzhao219/WSDM-Cup-2024/tree/main
마지막이자 가장 중요한 것은 대규모 모델 혼합 전문가 모델( 줄여서 MoE)는 여러 하위 모델(즉, "전문가")을 결합하는 모델 아키텍처 방법으로, 여러 전문가의 공동 작업을 통해 전반적인 예측 효과를 향상시키는 것을 목표로 합니다. MoE 구조는 모델의 처리 능력을 크게 향상시킬 수 있습니다. 일반적인 대형 모델 MoE 아키텍처에는 게이팅 메커니즘과 일련의 전문가 네트워크가 포함됩니다. 게이팅 메커니즘은 각 전문가의 최종 기여도를 결정하기 위해 입력 데이터를 기반으로 각 전문가의 가중치를 동적으로 할당하는 역할을 합니다. 출력에 대한 기여도와 동시에 전문가 선택 메커니즘은 게이팅 신호의 지시에 따라 실제 예측 계산에 참여할 전문가의 일부를 선택합니다. 또한 모델은 다양한 입력을 기반으로 최적의 전문가를 선택할 수 있습니다.
전문가 혼합(MoE)은 최근 새로운 개념이 아닙니다. "지역 전문가의 적응형 혼합". "는 1991년에 출판되었습니다. 앙상블 학습과 유사하게 그 핵심은 독립적인 전문가 네트워크 모음을 위한 조정 및 융합 메커니즘을 만드는 것입니다. 이러한 아키텍처에서 각 독립적인 네트워크(즉, "전문가")는 특정 부분을 처리하는 책임을 집니다. 이 하위 집합은 특정 주제, 특정 분야, 특정 문제 분류 등에 편향될 수 있으며 명시적인 개념이 아닙니다.
핵심 문제는 시스템이 어떤 전문가를 처리할지 결정하는 방법입니다. Gating Network는 이 문제를 해결하기 위해 전체 교육 동안 이러한 전문가 네트워크와 게이트에 가중치를 할당하여 각 전문가의 작업 책임을 결정합니다. 제어 네트워크는 동시에 훈련되며 명시적인 수동 조작이 필요하지 않습니다.
2010년부터 2015년까지의 기간 동안 두 가지 연구 방향이 MoE(혼합 전문가 모델)의 추가 개발에 중요한 영향을 미쳤습니다.
组件化专家:在传统的MoE框架中,系统由一个门控网络和若干个专家网络构成。在支持向量机(SVM)、高斯过程以及其他机器学习方法的背景下,MoE常常被当作模型中的一个单独部分。然而,Eigen、Ranzato和Ilya等研究者提出了将MoE作为深层网络中一个内部组件的想法。这种创新使得MoE可以被整合进多层网络的特定位置中,从而使模型在变得更大的同时,也能保持高效。
条件计算:传统神经网络会在每一层对所有输入数据进行处理。在这段时期,Yoshua Bengio等学者开始研究一种基于输入特征动态激活或者禁用网络部分的方法。
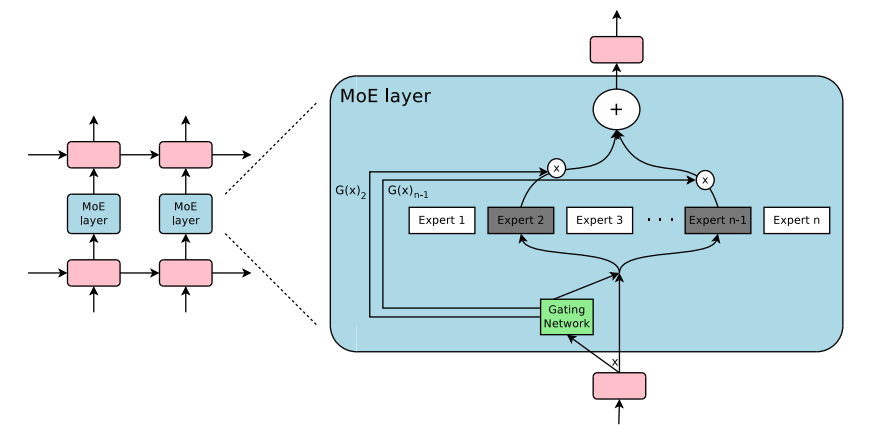
这两项研究的结合推动了混合专家模型在自然语言处理(NLP)领域的应用。尤其是在2017年,Shazeer和他的团队将这一理念应用于一个137亿参数的LSTM模型(这是当时在NLP领域广泛使用的一种模型架构,由Schmidhuber提出)。他们通过引入稀疏性来实现在保持模型规模巨大的同时,加快推理速度。这项工作主要应用于翻译任务,并且面对了包括高通信成本和训练稳定性问题在内的多个挑战。如图所示《Outrageously Large Neural Network》 中的MoE layer架构如下:
 图片
图片
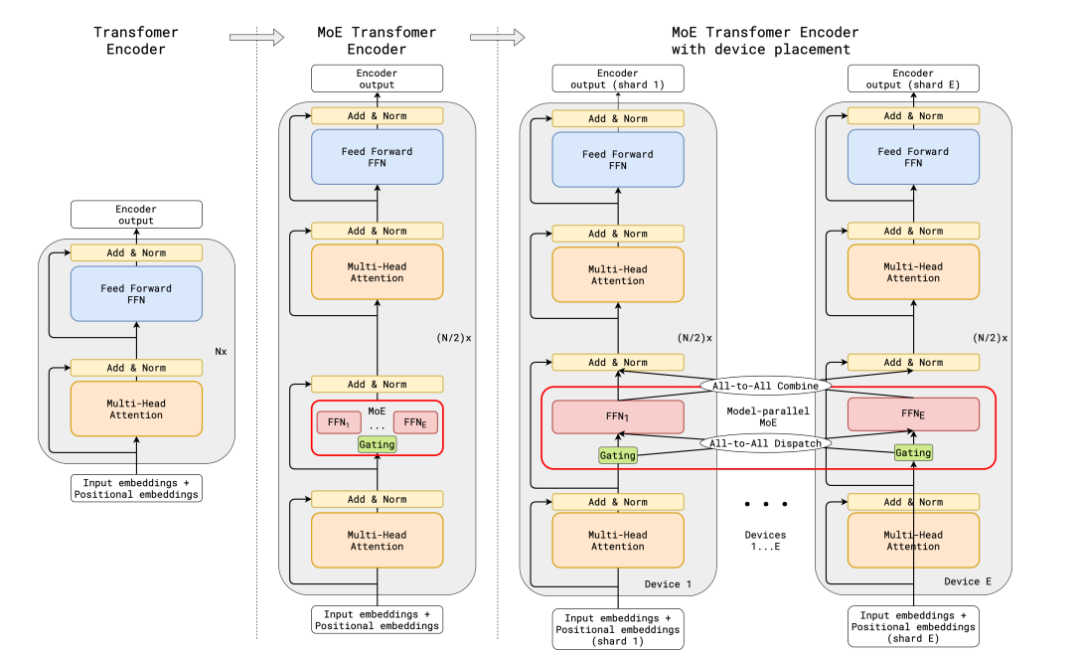
传统的MoE都集中在非transfomer的模型架构上,大模型时代的transfomer模型参数量达百亿级,如何在transformer上应用MoE并且把参数扩展到百亿级别,并且解决训练稳定性和推理效率的问题,成为MoE在大模型应用上的关键问题。谷歌提出了代表性的方法Gshard,成功将Transformer模型的参数量增加至超过六千亿,并以此提升模型水平。
在GShard框架下,编码器和解码器中的每个前馈网络(FFN)层被一种采用Top-2门控机制的混合专家模型(MoE)层所替代。下面的图示展现了编码器的结构设计。这样的设计对于执行大规模计算任务非常有利:当模型被分布到多个处理设备上时,MoE层在各个设备间进行共享,而其他层则在每个设备上独立复制。其架构如下图所示:
 图片
图片
为了确保训练过程中的负载均衡和效率,GShard提出了三种关键的技术,分别是损失函数,随机路由机制,专家容量限制。
辅助负载均衡损失函数:损失函数考量某个专家的buffer中已经存下的token数量,乘上某个专家的buffer中已经存下的token在该专家上的平均权重,构建这样的损失函数能让专家负载保持均衡。
随机路由机制:在Top-2的机制中,我们总是选择排名第一的专家,但是排名第二的专家则是通过其权重的比例来随机选择的。
专家容量限制:我们可以设置一个阈值来限定一个专家能够处理的token数量。如果两个专家的容量都已经达到了上限,那么令牌就会发生溢出,这时token会通过残差连接传递到下一层,或者在某些情况下被直接丢弃。专家容量是MoE架构中一个非常关键的概念,其存在的原因是所有的张量尺寸在编译时都已经静态确定,我们无法预知会有多少token分配给每个专家,因此需要预设一个固定的容量限制。
需要注意的是,在推理阶段,只有部分专家会被激活。同时,有些计算过程是被所有token共享的,比如自注意力(self-attention)机制。这就是我们能够用相当于12B参数的稠密模型计算资源来运行一个含有8个专家的47B参数模型的原因。如果我们使用Top-2门控机制,模型的参数量可以达到14B,但是由于自注意力操作是专家之间共享的,实际在模型运行时使用的参数量是12B。
整个MoeLayer的原理可以用如下伪代码表示:
M = input.shape[-1] # input维度为(seq_len, batch_size, M),M是注意力输出embedding的维度reshaped_input = input.reshape(-1, M)gates = softmax(einsum("SM, ME -> SE", reshaped_input, Wg)) #输入input,Wg是门控训练参数,维度为(M, E),E是MoE层中专家的数量,输出每个token被分配给每个专家的概率,维度为(S, E)combine_weights, dispatch_mask = Top2Gating(gates) #确定每个token最终分配给的前两位专家,返回相应的权重和掩码dispatched_expert_input = einsum("SEC, SM -> ECM", dispatch_mask, reshaped_input) # 对输入数据进行排序,按照专家的顺序排列,为分发到专家计算做矩阵形状整合h = enisum("ECM, EMH -> ECH", dispatched_expert_input, Wi) #各个专家计算分发过来的input,本质上是几个独立的全链接层h = relu(h)expert_outputs = enisum("ECH, EHM -> ECM", h, Wo) #各个专家的输出outputs = enisum("SEC, ECM -> SM", combine_weights, expert_outputs) #最后,进行加权计算,得到最终MoE-layer层的输出outputs_reshape = outputs.reshape(input.shape) # 从(S, M)变成(seq_len, batch_size, M)MoE의 아키텍처 개선과 관련하여 Switch Transformers는 두 개의 독립적인 입력(예: 두 개의 서로 다른 토큰)을 처리할 수 있고 처리를 위해 4명의 전문가를 갖춘 특수 Switch Transformer 레이어를 설계했습니다. 원래의 top2 전문가 아이디어와 달리 Switch Transformers는 단순화된 top1 전문가 전략을 채택합니다. 아래 그림과 같이
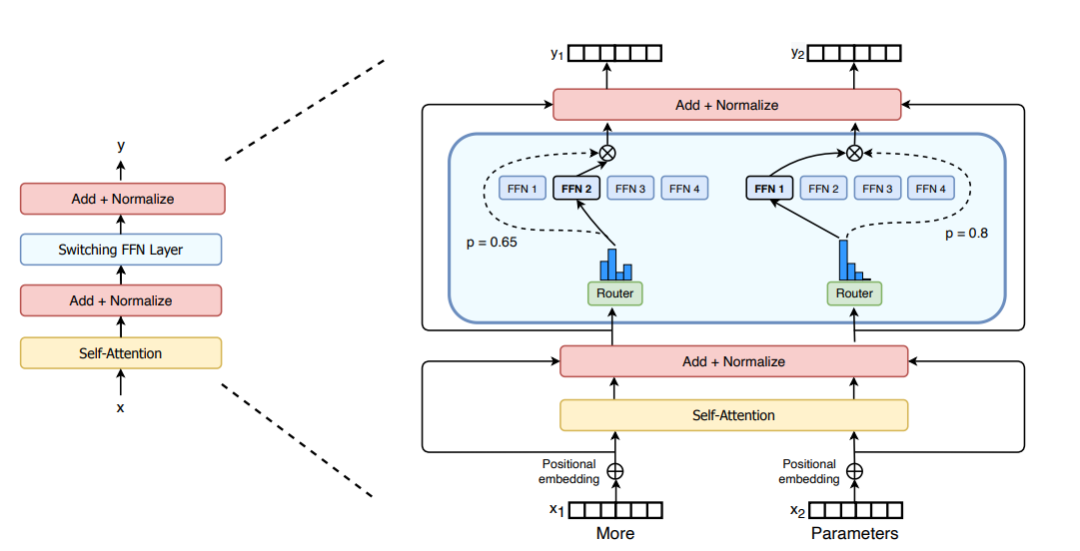 Picture
Picture
다름, 국내 유명 대형 모델 DeepSeek MoE의 아키텍처는 매번 활성화에 참여하는 공유 전문가를 전제로 디자인됩니다. 특정 전문가는 특정 지식 영역에 능숙할 수 있습니다. 전문가의 지식 영역을 세밀하게 세분화함으로써 한 명의 전문가가 너무 많은 지식을 습득해야 하는 것을 방지하여 지식의 혼란을 피할 수 있습니다. 동시에, 공유 전문가를 설정하면 보편적으로 적용 가능한 일부 지식이 모든 계산에 활용되도록 보장됩니다. 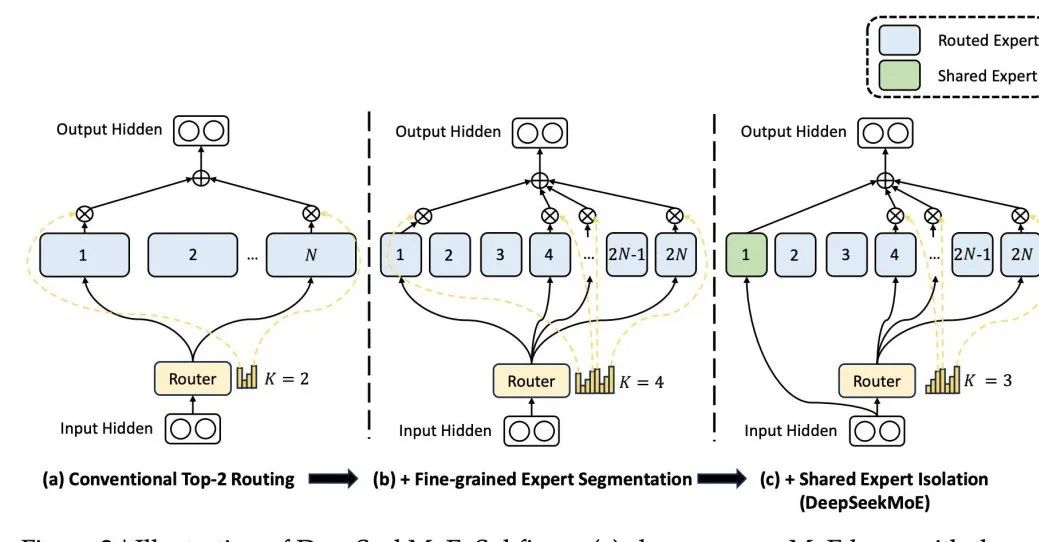 사진
사진
위 내용은 대형 모델의 모델 융합 방법에 대해 이야기해보겠습니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!


















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



